

Our latest benchmark suggests AI struggles to learn from experience
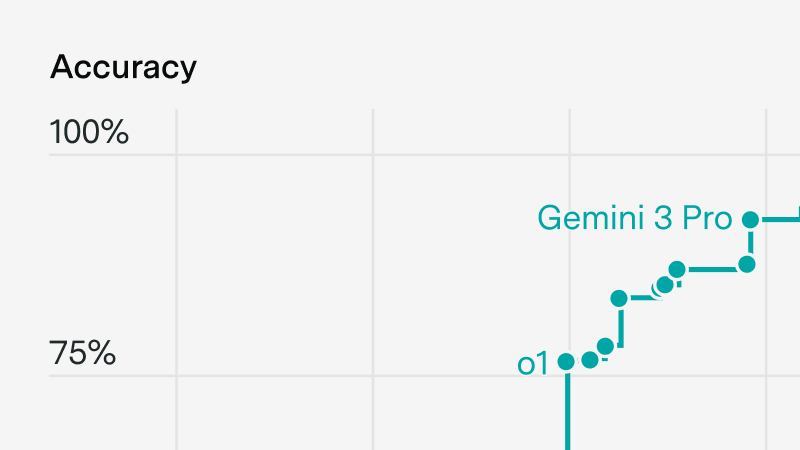
Give up at least one of: text only, short time horizon, easy to grade, and expert human superiority.

In this episode, Greg Burnham and Tom Adamczewski join Anson Ho to push back on benchmark pessimism and dig into what the next generation of AI benchmarks could look like.
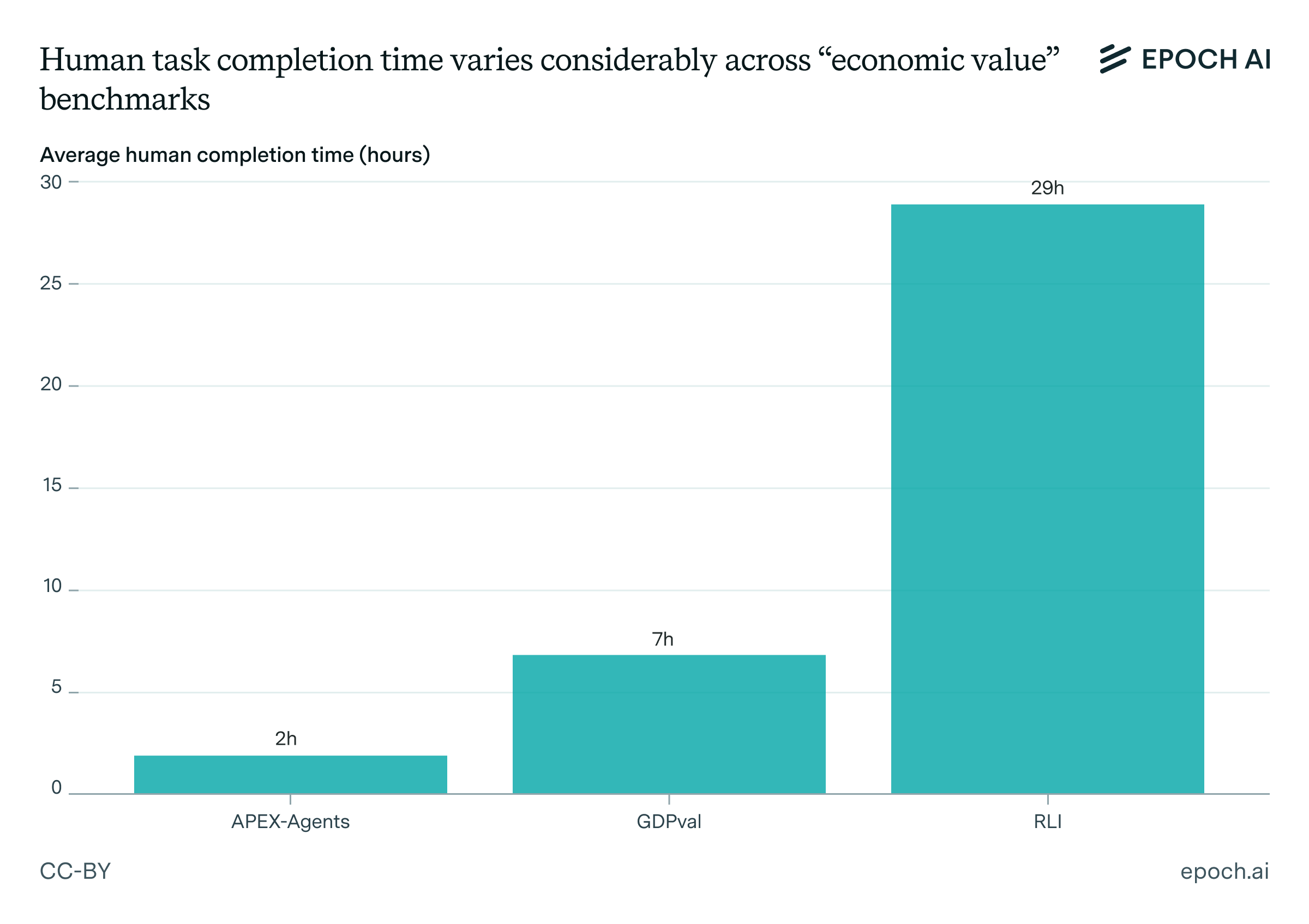
These benchmarks track a wide range of digital work. Progress will correlate with economic utility, but tasks are too self-contained to indicate full automation.

In this episode, Daniel Litt chats with the hosts about AI’s limits in mathematics, accelerating math research, and how to measure progress on open problems.
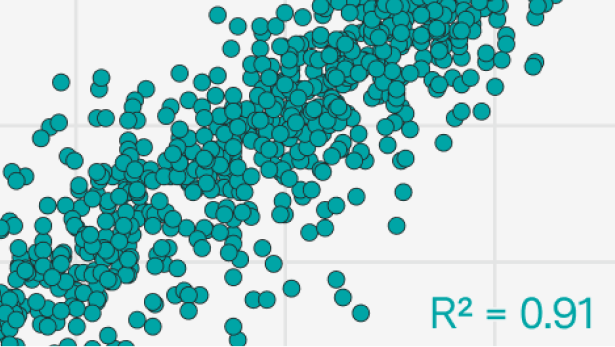
Is this because skills generalize very well, or because developers are pushing on all benchmarks at once?
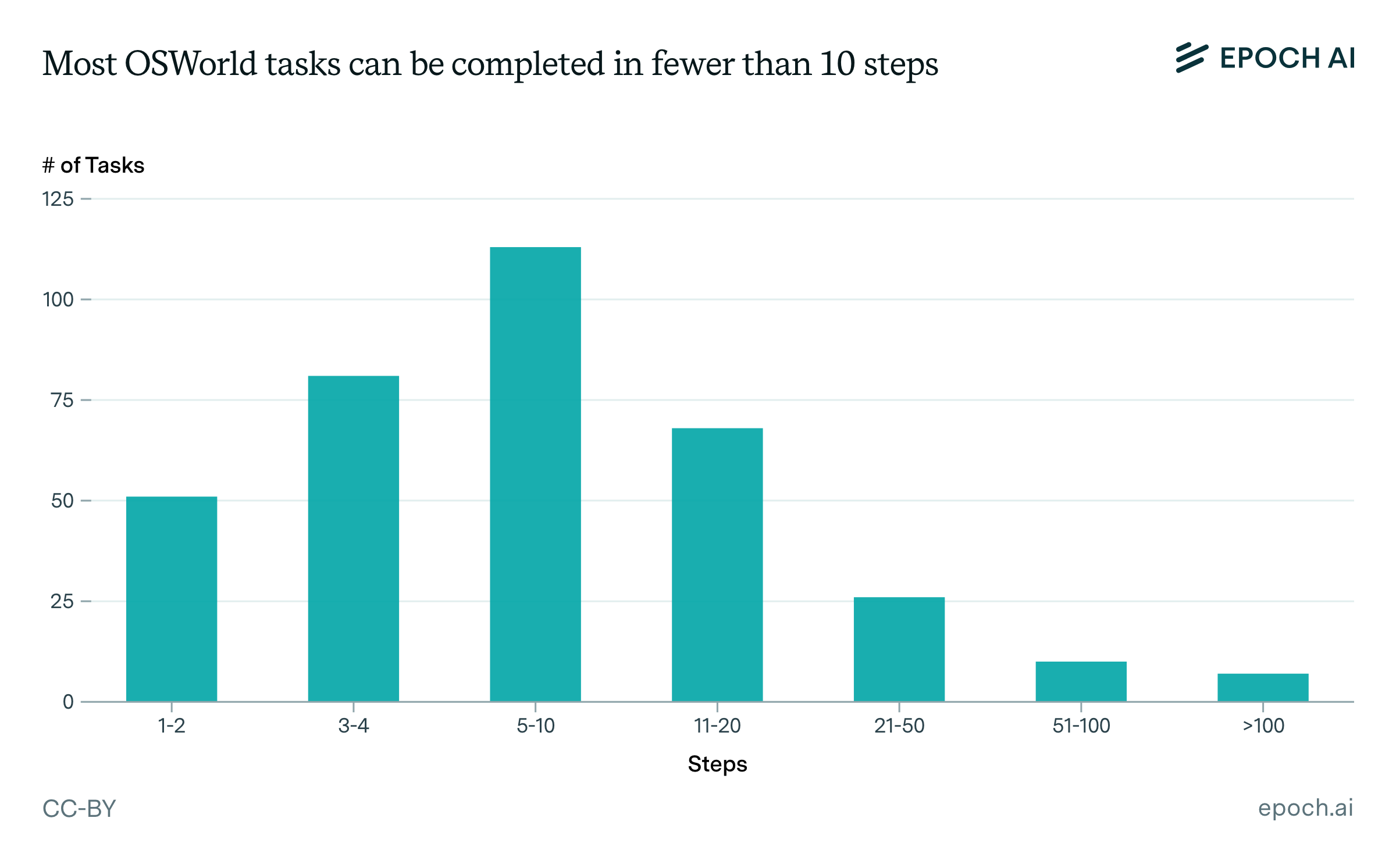
We review OSWorld, a prominent computer use benchmark. Its tasks are relatively simple, many don’t require GUIs, and success often hinges on interpreting ambiguous instructions. It is also not stable over time.
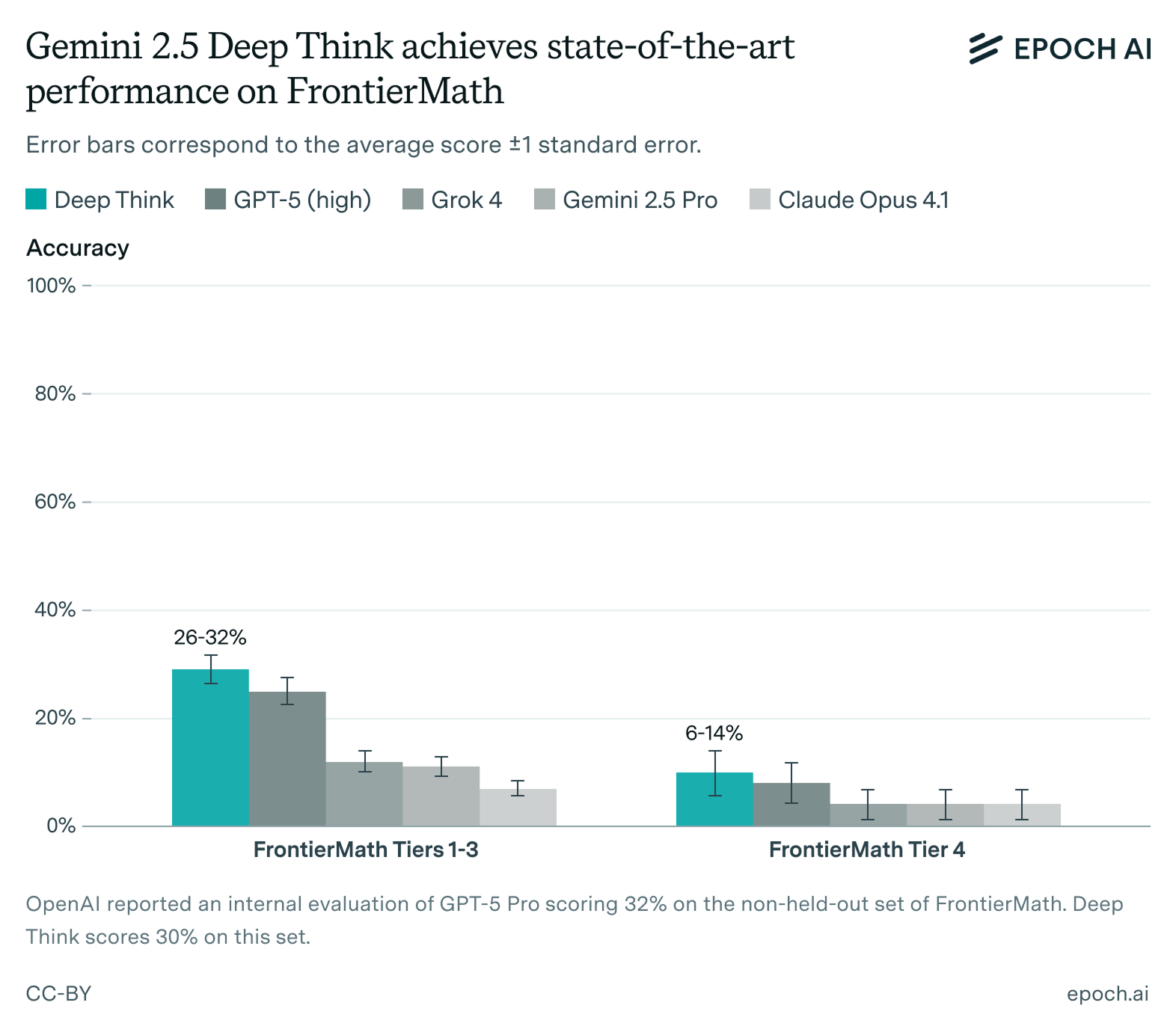
57% of problems have been solved at least once.

No company has gone from $10B to $100B as fast as OpenAI projects to do.
It has improved at using background knowledge and doing precise computations. It can be a helpful research assistant and may take a more conceptual approach to geometry. It shows limited creativity and sometimes struggles with citations.
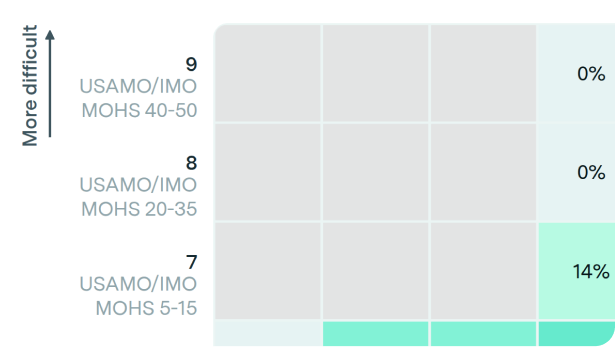
The problems gave AI only a slim chance to show new capabilities
It’s good at involved computations, improving at proofs from a low base, and useful for literature search. It still favors low-level grinds and leans on background knowledge.
Most discussion about AI and the IMO focuses on gold medals, but that's not the thing to pay most attention to.

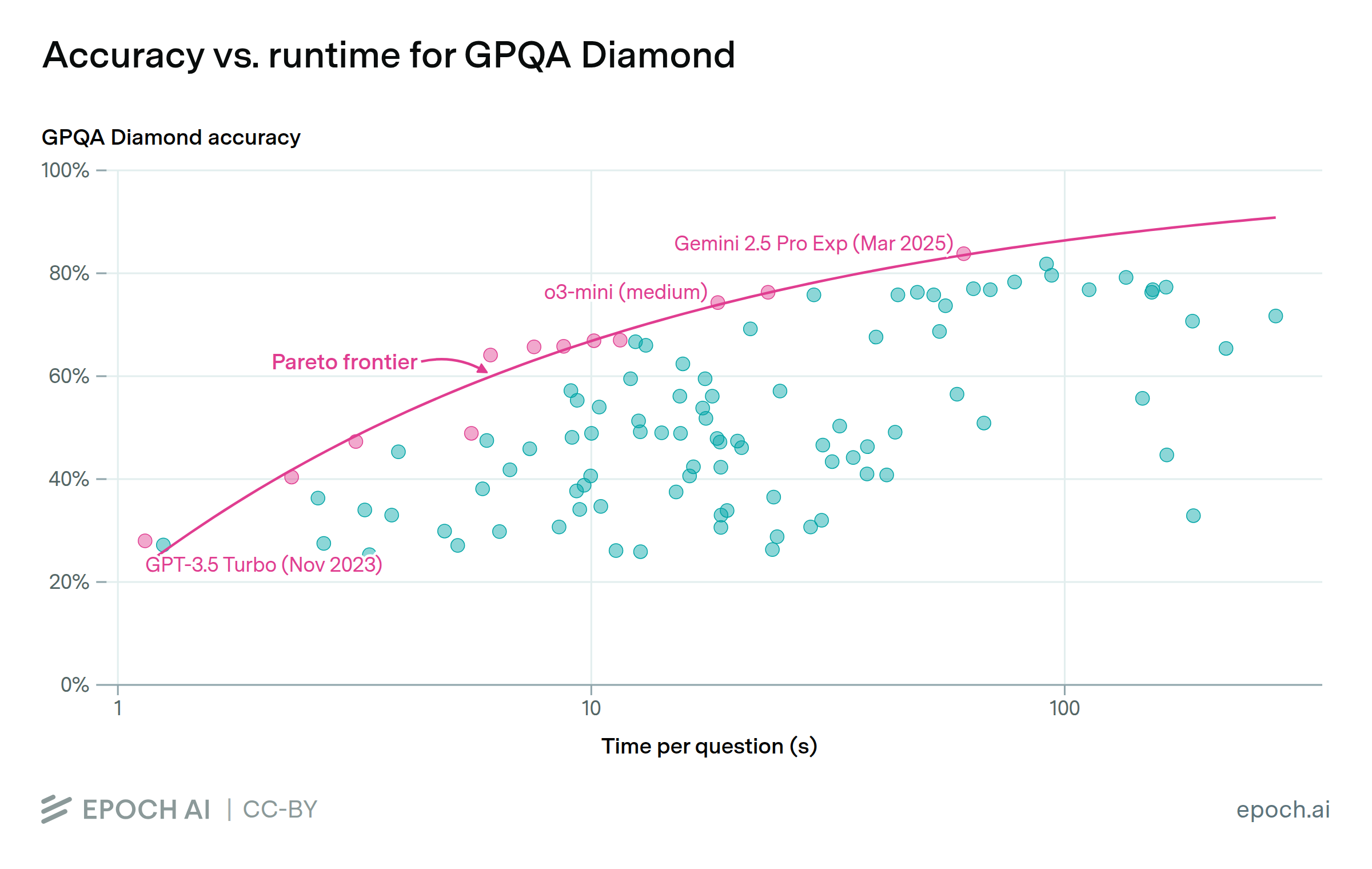
Investigate GPQA Diamond benchmark's validity: uncover flawed questions, model challenges, and why it still informs AI evaluation.