Featured
Newsletter
Feb. 25, 2026

Paper
Mar. 12, 2024

Newsletter
Feb. 28, 2025
Not all AI progress comes from throwing more and better hardware at the problem. Improvements to algorithms, data quality and training techniques can dramatically increase what AI systems are capable of, enabling models to reach the same capabilities with less computation. Epoch tracks these compute efficiency gains, often called algorithmic progress, over time, examining how quickly they are occurring, what is driving them, and what they mean for the pace of future AI progress.
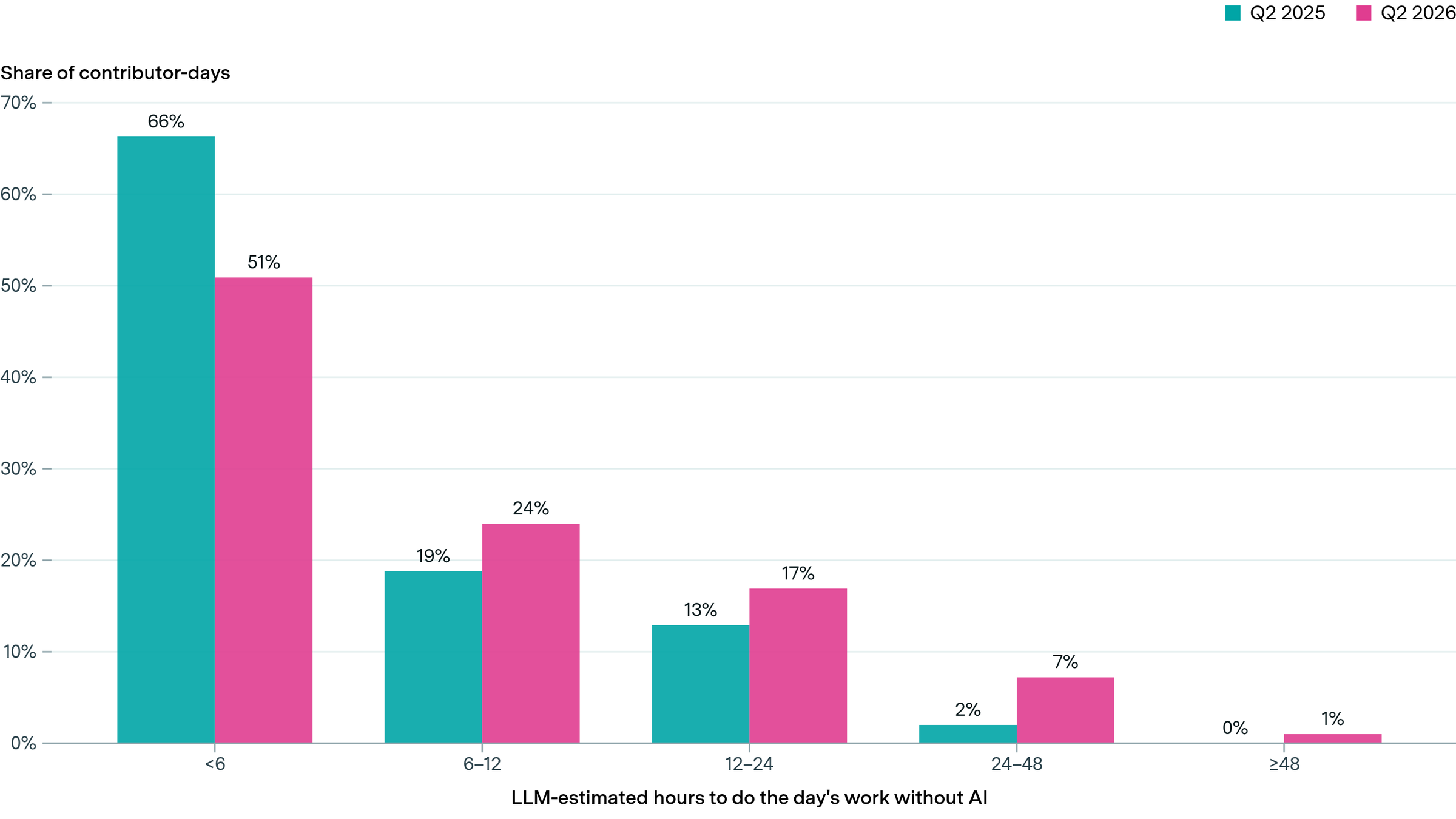
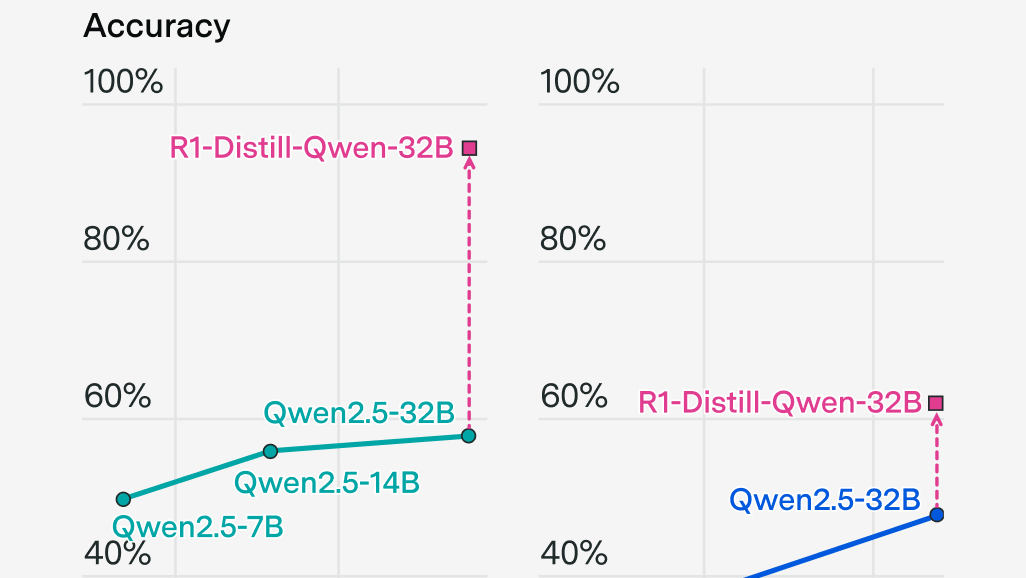
Can Chinese and open model companies compete with the frontier through e.g. distillation and talent?
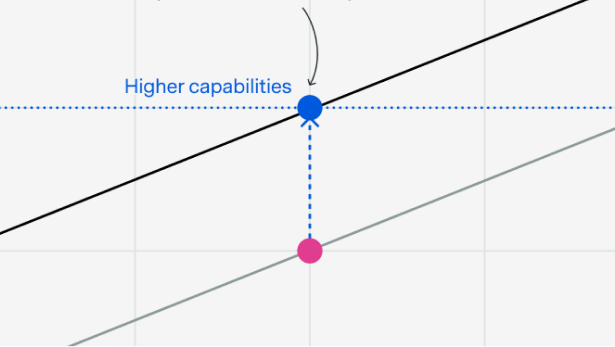
An opinionated guide to “algorithmic progress” and why it matters
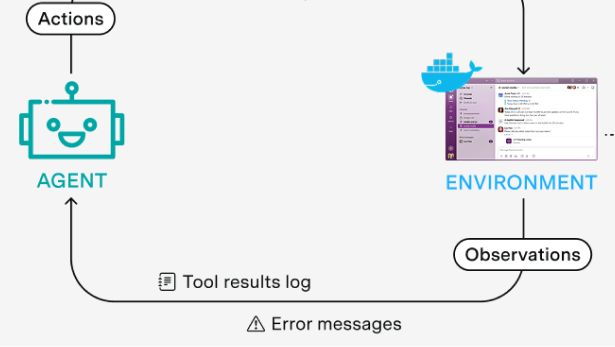
We interviewed 18 people across RL environment startups, neolabs, and frontier labs about the state of the field and where it's headed.
The existing debate rests on data and assumptions that are shakier than most people realize. To make progress, we need better evidence, and experiments are the best way to get it on the margin.
OpenAI focused on scaling post-training on a smaller model
Many multi-agent setups are based on fancy prompts, but this is unlikely to persist
Reasoning models were as big of an improvement as the Transformer, at least on some benchmarks
This week's issue is a guest post by Henry Josephson, who is a research manager at UChicago's XLab and an AI governance intern at Google DeepMind.
Available evidence suggests that rapid growth in reasoning training can continue for a year or so.
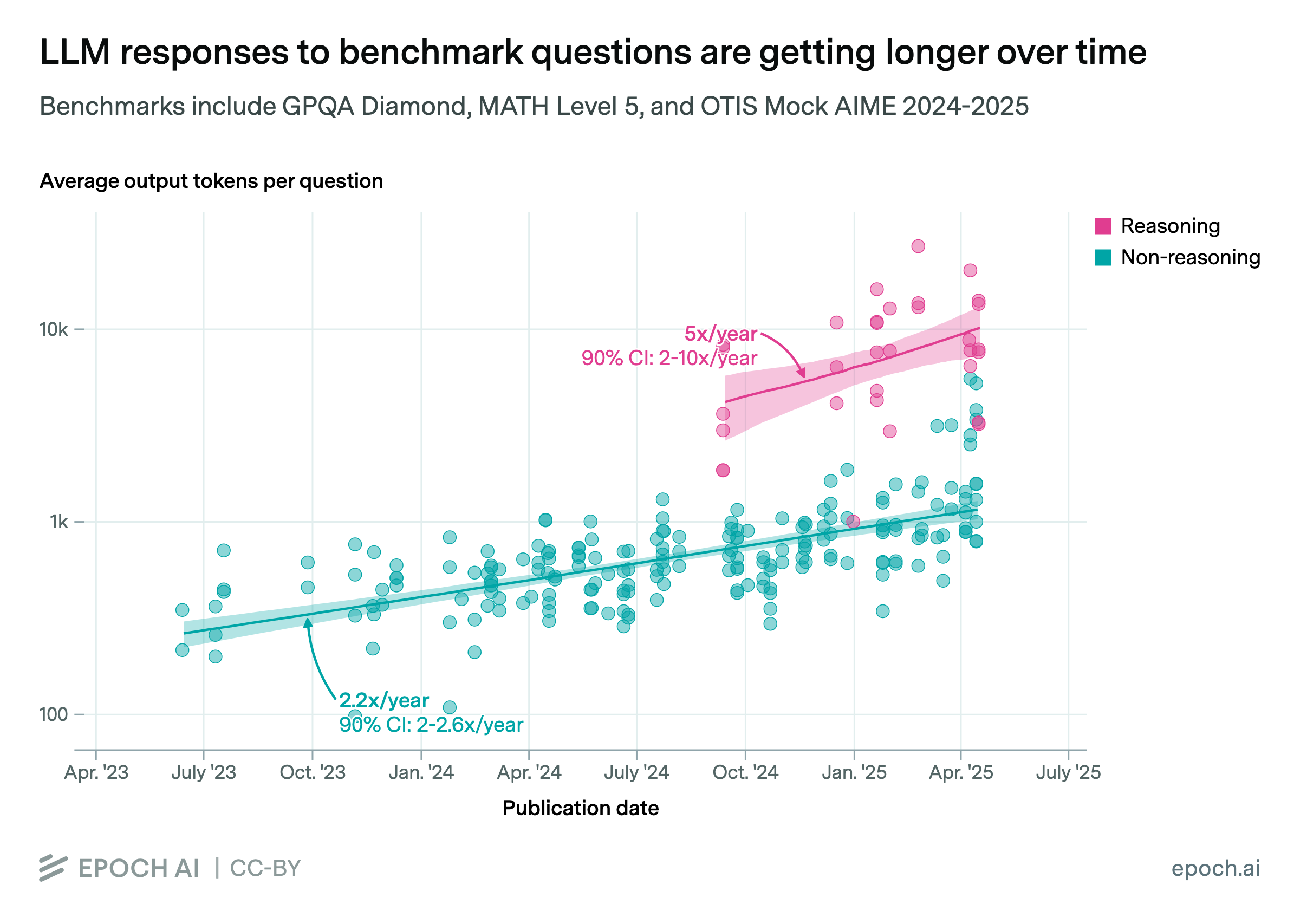
AI reasoning models will achieve superhuman performance in math and coding, yet their economic applications will lag behind, limiting real-world impact.
Algorithmic progress in AI may not reduce compute spending—instead, it could drive higher investment as efficiency unlocks new opportunities.
This Gradient Updates issue explores DeepSeek-R1's architecture, training cost, and pricing, showing how it rivals OpenAI's o1 at 30x lower cost.
This Gradient Updates issue goes over the major changes that went into DeepSeek's most recent model.

Epoch AI presents their first podcast, exploring AI scaling trends, discussing power demands, chip production, data needs, and how continued progress could transform labor markets and potentially accelerate global economic growth to unprecedented levels.
This Gradient Updates issue explores how mixture-of-experts models compare to dense models in inference, focusing on costs, efficiency, and decoding dynamics.
In this Gradient Updates weekly issue, Ege discusses how frontier language models have unexpectedly reversed course on scaling, with current models an order of magnitude smaller than GPT-4.
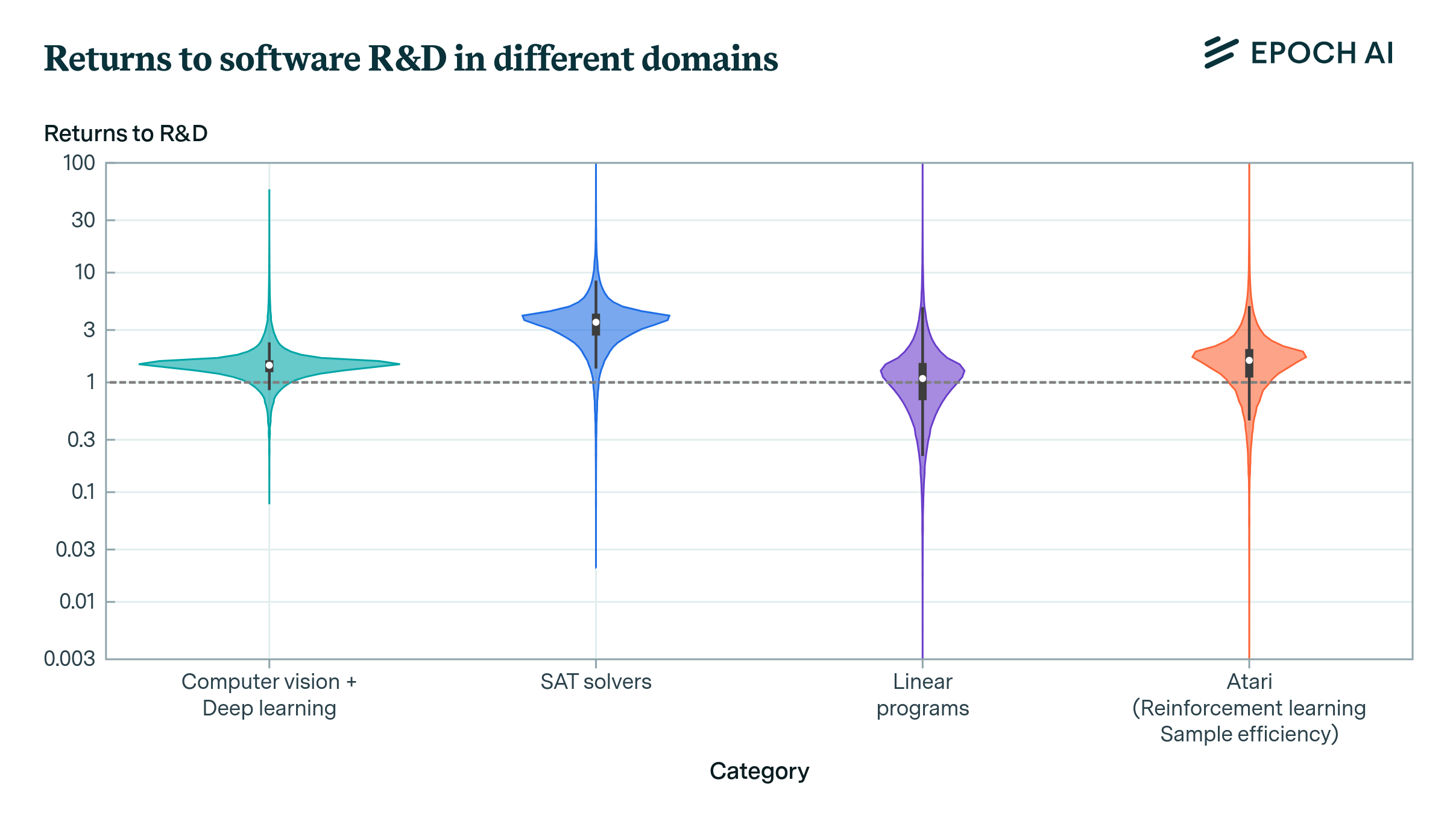
The returns to R&D are crucial in determining the dynamics of growth and potentially the pace of AI development. Our new paper offers new empirical techniques and estimates for this crucial parameter.
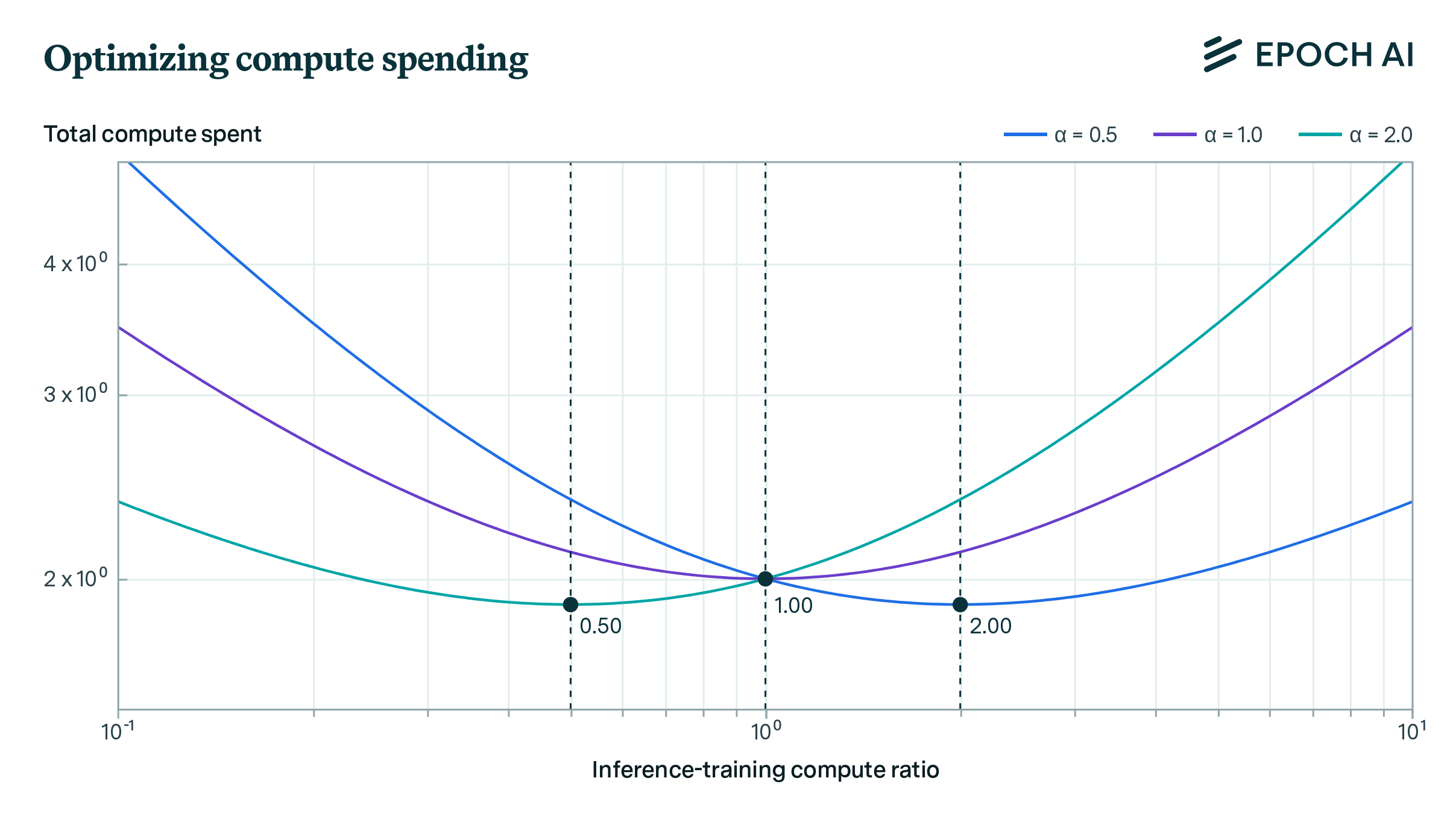
Our analysis indicates that AI labs should spend comparable resources on training and running inference, assuming they can flexibly balance compute between these tasks to maintain model performance.
Progress in pretrained language model performance surpasses what we’d expect from merely increasing computing resources, occurring at a pace equivalent to doubling computational power every 5 to 14 months.
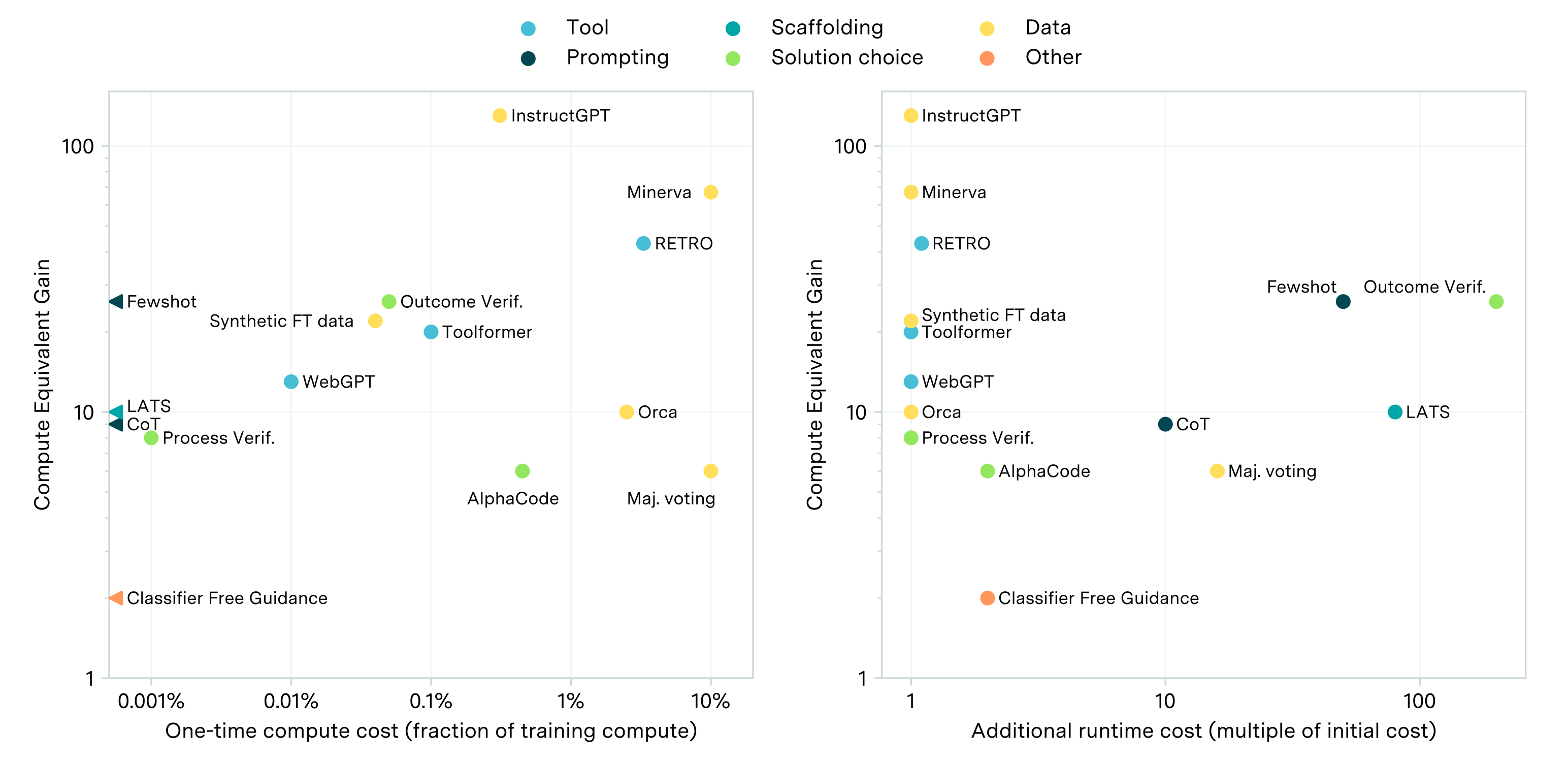
While scaling compute for training is key to improving LLM performance, some post-training enhancements can offer gains equivalent to training with 5 to 20x more compute at less than 1% the cost.
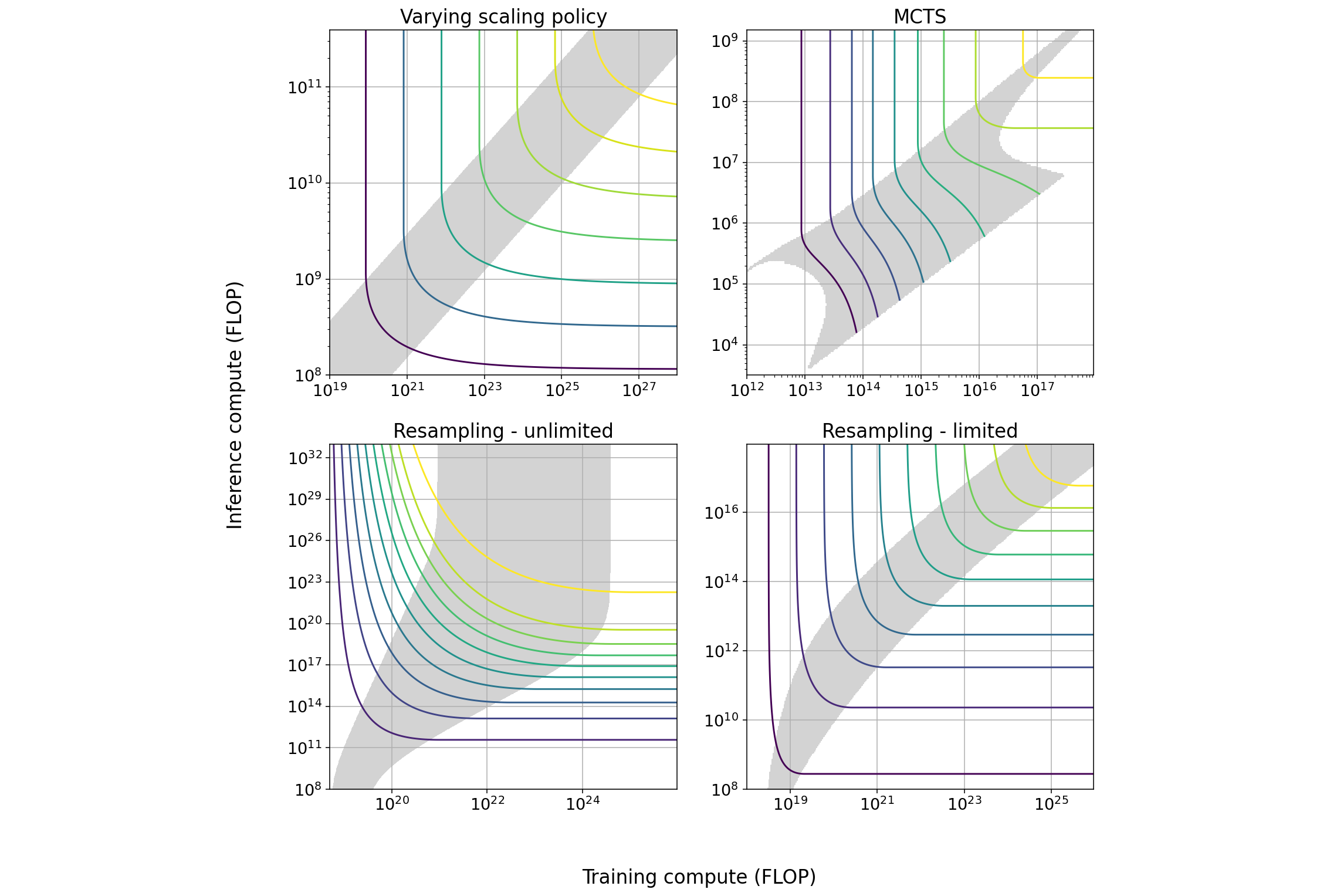
We explore several techniques that induce a tradeoff between spending more resources on training or on inference and characterize the properties of this tradeoff. We outline some implications for AI governance.
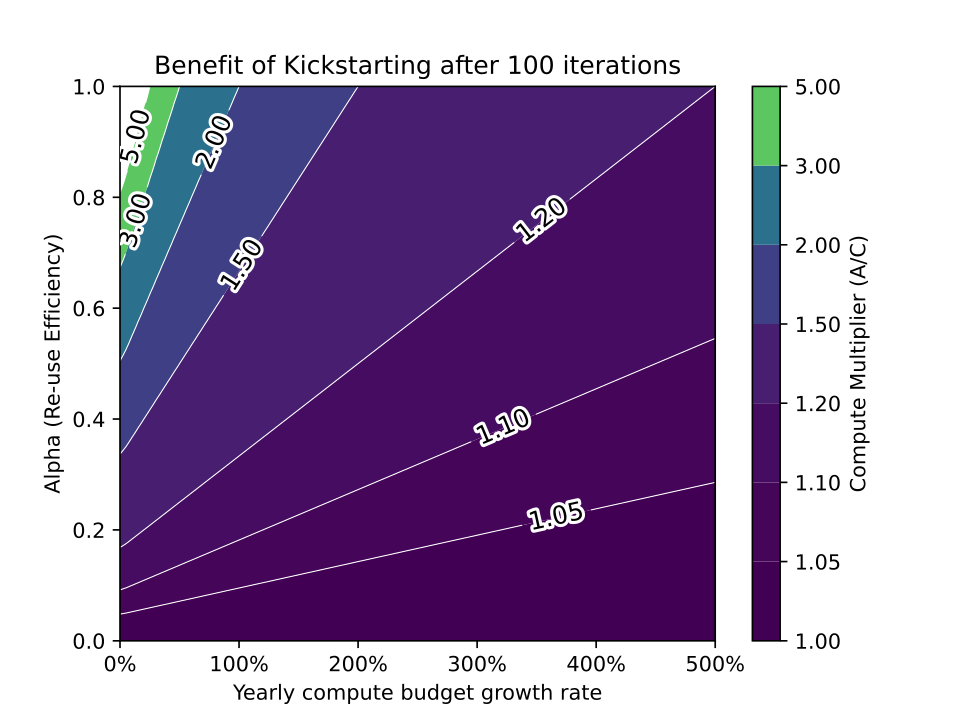
While reusing pretrained models often saves training costs on large training runs, it is unlikely that model recycling will result in more than a modest increase in AI capabilities.
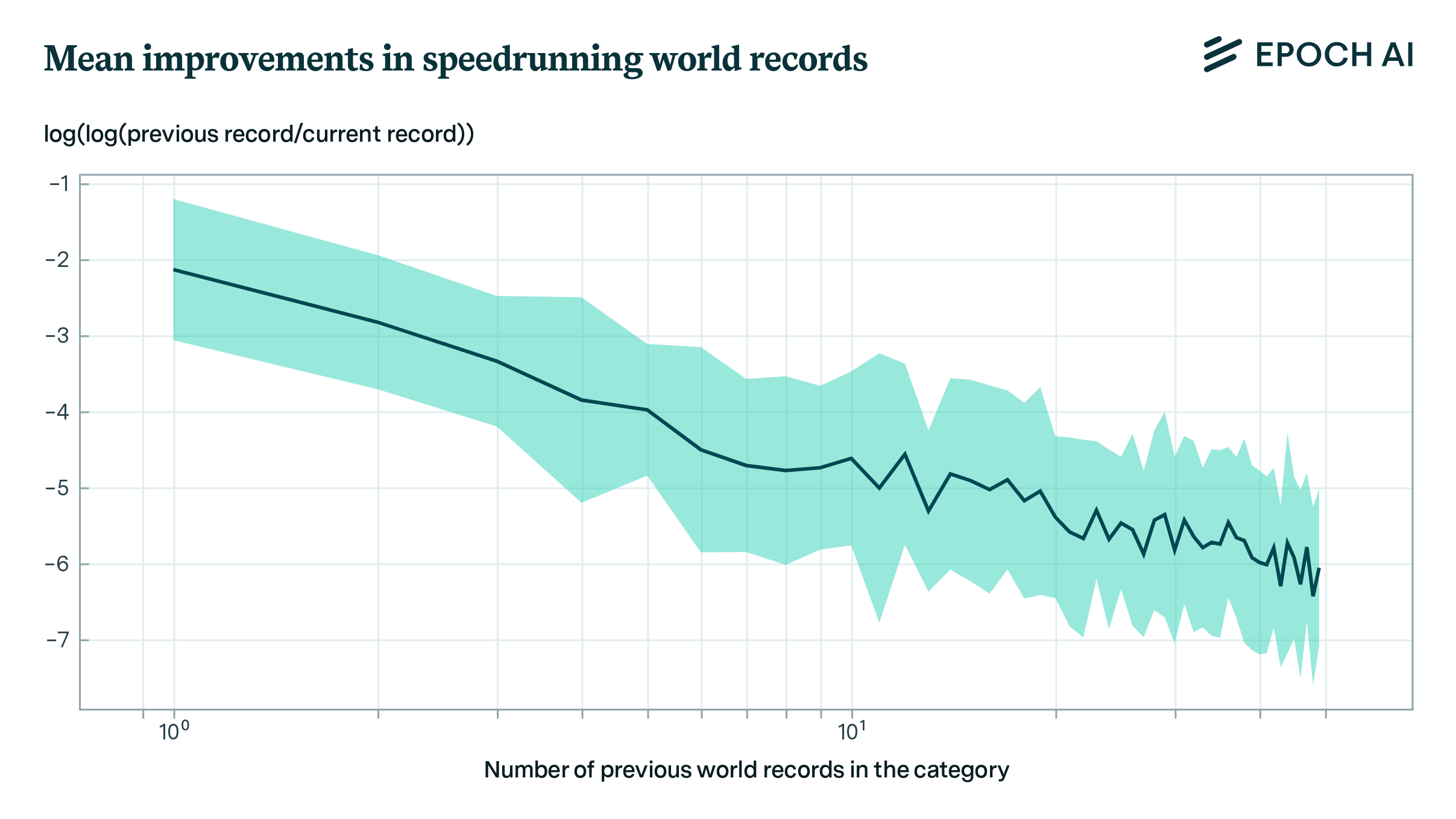
We develop a model for predicting record improvements in video game speedrunning and apply it to predicting machine learning benchmarks. This model suggests that machine learning benchmarks are not close to saturation, and that large sudden improvements are infrequent, but not ruled out.
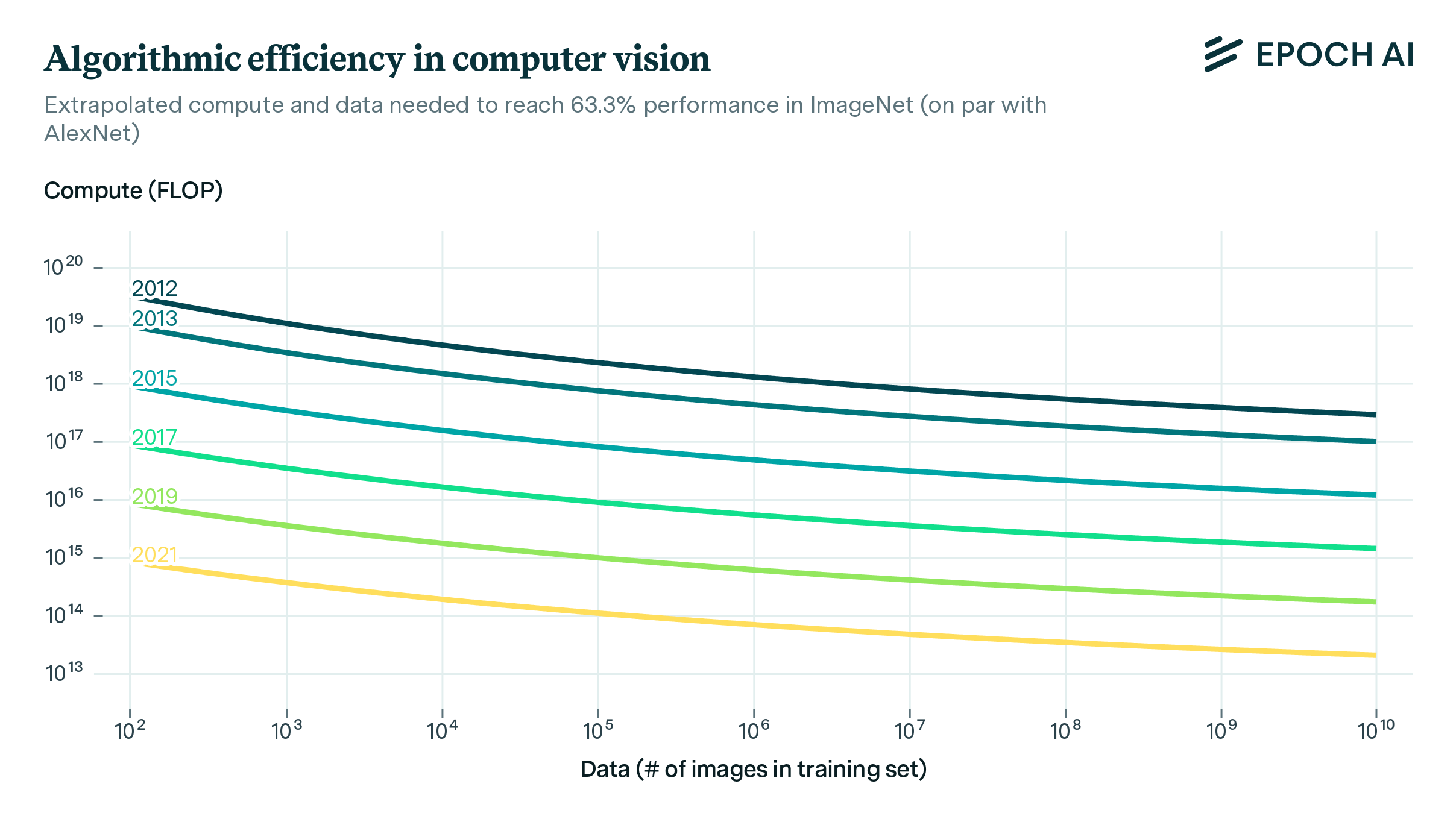
We use a dataset of over a hundred computer vision models from the last decade to investigate how better algorithms and architectures have enabled researchers to use compute and data more efficiently. We find that every 9 months, the introduction of better algorithms contribute the equivalent of a doubling of compute budgets.
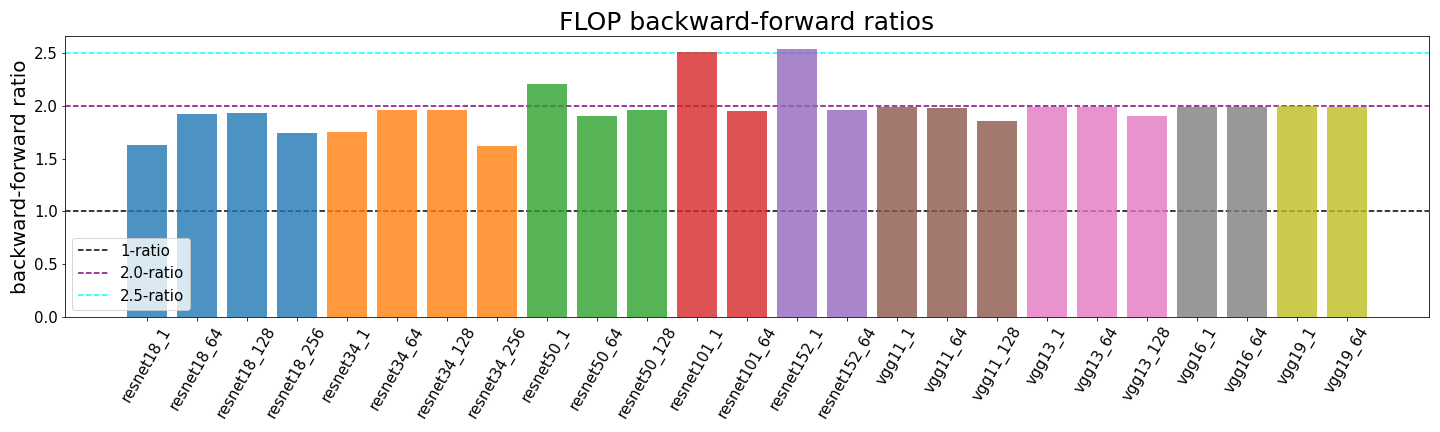
Determining the backward-forward FLOP ratio for neural networks, to help calculate their total training compute.