
But Anthropic and OpenAI may rapidly grow their compute share in the next few years. After that, continued scaling would require an economic transformation.
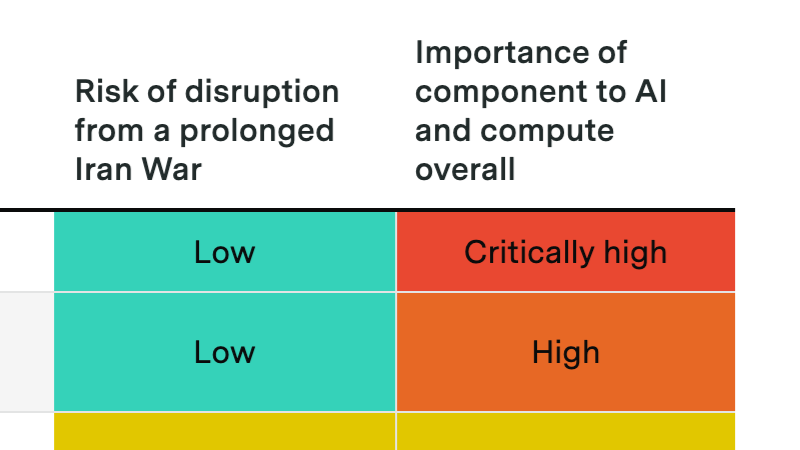
A prolonged Hormuz crisis probably won't derail the compute buildout, but it could slow data center expansion and disrupt Gulf investment flows into AI.

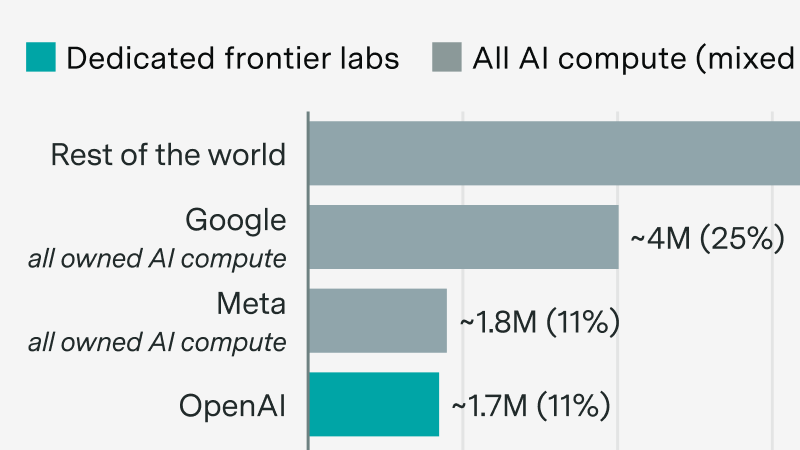
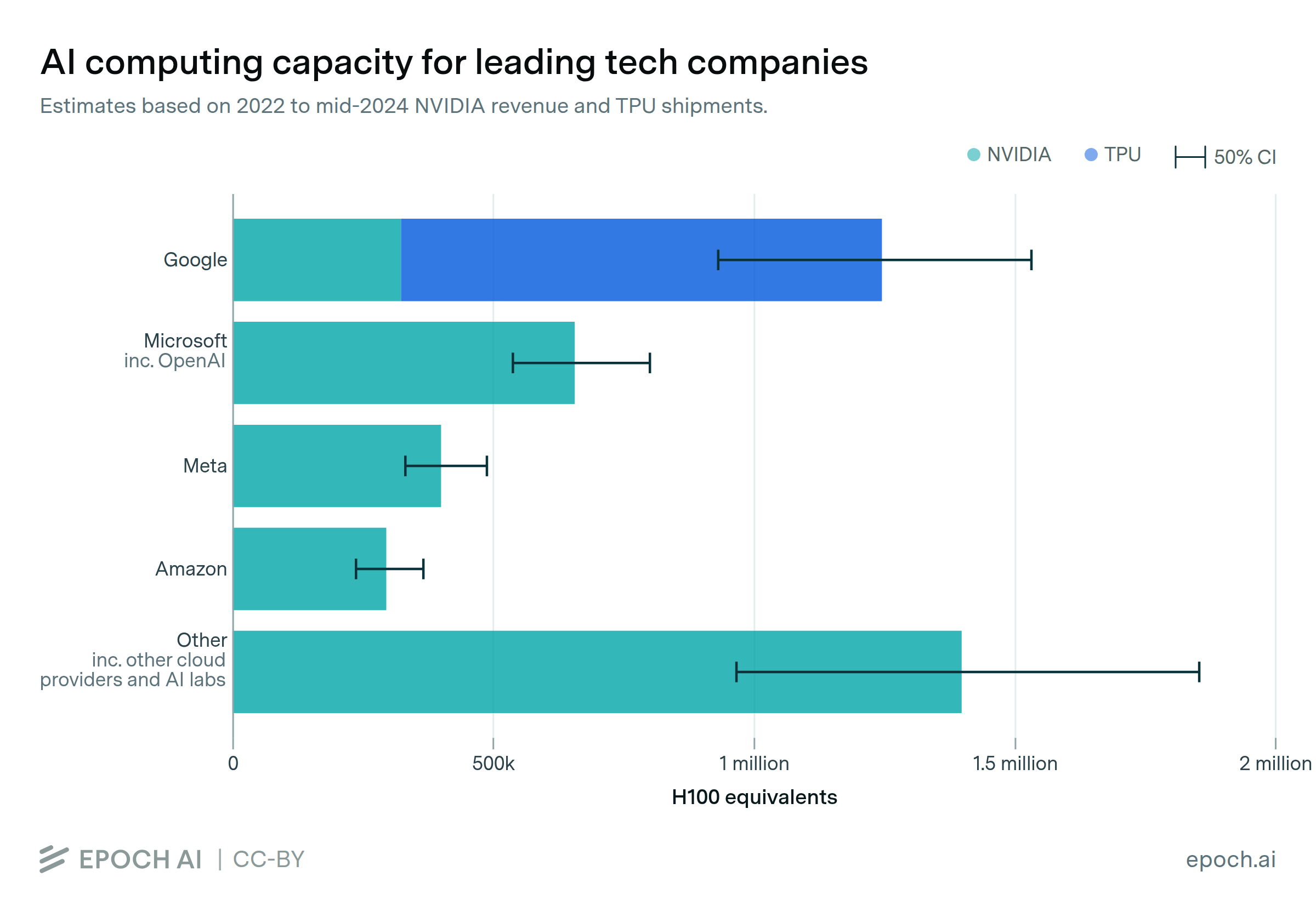
We announce our new AI Chip Owners explorer, showing which companies own the world’s leading AI chips.
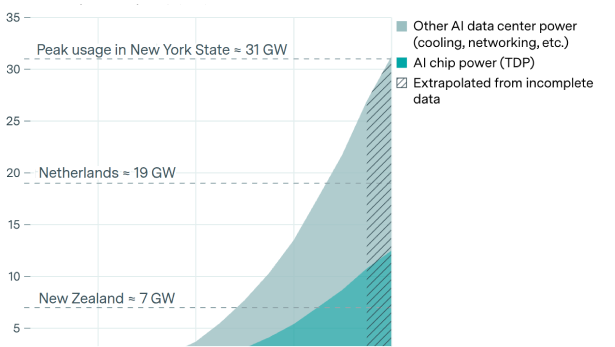
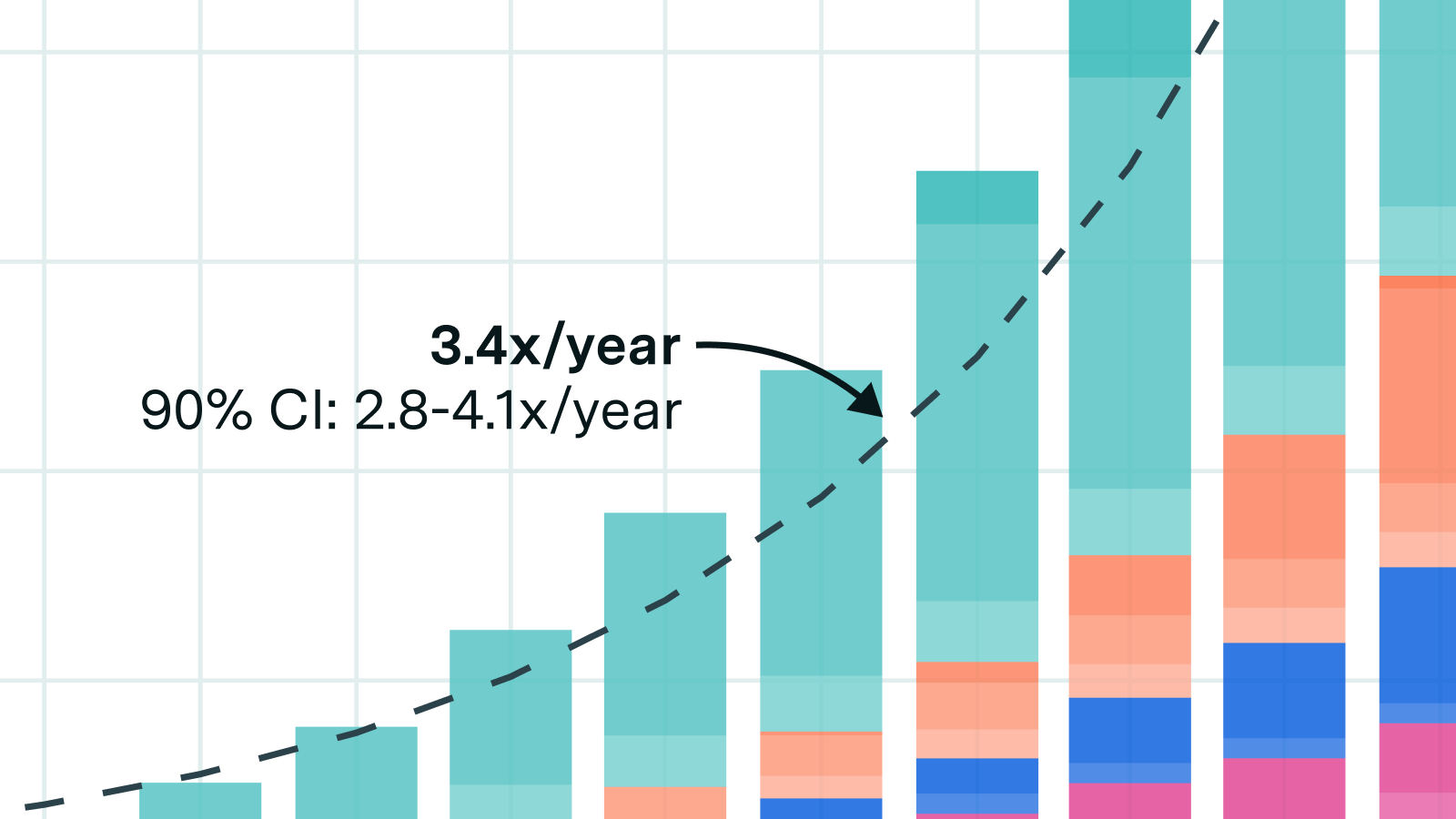

Why power is less of a bottleneck than you think.

The power required to train the largest frontier models is growing by more than 2x per year, and is on trend to reaching multiple gigawatts by 2030.
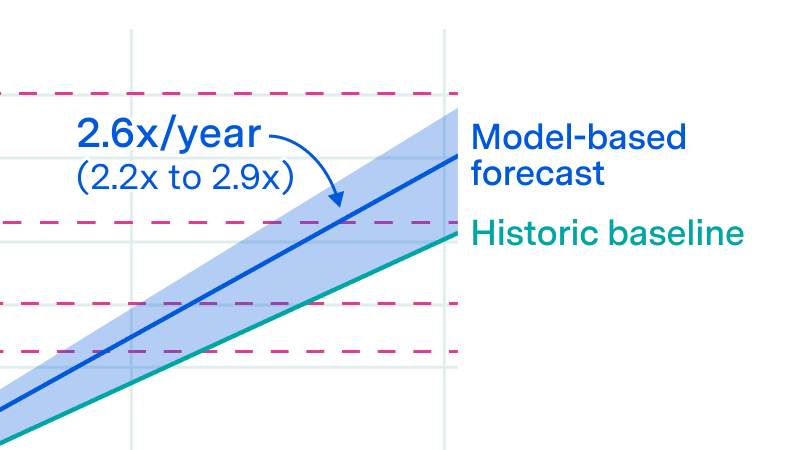
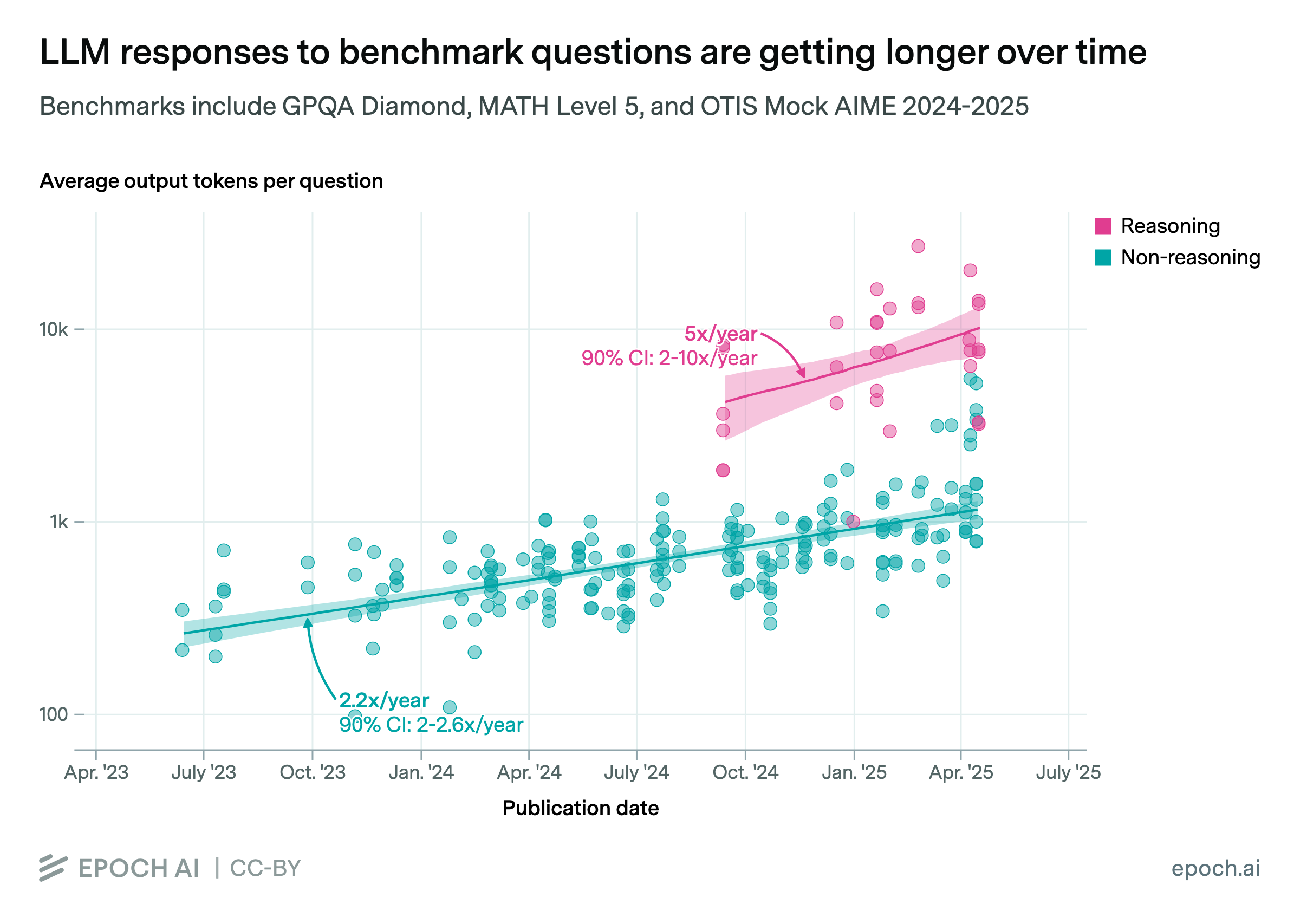
Available evidence suggests that rapid growth in reasoning training can continue for a year or so.
This Gradient Updates issue explores how much energy ChatGPT uses per query, revealing it's 10x less than common estimates.
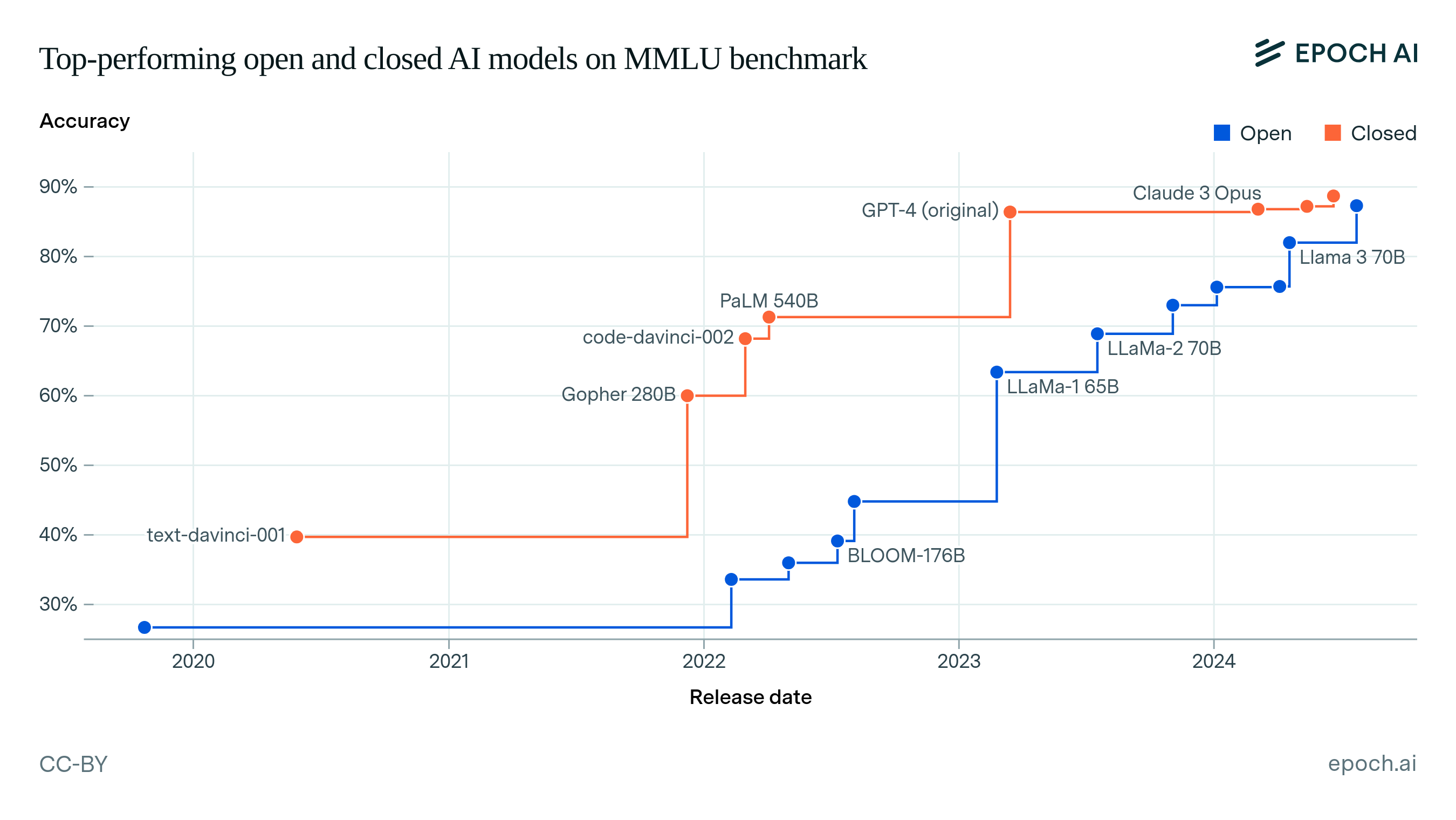
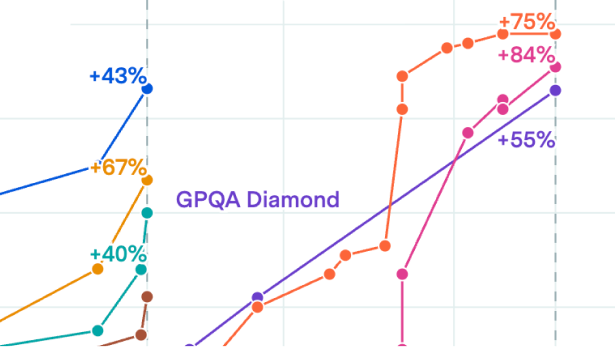
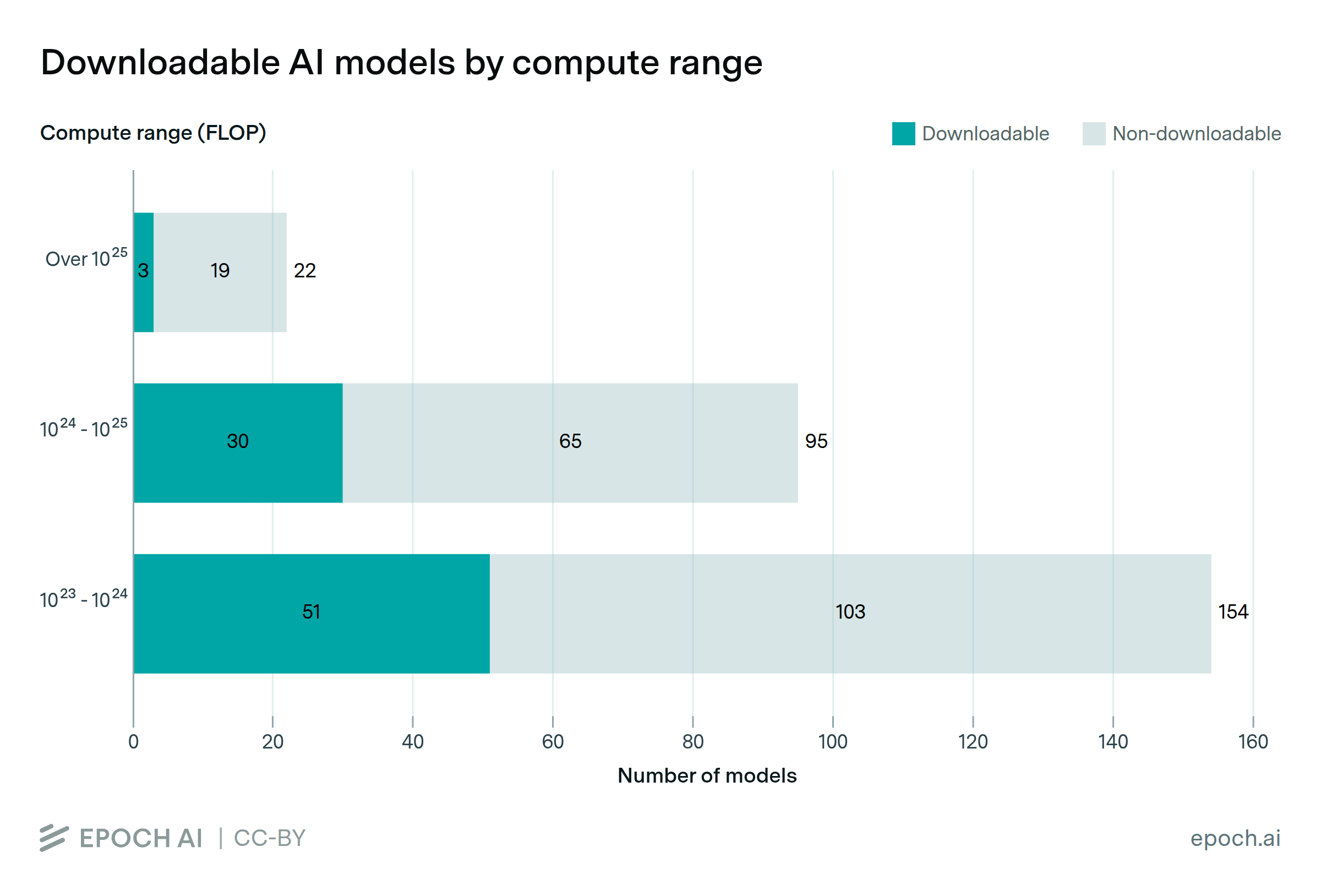
We compare open and closed AI models, and study how openness has evolved. The best open model today is on par with closed models in performance and training compute, but with a lag of about one year.
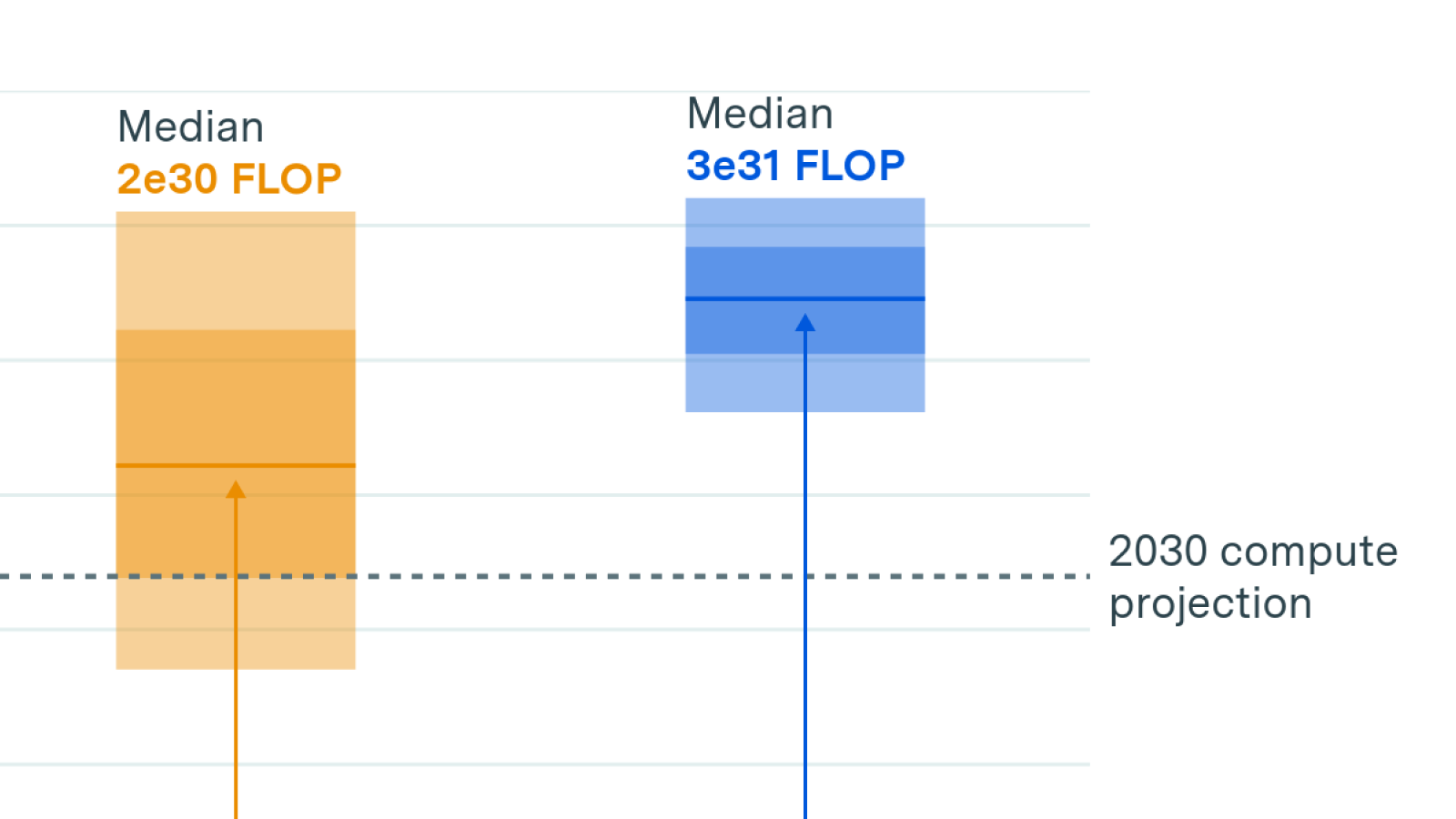
We investigate the scalability of AI training runs. We identify electric power, chip manufacturing, data and latency as constraints. We conclude that 2e29 FLOP training runs will likely be feasible by 2030.
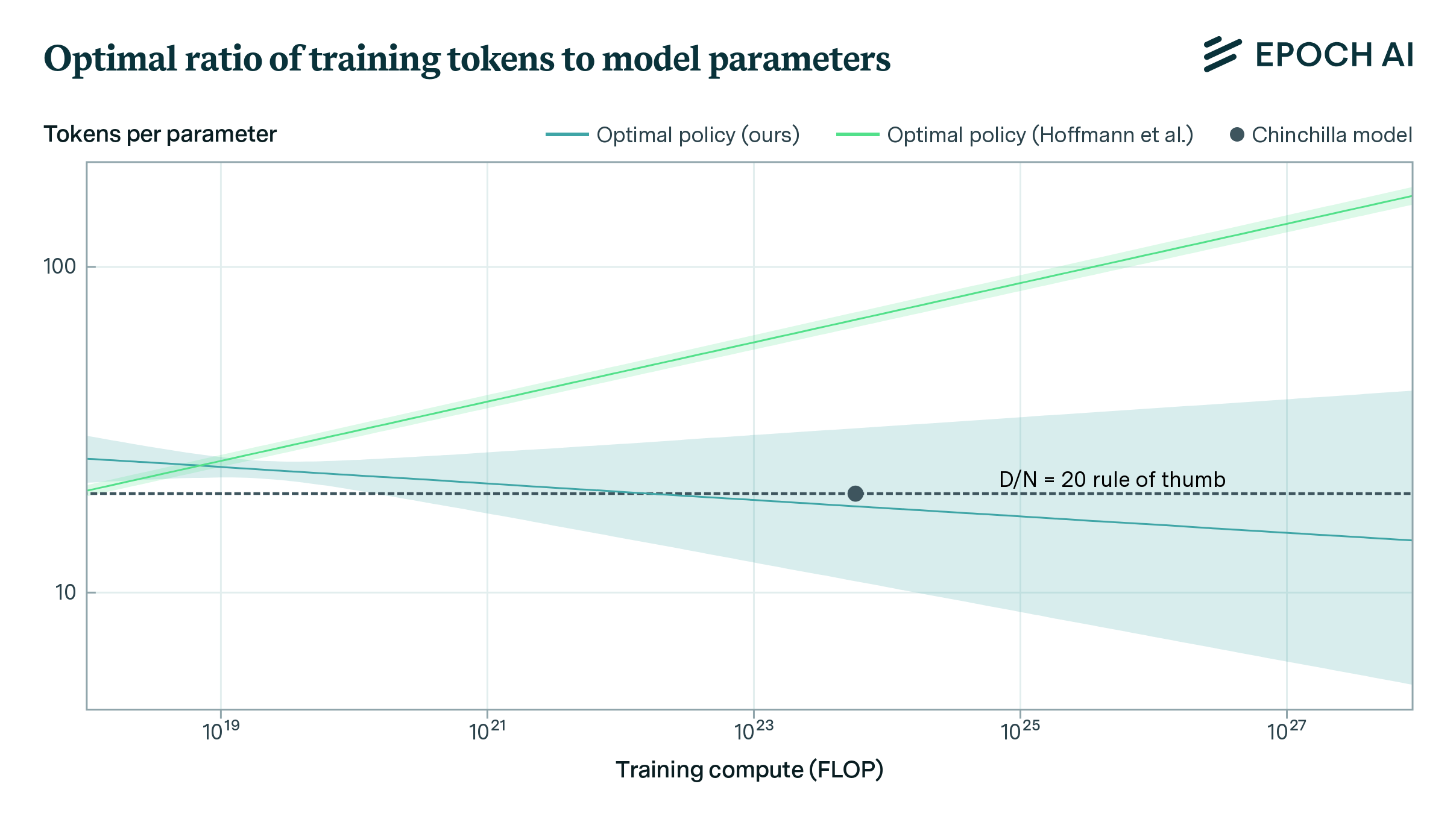
We replicate Hoffmann et al.’s estimation of a parametric scaling law and find issues with their estimates. Our estimates fit the data better and align with Hoffmann’s other approaches.
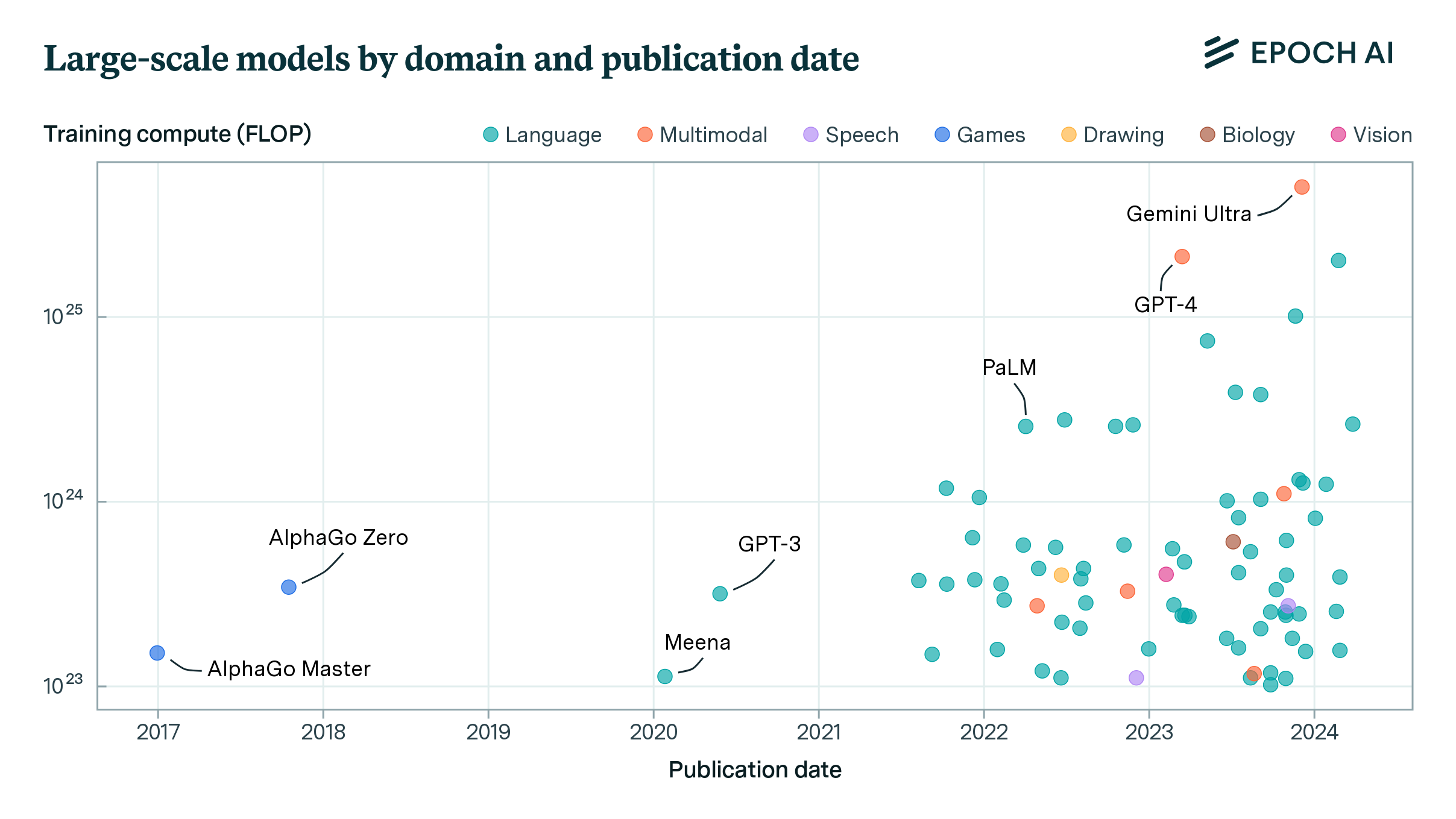
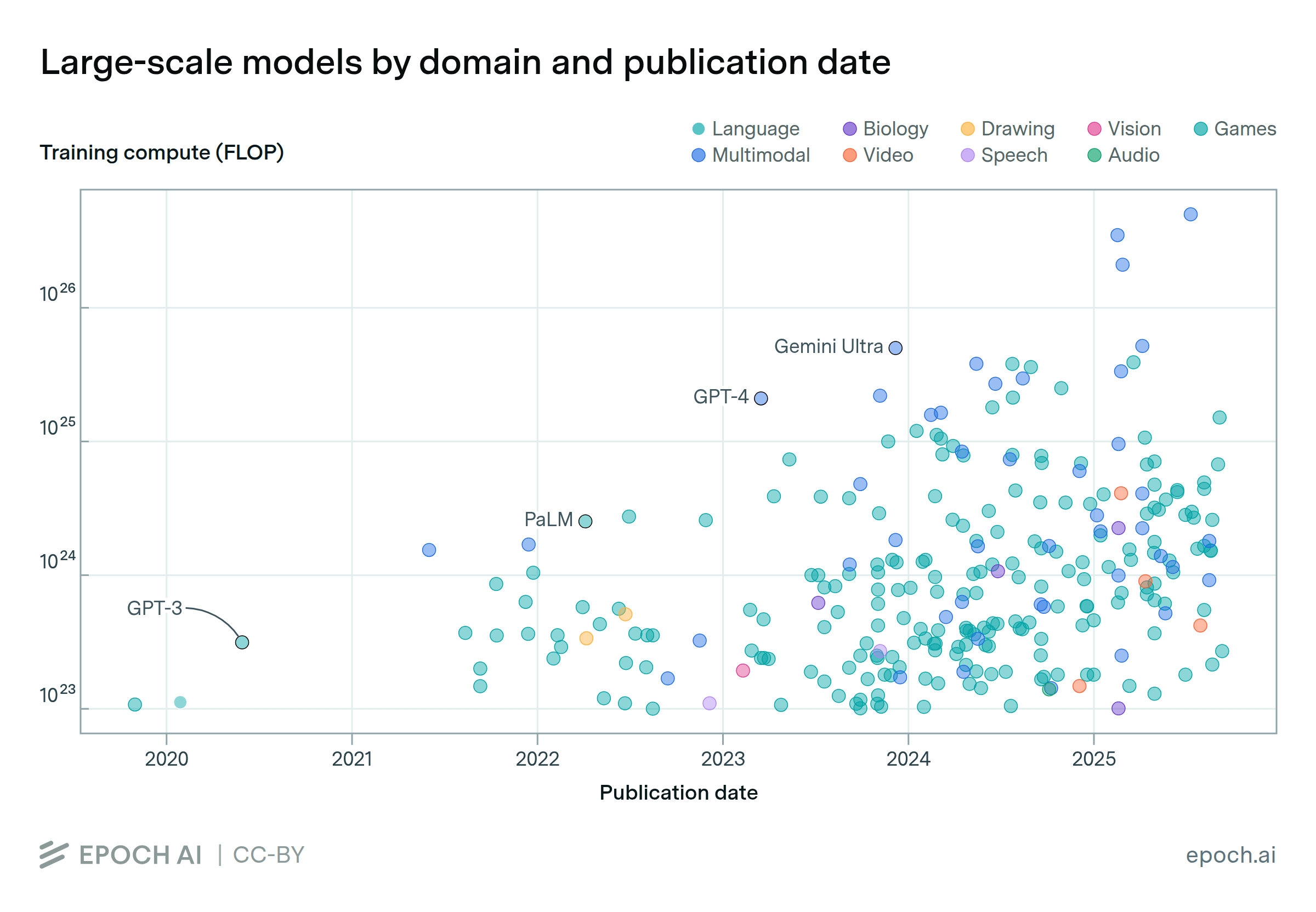
We present a dataset of 81 large-scale models, from AlphaGo to Gemini, developed across 18 countries, at the leading edge of scale and capabilities.