Daniel Litt is a professor of mathematics at the University of Toronto. He has been a careful observer of AI’s progress toward accelerating mathematical discovery, sometimes skeptical and sometimes enthusiastic.
Topics we cover: the hardest math problems models can solve today, whether there is convincing evidence that AI is speeding up math research, and if AI could ever solve Millennium Prize problems.
We also discuss how to measure progress in math, including Epoch AI’s new FrontierMath: Open Problems benchmark which evaluates models on meaningful unsolved math research problems.
Transcript
What’s the hardest math problem AI can solve today? [0:00:00]
Greg
Hello everyone. I’m Greg Burnham, I’m a researcher at Epoch AI and this is my colleague Anson.
Anson
I’m also a researcher at Epoch AI.
Greg
And we’re joined today by Daniel. Hi, Daniel.
Daniel
Hey. Nice to see you guys and meet you in person. I’m Daniel Litt. I’m a professor at the University of Toronto in mathematics.
Greg
I wanted to start with a fun one. Could you characterize what’s the hardest math problem that AI systems today can solve?
Daniel
That’s a good question. Every frontier model basically has gotten a gold on the last IMO. I think that’s a pretty good baseline for what you should expect. Later in the discussion, we’ll discuss a few open problems that have been resolved, either with the help of AI or autonomously by AI. I think it’s accurate to say those are about at the level of a mid-tier or low-tier IMO problem.
Greg
Gotcha.
Daniel
There’s some evidence that systems can do a little bit better than that right now. With some work, one can probably elicit better performance from current-gen models. But overall, it’s about the level of a contest problem—something you would expect a strong high school student or undergrad to solve in a couple hours.
Greg
One thing you’ve stuck your neck out on is that within the next year we might see mildly interesting conjectures resolved. What does that mean?
Daniel
For me, a mildly interesting conjecture is something that someone has stated in print. At least one person was really interested in it, and hopefully someone has spent at least a few hours thinking about it. There are a good number of problems at that level. I would expect that current-gen systems can resolve some of these with pass at 1 million or something like that.
Greg
Gotcha.
Daniel
I think arguably some recent examples actually fit that bill. Maybe that prediction has actually come true, although there’s some questions about exactly—
Greg
How interesting.
Daniel
How interesting such problems are, right.
Greg
You’ve referred a couple of times to time frame for human solve. Is that a metric you like in general?
Daniel
To be honest, not really. I think that’s not a great way to think about difficulty. An IMO problem—the best students in the world have about an hour and a half to solve it. That gives you some upper bound on difficulty. For a lot of those problems, if you gave them to a professional mathematician, they would actually take longer because they fiddle around, they wouldn’t be motivated the same way as in a contest. Also, solving a contest problem involves a very constrained set of techniques. In research mathematics, you’re not constrained at all. You try everything, you fiddle around, maybe break out a computer and work out some examples.
Difficulty is a funny thing. How do you judge it? A lot of the time, maybe the best way to judge it is after the fact. You look at the structure of the proof and say, “Actually this wasn’t that hard.” That’s a little dangerous—when we’re talking about evaluating a model, it leads to goalpost moving. The model comes up with a proof and you say, “Well, that wasn’t that hard. I just pressed a button.”
Anson
You’ve said often on Twitter that the amount of uplift you get from these systems is actually quite limited. But there are also people who feel the uplift is quite a lot bigger. How would you characterize that difference?
Daniel
There are some areas where the models are just better. If you’re working on optimization, for example, my sense is there are people at OpenAI who are experts in that area, and they’ve generated a lot of data and used their human expertise to guide the models. I would not be surprised if people in that area are getting more out of the models. Comparatively, in algebraic geometry and number theory, the models are just not that good.
There are areas more amenable to the tool use models have access to. If you’re trying to come up with a counterexample to some inequality, writing code is a natural thing to do. If you’re trying to come up with a counterexample to a conjecture about the intermediate Jacobian of a cubic threefold, there probably isn’t any code you can write that will help you.
That said, I also think people are probably misreporting how much the models are helping them. You have a new tool. It’s a lot of fun to use. But I think a lot of people are talking about accelerating science without trying to rigorously run tests. I’m happy to believe that some frictions are being removed, but there are also a lot of bottlenecks in research that the models don’t touch. Are you really accelerating if you’ve removed a bottleneck to opening a paper and finding lemma 3.7, but not to having a good idea?
Anson
The typical way I’d characterize differences in capabilities or the spikiness of AI capabilities across domains is through something like Moravec’s paradox. But within math, we also get this spikiness. Some of it comes from training data, some from what’s more amenable to the AIs. Is that explaining most of it, or is there something else?
Daniel
Doing research math is a high-dimensional skill. It’s a little different from contest math in that there’s not a finite set of known techniques that are useful. The models have not really succeeded in solving problems where creativity is required.
A lot of the jaggedness we see in math is just the same jaggedness we see everywhere. I don’t think there’s anything special. The biggest obstacle to models autonomously doing high-quality math research is the same as the biggest obstacle to automating anything: they can’t do long-context tasks. No task that takes a human six months can the models do. Once we start seeing models performing software engineering tasks at that scale, I would not be surprised if they also start doing high-quality math research. I don’t think there’s anything special about math in this regard.
Greg
One galaxy-brained take I have is that models are weak at spatial reasoning and visual-spatial intuition. I wonder if they’re especially good when there’s a more symbolic manipulation approach to solving something.
Daniel
That might be. I’m a bit skeptical of that kind of explanation. There’s a lot of diversity in how mathematicians think about mathematics. Some of us are shape rotators, some are more word cells.
Greg
I was curious whether there are mathematicians with aphantasia.
Daniel
Quite famously, even geometers who have aphantasia. There’s a huge number of mathematicians working on problems with lots of different approaches. That’s partly why there are mathematicians who I think are way better than me at math overall, yet I’m proving theorems they haven’t proved or probably couldn’t prove in the same amount of time. It’s because we have different approaches.
Now there are three or four models that can reasonably well solve math problems. They have slightly different approaches—much smaller diversity than humans. I think we see that reflected in the benchmarks. The set of problems being solved has quite a lot of commonality between the models, whereas all the problems in the benchmarks have been solved by at least one human. My sense is you should think of the model as a mathematician. There are certain problems they’ll be quite good at and certain problems they’ll be quite bad at. But maybe we shouldn’t read too much into what those problems are. It’s just an artifact of only having two or three models to look at.
Greg
How much transfer do you think we’re seeing in capabilities across different subfields of math?
Daniel
My sense is that most of what happens when you try to get a model to prove a statement in algebraic geometry is that it tries to find it in the literature or something very close, and maybe does one or two reasoning steps beyond that. Compared to what happens when you ask it a combinatorics question, it’s not really doing the same kind of real attempt to solve a problem.
Compared to a graduate student who knows all the stuff the model knows about algebraic geometry or number theory, that student would be able to do a lot more reasoning and really try to prove theorems. The models are superhuman in some mathematical subjects in terms of knowledge, but they haven’t necessarily learned the same techniques that a student with that same knowledge base would know. Just based on vibes.
Greg
What areas do you sense the models are stronger in for native reasoning?
Daniel
They’re definitely better than me at proving inequalities, that kind of thing. My guess is it’s easier to generate data and there’s probably a lot more data in that area than in algebraic geometry.
Greg
When you say an inequality, are we talking contest-style inequalities? Not something more interesting from analysis?
Daniel
Yeah, something where coding is useful—they’re typically very strong there. Every once in a while I need to prove an inequality, and now my first step is to explore what the space looks like by writing some code using a model.
Greg
You mentioned two things that seem in tension. One is that what models are missing is having a good idea, but another was if they can just do things for six months in many domains, maybe they’ll be good at math as well.
Daniel
That’s a good question. Those statements are in tension. I think there’s a continuum between just applying a well-known technique and developing a new technique. Arguably a new technique is taking 100 different things and putting them together in some way. At least one ingredient to doing that is time. It’s just not clear whether it’s the only ingredient.
My experience of doing math is very rarely that I have a brilliant idea that just solves the problem. Sometimes you wake up in the middle of the night and the problem is solved. But typically for that to happen, you have to marinate in the problem for months. There is some secret ingredient of time. I don’t know if my introspection is trustworthy enough to say whether that’s the only real ingredient.
There are other things that happen. You develop philosophies or analogies—some kind of mystical aspect to doing mathematics that we haven’t seen the models do. But it’s also BS, right? That mystical aspect is maybe just compressing a lot of ideas you’ve read or absorbed into some package that’s digestible to humans. Maybe it’s close to context compaction.
Greg
There are these big analogies—intelligence is search, or intelligence is compression—and we’re just better at that for now.
Daniel
I’m generally skeptical of those analogies. My sense is there are a lot of ways to be good at math. If you look at what different people are able to do, there’s not that much overlap in capabilities. I don’t know that there’s any mathematician who can prove the same theorems I’m proving. And there are plenty of mathematicians doing stuff where their way of thinking is just quite different from mine.
How helpful are today’s AI models for math research? [00:16:08]
Greg
Could you contextualize the utility you’re finding in the context of previous generations of tools? Literature search is better, but Google Scholar existed.
Daniel
Right now the tools are on a continuum with previous generations. Literature search—the models are now, at least for some tasks, better than Google or Google Scholar. That probably saves some time. Is it a lot of time? I don’t know. How much time does it save compared to going to the library?
Greg
That kind of 2% productivity, long-run productivity improvement.
Daniel
Right on trend. In general, those improvements seem to be fairly small. I would be skeptical that this is more than a percent or two.
Greg
If AI progress stalled today, you wouldn’t expect we already have baked in an explosion in quality of mathematics.
Daniel
I would expect similar productivity growth to what we’ve seen, which is maybe attributable to some extent to technology but probably mostly attributable to population growth. You can ask the same question about Google—how much did Google or email increase productivity?
Greg
Did you live through that? Did that feel like something?
Daniel
No, I was born in 1988. I got my PhD in 2015, so Google was already around by the time I started thinking about math. I have asked older mathematicians this question. The general consensus is that Google did increase mathematical productivity, but it’s hard to see if you try to look. It’s hard to come up with a proxy that lets you measure this. I don’t think it’s obvious from vibes that the advent of Google led to remarkable growth in good new mathematical ideas. I just think literature search is not where the main bottleneck is.
There’s another precursor to these AI tools, which is just the development of computing. We saw a lot of progress in a lot of different areas in the 60s, 70s, 80s. Maybe a famous example: Euler had this sum of powers conjecture about when there’s always a solution to a sum of kth powers being another kth power for some number of kth powers. The first counterexample was found via computer search. More famously, the case of fourth powers was resolved by Elkies in 1988 using a very clever computer search.
Greg
That method would have been dead in the water without computers, even though there was a lot of cleverness.
Daniel
That’s right. He found a way to make these questions accessible to a 1988 computer. Probably now they would still not be accessible to just naive brute force. But this was a huge development. If we just stopped with existing models, we would see some kind of natural continuation of that trend.
Greg
What would that look like? If right now we mostly use them for literature search and coding, maybe it’s the coding aspect, like AlphaEvolve style?
Daniel
Sometimes to make progress in mathematics, you have to do a search. A lot of the time that search involves some art to it. Maybe you’re working through a thousand different examples and you don’t have an algorithm to work through each example. Each example requires some little idea or executing some standard technique. It’s hard to write a computer program to do it.
In algebraic geometry, you might need to work through some steps. Parts of it you can automate with a Python program. Parts require some real idea. Probably where the models are now, you could imagine automating with relatively high reliability some of those example searches.
Greg
These are cases where much of it would have had to be manual work scaling linearly with problem size. And now—
Daniel
Now some of that work can be cut down. I think that’s something I’m really looking forward to. Sometimes I write a paper that’s just “here’s a beautiful construction.” To find it, I needed to do some search and think about where the right place to look is. We already see AlphaEvolve as maybe some baby version of this—automated search aided by a clever LLM. I can imagine that having a really significant impact on mathematics. But it would be in the same spirit—it wouldn’t mean automation of mathematics.
Greg
A continuation of figuring out how to use computers to reduce labor or open up new avenues.
Daniel
Yeah. Think about the proof of the four color theorem or Kepler’s conjecture—a similar thing where you have so many cases that need to be checked and you have a computer to figure out how to do that.
Greg
Could you get lots more of this if you way amped up the compute?
Daniel
People actually do this. Computational number theorists—I’ve had really fun conversations where someone takes a problem and says, “This problem will be solved in this year” just by taking Moore’s Law and saying when it will no longer be compute-constrained. Those predictions are reasonably accurate.
Maybe you’ve heard about this example: can you write an integer as a sum of three cubes? We know about how hard each instance of this problem is. You can double the computer, triple the computer, and you get a few more interesting integers. But there’s a question as to what extent that constitutes progress. There are people more excited about it than I am.
I’m imagining things where you’re maybe looking for an example of some construction where there’s not just a known algorithm, and instead you ask GPT to cleverly search and let it come up with ideas.
Greg
If you give it enough test time—
Daniel
Maybe eventually it will come up with something. I’m not imagining it coming up with better and better ideas as the test time continues, but just trying more and more things.
Junk papers, LLM-generated proofs, and the refereeing crisis [00:23:36]
Greg
Are there problems that AI is causing right now? Cheating in college is clearly an issue. What about junk papers?
Daniel
There’s definitely junk papers. I started counting in maybe September, papers on the arXiv with “Hodge conjecture” in the title or abstract. The Hodge conjecture is one of the six remaining open Millennium problems—the one where the statement is probably hardest for a layperson to understand. For a long time it was safe from cranks because you just couldn’t write anything comprehensible about it. Now that’s no longer true. Frontier models can write reasonable-looking text about the Hodge conjecture.
In September and October, there were something like 12 or 13 papers posted to arXiv math algebraic geometry with Hodge conjecture in the title or abstract. All but one were nonsense. I can’t prove they were generated by an LLM, but based on the writing style, it was quite clear. There were maybe six repeat offenders.
To what extent is this causing a problem? It wasted several minutes of my time. As the LLMs get better at writing coherent-looking text, you know, before you would have to spend 10 seconds to find nonsense. Now you have to spend a few minutes. The most serious offender—the argument really didn’t make sense, but I had to go to the middle of the paper and see that some statements were just nonsense. The introduction was totally reasonable and interesting and making quite dramatic claims. It wasn’t a trivial job to check that it was BS. I think that problem will get harder.
In areas where formalization is not really practical right now, that’s going to be an issue. You can imagine way worse versions where a graduate student stuck on a problem uses one of these models to generate a nonsense proof of a key step. Maybe 99% of the paper is correct, but it has no value because of some nonsense.
Greg
People have been bullshitting since time immemorial.
Daniel
There are lots of wrong papers out there. But a lot of this is about marginal cost. The marginal cost of lying and cheating is getting a lot lower.
Greg
If capabilities froze, is this at the level of “society manages”?
Daniel
It’s contributing to a refereeing crisis in mathematics. There are way more papers being generated than can be refereed carefully. It would continue to worsen. A lot of that is about incentives in math academia, not the models themselves. We’d manage the way we’ve been managing, but imperfectly. I do think there’s some hope—the models can also help check papers, and there are already nice tools being developed.
AI enables searching through problems at scale [00:27:21]
Anson
I want to think a bit longer term. A big part of progress in AI and math is about compute and scaling. One of the things we discussed was getting AIs to run lots of examples. How should we expect fields of math to evolve as we get more of this ability to run lots of experiments at scale?
Daniel
You’re asking about the thing I was proposing earlier where you’re working on lots of examples, not trying to get models to solve the Riemann hypothesis.
Anson
Exactly.
Daniel
I think we’ll see a continuation of previous trends. We’ll be able to work through larger volumes of interesting examples. The main benefit is that the cost of trying the first dumb thing you would think of gets very low. Historically, if I want to find a construction, I have to sit down and try a few things. Even if that requires very little cleverness, it still takes a few days of my time. I’m a busy guy. Moreover, this might be just an idle question and I have other things I’m more excited about. There’s opportunity cost.
The marginal cost of trying something will get very low. Even if you’re asking a model that’s not that capable, that’s very valuable. One way mathematics moves forward is you look for examples of cool stuff and you occasionally discover such examples. That doesn’t necessarily require deep insight or brilliance. It just requires spending time. Having an automated search for cool stuff would be a really big deal.
There are some sporadic examples of cool things—the sporadic finite simple groups, the exceptional Lie groups. People search for them in a fairly principled way. But ultimately, you have to make a discovery. A lot of the time, you make that discovery by noticing someone worked out a cool example and you observe some interesting property. Some of the projects I’m most proud of are where I noticed something cool in the literature and drew some consequences out.
Greg
That can be very productive.
Daniel
It’s a big part of how math moves forward. It’s not just the most brilliant people proving amazing theorems. There’s a huge background of people who are more workmanlike doing work and thinking about lots of cool stuff. Every once in a while, they find something important. That’s something where the ability to automate is probably a huge deal, even if the automation is not at the level of the median professional mathematician.
Anson
How quickly do returns to running these experiments diminish? Would a thousand examples be much more helpful than 100?
Daniel
It depends on how you’re searching. The most interesting examples, at least for me, are where there’s an infinite collection of objects and you’re looking for 26 of them. They’re really very special exceptional things. You’re not doing brute force search; you’re doing some cleverness. The models can automate a little bit of cleverness. I can imagine situations where searching through a million things is way more valuable than searching through a hundred.
Anson
Which particular fields would be most amenable to this?
Daniel
I think everything. There are certain exceptional constructions in algebraic geometry that I like—the 27 lines on a cubic surface, 28 bitangents to a plane quartic. These examples have interesting properties; they’re connected to the exceptional Lie groups. This is all known classically from the 1800s, but it would be amazing to find new cool, weird constructions like that. That doesn’t seem impossible. People do regularly find cool examples of that nature.
Anson
So compute is really important. Then why aren’t all the mathematicians trying to go into a big lab and work with OpenAI or DeepMind where there’s a huge amount of compute?
Daniel
Model capabilities are not really there yet. Right now, the way you would try to automate this is run a model in a loop saying “look for a cool example of this phenomenon” and track what examples you’ve looked at so far. When you try to ask the model to do this, it will basically fail 100% of the time. At least in algebraic geometry, the capabilities just aren’t there. They can’t work through an interesting example. Maybe that’ll happen soon.
Anson
If we extrapolate the trend on FrontierMath, maybe by the end of next year it’s probably going to be saturated.
Daniel
I think saturating FrontierMath is somehow not relevant to doing this.
When will AI be good enough to publish in top math journals? [00:33:49]
Greg
Let’s ask about timelines on the scales you care about. You made this bet with Tamay Besiroglu—3-to-1 odds that by early 2030, an AI system would not be able to autonomously produce a paper publishable at today’s standards in the Annals, the top journal in your field. That’s you giving that a 25% chance of happening.
Daniel
I think there’s some chance I was overconfident. I’ve probably revised my estimate more toward my side since then.
Greg
If I recall, Tamay has moved toward you, and you’ve moved toward him.
Daniel
Yeah, it’s beautiful. There were a few more constraints. First, it has to be repeatable capability—although if the model proves the Riemann hypothesis, probably we’re past that.
Greg
Repeatable for the sake of it not being a quirk.
Daniel
Not like it just finds one weird example that’s a counterexample to some major conjecture. Regularly producing stuff. And there was a cost constraint—the marginal cost had to be about $100,000, which was some estimate of the marginal cost of getting a human mathematician to produce an Annals paper.
Greg
You don’t make millions a year, so—
Daniel
Probably we’re not going to spend $100,000 on compute trying to do this, although maybe. But if in 2031 it’s doing it for $1,000, then easy resolution.
Greg
Just acknowledging—25% of this happening in five years. That’s a lot of progress from where we are today.
Daniel
I think that’s very plausible as a forecast.
Greg
What were your updates since then?
Daniel
25% feels a little bit low, not really based on anything besides vibes. I think it’s reasonably likely that models will be able to autonomously produce very high-quality research in that time. That bet was supposed to be a proxy for “will models have absolute advantage over humans in doing math research.” I’ve come to the view that it’s a very poor proxy.
One reason is this: right now there are mathematicians much more capable than me whose marginal cost of producing an Annals paper is much lower. They’re doing one a year. I’ve produced one Annals paper so far and a few other papers in comparable venues. But they don’t have absolute advantage over me in some sense. We have different points of view and we’re doing mathematics in different ways. There are areas where I have substantial advantage in proving interesting theorems or understanding interesting mathematics.
Greg
If models have five years from now the same characteristic they seem to have today—they’re all kind of doing the same thing—it’s like a mathematician.
Daniel
That’s right. You can imagine models that are very strong at certain types of mathematics, even proving theorems of many different shapes. But you would still maybe expect—the fact that Maxim Kontsevich is around doesn’t mean there’s no role for other mathematicians.
Greg
The cost criteria is relevant there a little. Let’s imagine the cost was zero and we weren’t at 200 tokens a second. What if you put your own brain in a data center and could run 100 subjective years in a minute? Could you give every mathematician in the world a run for their money?
Daniel
That’s a good question. Right now, because I’m limited in various ways, I mostly work in areas where I’m very good. Every once in a while that involves learning a new technique or developing a new technique—something models haven’t really shown capability of doing—which takes a lot of effort. If I was not so constrained, I could start trying to learn other people’s techniques more easily. That depends on my capability of doing some kind of continual learning.
When we’re comparing to a model, maybe it depends on how things develop in that direction. That said, my expectation is that no, I would probably do a lot of cool mathematics. I hope I’d be very embarrassing if I was given so much resources and was not able to do it. But other mathematicians would still be very valuable. There are certain styles of thinking or modes of thought within mathematics that I do not feel suited for.
Greg
Does AI break down comparative advantage dynamics that we’re familiar with?
Daniel
I don’t see a reason to think that. We’re also asking the question without resource constraints, which is critical to analyzing comparative advantage.
Greg
Five years from now might look like there’s math the AI just happens not to be good at, humans gravitate toward that, and a few humans are guiding the math the AI is good at.
Daniel
I imagine one would also try to develop some kind of taste evaluation for the AI and try to get it to do interesting things on its own. Five years—maybe 25% is still around where I’m at. I would go a little higher. I think it’s very likely within 15 or 20 years that there will be a lot of areas of mathematics where automated systems have advantages over humans. I would be surprised if it doesn’t happen.
Greg
What are you using to draw the trend line?
Daniel
Primarily vibes. I’m participating in the age-old tradition of AI forecasting where five years means you think it will happen soon, and more than five years means anything from five years to never. Forecasting AI progress in the 60s and 70s—we’re saying 5 to 20 years in the same way.
Greg
Whatever those sort of—today there’s “soonish probably maybe I don’t know” and “oh come on who knows.”
Daniel
What I’m saying is I think it’s reasonably likely—25%—but far from certain that if current trends continue, we’ll see high-quality automated research.
What are the returns to intelligence? [00:42:15]
Anson
Maybe we should see what happens when we go 15 or 20 years or more into the future. How do we compare the scaling of one person thinking for 100 years versus 100 people thinking for one year? Is there a way to characterize how much better a person gets over the course of 100 years?
Daniel
Let me connect this to something we discussed earlier about deciding how hard a problem is. There are a lot of problems that clearly have the flavor of “if you had a Manhattan project to solve them, they would be solved pretty fast.” The primary thing missing is attention. Even if you just got a few mathematicians to really devote their time to them, it’s almost certain they would be solved.
Greg
Can you name such problems?
Daniel
The inverse problem for the last sporadic simple group—the Mathieu group M23. That’s probably a hard problem. A bunch of people have thought about it. I absolutely think that if the US government devoted a substantial portion of its $200 million annual mathematics spending to solving that problem, it would get solved.
Greg
That’s helpful.
Daniel
If you ask a single person to think for a long time, there are a lot of problems where you’d expect a solution. There’s a problem I started thinking about in 2016. It came up in a talk I saw. I really liked it, tried to solve it, didn’t really get anywhere at the time, but kept it in the back of my head and then solved it in 2024.
You learn stuff, you connect it to the things you’re thinking about. There’s the problem of matching your knowledge to a conjecture, knowing a conjecture even exists. As time passes and you try various things, sometimes you eventually hit on a solution. In fact, one of the ingredients of the solution just did not exist until 2023. Sometimes you just have to wait for someone else to do some work.
Greg
That makes the individual mathematician thinking sound a bit more like a group of mathematicians, because someone else did that other piece.
Daniel
Right. Some of it is just time passing. You learn things, you try different things, you become a better mathematician, you learn techniques. A big part of mathematics—and I think this is something where humans still have a very substantial edge over models—is you have a new object and you try to make friends with it. You play around with it, work out various questions, examples, and relevant special cases. You learn about an object that way and develop some theory for it.
I really worry about model capabilities in the current paradigm. Right now for a model to learn about a new subject, you have to train a new model. Peter Scholze is developing this theory of Gestalten, which is some new kind of space. None of the models know about it. They can go online and look at the paper, but they can’t take the object and try to work with it.
Greg
Skimming it sort of level.
Daniel
They can’t make friends with it. A human can do that over time. The main way that time helps in solving a problem is you become friends with the objects and develop some intuitions. The models just can’t do that without training entirely new models. The marginal cost of solving a problem that involves some new object or new way of thinking is the cost of training a model—huge. Way, way worse than asking a human to try to understand the object.
Greg
Continual learning seems very important even for this.
Daniel
It’s not just continually learning in the sense that I can read a paper and understand the object. To behave like a person, it’s playing. I guess we have seen some attempts at getting models to do self-play with mathematics, but it’s not clear what kind of success that has had.
Greg
You see glimmers of this in chains of thought where they try different things and play around a little and eventually hit on something. Probably because it’s what they’ve been trained to do for solving a concrete problem, rather than this more taste-oriented thing of “I’ve got a better angle on this.” Maybe that scales.
Daniel
Yeah, I’m not necessarily skeptical.
Anson
The other part I found interesting was the limits to parallelization. There was this dependence from another result in 2023. If we’re comparing “Daniel thinks for 100 years” versus “100 Daniels”—maybe the 100 years is more productive in the long run with the continual learning, but maybe there’s a parallelization bottleneck, or you need something else to happen throughout the math economy.
Daniel
That’s accurate. This result took input from two deep theories: non-abelian Hodge theory and the Langlands program for function fields. The main thing that allowed this project to go through was someone else—EsnaultD’Addezio and Groechenig—had proven something using the Langlands program for function fields and the theory of companions. That’s not something I would have thought of. It’s close enough to my area that I knew about it, but it’s really a very creative and important development—different from the things I was thinking about.
It’s really not clear I would have even known it was relevant if I was just thinking about this problem for 100 years in isolation. Historically, asking a human to think about just one problem for a long time in isolation is probably not that productive. You try a bunch of things and at some point hit diminishing marginal returns.
Greg
Parallelization—diversity is important there. Have you tried to get models to do something surprising or more original, even if wrong?
Daniel
For sure. Right now, anytime I think about an open problem, the first thing I do is ask models for some ideas. They’re almost always nonsense.
Greg
Yeah.
Daniel
I’ve never, maybe never, gotten an idea that passes the sniff test for a deep open problem.
Greg
It feels like random initialization in some abstract way should solve this problem, but we’re just not seeing it.
Daniel
You can also try—every day I wake up with a different random initialization.
Greg
That’s right.
Daniel
There’s still some kind of persistence in who I am that limits my ability to really search the full space of mathematics.
Anson
The other aspect of this was returns to intelligence. If you had a million Ansons trying to do the stuff that you do, I don’t think I would make very much progress. And then the next scale—there’s a million Daniels compared to superintelligent mathematicians. Would we expect the same dynamic where the superintelligence is just so much better, no matter how many times you scale up the number or duration of researchers?
Daniel
Let me push back on the claim about you versus me. I find it plausible that if you really devoted a long time to learning cool mathematics, you would be able to do cool mathematics. Probably it would be different math from what I’m doing because we have different preferences and capabilities. But you seem like a sharp guy. I don’t see a reason to think you wouldn’t do interesting mathematics if you had the motivation and resources devoted to it.
Similarly, with a superintelligent AI—whatever that means—intelligence, even within a fairly narrow domain of math research, is an exceedingly high-dimensional thing. We see comparing different human mathematicians that we’re very good at very different things. Even if you imagine an AI that’s very capable of solving interesting research problems, it’s not clear it’s very capable of solving all interesting research problems that all humans are good at.
Greg
We could try to sharpen the question by saying—of whoever is smartest subject to being a good fit for a particular field—what does that scale of productivity look like? Are there people where you avoid working on a problem if you know they’re working on it?
Daniel
That happens in some sense, but I don’t think of it as about capabilities. For example, there’s a very active area now, p-adic Hodge theory. I’m adjacent to it in various ways. I don’t really work in the area, but it’s because it’s a very fast-moving area. If I wanted to get into it, I’d have to learn a lot and catch up to people working very quickly. It’s more about opportunity cost.
Greg
So we don’t see so much the returns to whatever we call intelligence in humans.
Daniel
I have a two-and-a-half-year-old who I think is very sweet and very sharp, but she’s not doing math research right now. She’s two and a half. There are absolutely differences in capability between people. But among professional mathematicians, it seems mostly about the fact that it’s a high-dimensional space and people are specialized in different parts of that space.
If models continue in the current paradigm where they’re very jagged and have narrow capabilities compared to a person, you can still imagine substantial value. The fact that we specialize in tiny little zones means basically all problems are attention-bottlenecked. The number of people who even know what the words in a problem statement mean is like ten. You can imagine those problems are not very difficult—it’s just no one has had time to think about them.
Anson
Another way to think about this for people who care about superintelligence and fast AI takeoffs: suppose we increase the rate of math progress by some measure and break it down into three factors—more AI, AI thinking for longer, and smarter AIs. What would the breakdown be?
Daniel
Whatever, it’s not clear to me to what extent progress in math research has increased over the last 40 years prior to AI. Maybe my sense is that productivity growth comes down largely to the increased number of mathematicians. Once you expect AI to reach parity with humans, maybe you expect it to come down to number.
A little concern: why are there returns to numbers of humans? Part is attention. Part is diversity of modes of thought. And maybe you don’t have as much of that with AI depending on how systems develop.
Probably a lot of the returns to increased number of mathematicians just comes from increased time spent thinking about different problems, increased attention. I expect you could see substantial returns to that even with not very capable AI.
What about returns to intelligence? This is not such a well-posed problem. Intelligence is a very high-dimensional object in my view.
You can imagine the ability to search through some high-dimensional space of proofs in a clever way being very valuable. Presumably the proof of the Riemann hypothesis will involve developing various objects and theories that don’t yet exist, and that would take a lot of searching in some very high-dimensional search space.
I think a lot of the way that search happens in practice is that normal mathematicians are just thinking about objects, doing low-level search, working through lots of examples, noticing patterns. Then people start to encapsulate those patterns into the relevant objects. That high-level theory building, which we attribute to maybe the most brilliant mathematicians, really depends on a background of just hard work and example analysis. Arguably some of that is also attributable to scale in the number of mathematicians.
Will AI solve Millennium prize problems? [00:59:50]
Greg
Fun little question: what are your solve probabilities over time for the Riemann hypothesis, or pick your Millennium problem?
Daniel
The ones I’m probably most familiar with are Riemann hypothesis, Birch and Swinnerton-Dyer, and the Hodge conjecture. Of those, the Riemann hypothesis is the one where in some sense we know what a proof should look like.
There’s an analogous conjecture—the Riemann hypothesis for varieties over finite fields—proven by Deligne in the 70s. The part most closely analogous is the Riemann hypothesis for curves, proven by Weil much earlier. We really have some sense of what the shape of a proof should look like—it should look like Weil’s proof.
Weil gave two proofs of the Riemann hypothesis for curves. The problem is various maneuvers in that proof don’t make sense for the integers rather than a curve over a finite field. One has to figure out how to make those maneuvers work. This is science fiction, but there’s at least some kind of plausible way of thinking about a proof.
Many mathematicians have thought about how to make these maneuvers work. I think there’s some chance one of those attempts will work out in the next ten years. The number I put on it is like 15%. A fairly small but not zero probability.
In general, if you look at solutions to major open problems, the time difference between the last big idea you need and completing the proof has been fairly small. For Fermat’s Last Theorem, the distance between the Taniyama-Shimura conjecture and the proof—temporally—was not so long.
Greg
That makes it sound a little like, because the Weil conjectures for curves are decades old, maybe—
Daniel
In fact, people expected, when Weil proved the Riemann hypothesis for curves, that the proof of the Riemann hypothesis would come soon. That’s my understanding of the history. And then it wasn’t. So people don’t really know what the missing new ideas are. We have some very vague sense as to what their shape should be.
Greg
Has your time prediction changed with AI progress at all?
Daniel
I haven’t really—I don’t feel like I’ve seen some aspects of what I think is necessary for high-quality research. I haven’t seen sparks of it from AI. The distance between solving an IMO problem and doing high-quality math research is larger, in my view, than some other people seem to think.
I would say it has not moved so much. Right now the tasks AI can help with, and the tasks it seems like it will soon be able to help with, don’t seem to be the primary bottlenecks for resolving major open conjectures. That said, I gave 25% chance that AI will be able to do high-quality research. Maybe some 5% of that—depending on how that works, it could be on track to do something crazy.
Greg
For fun: Millennium Prize Problems. These big targets in math. Where are you on how likely you think those will be solved and whether AI will contribute substantially?
Daniel
My prediction is that zero will be solved autonomously by an AI in the next ten years.
Greg
Ten years?
Daniel
In total, I would say maybe 0 to 1 I would expect to be solved in the next ten years. There’s arguably been some progress on Navier-Stokes, which is far from my area, but I don’t find it totally implausible that will be resolved. The current news about it is about a team working jointly with DeepMind—maybe more traditional deep learning techniques, not LLMs or reasoning models.
Greg
One of the seven was resolved not too long after they were codified—the Poincaré conjecture. Our base rate is not zero.
Daniel
But I think with a couple of them—Hodge conjecture seems like there’s just no ideas. BSD similar. With Riemann hypothesis, we discussed there’s some kind of ideas, but it’s unclear how far away we are. It could happen in the next ten years. It could happen in the next hundred years.
Greg
Relating this to your other AI timeline senses—the 25% chance that we hit Annals-level papers in five years—some part of that goes toward—
Daniel
My expectation is that seems very possible without starting to knock out Millennium problems.
Greg
Basically not much of that. And then your 20-year timeframe, you know, it’s beyond—when this has had a lot more time to brew and develop.
Daniel
It depends on acceleration of AI progress itself or self-improvement. I’m generally pretty skeptical on that in the same way I’m skeptical of acceleration in general.
Greg
This might transition us into measurement and benchmarking. First with a speculative version: you’re not seeing so many glimmers of some things you think are critical. What are those things?
Daniel
Let me imagine what would be signs for me. Making a new interesting definition would be important. Showing some kind of research taste would be important—asking a question or discovering even just conjecturally some new phenomenon. A lot of the most important mathematics is actually just making conjectures. That’s hard to get current systems to do.
Developing a theory—related to making a definition—some kind of theory building. I don’t think we’ve seen that. It’s already been very surprising to me that the models are able to learn during training techniques that people use and apply them. That’s the thing that really changed with reasoning models—they were able to take well-known techniques and start to really apply them with high reliability.
If they were to develop a new technique—there’s some continuum between old techniques and new techniques—if I were to recognize something like that, that would be a sign. I don’t think any of those things have happened. Will they happen soon? Maybe.
Greg
Of the tasks that constitute doing math, which are the hardest for AI? Theory building and conjecturing seem critical. Are there others?
Daniel
I try to have all of my papers contain a new idea. It’s not true for all of them—sometimes you find a trick to resolve an old conjecture. Most people don’t have a lot of new ideas. Mathematicians typically write 1 to 2 papers a year. Compared to other subjects, we’re not very productive in terms of total output.
That thing where you develop a new technique—that’s a genuine new idea. And what does that even mean? That’s the hard part.
Greg
When you see it.
Daniel
That’s the hard part. Yeah. People like to point out for AlphaGo—move 37 was described as an inhuman move, a move no human would have thought of. The AI stepped outside the search space humans had looked at. Would it be enough of a move 37 to just have a new idea, even if it was something a human could think of?
Daniel
It’s funny. In some sense that’s happened prior to these AI systems. The proof of the Kepler conjecture, proof of the four color theorem—those are inhuman proofs. A human was in charge, but the majority of the work was some kind of horrible casework done by a computer. Or beautiful casework—there’s no such thing as horrible math. Everything true is beautiful.
Greg
You’ve said you encourage your grad students to adapt their way of thinking to this.
Daniel
You should prove things by any means necessary. Why tie your hands behind your back? That’s some kind of move 37 arguably, which had nothing to do with an AI system. Would I consider an AI system generating that kind of proof—automating a huge amount of casework—to be a move 37? No, because we’ve already seen humans do it.
You can also imagine some kind of weird Lean proof of some hard theorem with no comments that’s very hard to extract a human argument from. If you’ve ever looked at Lean code, it’s not easy.
But if I were to see something I considered to be a new technique—something where I couldn’t really find a precursor in the literature—that would be very exciting.
Greg
Part of why I pay attention to your commentary is you seem to be trying to do an honest job of avoiding goalpost moving.
Daniel
There’s a huge temptation to move goalposts. Right now, the signal you get from AI solving a problem is partly “the AI is capable” and partly “the problem is easy.”
Mathematicians have a habit of saying, “This problem was solved by AI, but it was actually easy, so maybe we shouldn’t update.” To some extent that’s true. But we should try to evaluate what the models are doing and see: if a human had written this, would I be excited? For these recent problems—if a human told me they solved this problem with this proof—which has happened—I would say, “Oh, that’s cool.” And that’s also how I feel about the AI doing it.
Greg
“Oh that’s cool. Life goes on. But don’t diminish it in the moment.”
Is math full of low-hanging fruit? [01:11:54]
Anson
You’ve mentioned on Twitter that whether solving these problems is impressive depends on how much human effort was put into it previously. Is it possible to go through these problems and say how much effort has been put in?
Daniel
You can look at the paper where they were proposed and how many citations that paper has. For the ones that were solved, I actually don’t know. The hard version of Problem 124 that was not solved—the paper has 14 citations. For a 1996 paper, that’s not a lot in math.
Greg
14 is not nothing.
Daniel
There are plenty of papers from 1996 with zero citations. But many of those citations probably aren’t to the problem of interest—the paper has a lot of problems.
Greg
Do you know how many people are working on the p-curvature conjecture?
Daniel
Very few. It’s one of my white whales. I’ve thought about it a lot. Probably very few people are actively working on it—I’d expect I know all of them. Fewer than 20, I would guess. Historically there was more activity in the 80s, 90s, and early 2000s, then people got stuck and it died down. Maybe now there are some new ideas in related areas.
Any question where not a lot of people know what the words mean is automatically going to have small attention. There are probably a couple thousand people who know what all the words mean.
Greg
Is there a selection effect where problems get characterized as embarrassing to work on?
Daniel
Like the Collatz conjecture—it’s also a crank magnet. A lot of problems where the expert opinion is “we don’t really have the right techniques to solve it,” there’s a bit of “who are you to think you can solve it.”
Are there a lot of quiet, small attempts on big famous problems that wouldn’t be announced? Probably everyone thinks a little bit about famous problems, including quite well-known people who have published papers on related topics. But what does it mean to try to solve a problem? A lot of the time you go, “It’d be nice to solve this,” then try nothing.
Greg
What does it feel like when you’re like, “Maybe I do have an idea worth trying”?
Daniel
Sometimes you wake up in the middle of the night with a great idea. A lot of what I do when trying to think about a problem—either you start with an idea, or you start with a new technique you came up with some other way and try to extract value by thinking “what problems is this relevant to?” That’s an opportunistic approach.
Sometimes I do set out to solve a problem or prove something—or more accurately, try to understand something and then benchmark my understanding by proving something interesting. You take the minimal example where you don’t know how to approach it via techniques available to you, try to work it out, develop techniques to handle that minimal example, then see how far you get.
Greg
From a data analysis perspective, if we take citations as a metric, would there be some nonlinear correction needed?
Daniel
It might be overstated—there are a lot of papers that cite work on the Riemann hypothesis without making any meaningful progress toward the hypothesis.
Greg
Then it’s a wash.
Daniel
I think it’s very hard to evaluate difficulty this way.
Anson
There’s also the junk papers problem.
Daniel
There are also a huge number of papers claiming to prove the Riemann hypothesis, which obviously makes it harder. A huge number of computer science papers cite things relevant to P versus NP. Are they really making progress on it?
How Daniel has adapted his professional life to AI progress [01:18:47]
Greg
Before we move on fully to measurement—have you made or are you planning ways you adapt your professional life to survive or thrive in this world?
Daniel
There are certain things I’m doing with the expectation that AI will become more capable. Right now there’s a lot of work on formalizing mathematics in Lean or other proof verification software. I’m not really working on this because I expect that tools for vibe formalizing will dramatically improve over the next few years.
Greg
Vibe formalizing—just to catch up with you.
Daniel
Partly it’s because I’m not an expert in it. I played with it a little bit. I don’t think I’m adapting which problems I think about or what techniques I’m using based on the expectation of improved capabilities.
Part of the reason is that I don’t view my job as proving things. I view my job as trying to understand things. When you prove a theorem, that’s a benchmark of understanding. A lot of theorems or conjectures are sinks rather than sources—meaning if you’ve developed a technique that can prove the theorem, it shows you’ve understood something. But the actual value is in the understanding.
This is maybe something that explains part of the difficulty in training AI to do good mathematics: a lot of what we write does a poor job of conveying the actual value proposition of mathematics, which is that there’s a human who now understands the subject better.
Greg
The words in your head that amount to that understanding are not the words that appear in the paper.
Daniel
You try to convey your intuitions, but it’s just a famously hard problem. If I could tell my students “this is how you should think about this object”—I do tell them that. But it doesn’t convey anything valuable. It gives them some hint they can decompress by playing with the objects themselves, but you can’t directly convey it. It’s just not contained in the text except in some very compressed or hinted-at form.
Greg
I can imagine—you write up a paper that’s “here’s the proof of this conjecture” and the route is so much more roundabout to developing that theory that there’s just not much training signal.
Daniel
A lot of work is—when you prove something, you often have a very straightforward idea for how the proof should go. Then there are various roadblocks that come up, maybe because we don’t understand some intermediate objects in the proof. You find some way around it. The actual written argument looks very ugly. Of course you try to hint at “this is what I’m actually trying to do,” but how successful is that?
So how is this related to how AI affects my personal planning? AI can’t understand something for me. Because of the difficulty of conveying intuition, even if a model exceeded my capabilities in every dimension, that would probably help me a little bit understanding these objects. But maybe not as much.
Greg
You’d still have to do the work.
Daniel
I saw you say on Twitter, citing a philosopher, that the societal role for a mathematician is to embody mathematical understanding. I love it—what a nice framing. I can’t tell how much you’re bothered by it. If we’re in a world where AI systems can pretty quickly resolve any problem faster than any human—total AI dominance of human mathematics—would that bother you? Would you still pursue mathematics?
Daniel
Part of doing math is you get a rush when you prove something. That doesn’t necessarily have to be an open problem to get that rush. You lose maybe some ego boost, but the main emotional aspect is still there.
For me, the actual goal is to understand stuff. In a world where our primary role is to—as Peli likes to say—embody human understanding, where we’re running seminars on the latest great result proven by an AI, if society is willing to support that activity, I would be pretty happy with it.
Greg
Like this lasts in post-scarcity utopia.
Daniel
For sure. I do think we’re quite far from that.
Greg
But if we’re still like ourselves when we get there, then we would want to do that.
Daniel
There is a social question—if models have absolute advantage over humans in all areas of math research, or if the public has the perception that they do, which I think is more likely—will society be willing to support that activity? I think that’s an open question. But I hope so.
Greg
Society currently has the perception that math ends up being useful a lot of the time.
Daniel
One way math ends up being useful is that there are human experts and there’s human capital developed out of math. Even people working on the most abstract and pure mathematics—the fact that they embody understanding is valuable. Depending on how capable and innovative future models are, it may still be valuable to have humans embody that understanding, even if narrowly within math research AIs have absolute advantage.
What do AI math benchmarks actually measure? [01:25:28]
Greg
We’d love to continue the track we’ve been on making benchmarks—FrontierMath in particular. But it seems like the y-axis is not capturing everything that’s important. What are the big things missing?
Daniel
Let me say a little about what I think a benchmark measures. You’re trying to benchmark knowledge—do you know what the words mean? Do you know existing results? Knowledge of existing techniques? Can you apply existing techniques? And also some kind of reasoning ability and creativity?
I think what the benchmarks primarily end up measuring is knowledge. When a human solves a problem, humans typically have very limited knowledge. So what do they do? They maybe have some idea, work on it for a while, realize “I need this fact or this result as an intermediate step,” then try to prove that result or look it up.
The activity of proving an intermediate result, or even finding that intermediate result and realizing it’s something that could exist—that’s a very reasoning-intensive activity. If you’ve memorized the entire mathematics literature, you already know that result exists. It’s much less reasoning to realize it’s a true fact that would be useful to prove the thing you’re trying to prove.
When you’re asking a question to something that has memorized the whole literature, you’re primarily not testing that secret reasoning ability that happens when a human with very limited knowledge tries to solve a problem. They have to discover something intermediate that is already discovered by someone else but not by the human in question. And the model already knows.
A lot of questions that in humans test reasoning ability and correlate highly with mathematical expertise and research success are much less correlated with that kind of capability in models. Any human who can do as well as a model on FrontierMath would probably be a very successful researcher, in a way we’re not seeing the models do. This is part of the explanation—the very same question is testing something different in models than it tests in humans.
Greg
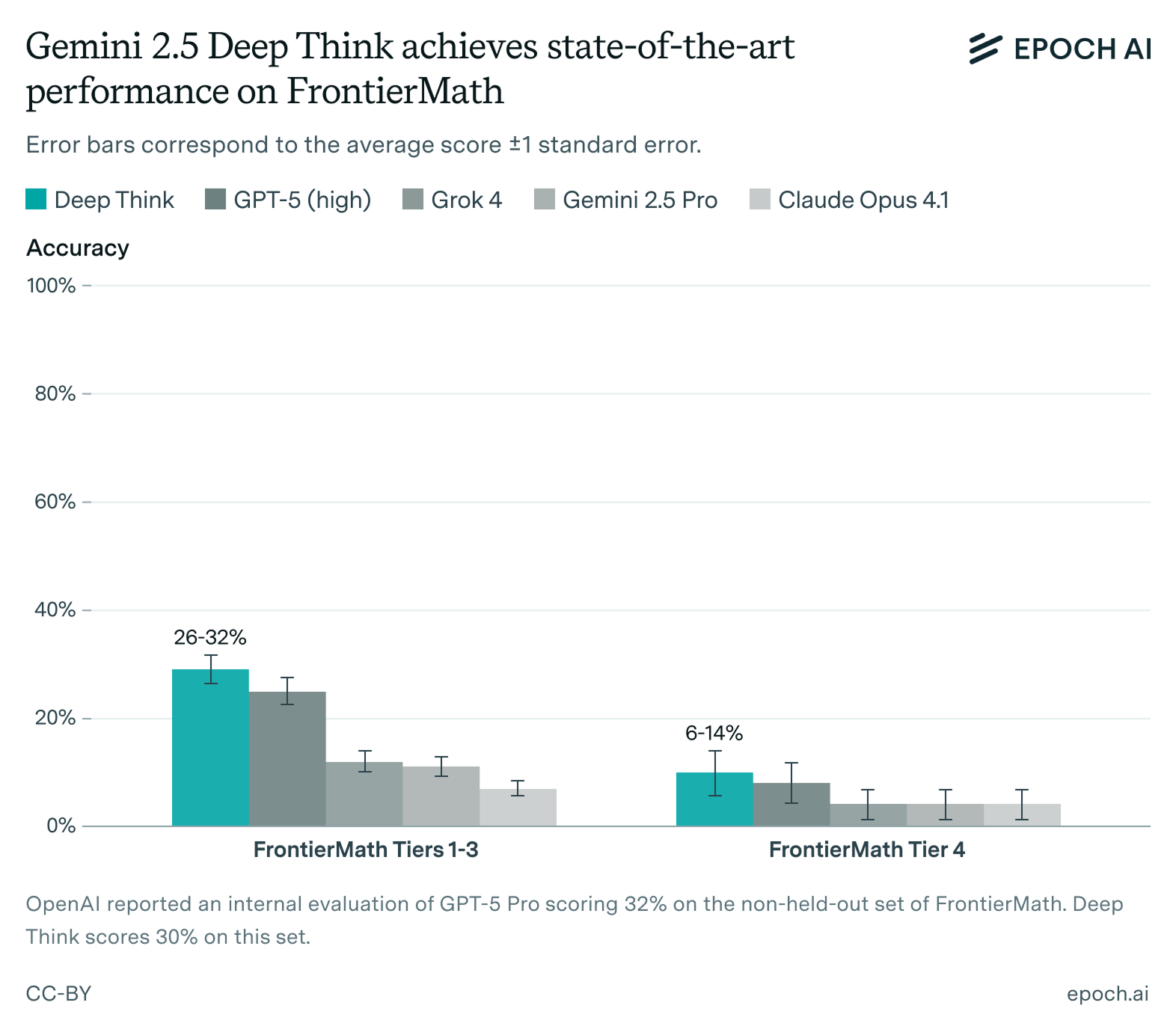
To add something you may not have seen: we did a deep dive into Gemini 2.5 Deep Think’s math capabilities, including running it manually on FrontierMath. The problems all have three ratings: background, execution, and creativity. Execution is something like how long the solution is, how much nitpicky calculation you have to work through. Background is how advanced and obscure the required knowledge is. And creativity—I think of those three, was probably supposed to be most correlated with this reasoning capability we’re describing. We see a negative correlation between Gemini’s scores and background and execution, but no correlation with the creativity rating.
Daniel
Interesting.
Greg
It captured exactly the phenomenon you’re saying. Even though we tried to make FrontierMath span this creativity dimension, that doesn’t seem to be what models are actually picking up on in terms of what problems they find harder to solve.
Daniel
Do you see the same correlation with other models? Gemini seems to do less synthetic data—it may be that Gemini knows less about fancy topics.
Greg
Same pattern for GPT-5 and others. But yes, indeed it’s missing this piece.
Daniel
The other thing is—you try to write a hard problem. Realistically, the people doing this are busy, they write something they already know how to do. A problem that a random person already knows how to do is obviously accessible via existing techniques.
Maybe they came up with some new technique to solve the problem that hasn’t yet made it into their paper. Whether it’s really new or just new to them is a question. Eventually the paper comes out and makes it into training data, and then we’re no longer measuring the model’s ability to develop new techniques.
Sometimes the hard thing is you need to plug numbers into a formula in a paper where understanding the words in that paper requires a lot of background. But the models have a lot of background. They can read a PDF and plug in numbers.
Greg
Sometimes you end up testing “can you read a PDF?”
Daniel
Yeah. My sense is that if a benchmark is constrained by what a person can do in a few hours, it’s probably going to be saturated soon. What a person can do in a few hours is very limited.
Greg
One of our FrontierMath Tier 4 contributors mentioned he was quite proud of his problem because he got nerd-sniped and instead of coming up with something he already knew how to do, he set himself a two-week research project. He set out with “I want to do something with these techniques” and explored until a problem fell out of it.
Daniel
The longer you get someone to spend setting a problem, probably that will correlate with problem quality. But there’s another trap—someone sets out to write a hard problem, what they end up writing is a problem that’s hard for them. You try to write a problem in a field where you’re not an expert.
Greg
And everything seems new and exciting and difficult.
Daniel
You end up writing an easy problem for an expert in that field. Writing a hard problem and not trying to test its hardness is a recipe for producing benchmarks that will be saturated easily.
Designing the Open Problems benchmark [01:33:05]
Greg
Let’s get into the Open Problems benchmark that Epoch is cooking up—we’re calling it provisionally. The goal is to find open math problems that at least today, no human knows how to solve. We’re still constrained by automatic verifiability—we want every problem, even though no human knows the answer, to be verifiable if an AI comes up with a purported answer. It’s meant to get around the problem of not knowing how difficult a problem is.
Daniel
A lot of open problems are attention-bottlenecked, so it could be that an open problem is not as hard. One useful thing would be to get mathematicians to say “I think this is hard.” That prevents goalpost moving.
One thing I like about this kind of project is that right now, a lot of labs are devoting resources to solving some problem so they can say “we solved this problem.” It would be nice if some resources went to problems people actually care about. Some labs are doing what I’d consider real science, and some are primarily doing PR.
Greg
It also gives us a pre-registration of a population of problems. With a lab saying “our model solved this problem”—how cherry-picked was that?
Daniel
There was a paper from OpenAI that went through some conference proceedings and looked for problems. If I remember, they looked at ten different ones and solved one. That gives you some sense. I don’t think that paper gave good evidence of acceleration happening. And as with all these stories, there are complicating factors.
Greg
Good. If we can get a sense of mathematicians saying “I think this would be interesting”—how do you characterize that? What scale are we using?
Daniel
Maybe you can get someone to say “is this interesting? Is it very interesting? Extremely interesting?” You could get people to talk about consequences. Sometimes the problem is interesting because it’s a source—it implies some interesting stuff. I understand the benchmark is primarily looking for some kind of construction that can be verified.
Greg
We’re not looking for constructions per se, but because we have this verifiability constraint, it’s usually “construct an object.”
Daniel
Some constructions have genuine consequences. Some questions are sinks—supposed to serve as a benchmark for understanding. That Euler sum of powers conjecture—because brute force search is infeasible, the problem benchmarks understanding. To solve it, you have to come up with some clever search, so you’ve understood something about the search space.
Greg
Would those sink-benchmark problems be fair measures of AI understanding, given that they’re unsolved by humans?
Daniel
It depends on the problem. Some of these are just attention-bottlenecked. A lot of constructions people look for—the state of the art is “someone ran a naive search on their laptop over the weekend.” You find a better construction—okay, you tried one thing rather than zero things. Clearly that has value, but it’s a little hard to get a sense of what it’s showing.
But there are some questions—like the inverse problem for M23—where I think if there was a Manhattan project to solve it, it would be solved. It’s definitely within reach. People have definitely tried.
Greg
Is it worth considering interestingness or value as distinct from difficulty?
Daniel
Those are absolutely different dimensions. They correlate because people try the interesting problems. The interesting problems that remain unsolved happen to be hard.
Greg
We touched on goalpost moving. There are cases where you didn’t expect a boring way to solve this problem, but looking at the AI system solution—no new ideas in sight, not within a mile. It’s a grind. It proves it, but doesn’t seem relevant for capabilities forecasting. Any ways we can get ahead of that?
Daniel
I want to argue that if you’re solving an open problem that’s not super attention-bottlenecked, and the proof is a grind—that’s okay. You shouldn’t say “this doesn’t demonstrate anything.” The ability to grind is a valuable skill as a mathematician.
Greg
Mathematicians would do this if they could.
Daniel
The proof of the four color theorem—nobody cares? Some people do say this. I think they’re wrong.
There’s a long tradition in mathematics of goalpost moving. A lot of the great mathematicians of the 18th or 19th century were great calculators. A lot of what they did, any eighth grader can do with their TI-84. We’re tool users. We’re allowed to use tools.
Greg
It’s fair play for doing interesting math. But for capability forecasting, if we look at this and say “it’s doing the same thing as P6 on the 2024 IMO, which AlphaProof got”—it’s shocking. What a boring proof it looks like.
Daniel
Sometimes you don’t know a problem is easy until you solve it. That happens for human mathematicians too. Last year, Aaron Landesman and I solved a 40-year-old open problem. We didn’t publish that in Annals because the solution, a posteriori, was not that interesting. That happens.
Maybe the thing to do is look at it and say: we have to have some principled way of deciding whether there’s a really new idea here. A post-mortem rubric. You can wait five years and see how many new results have been proven using these ideas.
The conjecture over finite fields introduced the polynomial method, which has been hugely influential. That paper was published in Annals, very well justified by the post-hoc productivity on top of it. Whereas a grind solution to IMO 6—nothing is going to come out of that idea.
Greg
The difficulty measure we’ve been thinking of—how many mathematicians, for how long, maybe some notion of seniority. If 1 or 2 early-career mathematicians tried to solve this problem and failed, how big a step forward is an AI solving it from where we are now?
Daniel
It’s unclear how much low-hanging fruit there is in mathematics. It’s quite possible there’s a huge amount. Maybe the fact that AI systems have not already started to resolve interesting open questions is mild evidence against this. But every question is attention-bottlenecked. In that world, we’ll see a huge advance from AI systems. And benchmarking will be easy—you’ll put any open problem on it and it will eventually be solved.
On the other hand, there’s some mild evidence that not everything is attention-bottlenecked—that there’s not that much low-hanging fruit. When people actually work on stuff, it either gets solved or it’s hard.
Greg
What do you have in mind for why it might feel that way?
Daniel
Well-known open conjectures with very short proofs—there are very few examples. In a world where we were really bad at picking up low-hanging fruit, you would expect to see evidence that we do sometimes find it. It does happen, but it’s pretty rare.
Typically, a resolution of an important conjecture doesn’t just introduce a short new idea but introduces many ideas or relies on lots of other developments in the field. You can visibly look at the resolution and see advances required.
We’re not always good at seeing it. Sometimes you prove a result because the last thing you needed was just proven recently and finally slotted into place. Sometimes something was proven and had been in the literature for 20 years.
All of us have examples of papers that come out and we’re like, “Oh, I knew the main idea. If I had just realized…” One of my favorite papers—the main idea is in a MathOverflow answer someone wrote in response to a question I asked from a few years earlier, and I was kicking myself.
Greg
For this benchmark, we have this binding, annoying, unnatural constraint of automatic verifiability—we want a computer program to tell you whether the answer is right. How bad is that?
Daniel
In principle, it’s not a constraint. Any mathematical construction—modulo issues of incompleteness—you could imagine accompanying it with a proof that could be verified. But in practice it’s a real constraint because you have limited resources to get people to write code that verifies things.
Greg
We’re limited to more like “regular old computer program can verify.”
Daniel
So one constraint is that a lot of fields and interesting questions are just simply not of this nature. There are areas of algebraic geometry where no question has this nature, same with areas of number theory, although there’s a lot of beautiful computational number theory.
The primary area where this limits you is interest. There are things like the inverse Galois problem, where one wants to make a verifiable construction and people are very interested. With rare exceptions, you want to make an infinite series of constructions, and those are much harder to verify.
Greg
One problem class I’ve gotten excited about is doing a zero-knowledge proof—maybe you have an infinite sequence, so I’m not going to verify the whole thing, but do it for 297.
Daniel
That’s a great way to do it. But you very quickly run into practical issues unless you can verify extremely rapidly. Often all you’re asking is for the first five. Even for the inverse problem, you can ask for things, but probably beyond the first 3 or 4 it’s not practical.
There are very serious constraints. What one hopes with a benchmark like this is that the ability to produce an example is actually a proxy for some kind of understanding or clever search. It’s often unclear whether that’s the case. Sometimes we have evidence that humans have tried and failed, so we sort of know we’re missing something. Or perhaps humans have succeeded at similar problems with some insight, and otherwise nothing’s come out.
Greg
There are definitely examples of problems where every new construction requires a beautiful new idea. If you can get another example, you hope there’s a beautiful new idea behind it.
I sent you a list. We’re aiming to span a difficulty range. Our risks on the easier end are that the postdoc who wrote this paper was having a bad day. And it’s no harder than an IMO P1 in some ways. We’ll defeat this with statistics. I’m also curious on the difficult end—the math that’s most interesting, most difficult, often has more abstraction.
Daniel
That might be more of a Moravec’s paradox issue. One way math can be difficult is it requires high reasoning effort. Another way is you need to learn a lot of what a lot of words mean—hold a huge theory in your head.
Algebraic geometry has a reputation of being very hard. It’s quite possible that’s just because humans are kind of bad at it, and very few humans are in it at all.
Greg
Right. Attention bottleneck. For the problems I sent you—did you have any gut feeling of “this is much harder, much more interesting”?
Daniel
There are a few. The inverse problem for M23—I can certify that as a problem I would be very excited to see solved. I think it’s within reach of a Manhattan project, but it would be a big deal. I’d be very excited if humans solved it. I’d be very excited if AI solved it.
There were some problems about irrationality. In the late 70s, Apéry proved the irrationality of zeta(3)—the sum of the reciprocals of the cubes of the positive integers. It was a magical proof. He explained it at a conference and no one could believe it. Then they went home, checked it, and it was amazing. People later realized it was connected to deep theory—the theory of G-functions.
The problem is to find sequences of integers or power series that would let you run this for other interesting constants. Zagier, a very serious mathematician, did a lot of computations trying to find analogous sequences, with mild success—6 or 7 examples.
Greg
None of them things you would have picked ahead of time as the most important?
Daniel
There’s been very recent progress by Calegari, Dimitrov, and Tang. Instead of finding new sequences, they found new ways to apply the same general method with very beautiful innovations to let you do this with a broader class of sequences. I think this can be certified as hard—a lot of people have thought about it.
Do mathematicians believe heuristic arguments about conjectures? [01:56:35]
Greg
Another challenge we face is we want the problems to be solvable.
Daniel
You’re trying to pose questions which have an answer: true conjectures. That’s a very hard thing to do—to figure out what’s true, let alone prove it.
Greg
Do you have a sense of when a mathematician familiar with an area tells us they’re 80% sure this problem resolves in this direction, though they can’t produce the construction themselves, how much credence do you give that?
Daniel
Slightly better than random chance, but not much. People change views all the time. One of the examples on your list—finding an elliptic curve of rank at least 30—for a long time, everyone in the field believed the ranks of elliptic curves were unbounded. I think now maybe the majority believe the ranks are bounded.
Greg
Oh really?
Daniel
There’s a fair amount of recent heuristic work suggesting that, although some people have doubts. People’s views of the truth—if you ask about the Hodge conjecture, probably most algebraic geometers believe it, but a lot do not.
Greg
In some cases we get proofs that some construction exists, but no one’s been able to produce it.
Daniel
I quite like that kind of thing. There are bounds on Ramsey numbers from the probabilistic method—you can ask for explicit constructions. One of the problems I’m working on now is—Serre asked for some examples of objects that have been constructed via very inexplicit techniques, and I’ve been working to find explicit constructions. It’s very different to do something explicitly versus inexplicitly. It gives you a lot of insight.
Anson
What are the heuristic arguments or good examples of these arguments that make people update without the full proof?
Daniel
There’s a long history in number theory of making random models of number-theoretic objects. You could think maybe the prime numbers are distributed like a random collection of integers with certain properties. You try to make a random sequence with those properties and ask what properties it satisfies with probability one. Then you guess maybe the same things are true of primes.
For elliptic curves—you list all the properties you can think of, try to make a random model with those properties, and guess what it has. A very basic situation: maybe you have an n×n matrix that comes from some geometric or arithmetic situation. You say maybe it should behave like a random n×n matrix.
There’s beautiful work by Melanie Matchett Wood and collaborators studying random matrices of integers. They used that to make number-theoretic predictions about elliptic curves and related objects. There’s a theorem behind it—the theorem says a random object satisfying properties x, y, and z has such-and-such properties.
A classic example is the class group of a number field. You say maybe that behaves like a random abelian group generated according to some distribution. You expect if you list number fields in some natural order, the proportion satisfying property X, Y, or Z behaves like a random group satisfying all the properties you can think of. That’s the Cohen-Lenstra heuristics—one of the driving forces behind a lot of number theory and arithmetic statistics right now.
What if FrontierMath: Open Problems gets solved? [2:01:24]
Greg
If an AI system wiped the floor with this benchmark—with problems of the kind we’ve discussed—what sort of world do you think we’re living in?
Daniel
I would be very excited. Presumably whatever it did to find these constructions would be interesting at least some high proportion of the time.
There’s a good question as to how we should expect it to correlate with other capabilities. With these sorts of constructions, there’s a clear reward signal. You could imagine trying to train a model to target this kind of construction. It’s unclear whether that reward signal would generalize to proofs. And of course one can verify proofs too.
Greg
But maybe you have to wait for that machinery to be better set up before you train on it.
Daniel
In general, a big open question for me about the future of math capabilities is how much generalization is happening. A world where every time a new mathematical object is discovered or invented you need to train a new model from scratch is very different from one where models can pick it up and run with it.
Or even if general knowledge and capability in algebraic geometry generalizes to algebraic geometry plus epsilon. I can think of ten new versions of what a “space” is from the last ten years. Not even just continual learning—if each of those require, if you imagine a model that learns what those are but doesn’t learn capabilities and have the capacity to play with them the way humans can.
We’re talking about a special case where we have a model that’s very good at making verifiable constructions. It’s an open question how much that correlates with broader capability. It would clearly be an epochal development.
Greg
For math certainly. And for broader capabilities, it would depend on what that system looks like in terms of generalization. It could be extremely narrow—we’ve hill-climbed our way to game playing.
Daniel
We already see some constructions like this from AlphaEvolve. AlphaEvolve is not doing interesting proofs—it’s doing interesting constructions.
Greg
You’re on the record on Twitter that the interestingness of the AlphaEvolve constructions is limited.
Daniel
The specific constructions are primarily interesting because it’s an automated system doing it. But one could imagine a future iteration where the constructions themselves are of substantial independent interest.
Greg
And to the last real thing I have on my mind—not just generalization to other fields of math, but to scientific fields, R&D fields. In a world where AI systems are regularly resolving interesting math problems—not through hyper-specialized methods like AlphaProof—what do you think that looks like for the sciences, for AI R&D?
Daniel
My view is that right now, the primary obstructions to AI doing autonomous, high-quality math research are the same as the obstructions to doing any kind of economically valuable labor. Sometimes you need to be creative. You need to adapt to new techniques. You need to learn something. You need to work on something for a long time. Those are all things current systems have problems with.
I suspect that if those problems are solved, the models will become very good at math research. And solving those problems is more or less required for models to become very good at math.
Greg
There’s a question—what are the chances that there’s an extra ingredient that makes math difficult, so this ends up being one of the last things to fall on the path to more societally transformative AI?
Daniel
I think that’s pretty unlikely. It’s very hard to understand what’s required for good math research—it’s some kind of introspection. There’s evidence it involves things like creativity and working hard for a long time.
It’s possible that’s not true. In that case, math might have more progress before we see other areas. I think it’s very unlikely there’s an extra ingredient to mathematics. The practice of me doing my job is not that different from other people doing their jobs. Okay, there’s a lot more lying back on my couch and staring at the wall and just thinking about stuff, but I think the actual ingredients are pretty much the same as any other economically valuable labor.
Is AI on the cusp of accelerating math progress? [02:06:53]
Greg
Are there other questions we should have asked you?
Daniel
One thing I want to talk about more—a lot of this is about the marginal cost of doing different mathematical activities. I think where I expect AI to have a significant impact is that the marginal cost of trying something is getting very small.
A lot of conjectures have this flavor—you should probably have run some computer program to do some computation, but you were too lazy. You don’t need a very capable system to resolve that kind of conjecture. We’re already seeing a lot of these fall. I think that’s a huge deal.
Greg
What sort of acceleration to math progress does that give you?
Daniel
I don’t think of it as much about acceleration. There’s some tax on progress—you have to try something—and bringing that cost down is meaningful, even if the primary bottlenecks are elsewhere.
The primary obstructions to progress are: you have to have a good idea. Most people have a couple of those a year. Not clear to me how much AI helps with that. But sometimes you don’t need a good idea. You just need to sit down and grind something out. Knowing when you don’t need a good idea is very valuable.
Even holding capabilities constant, we should expect a lot of frictions to disappear. That seems to be the area where I expect the most progress to happen.
Greg
Even though you don’t expect that to cause a discontinuity in math progress, that’s the framing you find most helpful for what AI is bringing to math right now.
Daniel
In terms of acceleration—I would really love to see some way of operationalizing that and actually measuring: are we actually seeing acceleration? Have we ever seen acceleration? Has the productivity per person of mathematical work increased with time? It’s just not clear to me, even though we have all these new tools. How do you operationalize that question? You can look at citations—a very bad proxy. It also seems to correlate relatively well with population.
Greg
Before we wrap up—any things you’re looking for in the next couple of months that would be interesting?
Daniel
In August I said something like “it’s weird that we haven’t seen a lot of mildly interesting conjectures resolved by AI given current capabilities.” I guess we’re now starting to see those, arguably.
Within the next year we’ll see a lot of those—problems no one has really thought much about, throwaway questions, but things people found interesting enough to write down—resolved autonomously. That seems quite likely.
Greg
We will have plenty of opportunities for emergency podcasts in the future. Everyone follow Daniel on Twitter. It’s honestly a pretty good source of AI math news writ large. Thank you so much for talking with us.
Daniel
Thank you so much for the invitation. It was great to be here.
Greg
Very nice.
List of referenced works and media
- Euler’s Sum of Powers Conjecture: Lander & Parkin 1966 (the first counterexample) and Elkies 1988 (fourth powers)
- Esnault and Groechenig (Theory of Companions and the Langlands Program)
- Deligne’s proof of the Weil Conjectures (1974)
- Irrationality of Zeta Values: Apéry’s Proof (1978-1979), Van der Poorten’s exposition, Zagier’s computations, Calegari-Dimitrov-Tang’s recent progress
- Random models in Number Theory: Melanie Matchett Wood on random matrices, Cohen-Lenstra Heuristics
- Mentioned Millennium Prize problems: Riemann Hypothesis, Hodge Conjecture, Birch and Swinnerton-Dyer Conjecture, Navier-Stokes
- FrontierMath: Open Problems benchmark
In this podcast



Related work