
There’s a familiar recipe for reasoning benchmarks: tasks are text-only, output is easy to grade, and expert humans can do the tasks in several hours. Unfortunately, this recipe is now obsolete. As an emblematic case, consider GPQA: a benchmark consisting of graduate-level science questions. It had remarkable staying power but by now it’s clearly saturated.
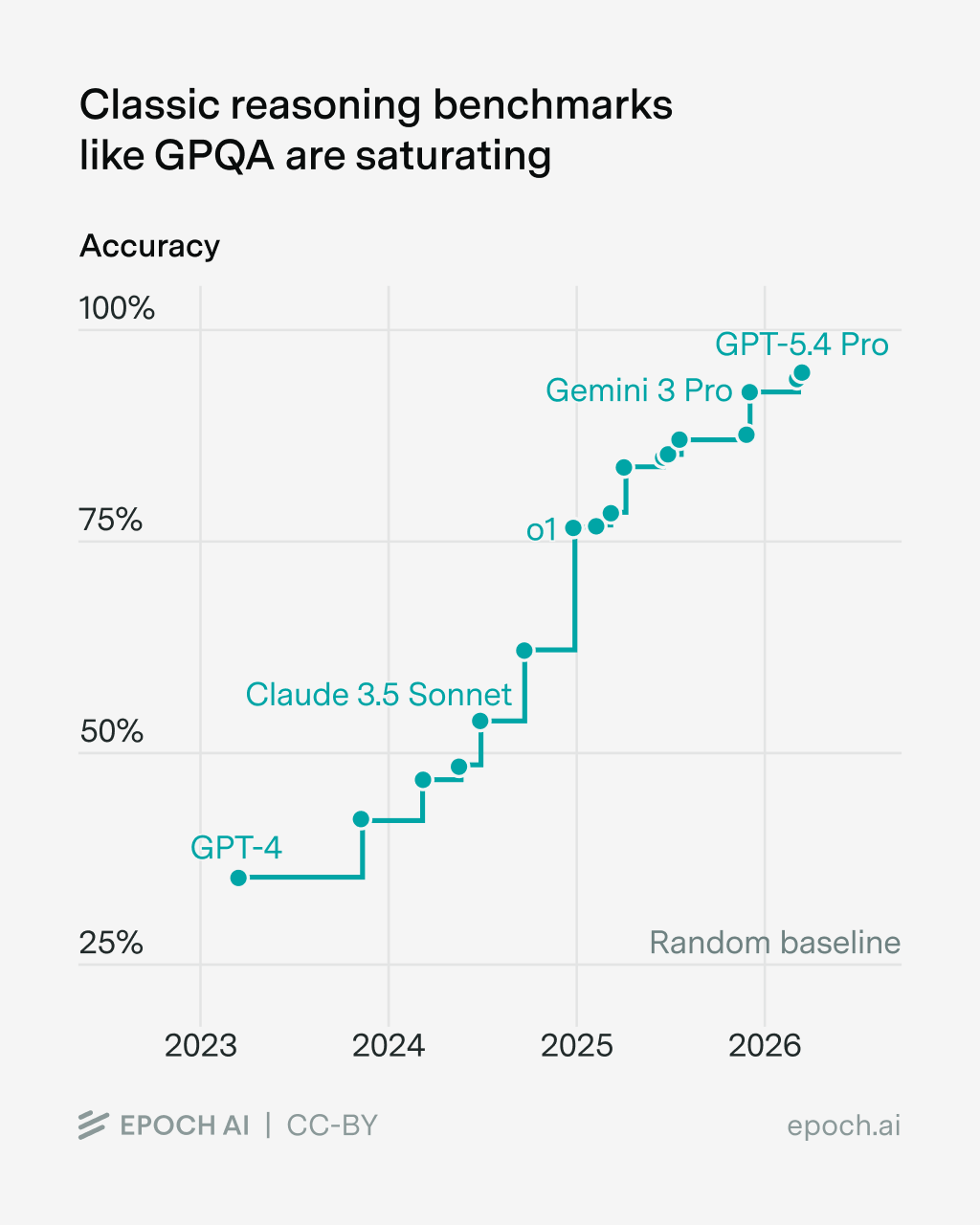
The same is true for many classical reasoning benchmarks, whether in science, math, or coding. What’s next? I think the old recipe points to a new recipe. Just relax one of the elements: text only, easy to grade, short time horizon, and expert human superiority. I see each of these categories as extremely fruitful to pursue, and far from saturated. The tradeoff is just that it takes more time and money to create such benchmarks.
Keep the classic format, but make it multimodal
It’s hard to say precisely, but to my eyes AI visual and spatial reasoning lags behind text-only reasoning. Still growing rapidly, but from a lower base. At any rate, it still seems comparably easy to create meaningful multimodal reasoning benchmarks.
To give one example, at a recent Epoch team offsite, we ordered a piece of IKEA furniture, laid all the pieces out, labeled them, and then gave AI systems the instruction manual and asked them to identify the step in the instructions in which each piece was first used. Top models scored around 40%.1

Which step is the part labeled 6 first used in? AI systems can’t say.
This is still “classic” in that it’s easy to grade and humans beat AI over relatively short time horizons. I also consider it to be plausibly testing a capability relevant to tasks of broader import. For multimodal tasks, at least, one person having fun over the course of a week can still make interesting benchmarks. Other examples of this: SpatialBench and IRGB. Arguably ARC-AGI and other videogame benchmarks fit this bill as well.
Keep the classic format, but push the time horizons
The first generation of “long context” benchmarks would fill a model’s context window with data, often at least partly synthetically generated, and ask the model to process that data, often without tools. This measured the model’s “native” ability to keep track of lots of threads at once. Some such benchmarks still show some headroom. But, on the one such benchmark for which Anthropic reported scores, Claude Mythos jumped to 80%,2 where prior scores had been less than 40%. Perhaps this specific kind of long-context benchmark is nearing the end of its utility.
Even so, I suspect long, reasoning-oriented benchmarks still have room to run. One direction I’m particularly interested in is games. While many games have significant multimodal aspects, I think some — often card-based, like Magic: the Gathering — have relatively little, while still demanding a high level of both strategic and tactical reasoning. A single game instance isn’t necessarily long, but the more relevant unit of play may be a sequential run of games. After all, that’s the context in which humans get good at a game. Can AI do the same? I think existing evidence on this is negative, but it’s surprisingly patchy. Benchmarking could improve our picture here.
I also think very long-running software engineering projects may not be tapped out. My colleagues have written recently about how some software engineering tasks which may take humans weeks seem to be within reach for AI systems. These are tasks especially well-suited for runtime hill-climbing, since they are very precisely specified. Still, I suspect that the harder end of this difficulty scale may remain unsaturated. Can an AI system implement a C compiler that works as well and as efficiently as commonly-used human implementations? Maybe so, but it’s worth testing.
Bite the bullet on hard-to-grade outputs
This is hardly an unpopular opinion in benchmarking: of course tasks of real-world relevance don’t often have short-form right-or-wrong answers. This remains true even of tasks that are heavy on reasoning. For instance, my colleague Anson recently wrote about trying to get AI to do his job, and two of the tasks he chose were replicating an interactive web interface for a complex economic model, and analyzing a given dataset and writing a publication-worthy article about the results.
If everyone knows this but the field has been slow to move in this direction, maybe all we need is a bit of coordination to make a more regular and rigorous practice of such evaluations. I was thus encouraged to see the formation of CRUX, a collaboration of researchers engaging in evaluations “in real-world environments where success cannot be neatly specified or automatically graded”. They also have a nice aggregation of previous one-off experiments like Anson’s.
This territory isn’t as new as it may seem. An early instance of just this sort of evaluation took place at the 2025 International Math Olympiad (IMO). AI solutions were graded by the official judges, using the same criteria as were applied to human solutions. The AI benchmarking thus piggy-backed off the pre-existing human practice of grading IMO solutions, which had been developed and refined over decades. This went so smoothly that I saw relatively little commentary on how unusual it was for a benchmark.
I think this points to a good way to evaluate increasingly sophisticated AI output: plug into pre-existing practices where humans already judge each other’s work. Can an AI system win a best paper award at an ML conference? Publish a law review article? Win a short-story writing contest? Collaboration with professions where judging written output is central — science, law, journalism, entertainment — could lead to many benchmarks that are messier but in many ways more informative than what we have today.
Target well above human expert ability
Benchmarks in scientific and technical domains often target top human expert performance. AI systems haven’t saturated all such benchmarks yet, but progress has been rapid. Where do we go when that finally happens? In several cases, we can just pose tasks that humans don’t know how to do; we don’t even need to give up easy grading.
This is precisely what we’ve done with FrontierMath: Open Problems: find open math problems which humans have tried and failed to solve, but where solutions can be evaluated programmatically. These are hardly trivial to devise, but once devised they can be run at scale. These might not lend themselves to simple accuracy metrics, but, on the plus side, each benchmark task becomes a valuable case study in its own right.
A broad category of optimization problems fits this bill as well: there may be a human baseline, but we don’t need to consider the benchmark saturated when that baseline is reached. Some great work already along these lines includes PostTrainBench, which asks how effectively AI systems can post-train ML models, ALE-bench, which asks how well AI systems can program constraint-solving engines, and AlgoTune, which asks how much AI systems can speed up general-purpose numerical programs.
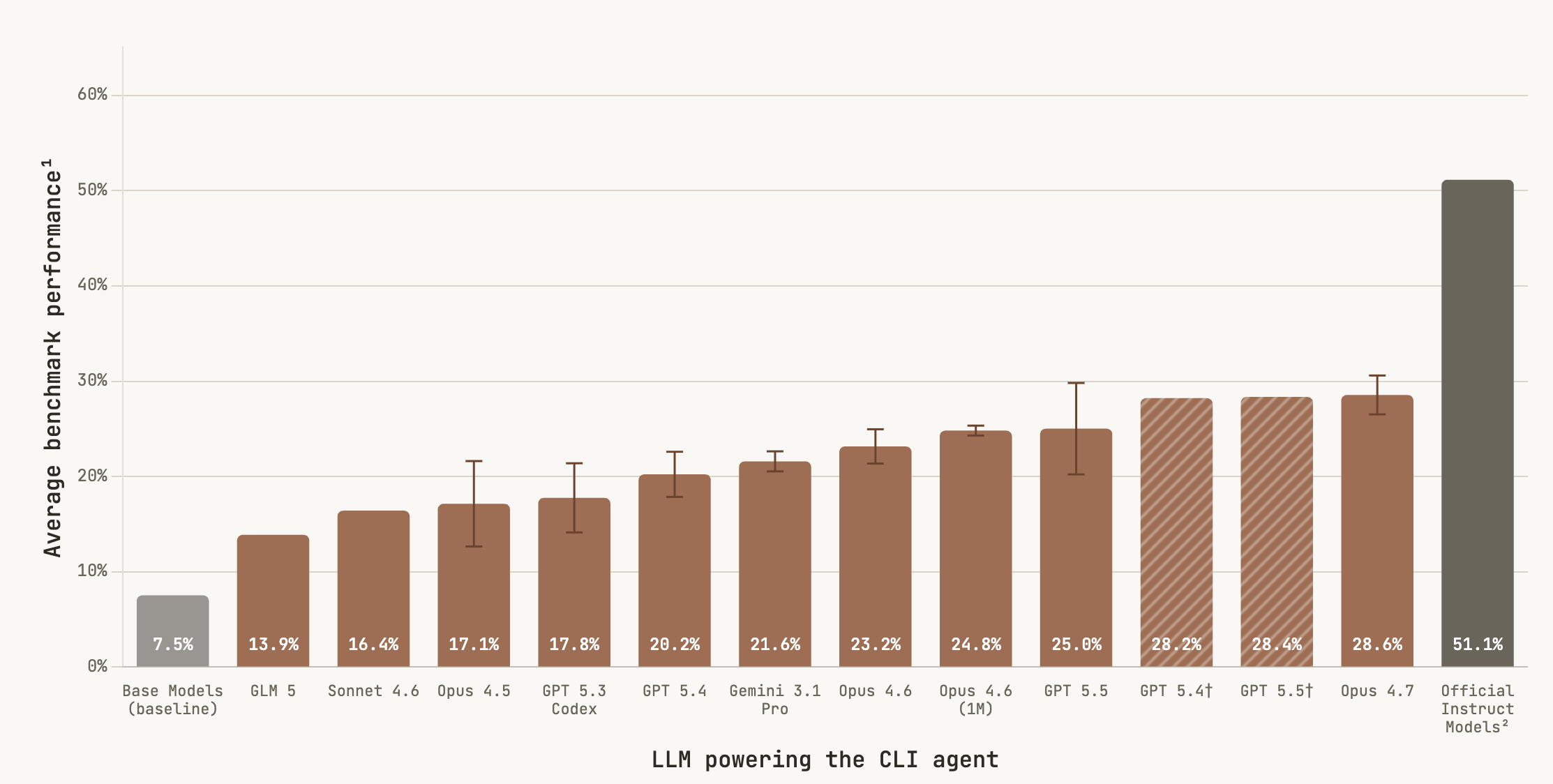
Results on PostTrainBench. There’s no reason to stop at 51.1%!
In some sense, such benchmarks will always be relevant. Even if it’s all AI doing the work, there will always be questions of resource optimization.
What about common sense?
For all this talk of advanced reasoning, GPT-5.5 Pro still regularly gets my favorite GSM8K question wrong.
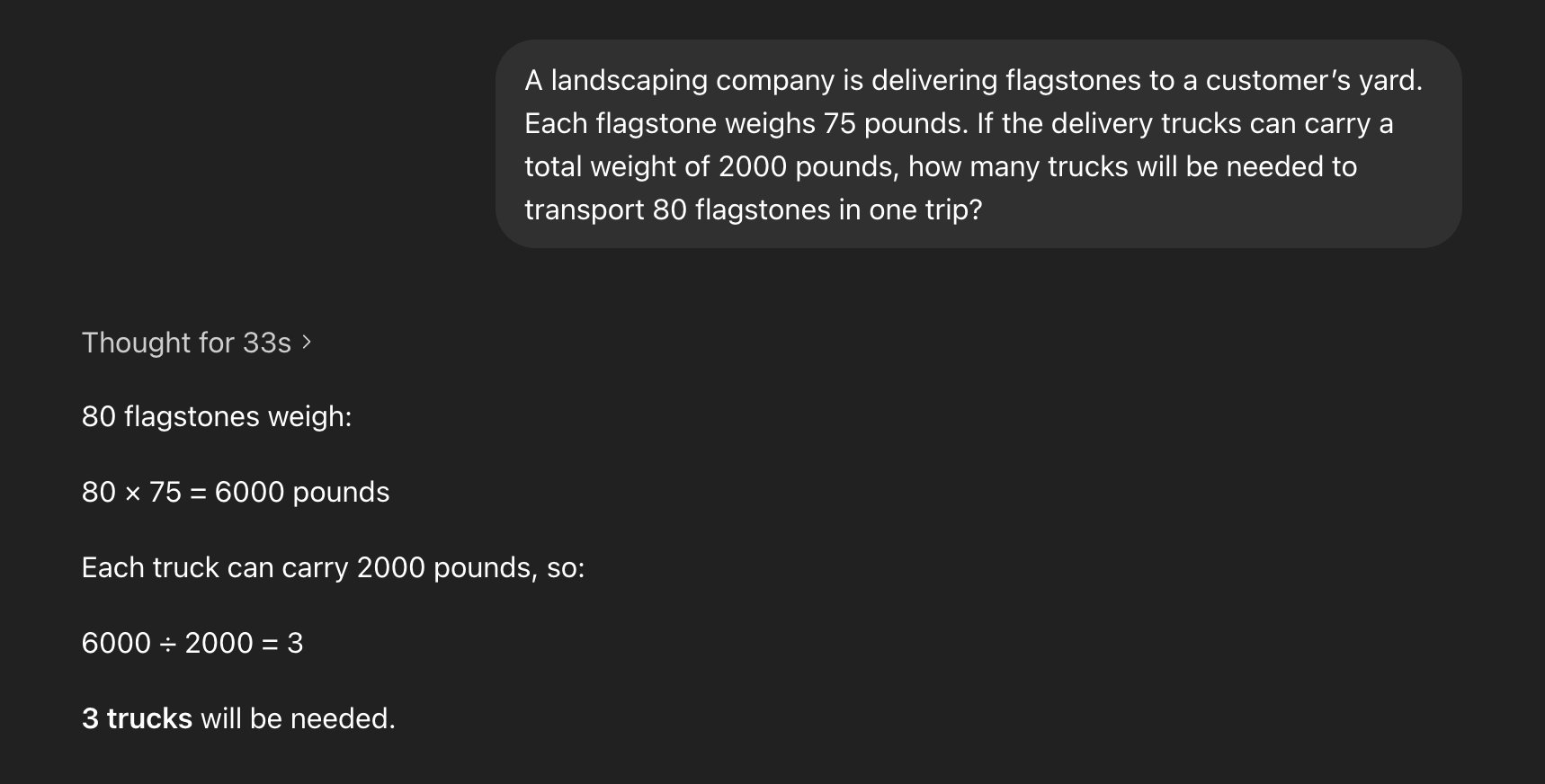
This is something of a trick question, though I suspect it wasn’t intended to be. Humans get it wrong too. This isn’t a completely isolated example either, for instance some models suggest walking (not driving) to a nearby carwash to get your car cleaned. What do we make of this?
These instances are somewhat analogous to human cognitive biases, often taking the form of getting a question wrong mostly due to not thinking too carefully about it. My personal sense is that they are getting harder to find. One systematic attempt at measuring something like this, SimpleBench, has seen models climb close to the average human baseline over the past year and a half.
If such benchmarks don’t saturate entirely, they will serve a role of deflating the strongest claims of AI infallibility. That said, I suspect their practical relevance is limited: if such “gotchas” do arise in the course of larger, real-world tasks, I suspect AI systems will be more adept at catching their own mistakes, even if not on the first pass.
Reasoning benchmarks aren’t dead yet
As AI systems get more capable, there’s an increasing temptation to benchmark them only on end-to-end tasks with practical, real-world consequences. I think it’s valuable to do so. I also think it’s obvious that AI systems don’t “just work” in all such cases. That leaves us with the question of why exactly they fail. One possible failure mode is not being able to reason through the problems they encounter along the way. Given that, I think reasoning benchmarks still have a role to play.
But the benchmarks we build still have to rise to the challenge of finding places where models still struggle. I’ve given my recipe. Give up on at least one of: text only, short time horizon, easy to grade, and expert human superiority. This makes benchmarking more challenging, but also more interesting than ever.
-
We don’t have a strong human baseline, but our light experiments suggest that humans can do this in well under half an hour.

-
This benchmark is GraphWalks. See Table 6.3.A of the system card for Mythos’s score.