For decades, Moore’s Law has dictated the relentless march of computing power, shaping our technological landscape. We’ve grown accustomed to exponential progress, to gadgets shrinking and capabilities expanding at a predictable pace. But what happens if we take seriously the continuation of recent trends showing rapid progress in the capabilities of AI?
That is the central question explored by Epoch AI, where we are dedicated to rigorously mapping the trends in artificial intelligence. In this inaugural podcast recording for the organization, Jaime Sevilla, Tamay Besiroglu, and Ege Erdil discuss the plausibility and wide-reaching implications of a world where AI scaling continues through 2030. They delve into the drivers of AI progress, the bottlenecks hindering its advance, and some of the potential economic and societal implications of a truly intelligent, automated future.
The hosts discuss:
- The surprisingly predictable “straight lines” governing AI development and what they reveal about the field’s trajectory
- Why a 10,000-fold increase in the compute used to train frontier AI is feasible by the end of the decade, despite the challenges of sourcing enormous amounts of power, chips, and data
- Technical constraints that might eventually limit scaling, including latency, hardware failure rates, and non-accumulable resources
- The counterintuitive insights from Moravec’s paradox, and why AI mastered chess long before walking
- Why economists are underestimating the possibility of extraordinarily fast growth driven by AI automation
- The profound implications for labor markets, human augmentation, and wealth distribution in a world where AI capabilities exceed human capabilities
Whether you’re an AI researcher, economist, or simply curious about the future, this podcast provides a rigorous perspective on the transformative potential of artificial intelligence and what it might mean for the world we live in.
Transcript
Intro
Jaime
We are saying that by the end of the decade, we’re expecting this 10,000 times increase in compute.
Ege
When Moore proposed this law in the 1960s was it really obvious that that line would continue? It’s been continuing ever since. The world is so complicated. There are all these different forces at play. So how come all these somehow average out into just a straight line?
Tamay
We had dinner with a development economist, and we’re telling him about, we think it’s plausible that we could get a 10 x increase in the growth rate, 30% per year. And then he responded, you mean 30% per decade? No. No. No. 30% per year.
What is Epoch AI?
Tamay
So we’ve been working on understanding trends in AI, and I’m curious what your kind of vision is for our work about these trends in AI.
Jaime
So think about Moore’s Law. Moore’s Law is, this empirical regularity that was observed about how performance in semiconductors was increasing year after year. That was hugely influential in determining the direction of technological fields. People were able to plan various years ahead of this technology’s existence because they had this expectation that GPUs or CPUs were gonna get so much better. We’re doing the same, but for AI, both on the input side and on the output side. We’re mapping this trend or the resources that you need to develop these AI technologies. And also now trying to understand what this AI is gonna be able to achieve in the future.
Tamay
So I think we’ve had quite some success with the work we’ve done recently. I’m curious to go back and talk about how we started Epoch and what we were thinking when we started the organization. On the one hand, you had people very carefully studying what seemed to me fairly parochial questions in academia. On the other hand, you had people thinking about the very big picture, but doing it very not rigorously, and very by analogy, thinking about evolution, or thinking about the human brain, or just what is possible in theory. Maybe doing like a bunch of advanced math and trying to figure stuff out from there.
But I totally kind of agree that the thing that I was really excited about was trying to do this very rigorously and carefully, and actually looking at the existing research and try to see if we can extract information from there or build our own frameworks for kind of carefully thinking through these results. And some of the scaling law work I see as being really quite instrumental in building up this framework that we currently have for thinking about kind of advanced AI and development of AI.
Scaling Laws
Jaime
So I think we should talk about what we mean by scaling laws. Maybe, Ege, you wanna take this one?
Ege
Sure. I mean, even going back to what you said, I think the idea people had about AI, maybe with a few exceptions, was heavily focused on software and coming up with better algorithms, better methods to try to match or exceed the performance of human brains. But if you make your focus algorithms, then it’s actually quite difficult to argue that that’s gonna be a thing that’s gonna scale predictably or smoothly, or you’re going to be able to say something about what AI is going to be capable of in 15 or 20 years. You would go and ask people, okay. So when are we going to get computer systems that can match the performance of humans in vision?
When will computer systems be able to look at the scene and pick out what are the objects in this scene? And people didn’t really have a good methodology for answering this question.
Tamay
There were surveys and people asked researchers how much progress has been made and extrapolated that, but I think that felt really unsatisfactory.
Ege
Yes. And, the precursor for this work was done by, I guess, maybe Moravec and Kurzweil. They were not, like, rigorous by our current standards at all. I wanna emphasize this. It was a very preliminary kind of work, but they were the only people I think who in the second half of the 20th century, let’s say, were on the ball on this.
And they said, it’s not really so much about algorithms. It’s about how much resources you have that you’re putting into the algorithms. And the two important resources here are for the first one is how much computational power you’re throwing at the problem. And the second one is how much data you’re throwing at the problem. And initially they were more focused on the computational power side.
They pointed out and Moravec has some early estimates where he tries to look into how much computation the human visual cortex is doing. And the numbers he comes up with are so much larger than the computers which people had access to in the nineteen seventies or eighties. So he made the point, well, it’s not really that surprising that our performance is extremely underwhelming compared to what humans are capable of. We think a lot of what we do is very easy because it’s just so intuitive as we just do it like that. But, actually the brain is a very sophisticated advanced computer and it hides a lot of this complexity from us.
And Moravec predicted based on Moore’s Law that you mentioned earlier, he just drew that line and he said, when are we going to get to a point when consumer hardware can actually match the amount of performance in the human visual cortex. He was just looking at the computational side of things. And he came up with a date of between 2010 and 2020.
Jaime
Again, a straight line. It feels like this is the recipe for success. You figure out what is the straight line that matters and you collect the data and just extrapolate.
Ege
I think the important thing here is that it is really kind of surprising coming from a prior point of view that the world turns out to be so regular that it is actually well described by straight lines. That’s not at all obvious. And, like, when Moore proposed this law in the 1960s was it really obvious that that line would continue at least until 2006 and, depending on how you adjust it after that, it’s been continuing ever since. Right? That’s actually quite a surprising thing. And I think people find it counterintuitive. The world is so complicated. There are all these different forces at play. So how come all of these somehow average out into just a straight line?
I don’t really have a good answer to this question, but the fact that it seems to happen so often and it happens also in AI is really what gives us most of our traction. And I think when people were thinking of thinking about AI in informal terms, well, you can’t draw straight lines when you’re thinking informally. You have to think quantitatively.
Jaime
What are the lines when we think about it? What’s your bet for? What are the most important lines that we ought to be tracking?
Tamay
I mean, I think the one that we’ve been tracking from the start is really training compute, and training compute has been hugely influential for shaping the capabilities and both the depth and breadth of the capabilities of AI systems. You know, we have some work where we try to decompose the sources of progress and the capabilities of LLMs, of vision models. And for those, we find that the majority, over 50% of the variation in performance is due to pure scaling pre-training compute. And then the other components are scaling and improving the datasets, improving architectures, improving algorithms, the implementations of those algorithms on hardware. So I think the most important for a long time has been pre-training compute.
Now I think the other trend that we’ve been tracking, actually we’ve been tracking this for at least 2 years now, is inference compute. There are scaling laws for the gains from inference compute, which started out with the Andy Jones paper on the game of hex. And once we saw that paper, we got pretty excited about idea of scaling inference compute, not just for game playing systems, but more broadly. And we’ve been thinking about that, as well as an important driver.
Key Drivers
Jaime
Alright. So artificial intelligence is achieving more and more in recent years. We now have AI that you can talk to, that can solve math problems for you, that can code for you. I think what we need to talk about is, what has been driving this? What are the reasons why artificial intelligence has been getting better? What are your the main highlights?
Tamay
So I think the key drivers have been the scaling up of compute, mostly in pre-training, but increasingly also for running inference.
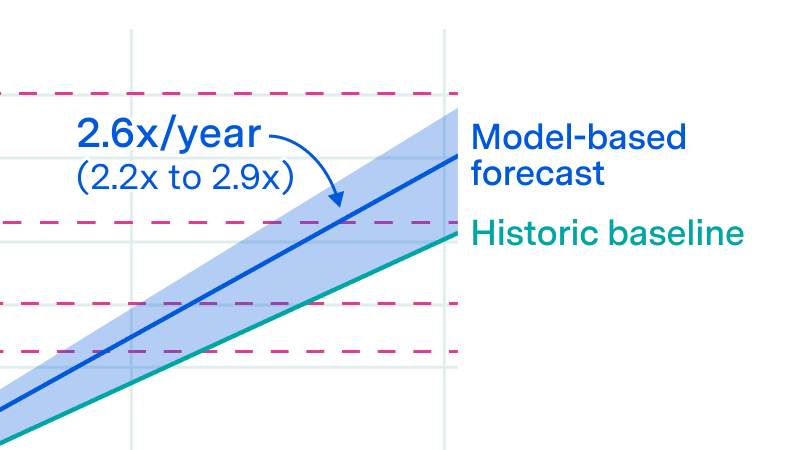
So we did this kind of inaugural project for Epoch where we tried to study the scaling of pre-training compute. And there we saw that since the start of the field of AI about, 1950 to roughly the kind of inception of the deep learning paradigm, we saw a scaling up of the pre-training compute of the compute used to train these systems that at a rate that, is roughly in line with Moore’s Law. So doubling every 18 months to 24 months or something. And since then, we saw an acceleration. So since the inception of deep learning, we saw this acceleration of training compute increasing roughly 4 or 5 times per year.
And this we have found in a kind of later work on language models and in vision models has explained perhaps the majority of the performance improvements in both the kind of breadth of capabilities and depth of capabilities for vision and language models. The other important components have been algorithmic progress. So, these are innovations in architecture, the development of the transformer, for example ideas about how to scale your compute, your model.
Jaime
Could you include data quality also in algorithmic improvements?
Tamay
Yep. So data quality has been a huge driver precisely how to quantify this or precisely how to classify this is a little unclear because I think in large part this has been kind of ideas about how to generate, filter, what techniques you apply and bring to bear to producing a really great training dataset, that you can think of as algorithmic, kind of innovations.
Jaime
Yeah. I feel like I’m a bit there with you here. Like, people have been talking for a bit about the 3 important things to think about when you think about AI is: compute, data and algorithms. But I think it’s right. And I think that what we have been able to do at Epoch is actually, we would rigorously show to which degree, this is correct.
Tamay
And you can go even more deeply into this breakdown and decompose pre-training compute into better chips, more spending on bigger clusters, longer training runs, and we’ve been kind of delving into this decomposition even more finely.
Jaime
Okay. So there’s this four factor, right, that is pre-training compute, inference compute, data, and algorithms. If I ask you to do it right now, a split of which percentage of success of AI in recent years is due to each of these components, how would you describe it?
Tamay
Yeah. So I think pre-training compute is probably close to 50% or something. And then the algorithms and data quality has been the remaining 50%. You can kind of break that down even more. I think in particular data quality has been, perhaps a really big part of, everything that’s not explained by scaling up, the compute and the size of models and so on.So data quality has been very important. And the post training kind of enhancement. So fine tuning, supervised fine tuning on instruction data, or fine tuning and post training on a very high quality kind of coding or math problem examples, and making the model really great at solving problems of the sort that end users face when they want to use the model. I think that’s been a pretty important component too.
Jaime
Yeah. And chain of thought, which links into this notion of inference compute. If you let the model think for longer, they are able to solve more problems. This is a, now it feels almost intuitive, but it feels like we really were ahead of the curve in having this notion internalized at Epoch.
Tamay
Yeah. I think in our inference training compute trade off report that we wrote, we made this claim that it seems likely to us that you can scale up the inference compute of large language models. And by the way, this was before people were rigorously doing this. I think this was round about the time that the chain of thought paper came out. We said that it seemed plausible or likely to us that you can scale up inference compute by 2 orders of magnitude and get the equivalent performance gain of scaling up your pre-training compute by some say one order of magnitude.
And I think, say the release of o1 has really validated that point.
Jaime
That’s right.
Ege
I guess one thing another thing I would point out is that the basic picture of compute data and algorithms. I think if you took that picture back to the nineteen eighties or nineties, I don’t think people would have really disagreed with you. And I think the important surprise maybe is that the older parts of this equation, meaning most importantly the algorithms part, I think that that was the part people really had serious doubts about. Also, basically turns out to grow smoothly and relatively predictably. This is not just the case in AI.I think it’s a broader fact.
Tamay
Just to clarify, you mean algorithms are getting better at a very predictable rate?
Ege
Yes. You can imagine a world in which for 10 years, there’s very little lab work in progress. And then in 1 year, some team or some lab makes a critical discovery and then suddenly models that are 100 times more efficient. But actually the picture we see more is that, algorithm progress is a very similar kind of pattern to Moore’s Law, where every year we see, say, halving a little bit more than halving of compute requirements to reach a fixed level of performance. And I think if you pointed this out, I think if you told this to people 20, 30 years ago, they would be quite surprised. This is not, I think, a result that they would have expected.
Jaime
How convinced are we about the smoothness? I wanna inquire your intuitions here.
Tamay
Yeah. We did some work about understanding the distribution of different innovations and, what is the, how kind of fat tailed is this distribution? And we did some work on improvements in performance in say vision models and other models. And there we find that, there’s this power law where most of your innovations are driven by kind of smaller innovations that are kind of more marginal. And then there are occasional, big insights that do push the field forwards.
I think averaging over a year’s worth of innovation, each year gives you a fairly predictable or fairly regular, gives you a fairly smooth curve. I think that seems basically right to me. So I would expect, within a factor of 2 or something, the slope being broadly accurate of the field if you average overall , what all the top labs are doing, I think this you can get within a factor of 2 of this kind of overall slope.
Jaime
Okay. So, I think one thing that, obviously comes to mind here is that how do we reconcile this with the fact that, AI architectures, the ones that we know about that have been conducted at larger scale, for example, the ones from Meta are quite open, the training process, they’re quite similar to what was being done to train, GPT-2 for example. How do we reconcile this with us expecting this smooth trend of improvements?
Ege
Well, I would say that architecture is just a very small part of what goes into the even purely in software terms, what goes into a modern system. In fact, the fact that Meta and also many other people are willing to release the weights of their model and, of course, also the architecture because you need that to be able to interpret the weights. But they’re not willing to share any information about the details of the training process. Things like how did they initialize their weights? Which learning rate decay schedule did they use? Where did they get their data from? What I mean, they will sometimes say we have trained on 15 trillion tokens. Okay. What are these tokens? Where did they come from? How do you filter them? They just don’t share this information.
And I think really a lot of the gains are hidden in these points. Another one is the developments in the scaling law literature itself, which has shown that previously people were seriously under training their models, which means that they were giving the models far fewer data than the models actually could use to improve their performance. And this was essentially a suboptimal allocation because you can use a greater compute budget to either have a bigger model or have more data. And, these scaling law improvements help us better optimize this allocation. This was another substantial gain in efficiency and none of these are really about the architecture use.
There are some minor improvements in architecture. Maybe you could say that the better embeddings that Meta uses are an improvement. Maybe you could say that grouped retention is an improvement over the initial transformer published 2017. But I think these are really fairly minor improvements. I think that most of the gains are coming from the other facts
Tamay
I also think there’s just a kind of a long tail of very many things. I think people like to say, when’s the next transformer gonna be invented, but I think, this emphasis on just these small big things, these kind of big sexy breakthroughs, kind of belies the fact that many of these improvements are due to just very many small things. That would be my guess as to how we are making so far progress.
Jaime
I’m really very excited to track this better. I really think we should just do that.
Ege
Oh, yeah. I agree. Tracking this better would be exciting. I do think though that’s like if you just compare the architectures, there isn’t enough small things that are different to explain the differences we see. Like, there really has to be something else. Yeah. A lot of other things, in the background, and I think there are.
End of the Decade Predictions
Jaime
So I think, and I believe you two will agree with me that despite all the bottlenecks ahead and the challenges ahead on getting the necessary power, getting the necessary GPUs, that we should be able to keep up with the rate of scaling we have had until the end of the decade. And that’s like 10000x times more compute than what was used to train GPT-4 . And that’s a massive gap in performance. Like to to put this into scale, GPT 4 was 10,000 times more compute than what was used to train GPT-2 . So, that same jump is what we are by default expecting by the end of the decade.
Tamay
How confident are you in this? So, specifically the claim that we’ll be able to keep up this 4 x per year that produces 10,000 fold, increase in scale. Are you 50% sure? Are you more than that, less than that?
Jaime
If there is the willingness to do it, I think I’m pretty confident that you can. So the 2 biggest bottlenecks that we found is, can you get enough power, and can you get enough GPUs? And, the power question is an important one, but that people already have identified as an important problem and that they’re already working out a solution for. And there is precedent for, a large scale up of, power production in the US and, in other economies. So, I think that people will just rise to a challenge. It might take a bit of preparation and a lot of money, but they will be able to do that. With GPUs, it’s a bit harder to scale since, like, GPU production is so concentrated. But, when we did this investigation, we roughly found out, well, if TSMC keeps expanding its production at the rate that they have historically and the rate that they expect to expand in the future, that should be enough to meet that demand. Is that right?
Bottlenecks: Power
Tamay
Yeah. That’s right. So maybe let’s get into the power component first. Yeah. So, where are we? How much power do training runs currently use? And at what rate is this growing, and what is determining, how much, we should expect the energy needs to escalate?
Jaime
So in order to train models of the class of GPT-4 or Llama 3, you will need between 15 to 30 megawatts of power. To put this in context, 30 megawatts of power is, not exactly, but roughly equal to consumption of 30,000 households in the US. Now, we’re saying that by the end of the decade, we’re expecting this 10,000 times increase in compute. That doesn’t match exactly much with an increase in the amount of power that you need for training. There’s some mitigating factors. Mainly that, we expect it to be more power efficient in the future, and also that people will train for longer. So if you train for longer, you need less immediate intake of energy at a single point. So if we combine all of that, roughly, the picture that we expect kind of by default, this is like the default extrapolation with trends continuing, is that we should expect an increase in the power you use for training of a factor of 200, 250 or so. And that’s still quite a lot.
Tamay
By the end of this decade.
Jaime
By the end of the decade, like a 200x increase. So that puts you in the range you’re gonna need for power, let’s say 5 to 15 gigawatts of power which is a lot. That’s more than the output of a single typical nuclear power plant. Though, it is also not a lot in the sense of, if you look at annual production of energy in the US, this will still be only a small percentage. So now there’s the question of will companies rise to the challenge? Will they be able to expand data center capacity, to the rate that is needed in order to keep up? And, what we did was, doing this very basic extrapolation of just looking at both historical rates of expansion of power in data centers. And also we looked at the plans of the power providers. And, even just taking the baseline, it looks fairly reasonable to do training runs of the scale that will be on trend by the end of the decade.
Tamay
So one constraint that, is quite important here is that if you have, a training run that happens within a single data center or within a single campus of multiple data centers, but geographically together, then you have to source that that power from either a single grid or maybe a single power plant. And, as you said, there are a few power plants that are of the scale to be able to power, to be able to give you enough electricity to run 10,000,000 GPUs or what have you. So we’ve been thinking about geographically distributed training, which enables you to tap into the energy infrastructure across the country in the US, which then enables you to pull together these very many distributed resources and power plants. So can you say more about how that might enable us to source the energy we need?
Jaime
That’s right. So a 5 gigawatt data center, at my best guess it is possible. There’s definitely some rumors going around of people wanting to aim for that scale, but it is stretching it. There’s no precedent of facilities that have that level of power consumption. I think the biggest smelters on earth have a consumption of 2 gigawatts or so. Distributed training is this very appealing alternative if they are not able to fulfill the stream of giant, 10 gigabyte scale data centers. Because then as you’re saying okay, I just have many data centers, each of them is drawing power from a different source. Then that relaxes this constraint of where you get your power significantly and makes it so much more affordable and so much easier to coordinate. But now, the question is, if you split your training across multiple data centers, can you do this? What are the fundamental reasons you might not be able to do this? I think there’s 2 main constraints that you need to consider here, which are bandwidth and latency. Now bandwidth is not really a constraint in the sense of the solution, if you are lacking bandwidth between the data campuses, it’s like you just build more fiber optic. You just increase the bandwidth. The amount that right now, people are spending on connecting data centers, it’s a very small fraction of what you spend on the GPUs and the supporting hardware itself. To put this in context, I believe that the fiber optic that goes through the Atlantic ocean costs a $100 million dollars to set up.
Tamay
The idea here is then if you’re spending $10 billion or $100 billion on your clusters, then what is a couple $100 million to be able to connect these and and actually orchestrate your training run. I think that seems to kinda match my sense that conditional on actually scaling this so far, the amount of resources that companies would be willing to expend are going to not be a huge challenge or upset to their ambitions.
Jaime
That’s right. And, then this other question is about whether latency is gonna allow you to do the training. Because the training, at least how we do it right now, is kind of like this sequential processing. It’s like you process a batch of data, then you update the model, and then you use this updated model to process a new batch of data. But here, we just did the calculation for, okay, what if we have data centers on different coasts in the US? And, it seems like the latencies are manageable. So, they will then stop scaling at least until the end of the decade on current trends. But now power is not the only bottleneck. I mean, in a sense, it’s like the most malleable bottleneck.
Bottlenecks: GPU Production
Jaime
So really, I think that, what we need to figure out is, will we have enough GPUs? And what’s your take here Tamay?
Tamay
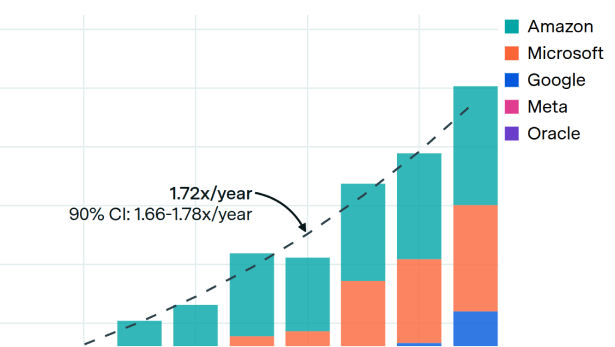
So again, if you think that AI is as powerful a force as we think and as valuable economically, then there should be a lot of effort going into relaxing this constraint and producing enough GPUs to power the training runs. So I think TSMC, if they receive enough advanced orders and companies and these hyperscalers are able to convince and signal to TSMC that they’re actually willing to pay for large scale-ups of their GPU production. Then TSMC, I expect, will be kind of willing to expand its advanced packaging capacity to be able to turn the silicon into advanced data center GPUs. They’re already kind of expanding this pretty rapidly. They’re building new fabs for packaging, to support this increased demand. I think there’s been some foot dragging by TSMC, where they’re not fully convinced about the demand for data center GPUs. I think it’s possible that these hyperscalers are able to come together and actually commit to paying a bunch of money and placate, and give confidence to TSMC that the scale ups that they could invest in are actually worth investing in. And if there’s not enough convincing that happens, very soon, then we might not produce enough GPUs.
So I think the GPU bottleneck is indeed kind of a challenging one. I do expect, from what I’m hearing, the rumors that OpenAI and Microsoft are working together on building these $100 billion data centers for doing training. That is very much precisely the thing that we would predict if this trend continues. And there are rumors that people are actually already, planning for precisely this. And so I think this is quite plausible that it would in fact happen, but I do think there’s some chance that there isn’t enough convincing through this chain of lab to hyperscaler to fab, that happens not quite at the right time for this to actually go through.
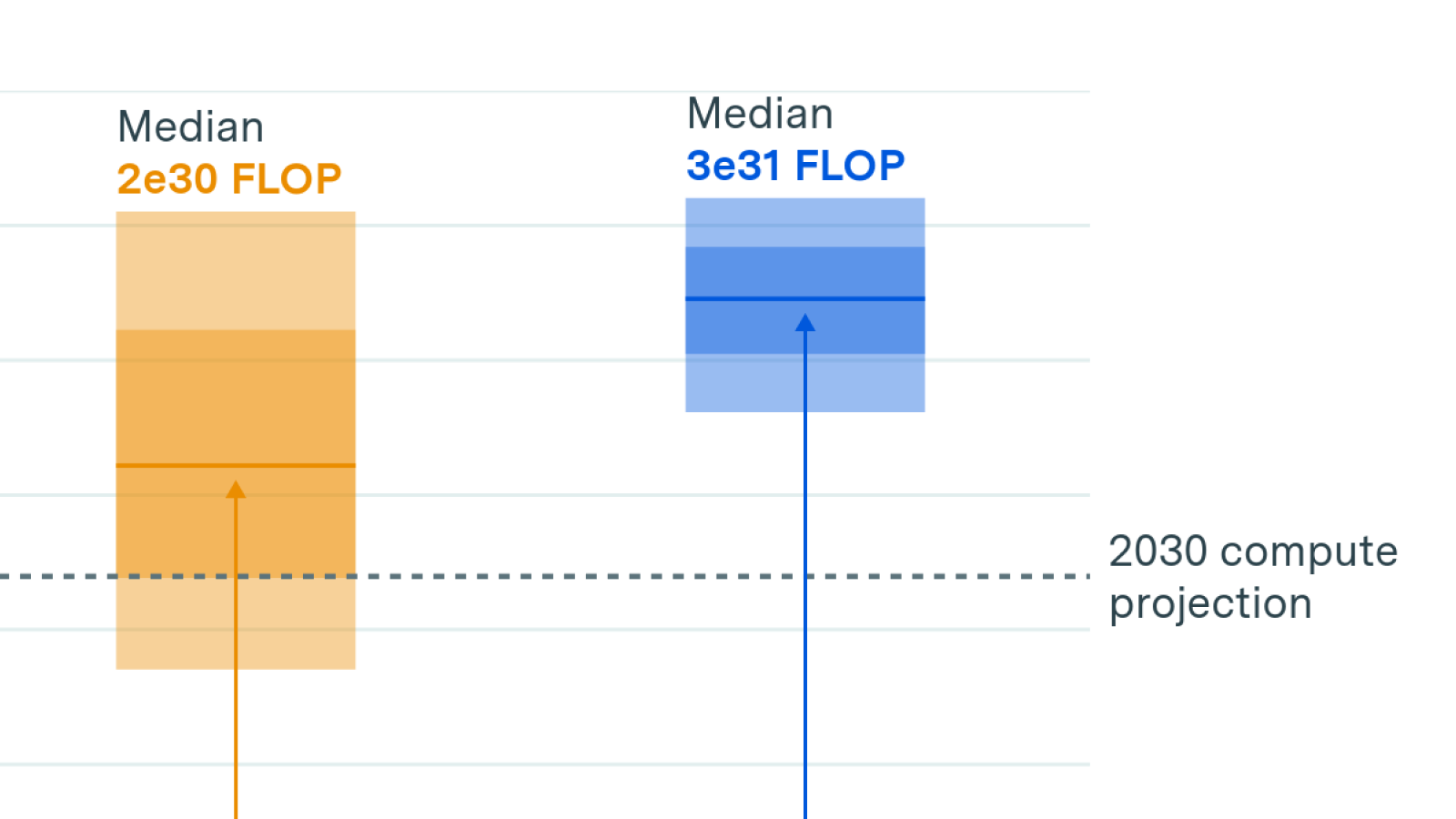
Jaime
Yeah. So I could put this into perspective. Right now, if we put all GPUs together on Earth, what would you be able to train? A model of 10e28 FLOP, or so or something of that scale. What you need is, that extra order of magnitude, that extra factor of 20, of GPUs to get to the scale that we need.
Tamay
I think it’s probably less than a factor of 20.
So, currently , there might be 4 million H100 equivalents that are scattered between labs and this is the production that TSMC has been able to achieve over the past couple years. And so there may be a factor of 10 or something that they should scale this up, and, unless you expect that there’s going to be this massive consolidation of resources. If there’s this massive consolidation, obviously they need to produce less, but I don’t expect that to happen. I think there’s going to be this kind of distribution across some of the 3 hyperscalers. And then there’s also going to be some allocation between inference and training. I think an order of magnitude scale up in production of TSMC is the thing that’s needed. I think in order to do this, they need to scale up their packaging and some of the other high bandwidth memory production. And, they’re as you said, they’re on trend with doing that. So if you read their annual reports, they will say that they’re scaling up, at a rate of about 30 to 60% per year, which would get you precisely the kind of order of magnitude increase by end of decade.
Bottlenecks: Data
Jaime
So we’re gonna have enough GPUs, we’re gonna have enough energy. I guess the other question people ask us is are we gonna have enough data? Are you gonna be able to train the models?
Tamay
So we’ve chatted about power and GPU production. And then there’s the data wall that people are often talking about. There’s Sam Altman tweeting tear down this data wall or whatever. We’ve been doing a bunch of thinking on this question, and we’ve done some of the early work, that we’ve been continually updating to contribute to this picture of where the data is. So Jaime, is this data wall real? Are we going to hit this data wall anytime soon?
Jaime
So let’s go back to the basics. Where are the companies getting the data that they’re training on? They’re getting it from the Internet. How much data do they need in order to train things like Llama 3? I think they were training in the order of 10 to 20 trillion words of content, which is a lot, but this is still only a fraction of what exists out there in the Internet.
Now not everything that’s out there in the Internet is gonna be good for you. Some of that content is just very low quality, and you’re not gonna be able to to train on this. Perhaps a way of thinking about how much more data are we gonna have out there is, primarily I expect that a lot of this data comes from efforts like common crawl that go through the Internet, gather a bunch of data, create an index that’s easy to crawl and filter for quality. And common crawl, our best estimate is that it only encompasses a 5th of the Internet or so. So, in theory, if you did more exhaustive crawling, you should be able to get 5 times more data, even if you still apply the quality filters that you want to make sure that you end up with data that is of high quality. And there is another wrinkle here, which is that at the moment, the state of the art on training is you train once on each data point because you’re not data limited. Right? So it’s better to just train on a more diverse dataset. But once you get to the point where you are really struggling to get more data, then what you might do is just train a few times on each data point during pre-training.
Tamay
I think some of the labs are already starting to train multiple epochs, especially on the very high quality stuff. There’s been this research on multi epoch training and there the picture is that you can train basically up to something like 10 epochs before you really start facing the diminishing returns of seeing the same data over and over again. Before then, it’s as if you have a fresh dataset. So you can multiply by a factor of, I don’t know, 4 or something relative to maybe the 2 epoch training that people are doing right now. And that gives you already a factor of 4 of the effective dataset size. And then maybe you can train for even another factor of 2 and still get some gains from that compute spend.
Jaime
Yeah. And take into account that the amount of compute that you use scales with the square of the amount of data that you have. So you don’t need that much more data in order to get to that 10,000 times larger model than GPT-4 in terms of compute. You just need 100 times more data. You might be able with text to almost get there, but you might struggle a little. So, right now, what we were saying is that you might get 4 or 5 times more data from just scrapping more exhaustively the Internet, and also 4, 5 times more data from training multiple times on each point. But that’s like a total 25x increase. And how do we get to the 100x increase? Right now, I think we have 2 main hypotheses of what you do here. One of them is you start training on modalities other than text and the other one is you train on synthetic data.
Tamay
Yeah. And multimodal training is just very useful. So you have OpenAI and others exploring multiple modalities for inputs and outputs. And, I think they’re finding a bunch of interesting use cases. I expect that those use cases will be sufficiently valuable to fold in a bunch of image, video, audio into the training data.
Jaime
Yeah. Just think about the Claude web browsing stuff. The web browsing stuff right now, one of the reasons why I think it’s not very good is because it doesn’t quite parse the screenshots that it’s being given.
Tamay
And the web browsing stuff you’re referring to is like taking control over the user’s computer, and then, performing some tasks, like troubleshooting your computer if you have an error message or something like that.
Jaime
That’s right. So multimodal training, I agree, It’s gonna be hugely useful. It’s something that the companies will want to do. And I think it might be reasonable to expect that if you train on other modalities, also your model is gonna get better. Here the evidence is a bit sketchier but I don’t know, it seems intuitively reasonable that by watching videos of people dropping objects and such, you might learn about physics and you might learn about how the world works in a way that you cannot from just reading text. I’m not super convinced by that, but I could say it as something that ends up working for this scaling. But then there’s the other question here which is synthetic data.
Tamay
Yeah. So synthetic data people are definitely quite bullish on it, at least for specific capabilities. So getting really good at writing good code, or solving math problems, or tool use.
So having the model generate a bunch of instances of good reasoning or good application of various techniques and then training the model on this dataset. I think people are using this quite a lot already, and there might be a more general sense in which you can use synthetic data to build these very basic representations just like pre-training does with the normal dataset that you get from the Internet.
Jaime
So here’s how I think about synthetic data and that makes me very bullish on this strategy overall. We know that it’s possible to distill models. It is possible to take a model that is quite large that has been trained on a bunch of data, make it produce data, and then you train a slightly smaller model on the outputs of this model and it learns to at least resemble the outputs of the larger model. And then on the other hand, you have this inferencing scaling where if you let models think for longer they produce higher quality stuff.
So this immediately creates this feedback loop where you get the models at the frontier, you use them to generate synthetic data, taking as long as they want. You use them to generate a 100 answers for each digital prompt, and then another model shifts to find the highest quality answer that it has produced. Or even better, in something like math, you check is this solution actually correct? And you use that higher quality dataset as the basis for your training and this is what allows you to train for longer.
Tamay
Yep. There’s this general principle that often verification is easier than generation. And this is especially true for math and for programming, where you can do unit tests and then you can generate a bunch of candidate examples and then use this verification, or you check the quality, and you filter out the low quality stuff and use the very high quality examples as training data. And so this suggests a way of spending compute and turning compute into data. And so if you’re going to be data constrained, but you have enough compute, then this suggests that you can balance those by just using your compute and translating that into more examples to train on.
Jaime
We know that this is already happening for post training. Meta was quite transparent. Like we train one version of our model on core data, and then we use it to generate synthetic examples of more core data that we could continue training on. I think is this gonna be useful also for pretraining? I think that, yes.
And I kind of suspect that already within OpenAI and these large labs, there’s already a fraction of their compute that’s a non-negligible fraction being dedicated to generating synthetic data.
Tamay
Yeah. I mean synthetic data is already feeding into pretraining data just by virtue of a bunch of a bunch of AIs output ending up on the Internet and they’re producing, OpenAI is producing 10 or a 100 billion words per year that ends up on the Internet.
Ege
I guess I would raise one concern here, which is that if synthetic data only allows you to match the quality of the existing high quality data distribution, then you have this problem that’s generating a lot of synthetic data. Usually training on a single token takes about 3 times as much compute as generating a single token. But if you want to get high quality synthetic data, you’re going to have to generate a lot of tokens for each token that actually ends up in the training dataset. And that’s going to mean that actually most of your compute is gonna be spent on generating the data and not training on it. In fact, this is what has happened with past approaches that trained the model basically on synthetic data. Maybe the biggest one is the line of work that came out of AlphaGo, where it took about a 100 times as much compute to generate the data that the models were later trained. So this might be a problem. But on the other hand, I think there’s a reason to expect synthetic data to be much higher quality than data you just find randomly on the internet even if you have filtered that data for quality. And I think one reason is, if you think about how humans learn to do tasks, there are some tasks, some things you can learn just by reading or watching other people’s text or actions or whatever, but actually for a lot of more complex tasks, for instance, if you want to be a good chess player, if you want to be a good Go player, if you want to be a good programmer, you can name a lot of other things of this nature, it’s not really enough to watch other people do the task, even if you do that a lot. But, if you practice yourself, you get a lot more gain out of that data, it seems, than you just get from watching other people. So there’s a hope here that synthetic data ends up just per bit or per token or whatever being much more valuable. And therefore, you actually don’t have to generate anywhere near as much as we currently do for pretraining. And so we can still make it to this deadline by the end of the decade. We can keep up the scaling, which I think might be difficult if you have to rely on synthetic data that’s just about the same quality as the existing native distribution.
Jaime
Yeah. I think this makes sense to me. So this is the reason why, I’m personally bullish about synthetic data, and this is the out. Right? If you run out of natural data, this is how I will envision that the companies are going to keep up with scaling the models.
Ege
Yeah. Of course. There are even some examples. For instance, DeepMind recently announced this result, that they were able to get very close to gold medal performance, on the IMO and, that was a combination of 2 systems, both of which were trained on synthetic data. There was a model that just solved geometry problems and a model that did formal proofs. And they don’t give a lot of details about their approach, but they say they basically used use something similar to the AlphaGo approach. Which means, some pretraining on a human data or existing proofs in the case of the Go approach, before, the first version of AlphaGo, they had pretraining, what we will call pretraining on just human games. That got the meta model up to something like decently strong amateur level, but far below the level of professional players masters. And then starting from that base, you were able to do, self play, generate synthetic data exactly as you said, you have this ability to spend more inference, compute, generate more high quality data and then train on that data and they were able to improve their models performance by using this method and I think they use the exact same approach in formal proofs, which I think it’s actually difficult to imagine that line of work succeeding just by pre-training.I think probably that will not have worked even if they had a lot more resources. So synthetic data is really vital for improving capabilities in some domains. You can get gains from it that you couldn’t get from pretraining even if you scaled up by a 100 or a 1000x.
Bottlenecks: Latency
Tamay
So, Ege, you’ve recently been thinking a lot about whether there are any limits imposed by, say, the latency of doing training or by GPU failure rates or other things that, become issues as you scale up your cluster, your the number of participating GPUs in training, by an order of magnitude or 2 or more as this picture suggests we will if this trend continues. So I wonder if you could say more about what you’ve been thinking about and what your conclusions of that work have been.
Ege
Yeah. Sure. So the basic way I would try to explain this limit to someone who’s just not familiar with any of the details is, currently training runs of frontier models take about 3 to 4 months. We think, as Jaime has explained before, that this might increase but not by a huge amount. So maybe it will go up to 6 months or maybe speculatively up to a year, but probably not much more than that.
Tamay
Can you say more about why?
Ege
Sure. So one thing is if you want to make it to the end of the decade then we don’t have that much time. So that’s one, like we can’t scale up by that much. But, I don’t even expect us to get close to that limit because, first of all the fact that we have these algorithmic innovations means that if you start a training, imagine that someone started the training run in 2019, which was just finishing about now. Even if they had spent a lot of compute, that model would just have been not very useful by now. It would be way, way below state of the art. So that means that you’re incentivized to not really do training runs that are that long.
Tamay
It’s like this question of how do you optimally colonize the galaxy. You wanna wait on Earth until your technology improves and your rockets are really fast. So, you don’t wanna launch very early with a very slow rocket because that’s gonna be overtaken by a launch, much later with a much faster rocket.
Ege
Yeah, I think that’s a very good way of picturing this actually. But whatever the reasons, let’s say that there is some kind of time limits that we have to work with. If you have to do a training run, say in less than 6 months, then the problem you face is that as you scale up your training run, each of your; so the way training works is that you start from some random points in parameter space, model is basically giving you random outputs and then you gradually adjust the model step by step to better predict your data, let’s say, in the case of pretraining and each of those steps you have to do in sequence. You have to take the first step before you can take the second step. You can’t take them at the same time. You can try to just pack more punch into each step. You can try to go further, but there are limits to how much we can do that. That is controlled by just how much information you see when you take each step. But at some point you just have seen enough focus, enough information and just seeing more doesn’t get you further. So there’s some limit to how useful each step can be, which means you really have to take some number of sequential steps. And this number we think increases as you are training bigger models on more GPUs.
The implication is that if your entire time is fixed but you have to take more steps then each step has to take shorter amount of time. And you can imagine that if we pushed this out by 10000 times, a 100000 times to keep this trend going by the end of the decade, then we’re going to really end up with individual steps that take a very short amount of time. And a lot of things that people today don’t think of as problems at all, like latency of communication between different GPUs. Today, it doesn’t matter at all. They’re so far from this being an issue, maybe by a factor of a 100 or a 1000. But if you scale by a 10000x, 100000x, these things that people currently ignore can suddenly become issues. And we try to work out, in our recent paper, that I was one of the co-authors together with a collaborator, we try to work out when these limits would kick in if you look at current technology, and also, what kind of improvements can we expect, assuming some reasonable technology improvements by the end of the decade. We end up with the bottom line that I think there is no obstacle to keeping the scaling until the end of the decade. But if you try to go further, then I think we start having problems on the current trajectory. Maybe we can do over GPT4 and we can get something like, 10,000 or a 100,000 scale up, probably 10,000 is more realistic, before we start to see substantial decline in the efficiency with which we use GPUs.
What happens is GPUs currently spend most of our time just doing the computations that are useful for your train run. But once you get to the scale, other things like time taken for communications start dominating. It just becomes harder and harder to coordinate these things, because each step just has to be done in such a short amount of time. And at that point the efficiency with the show using your GPU start declining. But I don’t think there’s an issue to make it to the end of the decade. And also, I think even after that, there are methods to do what I said before, which is to pack more punch into each step so that you get more value out of it so you have to do less steps.
One of the approaches that I think historically has not been promising is that, people have talked a lot in the past about the way we train these big models is we just do a very local computation of which direction should I go in to better fit my data. And then you just take a step and another step, another step. And people have said, well, the amount of information we’re using in these steps is really pretty limited, we can be a lot more sophisticated, and in fact, when people do simpler optimization problems, ironically, they actually use more complicated optimization methods than what we use in deep learning.
Tamay
With second derivatives or something like this.
Ege
Exactly. But the reason these methods have not worked, it’s not that they don’t pack as much punch per step. They do. They’re better in that respect. But the problem is they are much more expensive. And when you work out how much extra value you get per step versus how much more expensive each step becomes, it’s just not worth it to use them. So they have not been competitive, but they would be an option if ever the current optimizers hit a limit, which maybe after this decade.
Jaime
To summarize, and I think what I take away from here is these bottlenecks, this data movement bottlenecks, are an important problem to solve. But once you have them on your radar, and I fully expect that the companies will already be thinking about them, even before we wrote that paper, they will be able to solve them.
Tamay
I think yeah. So one thing I really like is that we’re solving, we’re identifying these novel issues that have not been on the radar of much of the AI community outside of the labs. Within the labs, I’m sure they have a bunch of research where we’re basically replicating things that they’ve already known for some time but otherwise, without our efforts, I think some of these ideas would have taken much longer to be uncovered. For these key strategic or conceptual questions and considerations to be uncovered and that’s, one thing I’m really excited about with our work.
Jaime
Yeah. Me too.
Tamay
So, you mentioned latency, which is largely a hardware property. Right? And in terms of solutions, you’ve been thinking about much of the software side of packing more punch in each step. So you expect the bottleneck, the way that we end up overcoming this bottleneck, if we do, to be more on the software side.
Ege
Yes. I think the reason for this is we have examined the historical improvements in the kind of latency that we would care about. And it has been fairly slow from the so for instance:
Tamay
DRAM access latency has increased by a factor by 30% over the past 2 decades or something.
Ege
Yeah. It’s very slow. The same thing is true for some operations that you need to do during distributed training to make sure all your GPUs know about what each other are doing. And those operations have also been, it’s about the communication latency between the GPUs. That’s also not been scaling very much. We’ve been seeing much more scaling in, flop per second and also in bandwidth, but not so much in latency, which means when you plot what’s been happening to this latency limit, it sort of looks flat. However much more powerful your processors are, if you have this serial, you need to take so many steps bottleneck, then at some point it doesn’t help very much at all.
I think another reason to be more optimistic is that people aren’t currently optimizing this very much, but that’s because you might argue that it doesn’t matter. So there hasn’t been much optimization pressure applied to this problem. Even there, I’m a little bit skeptical for the reason that I agree the latency bottlenecks are basically nonexistent right now at the current scales and training, but that is not really true in inference. So if people were able to reduce latency, that would actually have a meaningful impact on inference economics, which does give a strong incentive to do it. Right now, we estimate that the amount of compute the labs are spending on inference is not very much different from the, same order of magnitude as they’re spending on training. So there are big gains to be had there. But, despite this, the GPU producers seem to be unable to really get these latency numbers down by very much.
Jaime
Yeah. I think I find that quite persuasive. I also think of latency as the reason why you cannot just scale up to infinity, at least with the current setup and way that it works. It is still beyond what is on trend by the end of the decade. So you’re gonna still get, till the end of the decade. But, if you were trying to think of, how do we schedule a training round that uses a million times more compute than what’s expected by the end of the decade. You’re gonna run into..
Tamay
The laws of physics will eventually get you.
Bottlenecks: Failure Rates
Tamay
So another constraint that people sometimes ask is if you have a 10 million, a 100 million GPUs in your cluster, these have rates at which they fail. So they fail maybe every 10,000 GPU hours. There’s some kind of erosion or some kind of issue with the hardware, some flaw in manufacturing that results in the GPU giving out and shutting down or whatever. So, we’ve been thinking recently about whether this is an issue and I was wondering, if you could summarize whether or not this ends up being a constraint for scaling.
Ege
The short answer is that it doesn’t end up being a constraint. Even with present methods that people use. So what you have to do to deal with a failure, is ideally, you need to have an automated process whereby if a particular GPU, or sometimes it’s the CPU or power supply units or whatever in a particular machine that has failed, you want to just automatically swap out that machine, replace it with a machine that’s functioning properly, and keep your training run going. When you’re at really small scales, say below a 1000 GPUs, then the failure rates are manageable enough that often people didn’t even invest in automated recovery from failures. What they would do is when something failed, someone would just be on duty and they would just handle it. I’ve heard stories, I’m not gonna say who has told me this, but in some of Google’s earlier training runs, they would have people literally inside this and they’re just running around and replacing faulty interconnects that have failed, they would spot them out by hand. That works when you’re at a small enough scale, but at a big enough scale, you really want something automated. You don’t wanna deal with this problem.
To give some idea of how frequently these failures happen, the recent llama 3.1 paper from Meta, they give data about how many failures they experienced throughout their training run. We know how much compute and how many GPUs, what their hardware setup was. So our estimate is something like one failure every 50,000 GPU hours. This means that if you have 50,000 GPUs in your cluster, which is a little bit more than what they have, you’re getting one failure per hour. So one day you get 24 failures.That’s actually a lot if you have to recover it by hand.
But Meta had an automated recovery mechanism. Their idea was, suppose that some GPU has failed, we need to restart it. If you restart it, we lose the information on that GPU so we just periodically save the information we need to some remote storage. When a GPU has failed, we just start and recover it and keep our training line going. Right? And you can try to examine when would this become an issue. Well, you can sort of think intuitively that the point at which you start having a problem is when the time between consecutive failures becomes smaller than the amount of time you need to save and recover from this remote storage. But when you work out how much this will be and even for their model, you get to a number like 70 million GPUs. So it’s a lot. That is already enough to make it to the end of the decade.
First of all, the fact that you will be scaling your model up, gives you an advantage. The fact that there are actually more sophisticated ways you can recover from failures. For example, instead of saving to a remote storage, which is going to have fairly limited bandwidth, you can back, say you do have some number of GPUs in your training run, each GPU can send its state to say 3 or 4 other GPUs in the cluster. And then you have, 3 or 4 backups for everything in your cluster when you work up the mathematics of this. You see that if you have like 4 backups of each GPU in random places in your cluster, then it’s extremely unlikely that all of those are gonna fail at the same time. So it will always
Tamay
…The transfers are extremely low…
Ege
That’s right. And that gives you much more bandwidth because, you already need this very high bandwidth interconnect between your GPUs in your cluster and between nodes, to even facilitate your training run setting aside checkpointing. You just need this high bandwidth of communication. Well, if you already have it and it’s already there, then why not use this for checkpointing? It’s a very simple idea. And when we try to estimate, okay how big could you make training runs with this kind of strategy, you get even with very pessimistic assumptions about how your bandwidth might decline, bandwidth per GPU might decline as you scale your cluster, you still get 10 billion GPUs or more. So this is not gonna be a problem. I think anything else is more likely to bottleneck scaling than GPU failures.
Tamay
Nice. It’s gonna take a lot of engineering work to orchestrate such a training run. Maybe you’ll have robots, instead of humans running around solving interconnects, and there’s gonna be progress that we’ll have to make, in order to orchestrate training runs of this size. Seems like, there’s no kind of in principle reason to expect that…
Jaime
The fundamental barrier.
Tamay
Yeah. There’s no fundamental barrier.
Ege
I think that distinction is very important because, I wouldn’t say that it’s just gonna be very easy to scale. You’re just gonna have to buy the GPUs. In practice, each order of magnitude of scaling poses a bunch of engineering challenges. But, I think the way we look at this is, imagine that you’re spending $10 billion on the hardware in your cluster, with $10 billion you can pay for a lot of engineering time. So if it’s something you can solve just by having a lot of engineers thinking about the problem, then for us, it’s not really a significant bottleneck. We care about things that you cannot just overcome by spending a small fraction of your budgets on engineering or GPU cooling, or this or that. These are things that just add small constant factors on top of the cost.
Jaime
Well that small cost factor might be a $100 million to be clear. But it’s still small compared to the overall cost.
Tamay
Yes. So our kind of worldview is that AI is going to be so economically valuable and capable of maybe accelerating growth and certainly producing a bunch of output, so that these kind of costs, while large, end up being fairly small relative to the upside of what AI will likely deliver.
AI Investment
Jaime
Let’s talk more about this. We are talking about if people want to build these models using 10,000 times more compute than GPT 4, we think it’s gonna be possible by the end of that decade. But what does this buy us? What do we expect to see from AI in coming years?
Ege
And why would people do it? I think really this is the important thing. When you look at what’s going to limit scaling, yeah, there are things like energy and chip production and so on. You can see some limits there, but really the most decisive limit, that limit that could be most decisive is people just don’t wanna spend the money. Because we are talking about by the end of the decade, if you want to keep this up, on the order of $10 to a $100 billion being spent on just one training run. And then imagine that across many labs and imagine all the experimental and inference compute that has to go along with that. You end up with fairly large budgets. So what is this going to get you? Right?
Jaime
And that’s the amortized cost of a single training run. So just the cost of the clusters is gonna be in the hundreds of billions of dollars. So we expect that artificial intelligence is gonna keep increasing at a very fast pace. The natural question to ask here is why would people pay for it? The scale of the investment that’s gonna be needed to build a cluster where you can train a model that is 10,000 times larger than GPT 4 by the end of the decade, is gonna be in the order of 100s of billions of dollars. Why would people do that? What do we expect AI to be able to do and what impact do we expect it to have in order to justify such a large investment?
Tamay
So I think one fact that’s quite useful to keep in mind is just the amount of money that’s spent on wages each year. Right? So wages or human labor is the most valuable factor input in the economy today. About 60- 70% of total income gets spent on the wage bill globally. So this is like $70 trillion a year. So, if you’re able to fully automate human labor, you can capture this enormous sum and this is a flow rather than kind of stock and so that’s extremely valuable. If you do a simple discounted cash flow model of tens of billions of dollars a year, capturing even a fraction of that is worth investing hundreds, if not trillions of dollars per year on trying to capture that.
Ege
There was a recent comment by Masayoshi Son that he was being asked about the current rate of investment into AI. And he said, well, if you can automate even some of the economy, then imagine how much that’s worth, like trillions of dollars, and that’s per year. As Tamay said, it’s a flow. So he was saying, the current rate of investment is even too low. Right? We should expect it to go up over time.
Tamay
And I think that’s basically our view. Yeah. It’s kind of funny that we have this agreement with Masayoshi Son, which otherwise I don’t agree much with. But, we have the same kind of view that the current rate of investment is just much too low relative to the economic value and the potential that AI holds. I think it makes sense to spend a lot on building out our infrastructure for being able to do this kind of training and running inference, well in advance of when AI is able to do full automation or even partial automation. I think the reason for that is just that it takes time to build up the relevant capital, the infrastructure, to run and serve models. So things like energy, power plants, fabs, all those take time to build, and investors don’t want to be caught out of the blue. That suddenly you have a very capable model and the value of GPUs skyrockets and basically that the infrastructure isn’t there to support the serving of this model or the training of this model if we have innovations in software. And so it’ll make sense to kind of well in advance spend much more than we’re currently spending, in advance of actually doing substantial automation.
Automation
Jaime
So, how far are we from this? Do you think that by the end of the decade, we will already have full automation?
Tamay
Yeah. I think by the end of the decade is probably too soon. So we’re projecting this 10,000 fold scale up, and I think this is a long way towards this kind of idea of having a drop in remote worker. Which is this idea that you could have an AI system take control of your computer or kind of use a computer to accomplish the types of tasks that remote workers would do. So troubleshoot your computer, remotely log in and figure out what’s causing this issue, and try to identify and resolve it, or do a bunch of other types of work in IT or finance or accounting and other things that can be done remotely. Existing estimates of jobs that could be done remotely are on the order of 50% of the economy. Notably, this has increased since COVID. Like before, economists thought that work needs to be done in person, and this is one of the explanations for why there are cities of the scale that we see today, that some work needs to be done remotely (meant in person). I think COVID has poked holes in this idea that the majority of work needs to be done remotely (meant in person).
Ege
In person?
Tamay
In person. Yeah. That’s right. So I think close to 50% of things can be automated with drop in remote workers.
Jaime
Yeah. A big challenge that I foresee here is that you’re gonna need to build infrastructure to be able to accommodate these workers, and it seems that once it became clear that you needed to work remotely during the pandemic, we were very quick in building this infrastructure. So now the lesson is we will get better at building that infrastructure pretty quick. In the same way that we improved quite quickly, technologies for video calls and communication with our workers when it was needed. We might be able to find workarounds or finding ways of integrating AI into the economy in a more seamless way. One thing that’s important to reflect about is how fast and sudden this change can be. I will imagine, even if we have AI that already can solve very complex math problems, that doesn’t mean immediately that the world is gonna speed up by a hundred fold. What do you envision the process is gonna be from we have this AI that can solve pretty much any task that a human can do, to this AI having a large impact on the economy?
Tamay
Are you referring to just cognitive labor or also embodied tasks?
Jaime
Cognitive labor. Yeah.
Ege
Yeah. Sure. I think a simple estimate would be you just get a lot of AI workers on the tasks that we can currently do remotely, as Tamay says 50%, I think it’s a reasonable order of magnitude type estimate. Then you could at least get a lot of value out of those tasks. Insofar as you think, the bottlenecks in the world economy are not very strong, and maybe insofar as you think, the people who are currently doing those tasks can over some period of time acquire new skills and move to the jobs that AIs are not yet able to do. Then we should expect that it could double GDP or global domestic products or more. Right? So just because you automate out of tasks, all those people, move to the tasks you have not automated yet, that could already give a doubling and probably more than doubling.
But now how quickly does that happen? I think people disagree about this quite a bit. Even inside Epoch, there are a variety of different views. Some people think it’s plausible that we would get the system that is basically a drop in remote worker, as cheap or cheaper than a human. And maybe some people say 10 or 15 years. I think longer than that. So I would not expect over say the next decade, or the next 10 years, so not just by the end of this decade, to see a very dramatic acceleration of growth. Maybe we would see a few percentage points increase on the average or something like that. So I’m not very excited. But if you look at the historical trend, growth in advanced economies has been declining. So even stopping that trend and starting to increase that again would actually be a major change. So it’d be a big deal in the world of economics. But as maybe you’ll see later, it’s actually kind of small compared to the changes we expect to happen later.
Benchmarks & Moravec’s Paradox
Jaime
Let’s dive a bit more into this because what I think we believe is that for any single task that we can think of, for any single benchmark that we can think of, we sort of expect the AI is gonna make great strides there. We recently did this very hard math benchmark. Even for that one, it seems like the median expectation at Epoch is that by the end of the decade, AI will already be able to solve many of these complex research level questions. But there’s this gap between that and then this picture bent into, oh there might be a long tail of tasks, or there might be a long tail of challenges to overcome before it gets distributed into the economy. What is the distinction? Why?
Tamay
I mean, I think part of this is just, it’s been historically very hard to capture in benchmarks the types of tasks that people are doing in the economy. Having a benchmark that is able to capture this very well is just extremely hard. And so I think it’s natural to think that benchmark progress is going to just be much faster. Key reasons you might point to is the timescale over which such a task is performed. So often benchmarks, you need to do some reasoning, but you can do that reasoning within maybe an hour or something for our very hard frontier math, say where humans would take maybe hours to solve. And so this is a longer timescale than many of the traditional benchmarks, but still not the timescale over which key economic tasks are performed, which might be weeks or months or what have you. And I think that ability for a model to be able to execute plans over very long time scales, is a component that I expect to take slightly longer than solving these types of benchmarks, even the ones that are very hard.
Ege
I would point to a different phenomenon, which is that there’s this paradox in AI called Moravec’s paradox, which is that the task that a computer or an AI finds difficult are not necessarily the tasks that humans find difficult. And Moravec’s explanation for this was it’s because the tasks humans find difficult are tasks that we have only started doing recently in evolutionary history. And the tasks we find easy are tasks we have, maybe not just us, but even lots of other species have done for 100s of millions of years or maybe longer. Those tasks are much more optimized.
Tamay
So the first case would be the first class of things like math and programming and chess or Go. And then the other tasks that we’ve been doing for a very long time in our evolutionary history is walking and fine motor skills and things like this.
Ege
That’s right. I think to some extent even, for instance language is now basically something that AIs can do. And well, if you look at the evolutionary history of language, it’s actually not that old of a skill. Humans are the really the only species we know that have language. While if you look at the ability for locomotion and things like that, so many species have that skill. Even bees and whatever can do it in their own capacity. And we can’t even match that yet. Bees have very small brains actually compared to humans. So you might have expected that, maybe we haven’t yet trained models that could be on par with on par with the human brain. But is it really so hard to be even on par with the brain of a bee?
I think it’s interesting the extent to which the progress has been so lopsided towards some tasks. The progress in robotics in any form, not necessarily in a human envelope, but even something that could control the body of a bee has been very very slow. I think it has been very disappointing. I think the reason for that is probably this argument that those capabilities are just much more efficiently implemented. And our methods right now are quite sample inefficient. This is a difference that’s very easy to see if you train an AI to play Go or chess or whatever. Yeah, they can play it at superhuman level, but they can only do that after playing millions or tens of millions of games. And well humans, how many games can a human even play in their entire life? It’s not that many. And a human can get to a pretty good level of competence on this kind of task even with a few 100 games, which is extremely difficult for AI systems. So there’s this big gap in efficiency. We don’t know where this comes from. And I think that these kinds of things where biology is very efficient at doing some things that are very old, are just forming a huge chasm. I can’t even think of really prominent benchmarks that try to probe the capabilities that are very old in humans.
Tamay
I think, I kind of agree that Moravec’s paradox applies to things like robotics, and I think that’s a very compelling example. But for remote workers, I’m curious what types of tasks or what types of capabilities or competencies are really hard for AI systems to match human performance?
Ege
Yeah. So right now, I would return to the same point of sample efficiency. So the one way I would express this is, it’s very normal when a company hires a new worker right now, especially if it’s a fairly junior hire, for them to be quite unproductive for the first few months that they’re at the company. That’s essentially a training period in which they learn the context that they’re supposed to be working on. They pick up some skills that they didn’t have before, and they have to do that with a fairly limited number of samples compared to what we show AIs.
If you try right now to get an AI to adapt to your specific context, it’s actually fairly challenging. There are 2 approaches right now we have. One is fine tuning. The other is sort of in context learning. Fine tuning, you need less data than in free training, but still way, way more than typically you’re going to have access to in this kind of setting. And in context learning is much worse than we see in humans.
For instance, in math problems when we were talking with some mathematicians as part of our benchmarking project, they mentioned that when they try to get current models to solve a math problem, sometimes if the problem is easy, they solve it and that’s great. But sometimes they try an approach that doesn’t work. And then the human user says, “oh, what you did, it doesn’t work”, try something else. And often they will sort of go through the motions of trying something else but they will do exactly the same thing. Right? And why is this going on? Why is it that models are so bad at learning from their failures? I think this is a little bit of a mystery, but I see this as being a very big gap.
And I’m not sure right now how it’s eventually gonna be covered. My guess is that we are not really going to solve the sample efficiency problem. What we’re going to do is we’re going to use our ability to overwhelm the problem with greater resources to just scale past it. We’re gonna get the superhuman system just like we did in chess or go and other domains, which is still less sample efficient, but because of the overall intensity of the resource inputs we’re giving to it, is still more competent. But that does mean that you should expect us to get there longer than you might otherwise expect.
Economic Impact
Jaime
Okay. So let’s take it for granted that we have AI that can do any remote job. Let’s even go farther and say that it can do any physical job through robots for example. What are the implications of this for the economy?
Tamay
Yeah. So we’ve been thinking quite a bit about this and one thing you might do is look at standard accounts of economic growth. And there there are theories of economic growth, especially endogenous growth theory, that place idea generation and innovation as being very central to economic growth. So R&D and learning by doing, producing innovation. And this kind of economic theory tells you that,an important fact about the economy is that there are increasing returns to scale. That is if you double the inputs to your economy, capital and labor are the kind of key inputs, as well as resources, that go into idea generation and innovation, then each doubling produces a greater than doubling of the outputs. Right?
So you double your inputs, your labor on capital, you can basically duplicate this economic processes that you have set up. That gives you basically a doubling of output. And then you get this additional boost from innovation making these processes more efficient. So getting more output per unit input. And so you have increasing returns to scale and so doublings of your inputs produce greater than doublings of outputs.
Jaime
Now actually, sorry. I’m confused about the point here. The main mechanism through which the increasing returns to scale operate is through idea generation?
Tamay
Well, so an important component is that you get every doubling of the capital and labor, say, you get close to a doubling in output, but that there’s this additional oomph on top of that, that takes you to increasing returns. So it’s the combination of the kind of returns to scale on the kind of accumulative inputs, these 2 key inputs. And then on top of that, the returns to R&D. So those two things jointly determine the returns to scale of your economy. And so what this picture says is that, if it becomes possible for each of your inputs to be something that you can invest into, so you can turn your output dollars into more inputs, then you can get accelerating growth. Because, you double the inputs, that gives you a greater than doubling of outputs, that you can then reinvest and kick start this accelerating growth regime.
Now, of course we’re not in that regime because the central input, labor, is not something that we can turn money into more labor. This is determined by population growth, which is somewhat independent of how much output, not quite but it isn’t determined exclusively by how much we’re investing at the very least.
Jaime
And AI changes that.
Tamay
AI changes that not because it changes human population growth, but it produces human substitutes that, for all intents and purposes, are flexible substitutes for human labor. And once you have that, then you can invest output into building more compute related capital. So fabs, lithography machines, data centers, the energy infrastructure in order to power training and inference and by virtue of that, you can kind of get a dub greater than doubling of output for every doubling of input, and you can reinvest this into the cycle that accelerates growth.
Jaime
So to paint the picture here, we have this AI. This AI can solve many tasks in the economy and one of the tasks that it can do is, it can also help produce more infrastructure for more AI. It can help build more GPUs, which means that then you have more digital workers, more instances of the AI that can do more and more tasks. And this is the basic way that has been accumulated.And some of these digital workers are not only producing output, but also thinking about how to make the whole process more efficient.
Tamay
That’s right. And so sometimes people say this feedback loop of better technology enabling you to produce better technology has always been around, so AI is no different. But AI is different in a very important respect, which is that AI promises to be able to flexibly substitute for human labor such that there is no kind of bottleneck left that we rely on human population growth to try to unblock. And once you have that, then you get this kind of accelerating growth pattern.
Jaime
But then do you get blocked by other factors of protection?
Tamay
You do get blocked by those other factors. So those would be, land or total kind of energy that you’re able to harvest. Maybe there’s some scarce inputs, like minerals or metals or rare earth metals. I think that is definitely something that eventually binds, but I think there’s going to be a period of time when, we have kind of produced the substitute for human labor, but we haven’t yet reached the kind of limits of how much output we can produce.
Jaime
So the basic picture here is right now, the binding nonaccumulative factor is labor. Once that’s lifted there is gonna be others, but until we hit them we’re gonna still have this regime of accelerating growth.
Tamay
That’s right.
Jaime
Nice.
Ege
Yes. So one way to maybe try to reason about when this might happen is, when we turn something into an accumulative input and we accumulate tons of it, and complementarity between different inputs is fairly strong. We’re going to expect the share of those inputs in total gross domestic product to start to decline. And in fact, there is maybe some sign of this for labor, where the labor share of output has been declining, though not particularly quickly. If you imagine that we completely commoditize labor, we have tons of AI workers and they’re very cheap, what’s going to happen is the valuable things in the economy are gonna become precisely those things we cannot scale, like land and energy and whatever.Those inputs are gonna become very valuable.
But you can just look at the path like, the rate at which the labor share has been declining and that is not very fast even though the economy has been growing quite fast, and we have been scaling labor quite a bit. So if you just extrapolate, how many more orders of magnitude of increase in labor could we get, before the other factors according to current trends are gonna start to bite and stop additional growth. There’s a lot more room.
I think economists also would agree with this, in the sense that if you ask them are we likely to encounter a decisive natural resource bottleneck or some other bottleneck to economic growth at present rates continuing for, say 200 years, you’re quite unlikely to get answers that are “No, no. That can’t happen. We’re gonna hit some bottlenecks.” And all we’re saying really is that, AI is going to speed this process off because it’s going to allow us to grow the population much more quickly, which is gonna allow everything else to grow much more quickly. And so we get to the point we would get in in 200 years instead in 10 years or 20 years of growth, something like that.
And there’s really, I think, no decisive arguments against this in the literature now, [of this] implausible conclusion, which I think, makes people skeptical. And that’s I think a totally fine thing. You should be skeptical if someone comes along and tells you, something totally unprecedented is going to happen over the next 30 years. On its face, that’s a very implausible claim.
Jaime
We have been talking about how through this feedback loop of AI automating more of the economy, that economic output being used to create more infrastructure for AI and idea creation, and how this could result in accelerating economic growth. I want to ask, do you see this as a given? What are the uncertainties that one could have?
Ege
Yeah. So I guess we don’t see it as a given. We have a paper that we published on the subjects where, we basically say if we define much faster growth to be around 10x faster than what is typical in the world economy today.
Tamay
30%.
Ege
Yeah. 30% per year. Then we say, if we get AI that is capable of doing what you said, substitute for humans not only on all the remote tasks, but also on all the physical tasks, then maybe it’s like 50% that we would get a 10x increase. So we are uncertain if that magnitude is possible or not.
So arguments in favor, Tamay already explained the most decisive arguments, which is this idea about, we get this increasing returns to scale. Which is that, we get more AI workers, we can reinvest ordinary kinds of physical capital and we get a lot more researchers, because AIs themselves can do research, which drives growth in what economists call total factor productivity, efficiency with the sheer use of resources.
Tamay
Also learning by doing is like an important thing. Like explicit science?
Ege
I would say that yeah. I agree. There are other factors actually which contribute to the same kind of increase in versus scale. Just the specialization of human workers is something in practice that contributes to it. Everyone learns a specific thing that they really are good at and then they trade with each other, and that also gives rise to some amount of increasing returns to scale. But, the general idea is this increases from scale.
There are some other arguments even if you don’t look at this, if you just look at what economists call factor accumulation. So we assume there’s no technological progress, beyond what you have already seen, but we just keep reinvesting outputs into more chips and more robots and also more factories and whatever. Then the usual opinion in the growth economics profession, was that this kind of thing can’t really produce long lasting growth. But I think the reason for that is that we are very used to an economy where labor cannot be accumulated. So, once you remove that and labor itself becomes accumulable, then I think this conclusion that you just cannot get much more growth, by just factor accumulation, is overturned. At least we can get a 100x, maybe a 1000x, on top of what we have now. So that’s an additional reason to believe this.
Tamay
So one intuition for that is an H00 GPU costs $30,000. And, according to some estimates, at least, it does as much computation per second, as say the human brain might, although this is very uncertain. But it costs on the order of $30,000, which is lower than the median wage in the US, especially among jobs that we expect AI systems to be disproportionately doing. So at a rate of about a year, it’ll be able to earn enough money to pay for another copy of itself. So you get very quickly a doubling at the timescale of roughly a year, of just pure factor accumulation. And so you get this very fast accumulation of these factors, which gives rise to very fast growth.
Ege
That’s right. So I would say what is the decisive objection to really both of these views on some level is that okay, I mean, there are some other objections, like regulation, maybe we’re going to choose to slow down growth because we are worried about the risks or just generically we will prefer, we will be more comfortable if this transition happens slower. That’s one possibility. But in terms of the physical possibility of it as opposed to whether we choose to do it or not, I think the decisive objection there is really about these non accumulable factors.
We know these factors exist, like land is hard to accumulate and physical space eventually can become a bottleneck. Energy is a limited factor that some other natural resources could be limited. And right now these things, even if you sum all of them up, they don’t account to a big fraction of the world economy, most of the world economy, the majority of it is just labor. And of the remaining parts, most of it is physical capital. Both of which we assume will be accumulable in this world of AI. So we try to think about, okay, how much room do we have even based on naive calculations to just scale up GDP. Is it plausible that land or energy or rare minerals or whatever could be a bottleneck to growth? And I think we basically conclude that eventually, yes, but this is like many orders of magnitude away from where we are now.
I think we’ve had an interesting experience talking to professional growth economists about this because they tend to agree with the statements if AI is not in the picture. So if you just ask this question, can we keep up our current rate of growth for like 200, 300 years? They tend to say “yeah, you know, like it seems plausible”. That’s probably their default expectation. But if we then ask them, suppose we have these AI systems that can substitute for labor, we have these reasons to expect an acceleration, then can we get that same amount of growth but in 20 years? And then I think a lot of them become a lot more skeptical.
The reason I think is just that intuitively, it feels very implausible. We’re very used to a world of something like 3% per year growth worldwide. This rate of growth has been fairly stable since the end of the second World War. And economists are just very used to think of growth as constant. Even the rest of us sort of take it implicitly at least. If people don’t come from a very poor country that happen to experience this very rapid catch up growth, where they went from being very poor to something like advanced economy standards, then maybe they have a slightly different view. But generally we think of this as being a fairly constant thing. And I think the basic heuristic there, that you should be skeptical. If someone just comes along and tells you we’re going to see this totally unprecedented acceleration and growth in the next 20, 30, whatever years, that this is plausible. You should be very skeptical.
Similar claims have been made about other technology. People have said the same thing about the Internet. People have said the same thing about, I don’t know, nuclear reactors, nuclear power. Now some people say the same thing about fusion. And I think we would be skeptical of all of these claims because they don’t really… like labor is such a huge fraction of the economy. These other things are really not. There’s no reason to expect that increasing their supply by a lot would have such a huge impact on the economy. And we really do think in this case the arguments specifically about AI are very strong. Our best theories of economic growth just robustly predict this, unless you make very unfavorable and what looks to us like unrealistic assumptions, which is why we think there doesn’t seem to be an obstacle to it being physically possible.
Now. There is, of course, eventually, we think we are going to hit these non-accumulable inputs and then we’re going to have some… So for instance, people are worried about the impact of AI on wages and employment. This is something people worry about a lot. And there is a common argument that is offered by economists as to why these worries are unfounded or overblown. And this has been offered also in past examples. Automation, it’s very simple. Humans are always going to have some comparative advantage relative to AIs or other kinds of robots on some tasks relative to others. So the idea is you will always be able to gain from trading with them. We will not be worse off by trading with them. And the way this has manifested in the past is, say that cars become much more efficient than humans at transportation. We get on cars and there’s no need to have horse drivers or horses, or a lot of people can become unemployed suddenly. Or we have spreadsheet software and then suddenly a lot of people whose job it was to multiply and add numbers in corporations, suddenly they’re unemployed. But of course, unemployment doesn’t stay out forever. Those people find some new task to do that is not yet automated. And in fact, the fact that these tasks got automated makes them more productive. So not only do their wages not go down, they in fact go up after they transfer to these new tasks. And I think economists have been looking at AI and just seeing it as more of the same. They’re saying, well, it’s just another kind of automation. It’s just going to go the same way we’ve seen before.
But I think the important difference is that AI is capable of substituting for humans across all of the tasks. And that is very different from doing it only on some tasks. One way to try to see what would happen is, imagine that we have AI systems that can run on a GPU using say, as much power as the humans use to survive. Humans use around 100 watts of power. And if it can take that amount of power and it can just deliver, it can just do everything I can do, but 10x better, then my wage will never be above a tenth of what I need to even just stay alive. So there will be a big collapse in my wage, at least relative to the energy I need. And that’s like wages falling below subsistence.
So the reason the arguments of economists about comparative advantage, turns out to be not true is precisely because of the non accumulable inputs they will point to when they object to the possibility of very fast growth. What happens is that we have so much labor that the value of labor goes down a lot. This doesn’t mean humans as a whole are necessarily poorer. Because humans can just own a lot of capital, a lot of land, a lot of natural resources, and the rents on those things, in this future economy, we expect to go up a lot. So as a whole, humanity, if it keeps its current property possessions, is actually going to be much richer. It’s just going to be that labor in particular is going to become much less valuable.
Jaime
The analogy here that this makes me think is aristocracy, in certain countries now. Where aristocracy used to own land, because of that they got certain resources, some resources that they have accumulated through generations, and there is some historical wealth that comes through that. We might end up being in a similar position as the aristocracy of the future, that because of our historical position and privileges, we were able to accumulate a lot of these capital resources and then keep increasing and increasing in value. I guess that this also invites this other possibility, which is that I believe that the trend is for historical wealth to vanish as some members of some generations end up gambling away their money or making some poor bets on how they distribute their money. And they tend to revert towards not having this special place in the economy. Are you worried about something similar happening to humanity?
Ege
I would say it’s very reasonable to expect that because as you said, it’s actually the base rate that this kind of wealth that is built up does not last for that long. The wealthiest people in the world today are usually not the people who used to be the wealthiest. They’re not the descendants of people who used to be the wealthiest 100 years ago. And it’s actually a bit puzzling to explain that. Why can’t they just keep their capital invested and keep getting high returns on it? I think there are a few reasons. So one reason is that wealth just gets divided, as one person is maybe wealthy, but they have a bunch of descendants and their wealth just keeps getting divided through the generations.
Another reason is if you just passively own wealth and you invest it, usually the returns you can get are less than if you combine the role of being an investor and also a manager or a founder of a company. And so those people are able to get higher rates of return on their wealth, which means you might start from a higher base, but you grow more slowly compared to them, so they have the ability to overtake you. And this is definitely something to worry about in the case of an economy where AIs just do all of the jobs and humans are on the sidelines just living off the rents from their property. That can last for a fairly long time, but I would expect the AIs to eventually start to dominate the world economy in this sense. At least, unless humans are able to take advantage of the large amounts of technological progress that will be made in this world to increase their own capabilities, to just not just remain on the sidelines.
Jaime
Yeah, I think that this seems pretty determined to me. As economic time goes on, I expect AI to be a bigger and bigger fraction of the economy. Whatever remaining sliver of wealth humanity keeps is going to be a smaller and smaller fraction. I guess that there is a crucial difference between it being a small fraction but still being vastly more than we have now, and actually that shrinking to being zero, leaving us in a worse position in terms of wealth per capita than we have now. Do you have intuitions about which of these worlds are we headed towards?
Ege
I think if you manage to retain a peaceful economy in some way and humans are not expropriated, then there’s no reason to worry that humans as a whole are going to become much poorer. We own some wealth now. That wealth I think is going to have very high rates of return throughout the period of increased economic growth. So we will end up with a stock of wealth that is just worth an enormous amount by our current standards. I agree with you that over time, as a share of the entire economy’s wealth, it is going to shrink, but the overall economy is going to be growing so much.
For instance, if you think about the effect I mentioned with founders getting a higher rate of return on their investments, well, they are able to do that because they are in the process of creating a lot of value that was not there before. So yeah, they get a bunch of wealth, but that’s because they… It’s not because they have taken wealth that belongs to other people, it’s because they have created a lot of new wealth. And that would be my default expectation with AI. And I also think that it is probably not reasonable to expect that, with the amount of technological progress we can foresee, that humans are just going to stay on the sidelines forever, that the human capabilities are also not going to increase. At least if you consider the amount of wealth that would be available to some humans, at least in this world, there will be very strong incentives, for the economy to offer products to them that can increase their capabilities. Not just for sort of reasons of productivity, but because that might enable them to have much richer experiences. It might provide them prestige.
Tamay
Prestige and you want to be on the side of the very successful and prestigious types of beings.
Ege
Yeah. So sometimes people wonder, “what would it be like to see four colors instead of three?” Right now we can’t offer this experience to people, but in the future we might be able to, and there’s a lot of things like this which people might well be willing to pay up for. I think the biggest one maybe is the increase in life expectancy. Right now, this is just such a scarce good that no matter really how wealthy you are, there is very little you can do to spend your money to extend your life expectancy. But I think in the future, this probably will stop being the case. And if we need to in some way change something about humans to make them able to live much longer, right now some of the problem is that parts of your body that just get worse over time, it degenerates, and we have no way of dealing with that.
Jaime
How much are we gonna need to change in order to stay competitive with a robot. So if I imagine myself living like a million years and seeing four colors, I don’t think that gets me to “Oh, I’m going to be able to compete with AI that can solve math problems that Terry Tao cannot solve”.
Ege
Well, we should get back to the scaling laws, right? We should think that the amount of power or wealth or whatever amount of productivity that an agent is going to have in this economy should be roughly proportional to the amount of compute that they are able to use when running. As I think was mentioned earlier, the human brain does about as much computation, we think, as one H100 GPUroughly similar. If you have a total of billions or trillions of these GPUs, then there are some AI systems that run on millions of these GPUs at once. Well obviously, I think it’s very plausible that you’re not going to be able to be competitive with those systems.
Open Questions & Takeaways
Tamay
I think there are a bunch of interesting open questions that I’m excited for us to be working on. One is this question of algorithmic progress and what really drives algorithmic progress? How is this downstream from say scaling? Or is this something that you should think of as being largely independent from scaling of hardware? Is algorithmic progress mostly about reducing the costs of attaining already kind of achieved levels of capabilities, of training smaller models that are as capable as the large models that we just recently trained? Or are these algorithmic innovations around pushing out the boundaries of what our AI systems can do? Are these algorithmic innovations mostly in the form oo architectures and data quality or other minor tweaks? Are they in post training? And if so, exactly what is driving this? I think those are some questions that I’m excited for us to work on.
Jaime
Yeah.
Tamay
Other questions are how fast are we going to get kind of these drop in remote workers? I think this is a question that we can now already start to think about. Claude 3.5 has this computer use ability, that it can use your computer to accomplish some tasks. We are starting to see the kindlings of drop in remote workers and we can try to study how fast are they improving on the tasks of the type that actual remote workers are performing. And then we can say something about scaling behavior. Suppose we increase the amount of compute by 10,000 fold as we expect to happen by the end of decade. Will this be sufficient for automating 50% of work, or basically we think the work that can be done remotely?
What is the chronology of this automation? Which tasks are going to go first and what is the pace of this automation? I think an important question is whether the pace of automation is faster than the pace of retraining. If that’s the case, then I think this has really interesting qualitative implications around wage inequality, that they’re going to be bundles of. They’re going to be occupations that earn a lot because they have yet to be automated and are complemented by things that have been automated. But humans take too long to enter into those occupations because the timescale of training is so long. And so you might end up having a bunch of people who end up not being retrained to perform tasks. And as a result you kind of get inefficiencies this way.
Jaime
So I’d be curious again whether you have takes on either…what are some key takeaways about AI that you think are important or also what is some future work you’re excited about?
Ege
Well, I mean the key takeaway, I guess if someone is totally unfamiliar with AI, they come to listen to this conversation. I guess the one sentence takeaway I would give is: the future is going to be here sooner than you think. And I do think that’s a really important thing for people who are not following this space to understand.
Jaime
This has to be part of your laboral/career plan, right?
Ege
Right.
Tamay
And Ege, you are maybe a bit more kind of skeptical of fast progress than many other people, even in our organization. So I think coming from you, this says quite a lot.
Ege
Yeah, I mean if you’re. There’s a big difference between people who are I think tracking AI progress and people at labs or people who are outside labs but are sort of in the same social circle or something. They just have much more aggressive views about the rate of progress we’re going to see over the next 50, 100 years, some people even in the next 10 years, than the general population. I think people just do not expect anything like the rate of progress that we expect. Even economists telling an economist that you expect the rate of growth to plausibly increase by 10x at least for a while in the next 30 or 40 years, that’s a plausible thing that could happen. They are going to look at you like you’re crazy.
Tamay
We had dinner with a development economist and were telling him about, we think it’s plausible that we could get a 10x increase in the growth rate so 30% per year. And then he responded, you mean 30% per decade? No, no, per year. You mean like 3% per year, right? No, no. 30% per year. And it took a while to get this through to him, but as soon as he actually realized what we were telling him, he just started laughing and thought this was totally ridiculous. So there is this response that the economists have of this view as being pretty bonkers.
Ege
Yeah. And I would encourage people to keep the very long run historical view in mind. We have seen a lot of things in history which are, you could even say more remarkable than what we’re talking about here. For instance, maybe really the most unlikely, and still we don’t really understand, transition that happened is this transition of abiogenesis. You had planets with no life and then suddenly it has life and then suddenly you have these bacteria that can multiply by two every 20 minutes and then they just colonize the entire planet. Actually, we take it for granted. But if you look inside a cell, it looks so complicated. And that just happened. It’s just the thing that can happen.
Then after that, even in human history, went from the world population doubling every 100,000 years in the foraging era to something like every thousand years after agriculture, to now the world economy is doubling every 20 years. So we have seen many orders of magnitude of acceleration and growth before. And this is one of the main reasons why I would… So when people are skeptical, they say, well, in the last 70 years growth has been slowing down. How can you look at that and then say such a big acceleration is plausible? I would say, well, you have to take a broader historical view. If growth has been fairly constant for seven years, okay, maybe even if you know nothing about AI, just come at it from a pure trend extrapolation perspective, you could maybe say that’s going to last another 70 years, like 50% chances last another 70 years. And economists, and also I think just ordinary people are just much more certain in that, that this business as usual is going to continue.
There are some interesting stories of similar views in the past. So for instance, before we enter the industrial era, progress was so slow that usually it was happening, but you didn’t really see much progress in one lifetime time. So people will sort of take it for granted that technological progress and new inventions and things like that, those are pretty rare. And in the 17th century, late 17th, early 18th century, people started to notice that there was some real progress starting to happen in the economy. They could notice some changes in their own life. Isaac Newton said that this is very strange. We were suddenly seeing this progress. How could this happen? And his conclusion was that, it must have been because the civilization was destroyed before and we’re just recovering because he just couldn’t imagine otherwise. He couldn’t reconcile the rate of progress with, if we can progress at this rate, why are we not already extremely advanced? He couldn’t explain it. Now we think we have an explanation. This increasing returns to scale growth stories. But I would just advise people to keep in mind that we have seen a lot of big changes. We’re not saying something that is historically unprecedented in some sense and that I think should make you less skeptical than you would otherwise be. That’s really the main high level takeaway that I would want people to have.
On the details, what specific projects that I think could shed more light on the future trajectory of AI? I think one concept aside from of course, everything that has been mentioned so far, that seems like it could be pretty important is this training-inference compute, trade off. This is important for several reasons. One of them is that it seems like it plays a pretty central role in your story about why synthetic data is such a plausible way to overcome data bottlenecks. And I agree with that view. But I do think this trade off is just not super well understood. I think there’s just a lot more work that we could do here and the implications of this are, there’s so many implications of this that I think we’ve realized over the past six months that it’s really worth doing some more rigorous research in this area.
I’m very excited about the possibility of just getting much better benchmarks that are actually going to be able to at least put up a fight against the enormous rate of progress that we expect. I think people are just not taking this very seriously in a lot of domains. They are just sort of building easy benchmarks that easily get saturated. I don’t even know when GPQA… GPQA is this benchmark that was created as a multiple choice benchmark. It was created by getting some experts and non-experts and then telling the experts, okay, write a question that an expert in the same field as you is going to be able to answer with a very high chance; but a non expert, even with access to a search engine, is not going to be able to answer again with a high chance. But the resulting data set, in my opinion, it was not the kind of things that those experts are actually useful for in the real world. It was just things like terminological things or formulas that those experts explicitly know but are not very easy to find by googling them. But a model that can do that, but in no means is even close to substituting for the experts that were actually part of that metric benchmark.
So I think benchmarking efforts have been very poor and we have, I think, already improved upon the state of the art in a big way in math. And I just think we could do much more of that. I just don’t see the community paying too much attention to this problem. It seems like everyone wants these benchmarks to exist. When a new benchmark is released, everyone’s like “yes! a new benchmark, it’s so hard, so nice.” But at the same time, when I look at how many people are working on creating such benchmarks, it seems like so few.
Jaime
Yeah and in a sense, it feels like creating this benchmark is the obvious thing. Right. If you want to measure how fast AI is improving, what you need to do is create settings in which you can evaluate this rigorously, which is what benchmarks are.
Ege
For instance, in the case of GPQA, it was marketed at this very difficult benchmark. And then one year or maybe one year after this at least, now models are already at like, I don’t know, 70%, 80% or something like that. So I think benchmarks are not created with the right framing in mind. People may be stuck in the way of thinking about AI that was true like 10 years ago. They’re stuck in like, oh, let’s create these very narrow benchmarks. Like, let’s test if a model can look at a picture and tell a dog apart from a cat. This is the kind of benchmark we used to have, and that’s just so primitive and so easy compared to what we need to test and probe for the capabilities that are going to lead to the big changes that we’ve talked about. So maybe people are just not investing in this because they don’t share our view of how big the impacts are going to be. And in that case, I think we just have this worldview of advantage that we can exploit to build these good benchmarks.
Tamay
Yeah, I think our worldview on this is fairly rich. We’ve thought about this quite a bit and understand and I think have a better sense than a lot of people about precisely the way in which this automation might happen and the reason why this automation might result in accelerating technological change and economic change. And I think I want to spend a lot of time just harvesting that worldview and picking out things that we can translate into benchmarks so that we can understand if you scale these resources like compute data so on how much progress are we making on these tasks. And I think that will just inform us about how fast we are getting to this world that we expect eventually to reach.
Jaime
Yeah, and I think that this has also put us in a much better position to advance the rest of our research agenda. Algorithmic progress, if we have more data on benchmarks, will be much easier to study. More generally, this question of as you scale the systems, how much better they get, are also easier to study if.
Tamay
You have this information and research about predictable evaluation. So suppose you scale up your model by scale up your training compute and your data set and maybe scale up the post training and scale up inference compute, what exactly is the effect on benchmark performance or kind of real world utility? I think we will be able to develop a much more mature sense of this by investing in evaluations, by investing in good benchmarks and I’m really excited to be making progress on that kind of research.
Jaime
Yeah, this is the goal for us. We want to be that organization that everyone can look up to for understanding how quickly AI is advancing, how quickly investments are growing, and how do you relate this too in order to think about where it might be headed. And we have done a pretty good job here, but I think we’re going to do a much better job in the next year.
Ege
I would agree with that.
Jaime
Okay, so we’ve been talking about many things today. We’ve talked about the mission of Epoch, we talked about why we created this organization. We’ve talked about AI, how it has been able to achieve many incredible things in the last decade, in no small part due to the incredible scale up in resources that the field has achieved. We expect this scale up to continue. We expect these improvements to continue and eventually have AI that can substitute humans first in remote work and later in practically any kind of economically useful task that you can think of. And if this worldview proves true, we also think that this will have dramatic implications on the economy where like the economic growth might drastically accelerate.
Now I think we need to take all these lessons very carefully and prepare for the future, and that goes through having accurate up-to date information on how fast are the trends of investment in AI and how fast are the trends of improvement in AI. And that’s what Epoch AI is gearing up to do. And I would love for the people watching here to come with us in this journey, keep up with the work that we’re doing, because I think that by doing so, you’re going to end up being much more informed about AI and the role that it’s going to play in our society.
In this podcast



Related work