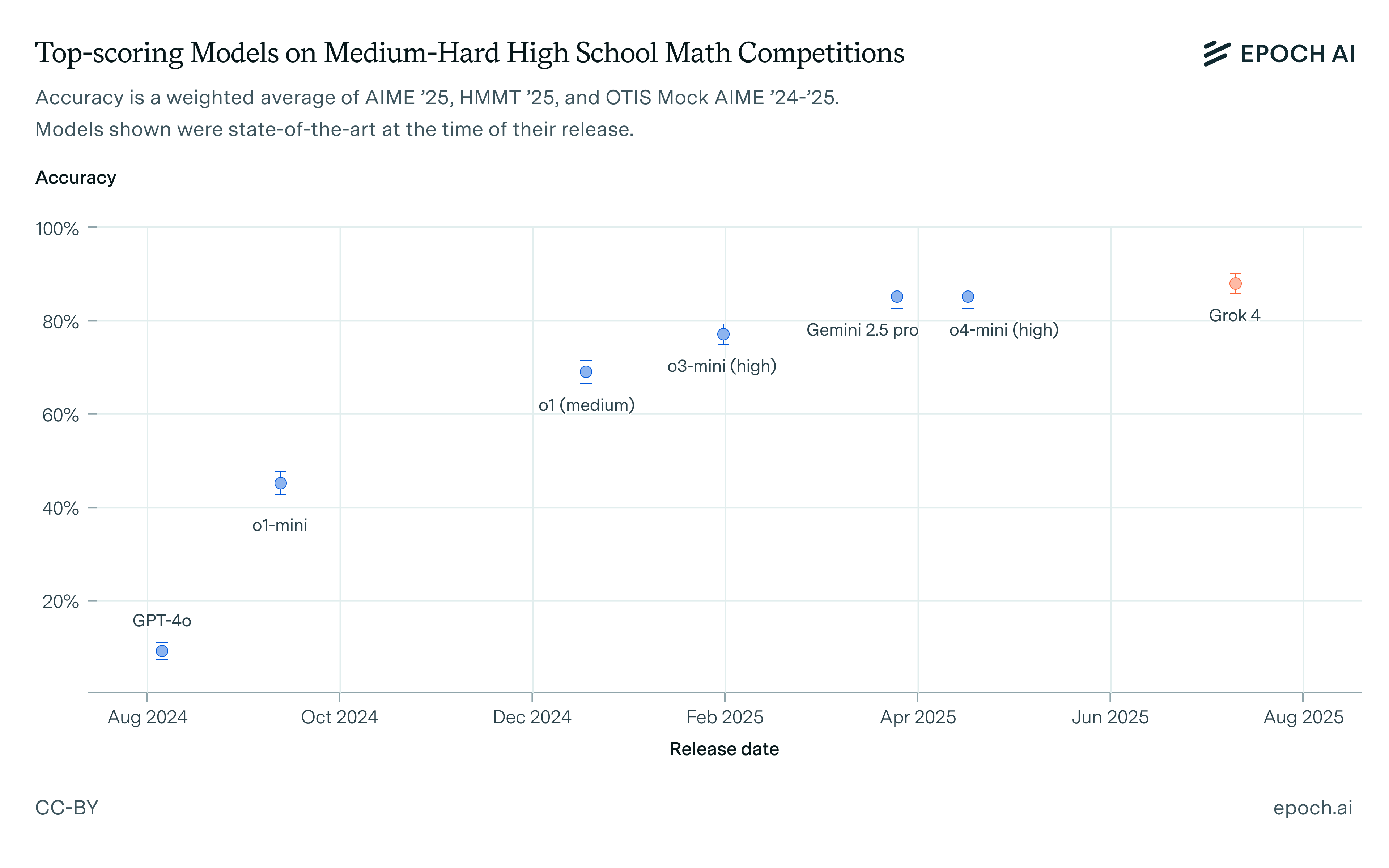
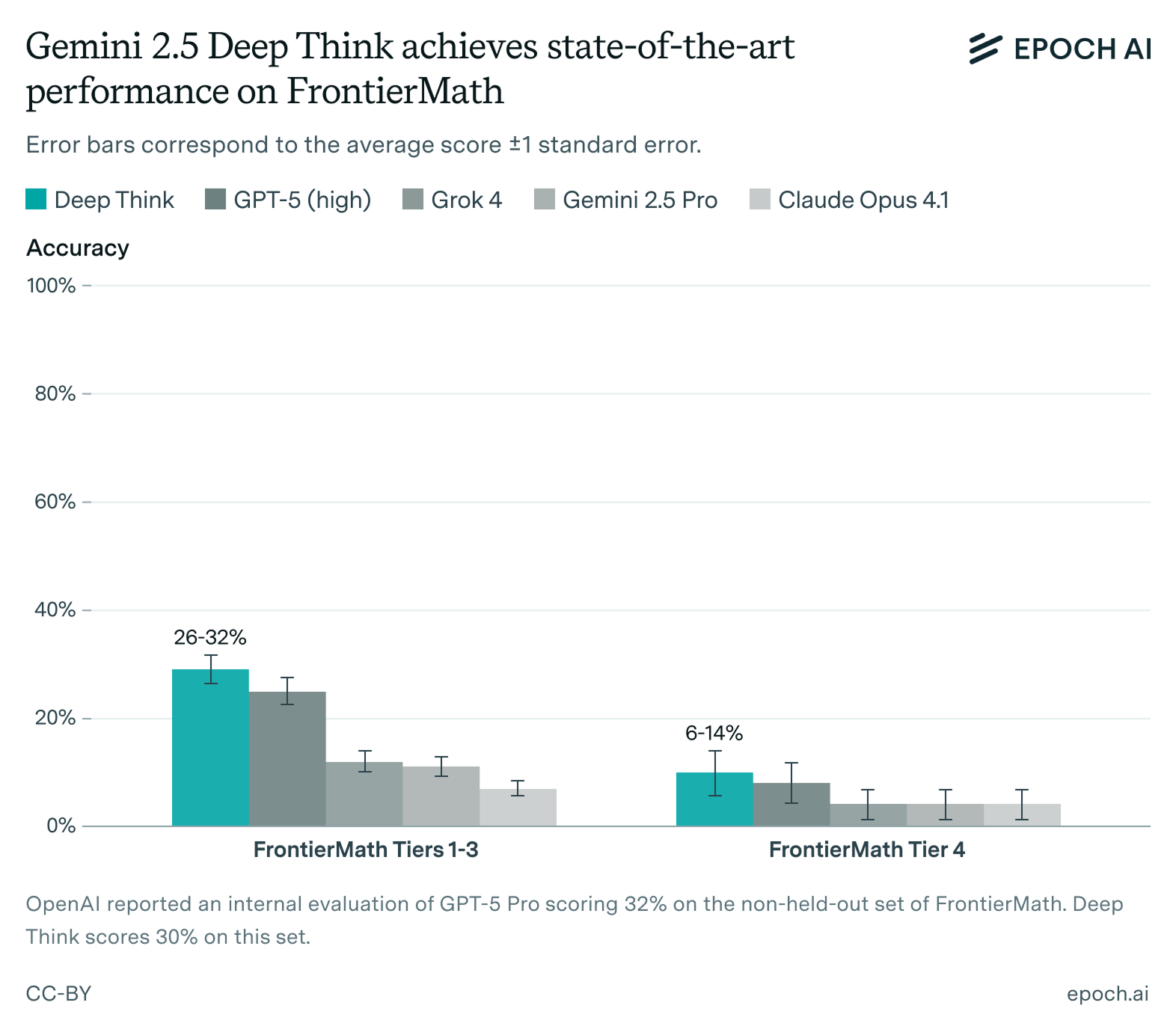
How well do humans perform on FrontierMath?
This is a benchmark that we released last year, designed to test the limits of AI’s math capabilities. It contains 300 questions that range in difficulty from upper-undergraduate level, to those that even Fields Medallists find challenging.
To figure out a human baseline, we organized a competition at MIT, with around forty exceptional math undergrads and subject matter experts taking part. The participants were split into eight teams of four or five people, and given 4.5 hours to solve 23 questions with internet access.1 They were then pitted against the current state-of-the-art AI system on FrontierMath, namely o4-mini-medium.2
The result? o4-mini-medium outperformed the average human team, but worse than the combined score across all teams, where we look at the fraction of problems solved by at least one team. So AIs aren’t yet unambiguously superhuman on FrontierMath – but I think they soon will be.
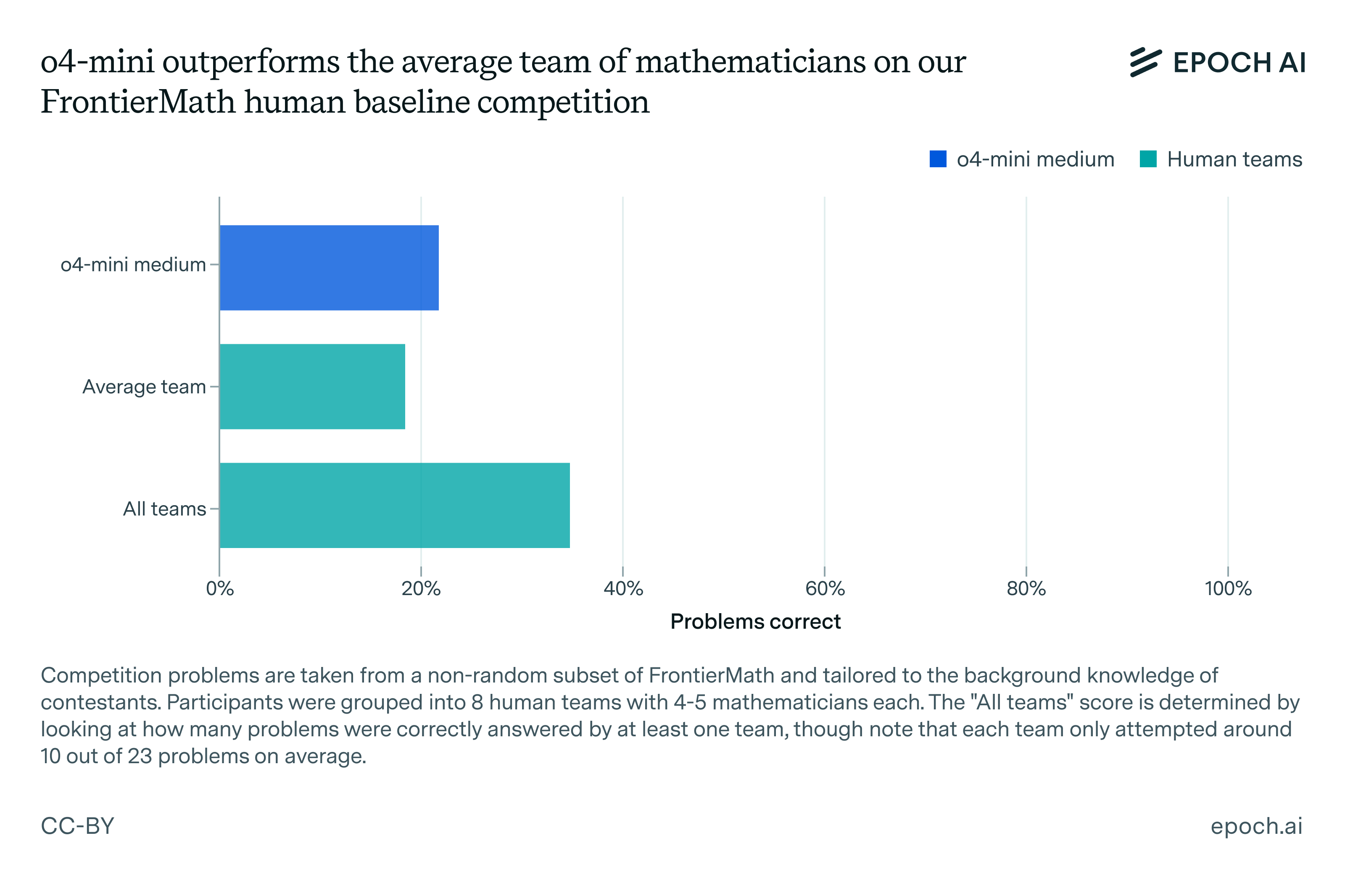
Figure 1: o4-mini-medium scored 22% on the FrontierMath human baseline competition, outperforming the average team (19%) but falling short of the combined score across all teams (35%). Note that o4-mini-medium only managed to solve problems that at least one human team had solved. Competition results can be found in this spreadsheet.
This data however is just based on a small non-representative subset of FrontierMath – so what does this mean for the overall human baseline? I think the most informative “human baseline” on FrontierMath is somewhere between 30-50%, but unfortunately this turns out to be rather more ambiguous than it might seem on the surface.
My goal in this post is therefore to briefly explain four things you need to know about this human baseline result, including where it comes from and what its implications are.
1. Subject matter expertise was underrepresented
To make sure that we got high quality results, eligible participants needed to demonstrate exceptional mathematical ability. For example, this includes people with PhDs, or undergrads with a very strong competition record.
We grouped the participants into eight groups of four or five, ensuring that each team had at least one subject matter expert on any particular domain. For example, a subject matter expert could be someone with a graduate degree or are currently pursuing a PhD in that field, and listing that subject as their preferred area.
Although it would’ve been ideal to have had expert-only teams and subject-matter experts across various domains, in practice most teams had a roughly even split between undergrads and experts. Participants also largely consisted of local members of Boston’s math community, which famously has a limited representation of domain expertise in analysis.
2. The competition was more designed to reflect reasoning capabilities than broad knowledge
In some ways, AI systems are already superhuman – for instance, they’re vastly more knowledgeable than even the most erudite human mathematicians. That gives them a huge advantage, because the problems on FrontierMath span a wide range of topics, ranging from number theory to differential geometry, and no single human can be familiar with the frontier of all these fields.
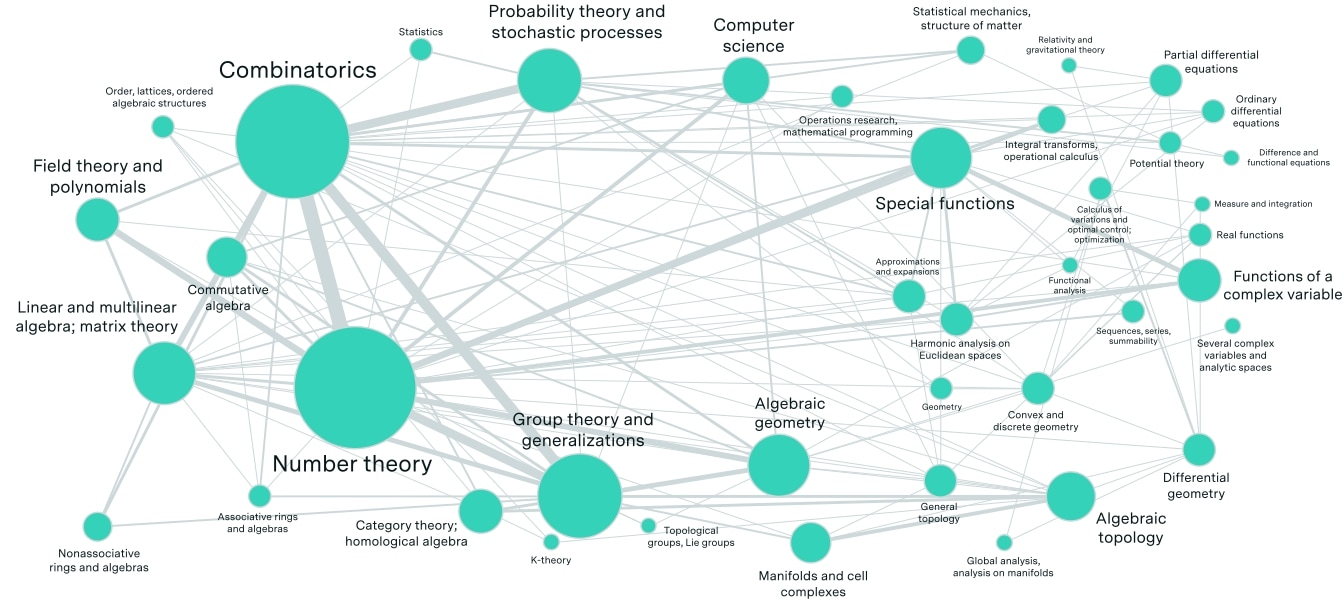
Figure 2: Graphical representation of the topics on the full FrontierMath benchmark, spanning a wide range of domains.
While this knowledge advantage is in itself meaningful, it doesn’t capture what FrontierMath was most heavily optimized for: whether or not AI systems are able to perform mathematical reasoning.
To obtain a more meaningful human baseline, we thus chose problems that require less background, or are tailored to the background knowledge of the participants.3 This meant choosing seven “general” questions that are accessible to smart undergrads, and sixteen “advanced” questions that were tailored to the experts taking part.4 These fall into four subcategories: (1) topology, (2) algebraic geometry, (3) combinatorics, and (4) number theory.
That said, we still did want to obtain responses across some range of domains, so that not all of the responses would be on the general questions. We tried to incentivize this using the competition’s scoring system, where each correct “advanced” problem counts for two points compared to one point for each “general” problem. Across each of the five total domains (the “general” category plus the four “advanced” subcategories), each domain that had at least one correct answer yielded an extra point.
Finally, winning teams were awarded prizes to incentivize high performance: $1000 for first place, $800 for second place, and $400 for third place. Other participants were awarded an honorarium of $150 in order to encourage participation.
3. The definition of “human baseline” is somewhat ambiguous
The teams generally solved between 13% and 26% of the problems, with an average of 19%. o4-mini-medium solved around 22% of the competition problems, which I think is roughly on par given the kinds of sample sizes we’re dealing with.
However, this way of reporting the human baseline may not be totally informative. While ideally we’d have had each team individually have subject matter experts on all four of the advanced domains, this was the case for none of the eight teams. As a result, the averaged human baseline score is likely to be a bit of an underestimate compared to teams with all the requisite knowledge.
One way to account for this is to consider a question as answered correctly if any of the eight humans teams provides a correct answer. Doing this pushes the performance up to ~35%, but I also think it’s a bit too optimistic. In some ways this allows humans to have “multiple shots on goal” (something like a “pass@8” for the human teams on questions where all teams have the relevant subject matter expertise), whereas o4-mini-medium was evaluated under a pass@1 setting. Given this, the human performance on this competition was probably somewhere in between these two bounds, at around 20-30%.5
If however we want a human baseline on our general benchmark, we need to address a second issue. In particular, the competition problems have a different distribution of problem difficulty compared to the full FrontierMath dataset, as illustrated in the table below.
| Difficulty tier | FrontierMath competition | Full FrontierMath benchmark |
|---|---|---|
| Tier 1 (~Undergrad level) | 17% | 20% |
| Tier 2 (~Graduate level) | 13% | 40% |
| Tier 3 (~Research level) | 70% | 40% |
Difficulty distribution of problems on the FrontierMath competition and the full benchmark. “General” problems in the competition are either Tier 1 or 2 problems, whereas “Advanced” problems are all Tier 3.6
We thus split the results by difficulty tier and weight the overall score based on the difficulty distribution on the full benchmark. This increases the human baseline to around 30% based on the per-team average, and 52% based on the “multiple shots on goal” approach.
Unfortunately, I’m not sure that this method of doing the adjustment is really any good, because applying the same weighting would suggest that o4-mini-medium achieves ~37% on the benchmark (compared to 19% from our full benchmark evaluations). It’s possible that this is due to the Tier 1/Tier 2 problems on the competition being comparatively easy relative to the average problems of the same tiers on the full benchmark, but it’s hard to adjust for this after the fact.
4. AIs aren’t yet superhuman on FrontierMath, but they probably soon will be
So what does this all mean?
First of all, although we now know that o4-mini-medium attains scores in a similar ballpark as human teams (at least under the constraints of the competition), this doesn’t tell us how the models are achieving this. Are the AI systems simply guessing the solutions to FrontierMath problems? How do they compare to human approaches? More on this coming soon!
Second, if the relevant human baseline is indeed around 30-50%, then I think it’s likely that AIs will unambiguously exceed this threshold by the end of the year.
One caveat is that the human performance might be somewhat understated due to the competition’s format. For example, it’s very possible that human performance would improve substantially given more time. Whereas o4-mini-medium takes around 5-20 minutes to complete each problem, humans generally take substantially longer. For instance, participants who responded to our post-competition survey spent a mean time of around 40 min on their favorite test problem. Related work on machine learning tasks also suggests that humans have better long-run scaling behavior – whereas AI performance plateaus after some period of time, human performance continues to increase. It’s also worth bearing in mind that the questions on FrontierMath aren’t a direct representation of actual math research.
Overall though, I think this is a useful human baseline that helps put FrontierMath evaluations into context, and I’m interested to see when AIs cross this threshold.
We’d like to thank Open Philanthropy for funding the FrontierMath human baseline competition.
-
We allowed participants to use their laptops to access the internet, write code in any language to aid them in solving the problems, subject to some rules (e.g. no contacting humans outside their team or using generative AI tools).

-
In our preliminary evaluations, Gemini 2.5 Pro scores the same as o4-mini-medium on the competition subset of FrontierMath, solving exactly the same 5 out of 23 problems.
-
This of course provides some advantage to the humans taking part, but whether this is a concern depends on what we care about measuring. If we’re less interested in comparing reasoning abilities in particular, I think it’s very likely that AIs are already superhuman on the full FrontierMath benchmark.
-
Note that we originally had 8 “general” problems, but one such problem had to be removed because one of the participants in the competition was the problem’s author.
-
There are of course other ways of operationalizing the human baseline. For example, FrontierMath problems have associated “background ratings”, and we can consider a subset of questions with background ratings that correspond to “undergrad level or below”. But doing this cuts down our sample size from 23 to 8 questions, and somewhat defeats the purpose of the scoring system we put into place. Moreover, we still get a broadly similar result – on the remaining 8 questions, o4-mini-medium yields around 50% (similar to the average across teams). If we instead count a question as correct if any of the human teams answers correctly, the performance is instead 75%.
-
Note that this differs from the previously announced difficulty distribution of 25%-50%-25% for tiers 1, 2, and 3 respectively. This is because the previous announcement was based on the 11-26-24 checkpoint of FrontierMath, whereas the numbers in the table above are from the 02-28-25 checkpoint.
About the authors
Related work