Featured

FrontierMath

Podcast
Jan. 29, 2026
Newsletter
May 23, 2025
Few domains test AI reasoning as clearly as mathematics, where answers can be verified automatically and the hardest problems extend to the frontier of human knowledge. Epoch tracks how AI is performing on mathematical tasks over time, including through FrontierMath, our own benchmark of expert-level problems designed to test the limits of what today's best systems can do.
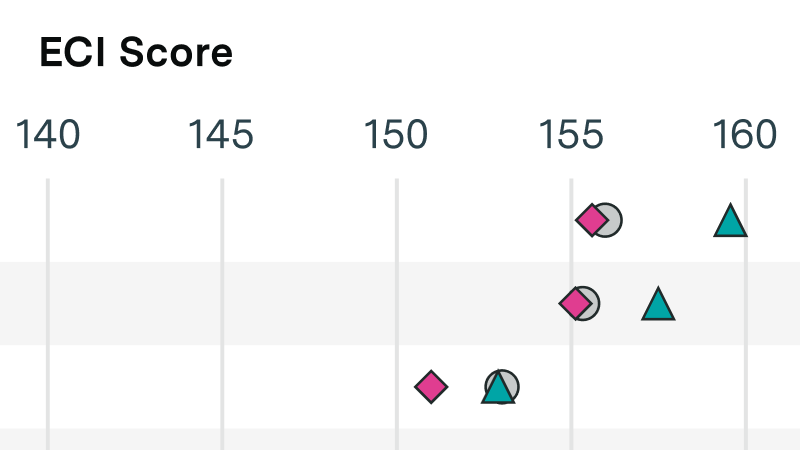
Give up at least one of: text only, short time horizon, easy to grade, and expert human superiority.

In this episode, Greg Burnham and Tom Adamczewski join Anson Ho to push back on benchmark pessimism and dig into what the next generation of AI benchmarks could look like.
In this episode, Daniel Litt chats with the hosts about AI’s limits in mathematics, accelerating math research, and how to measure progress on open problems.
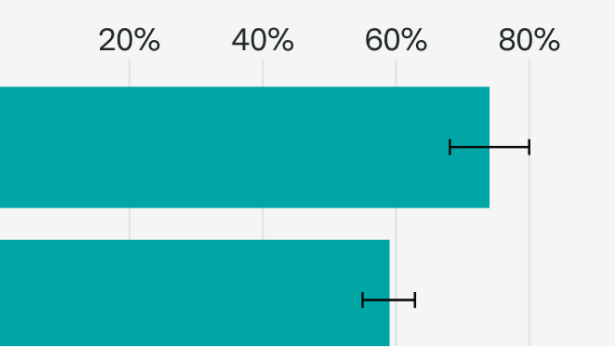
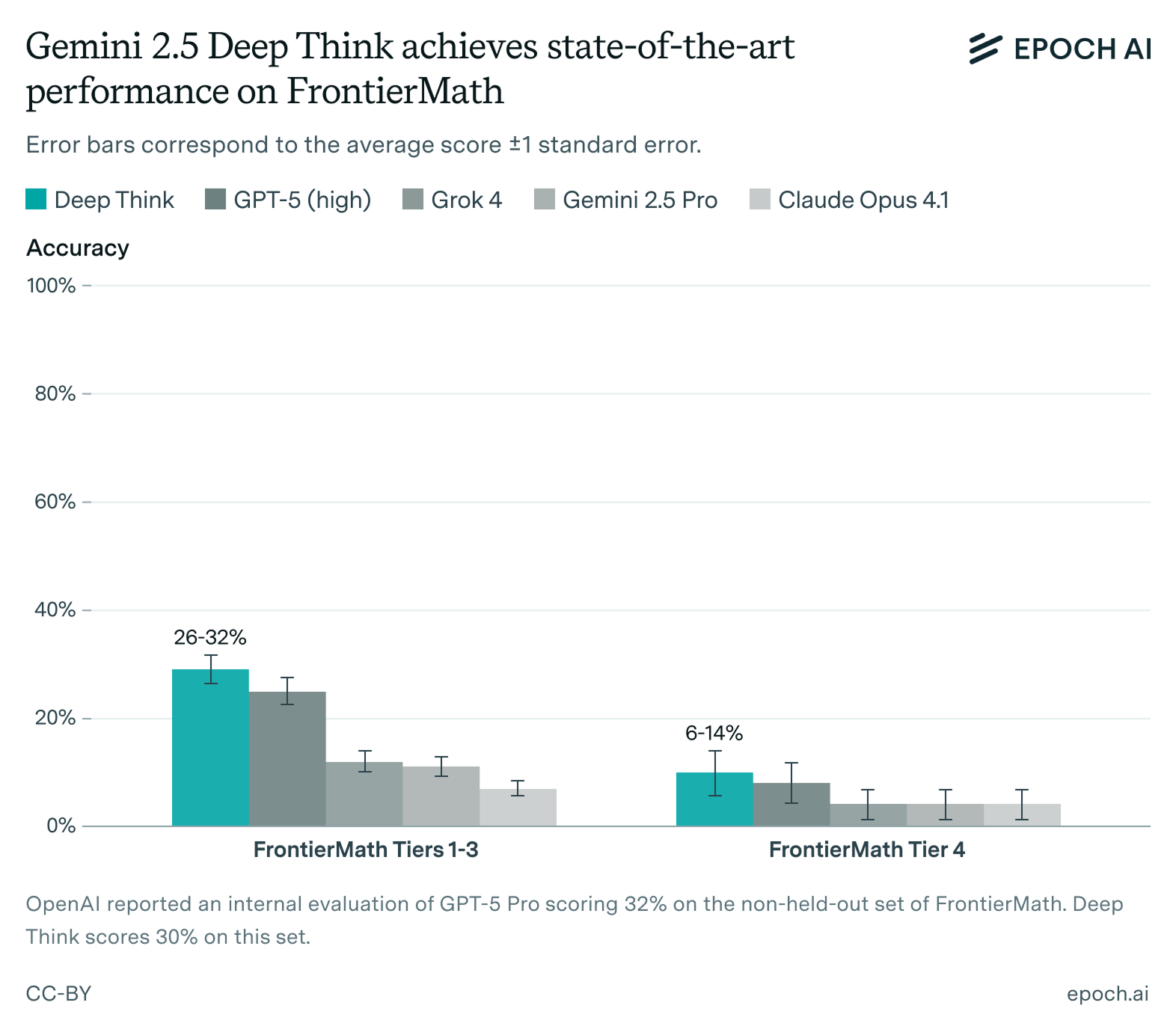
57% of problems have been solved at least once.
It has improved at using background knowledge and doing precise computations. It can be a helpful research assistant and may take a more conceptual approach to geometry. It shows limited creativity and sometimes struggles with citations.
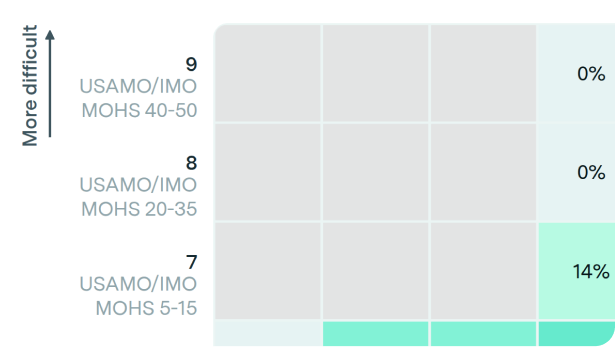
The problems gave AI only a slim chance to show new capabilities
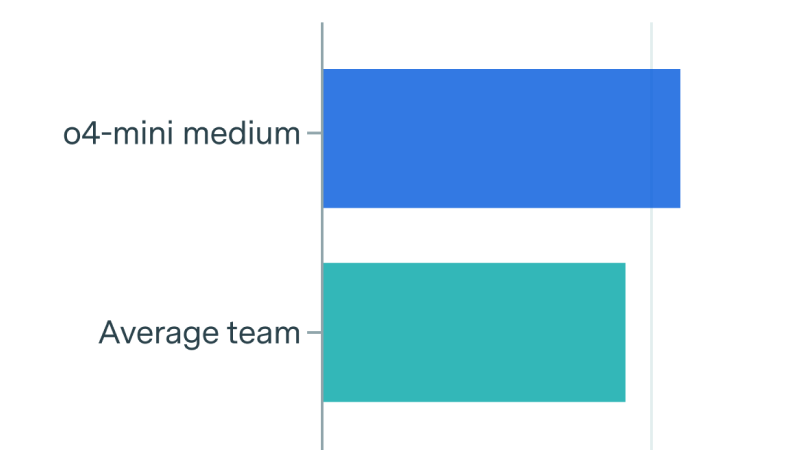
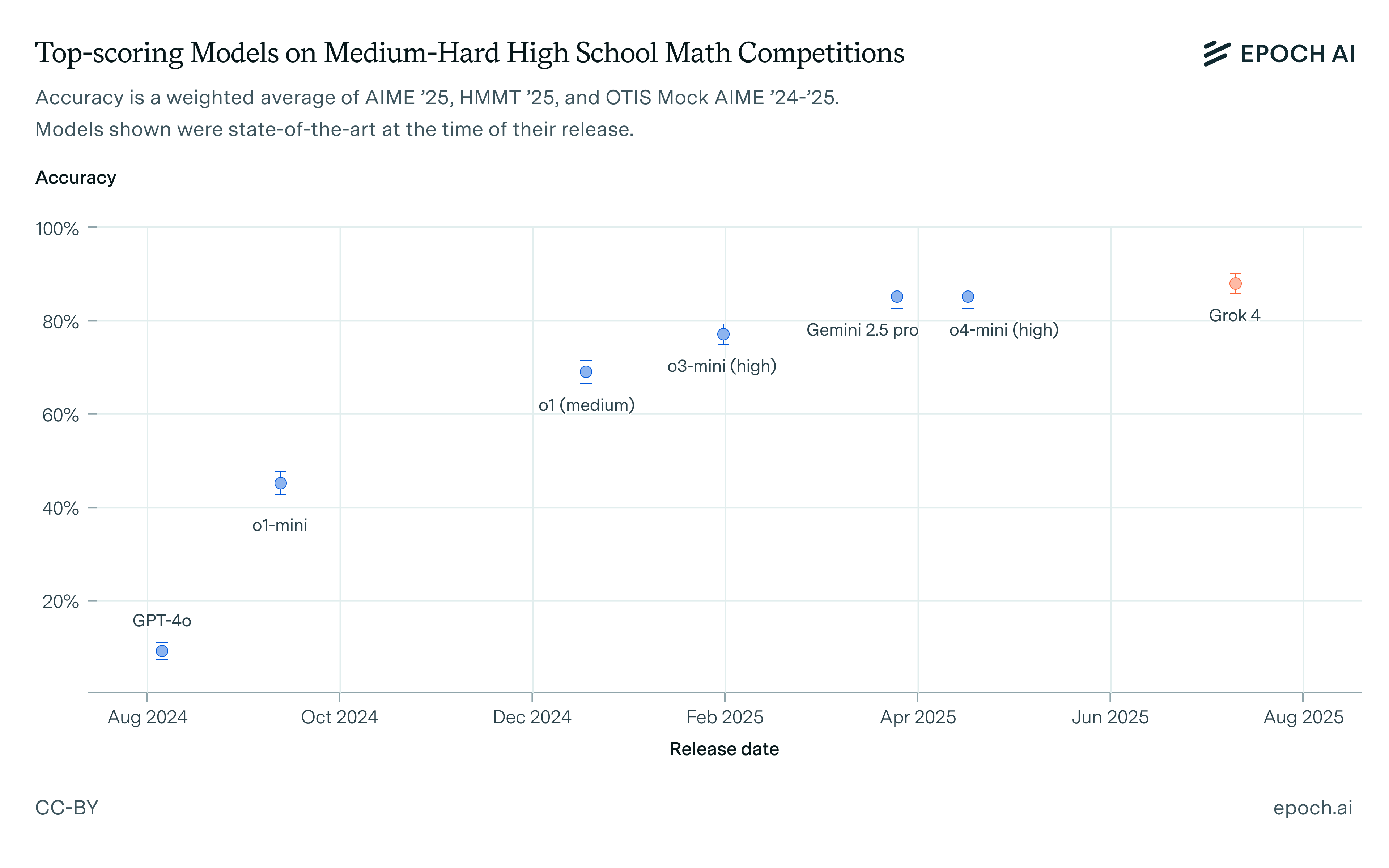
Reasoning models were as big of an improvement as the Transformer, at least on some benchmarks
It’s good at involved computations, improving at proofs from a low base, and useful for literature search. It still favors low-level grinds and leans on background knowledge.
Most discussion about AI and the IMO focuses on gold medals, but that's not the thing to pay most attention to.
Examining o3-mini's math reasoning: an erudite, vibes-based solver that excels in knowledge but lacks precision, creativity, and formal human rigor.
How do humans and AIs compare on FrontierMath? We ran a competition at MIT to put this to the test.

We clarify that OpenAI commissioned Epoch AI to produce 300 math questions for the FrontierMath benchmark. They own these and have access to the statements and solutions, except for a 50-question holdout set.

We are hosting a competition to establish rigorous human performance baselines for FrontierMath. With a prize pool of $10,000, your participation will contribute directly to measuring AI progress in solving challenging mathematical problems.

How will AI transform mathematics? Fields Medalists and other leading mathematicians discuss whether they expect AI to automate advanced math research.

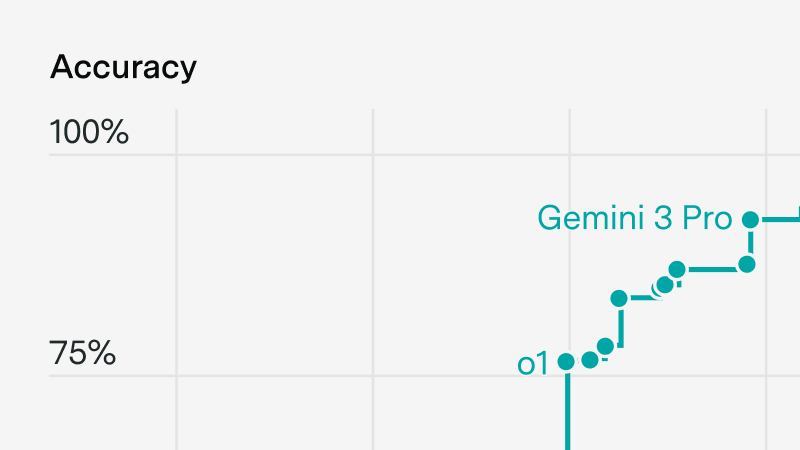
FrontierMath: a new benchmark of expert-level math problems designed to measure AI's mathematical abilities. See how leading AI models perform against the collective mathematics community.
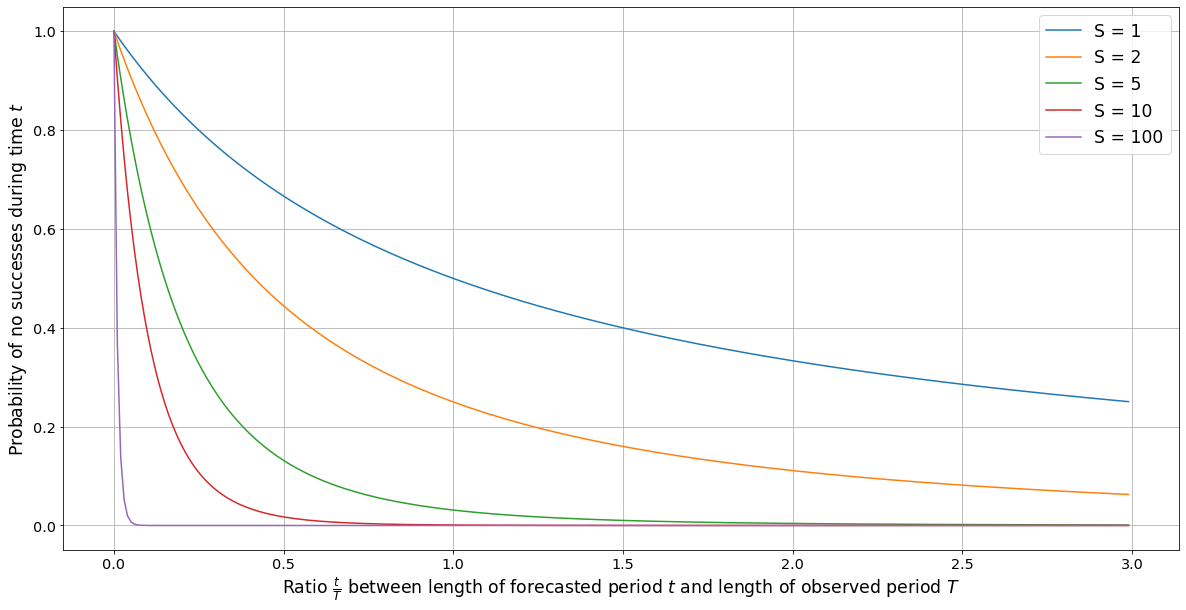
We explore how to estimate the probability of an event given information of past occurrences. We explain a problem with the naive application of Laplace’s rule in this context, and suggest a modification to correct it.