OSWorld is a benchmark for evaluating large language models on computer use tasks. A model is given task instructions and an Ubuntu virtual machine and must execute actions to perform the task.
- Size: 361 computer use tasks
- Data sourcing: Humans, forums, tutorials, etc.
- Scoring method: Evaluation function
- Contamination risk: Medium
If AI systems are to be digital coworkers, they will need to be able to use computers. In this article we review OSWorld, a popular benchmark designed to measure progress toward this milestone. What is in this benchmark, how should we interpret progress, and what will it mean when AI systems score near-perfect, i.e. have saturated it?
Main Takeaways
- Saturation on OSWorld means a model can execute simple, realistic tasks in Linux-based environments using popular open-source applications. These include things like adding page numbers to a document or exporting a CSV file from a spreadsheet.
- The benchmark is not stable over time, which makes comparing results across time challenging.
- A major update in July affected most task instructions. Even since then, about 10% of task instructions have been updated.
- About 10% of tasks rely on live data from the Internet, meaning the difficulty or feasibility of these tasks may change over time as websites change.
- Much of OSWorld can be completed with little or no use of a graphical user interface (GUI), meaning that scores reveal less about the AI’s ability to use the GUI.
- About 15% of tasks only require a terminal.
- An additional 30% of tasks can be completed by substituting terminal use and Python scripts for much of the intended GUI use.
- Many tasks have moderately ambiguous instructions, such that scores partly measure the ability to correctly interpret the instructions rather than pure computer-use ability.
- About 10% of tasks have serious errors that render them invalid, a rate on par with many benchmarks.
Given these facts, it is difficult to interpret differences in scores reported on OSWorld. Differences could be driven by GUI-based computer use capabilities, but they could also be driven by changes to the benchmark data, terminal and Python capabilities, or the ability to interpret ambiguous instructions.
To sum up our feelings after writing this review: constructing a computer-use benchmark that is both realistic and rigorous is hard. We have great respect for the efforts of the OSWorld team.
OSWorld setup and evaluation
A benchmark task is presented to the model as follows:
- An instruction describing the task to be performed.
- An Ubuntu virtual machine: sometimes starting with a blank Desktop, sometimes with specific applications opened. The machines are connected to the Internet.
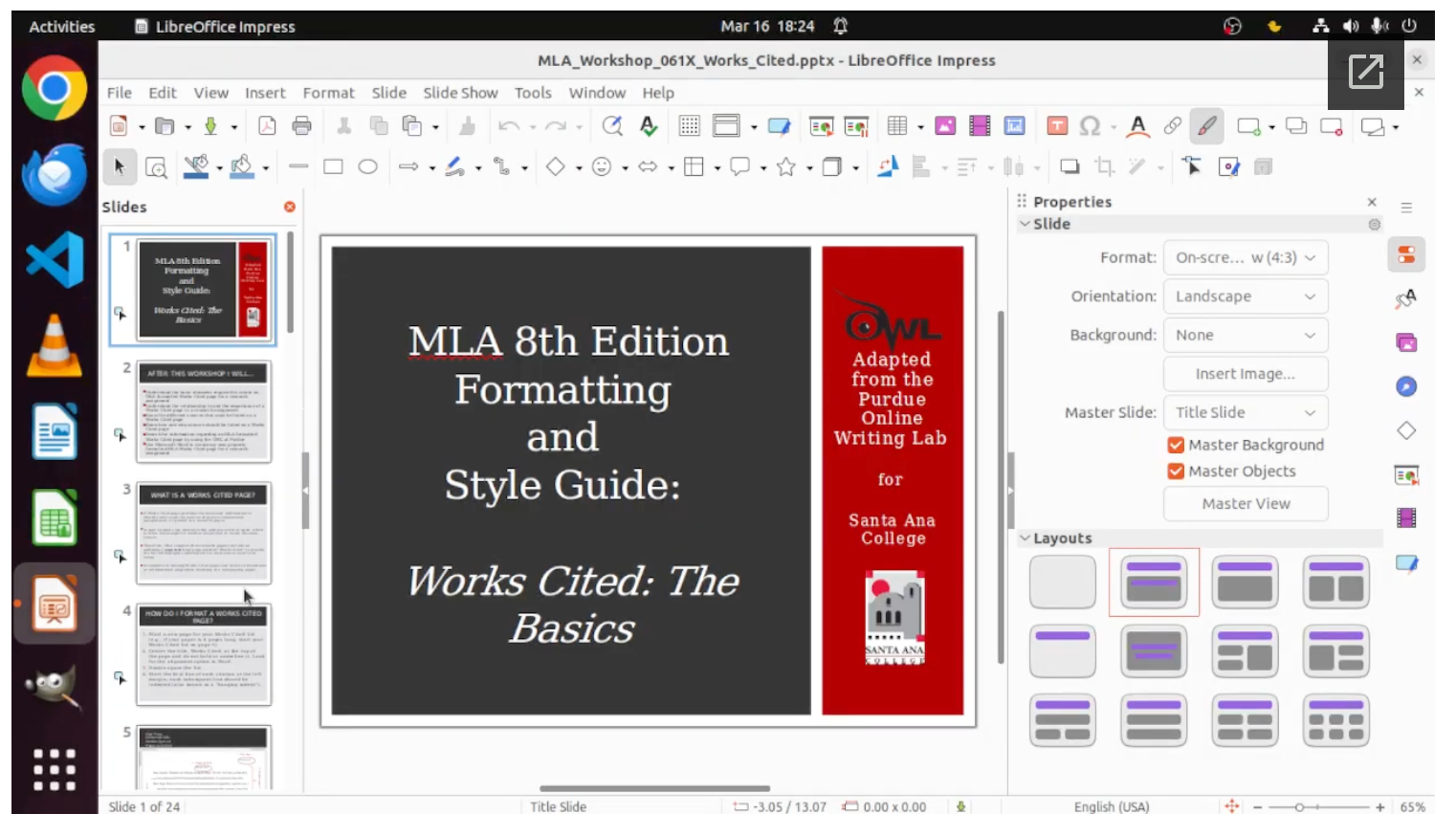
Example starting state for a task, with a LibreOffice Impress file open.
The task instruction is, “Make a duplicate of the last two slides for me, please.”
Tasks are sourced from the benchmark authors as well as drawn from resources like forums and tutorials.
Evaluation scaffolds provide a general prompt describing the setup and expose the state of the machine to the model.1 Models interact with the machine by writing Python code using pyautogui, a package for programmatically controlling the mouse and keyboard.
When the model is finished with the task, the state of the machine is evaluated on whether it has achieved a specified target state. Intermediate steps are not evaluated: a model is not penalized for achieving the target state through an unexpected or unintended series of actions.2
OSWorld consists of 361 tasks.3 About 8% of tasks are designed to be impossible to complete, typically due to the instructions asking for something that is not supported by an application. In such cases, models are supposed to state that the task is infeasible.
OSWorld task instructions are continually updated, making through-time comparisons of uncertain value
The team behind OSWorld continues to make improvements to the task instructions. A major release in July, 2025 included updates to most task instructions and evaluation functions. Even since then, an additional 10% of task instructions have been changed. To the extent that the corrected errors had been rendering tasks unnecessarily difficult or impossible, this will give a spurious appearance of improved model capability over time. While the effort to correct errors is commendable, this is a highly atypical practice for non-live benchmarks as it decreases the meaningfulness of through-time comparisons.
Saturation on OSWorld means a model can do simple, realistic tasks in Linux-based environments using popular open-source applications
Overall we found the tasks to be representative of practical, real-world workflows: the sort of tasks people do on computers all the time. Most tasks are relatively simple by human standards, typically a sub-part of a larger activity. All tasks use the Ubuntu distribution of Linux and focus on the open-source applications commonly shipped with it.4
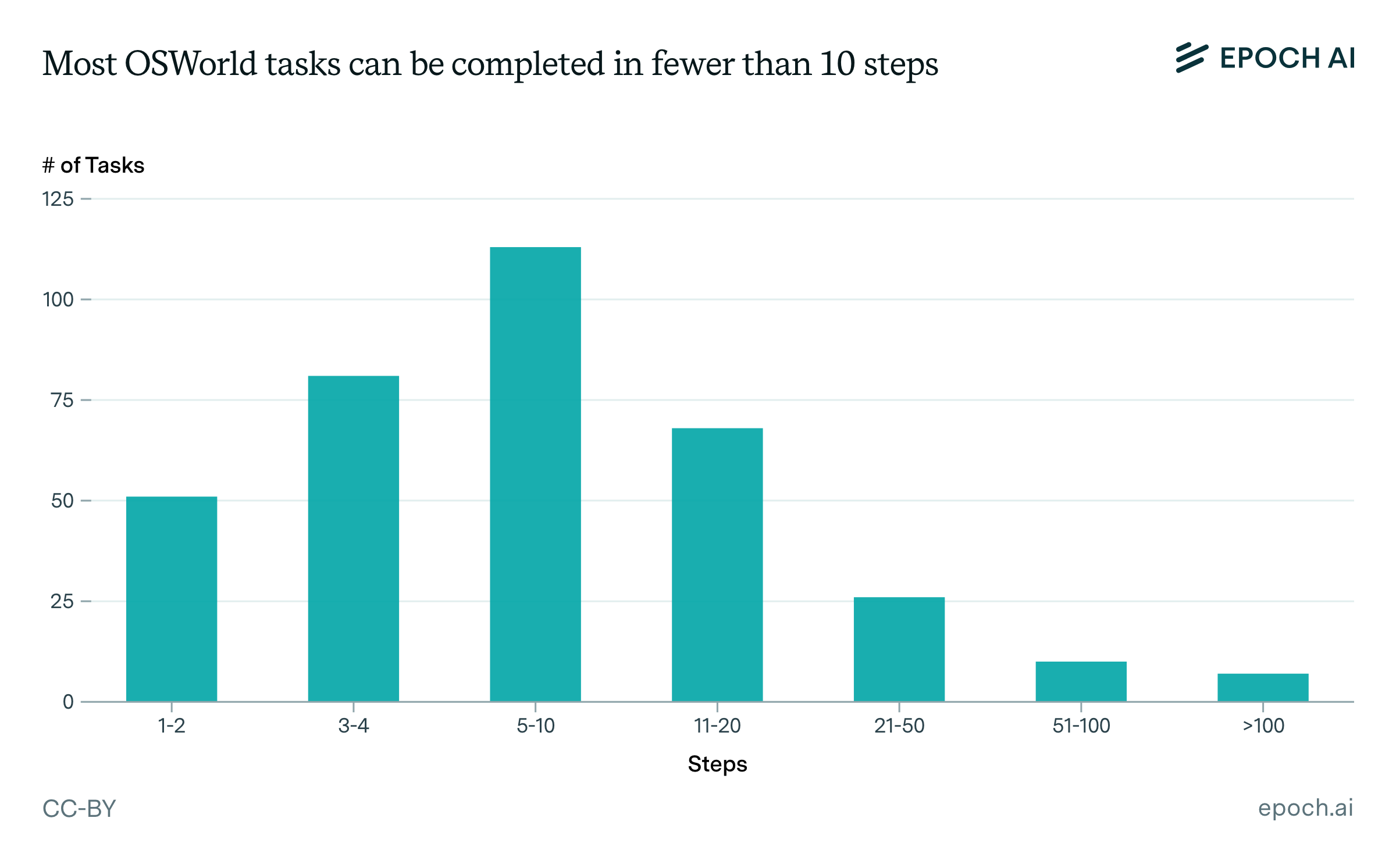
Most tasks are simple
To understand the complexity of OSWorld tasks, Abhyankar et al. analyzed the minimum number of atomic actions (clicks, text entries, keyboard commands) required to complete each task. Their analysis revealed that most tasks could be completed in fewer than ten steps. A few tasks require dozens or even hundreds of steps, but the majority of tasks represent work that would take a human only a few minutes to complete.5

Task length varies somewhat depending on what programs are used, with LibreOffice Calc (the open-source spreadsheet program) and multi-application tasks requiring relatively more steps.
An example of a task requiring the median number of steps (6) is to edit an image, where the setup begins with the image already opened in GIMP.
Could you fill the background layer with green color, leaving the object layer as is?
A much rarer, more involved task (104 steps) is to grade multiple choice tests and enter the data into a spreadsheet.
I am grading students' English exam papers, but the test consists only of multiple-choice questions. It's too exhausting to check each question one by one and record the detailed scores. Can you help me compare the remaining students' answers with the answer key and record the detailed scoring in the opened spreadsheet?
About 12% of tasks require more than 20 steps and only 5% require more than 50. Given the relative rarity of these longer tasks, we don’t expect task length to be a significant driver of performance differences among models.
Tasks use a variety of applications
OSWorld features a diverse set of tasks, spanning commonly used applications including web browsers, code editors, spreadsheets, and image editors.

About one-third of the tasks require interaction across multiple applications, e.g. downloading files and processing them in other applications. Tasks are fairly evenly distributed across application categories. We found tasks to be generally relevant to real-world workflows.
The titular OS is Linux and applications are open source, but this is probably not a major issue
Every OSWorld task setup uses Ubuntu and open source and freeware applications like LibreOffice, Chrome, and GIMP. Naturally, Windows and Microsoft Office are much more widely used, and the exact steps for performing analogous tasks in such an environment would differ. This means the benchmark is not directly representative of most common computer-use scenarios.
This kind of mismatch would generally lead us to worry that performance on a benchmark might not translate to real-world utility. But, if anything, the concern with OSWorld is reversed: if model developers focus on more popular operating systems and applications, OSWorld scores may lag relevant ability. Overall we suspect this is not a big problem, as there is some evidence of domain transfer and we suspect major developers would train on data from all available operating systems.6
Terminal use and Python scripting can go a long way
The image brought to mind by “computer use” is clicking around a GUI. We thus were interested to learn that almost half of OS World tasks require little or no GUI interaction.
About 15% of tasks can be completed using only a terminal
Using a terminal is part of using a computer more broadly, and some OSWorld tasks reflect this. For example, here is a task about force-quitting a program from the terminal.
Hey, my LibreOffice Writer seems to have frozen and I can't get it to close normally. Can you help me force quit the application from the command line? I'm on Ubuntu and I don't want to restart my computer or lose any other work I have open.
For other tasks, it is less clear whether terminal use is the intended workflow, as opposed to pointing and clicking in the GUI. For example, this task is about installing a VS Code extension. This can be done via a terminal command (code --install-extension /home/user/test.vsix) as well as in the GUI.
Please help me install an extension in VS Code from a local VSIX file "/home/user/test.vsix".
For a benchmark designed to cover broad computer use, these tasks seem appropriate. However, their presence must inform our interpretation: if a model improves on the benchmark, it may have improved primarily on terminal use, and not necessarily on the GUI manipulation that comes more readily to mind when we think of “computer use” benchmarks.
About 30% of tasks can substitute terminal use and Python scripting for much GUI use
Relatedly, there is a further set of tasks where the intended workflow uses a GUI, but the required GUI use can be significantly reduced through the use of the terminal and Python scripts. This is particularly true for spreadsheet tasks, given the existence of Python packages for programmatically modifying spreadsheets.
For example, consider this task about editing a spreadsheet.
Fill all the blank cells in B1:E30 with the value in the cell above it.
The model would have to interact with the environment to determine what spreadsheet the task is referring to — in this task setup, LibreOffice Calc starts with this spreadsheet open — but beyond that, it could use a Python script to achieve the spreadsheet modifications. This is, of course, not how a human would do this task. But models that are more “comfortable” with code may go this route, and the OSWorld evaluation would not penalize them for doing so.
Looking at the official leaderboard, models with access to code execution tools score considerably higher than GUI-only agents. We observe many cases of these models using software packages that might help avoid GUI-use, such as openpyxl for manipulating spreadsheets. We actually also observe some cases of models without code execution tools included in their scaffold nonetheless downloading such packages. The screenshot below shows Claude Sonnet 4 installing openpyxl and pandas for a task that asks for contact information to be extracted from a set of documents and organized in a table in Excel.
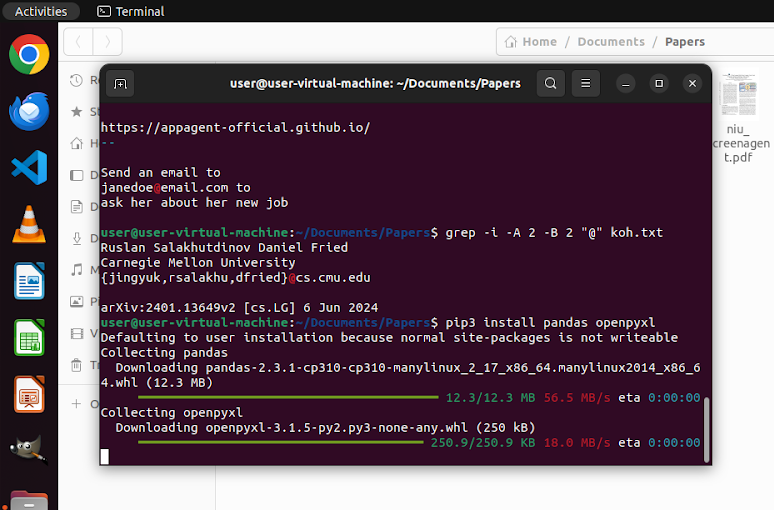
We do not quantify how prevalent this behavior is, but it certainly happens.
Many instructions are borderline-ambiguous and discerning the instruction’s intent is a significant part of succeeding
We found many tasks to be ambiguous at first blush. Upon closer examination, there was often a reasonable guess that one could make, which often corresponded to the gold results. In some ways this is highly realistic: a human may give an AI assistant a somewhat-ambiguous task, and it is certainly desirable for the assistant to be able to take a reasonable guess.7
However, we were surprised how often this seemed to be, by far, the hardest part of a task. For example, consider this task below about editing a presentation.
Align the first textbox on slide 3 to the right, on slide 4 to the center, and on slide 5 to the left. Ensure that the alignment is applied correctly to each respective slide.
The first ambiguity with this task is whether “align” refers to the text within the textbox or the textbox itself. That is, should the model leave the textbox in the same position, but change the alignment of the text within it, or should the model leave the text as-is, but move the textbox?

Slide 3 of the associated file, with the relevant textbox selected.
One of the authors felt this was ambiguous, while the other author felt the term “align” was more clearly associated with the text itself.
However, the ambiguity deepens. On two of the relevant slides, multiple text boxes are “grouped” into a single object. When the instruction says “the first textbox”, does it mean all boxes within the group, or just the top-most? Or does this cause us to consider whether perhaps we should move the grouped object and leave the text itself as-is?

Slide 4 of the associated file, with the relevant group object selected, showing its two constituent textboxes.
Again one of the authors felt this was fatally ambiguous, while the other felt that the best guess would be to align the text itself within only the first (top-most) box within each group. It turns out that this is indeed the intended resolution of the task.
We expect that not all readers would agree as to what tasks have an acceptable vs. unacceptable amount of ambiguity. We found amongst ourselves that, the more familiar a person was with common standards for producing the relevant outputs for a task (slides, images, code), the less likely that person was to find that task’s instructions to be fatally ambiguous.
Regardless, navigating this ambiguity is a separate skill from being able to use computer programs. A model may have all the requisite computer-use skills to complete OS world tasks and still fail if it makes reasonable but incorrect guesses about an instruction’s intended meaning.
Due to the subjective nature of this issue, it is difficult to estimate what percentage of tasks fall into this category. That said, we can note that the human baseline from the original OSWorld paper was 72%, suggesting that ambiguities affect no more than 28% of tasks.8
About 10% of OSWorld tasks have serious errors
This is not an unusual error rate for AI benchmarks. Below we note some common error classes we found among the tasks.
Some tasks are broken in straightforward ways, e.g. the evaluation function checks for a final numerical value to be outputted by a calculation, but the gold numerical answer is wrong.9
We also observed overly-strict and overly-lax evaluation functions. As an example of a strict evaluation function, consider the following task.
On the current website, show me the cars available for pickup at Boston Logan Intl Airport from the 10th to the 11th of next month, sorted by the number of seats to find the largest capacity.
While the instruction simply asks for “the 10th to the 11th”, the evaluation function checks for the time of day to be set to 12PM for both days. As an example of a lax evaluation function, consider the following task.
The cells are so big that I can not click on the cell I want, zoom out a little bit.
The spreadsheet that is opened for this task is zoomed to 260%. However, the evaluation function only checks that the model has decreased the zoom level. We found that clicking the zoom bar in a specific spot could zoom out arbitrarily, and thus a model would be graded successfully for, say, zooming out to an impractical 10%.
We also observed several tasks that did not actually ask for an action to be taken. We expect that the general prompt given to the model as part of the scaffold will encourage the model to take actions, but in some cases the instructions were phrased in a way such that the model would be disregarding the plain meaning of the instructions if it took actions as opposed to simply providing information. For example:
On my surface pro whenever I launch Chrome it always opens "funbrain.com." I don't want this. I cleared my cache but it still happens. What should I do?
Finally, some ambiguities were beyond repair. For example, we could not find a clear referent of the “IMDB Top 30 list” mentioned in this task.
I'm a huge movie fan and have kept a record of all the movies I've watched. I'm curious to find out if there are any films released before 2024 from the IMDB Top 30 list that I haven't seen yet. Help me create another sheet 'unseen_movies' in the opened Excel. This sheet should share the same headers and sort the results according to IMDB rankings from high to low.
About 10% of OSWorld tasks rely on live data from the Internet, and thus their difficulty may change over time
Some tasks rely on the use of a web browser and the extraction of data from live websites. These tasks could change in difficulty, or become infeasible, as the websites change or the underlying information changes.
For a particularly brittle example, consider the following task which asks the model to find a hotel on TripAdvisor.
Find a Hotel in New York City with lowest price possible for 2 adults next weekend.
The evaluation script for this task relies on exact, absolute XPaths to check for the presence of particular HTML elements in the website that the model navigates to. Updates to the structure of the TripAdvisor site would render this task unsolvable. Other web-based tasks are less brittle, though many rely on the continued existence of a particular URL.
Conclusion
OSWorld helps tell us how good an AI system is at executing simple, realistic tasks in Linux-based environments using popular open-source applications. State-of-the-art models have come a long way on the benchmark, from less than 10% to almost 70%. It is fair to say that much of this reflects improved computer-use capabilities.
However, progress must be interpreted with caution: task difficulty changes over time in unpredictable ways, many tasks can be completed without using much or any GUI interactions, and the skill of interpreting the instruction is sometimes as important as the skill of using the computer.
Thanks to Parth Patel from HUD for feedback on this article.
Appendix
Versions and variants of OSWorld
OSWorld was originally developed by researchers from the XLANG Lab at the University of Hong Kong and released in April of 2024. The same team made a major update dubbed OSWorld-Verified in July of 2025, which included fixes to many benchmark tasks. However, unlike some benchmarks, the “Verified” modifier does not seem to have stuck: even recent references to the benchmark still just call it plain “OSWorld”. As described above, the XLANG team has continued to update the task instructions, with over 10% of tasks affected since the Verified release. This article is about a recent version of the main repository of the benchmark, which we refer to simply as OSWorld.
Additional variants of the benchmark have been built on top of OSWorld. These include:
- OSWorld-Human, which adds annotations of how humans solve the tasks.
- OSWorld-Grounding (aka OSWorld-G), which uses OSWorld tasks and agent trajectories on these tasks to develop more granular, single-step tasks.
- OSWorld-MCP, which expands OSWorld with additional MCP tools.
Methodology
For this article, one of the authors inspected and categorized every benchmark task along various dimensions described above: whether they could be completed using a terminal alone, whether they could minimize intended GUI interactions with terminal use and Python scripting, and whether they had serious errors. The other author reviewed a random sampling of these task categorizations and gave a second opinion. Except where otherwise noted, percentages given in this article are based on the rates at which both authors agreed on a task’s categorization.
-
This is done either via the GUI itself or the accessibility tree.

-
In the extreme, models could find the open-source OSWorld-Verified dataset online and download the relevant part of the target state, often just a single file. We are not aware of any cases of such cheating.
-
This excludes eight samples that involve Google Drive. Most evaluations exclude these due to technical challenges with using Google accounts.
-
It also uses the non-open-source applications Chrome and VS Code.
-
The original paper records median human completion time of 2 minutes, with a long tail including “a significant number” taking 15 minutes. Human testers were college students. We expect that a significant amount of these longer human time-to-complete tasks are due to humans learning how to use unfamiliar applications e.g. GIMP.
-
Wang et al. showed that training on data from OS A and OS B leads to better performance on OS A than training on data from OS A alone. As expected, training only on data from OS A still leads to worse performance on OS B than training on data from OS B directly.
-
One of the authors was unpleasantly reminded of an early-career job where his manager would give (what he felt to be) vague instructions for the formatting of presentation materials, and then be upset if the materials did not match their intent.
-
The paper doesn’t analyze the source of human errors. We assume it is a mix of ambiguous instructions, lack of human motivation vs. task difficulty, and invalid tasks (some but not all of which would have been fixed since release).
-
An example of this: “Export the table to a CSV file and then help me write code to find the medium price (fill empty value with average). Save the result in “result.txt”.” Our calc check gives a different answer (25.27) than the gold contents of results.txt (24.93).
About the authors


Related work