SWE-bench is a benchmark for evaluating large language models on real world software issues collected from GitHub. Given a codebase and an issue, a language model is tasked with generating a patch that resolves the described problem.
- Size: 500 Python-only coding problems with issue descriptions
- Data sourcing: Scraping of GitHub issues followed by human filtering
- Scoring method: Unit tests
- Contamination risk: High
Main takeaways
-
SWE-bench Verified tests AI’s real-world agentic coding skills, the kind required for coding tools like Cursor or Claude Code (link).
-
Most of the problems are relatively simple, needing less than 1 hour to fix for a human engineer (link).
-
The benchmark has a high contamination risk (link), and the tests might not generalize well to real-world, closed-source codebases (link).
-
The scaffold built around a model determines benchmark performance as much as the model’s raw capabilities (link).
-
Saturation on this benchmark would be strong evidence that models are capable of autonomously fixing small to medium issues in Python repositories (link).
Introduction
Large Language Models (LLMs) are already widely used for programming, and they are expected to make significant progress in the near future, with many AI leaders such as OpenAI’s CPO Kevin Weil predicting that coding will be largely automated this year.
Many benchmarks attempt to measure LLM progress in coding, such as LiveCodeBench or Aider Polyglot. However, these benchmarks test code in an isolated setting, requiring the models to solve LeetCode-style problems from scratch. This hardly reflects the real-world coding tasks that engineers face, which involve working in large repositories and require the ability to fix bugs, implement new features, or refactor existing code.
SWE-bench Verified is a subset of SWE-bench (Jimenez et al., 2023) that addresses this gap by evaluating models on their ability to understand, navigate, and fix actual bugs from large, popular Python repositories. While it is a lot more realistic than previous coding benchmarks, SWE-bench Verified primarily tests models’ ability to fix simple bugs in a small set of well-known repositories. Furthermore, the possible contamination risk raises questions about whether the benchmark generalizes to real-world, closed-source codebases.
Anatomy of a benchmark sample
SWE-bench Verified is based on 500 real bug fixes from twelve popular Python repositories. Each sample was created by scraping merged pull requests and their corresponding GitHub issues. This collection was then filtered to retain only PRs that were indeed merged and included modifications to the project’s test suite.
A sample given to a model running the benchmark only contains the following:
- The repository with the state before the PR was merged
- The issue description(s), including the title and body of the issue(s) related to the PR
For evaluation purposes and to establish a ground truth, each benchmark sample also contains:
- The original, human-written code (the gold patch)
- The test patch, which includes new or modified tests that accompanied the gold patch
- A selection of tests from the repo’s test suite that previously passed and should continue passing afterward (Pass-to-Pass), and tests that failed due to the bug and should pass after the issue is resolved (Fail-to-Pass).
How models are evaluated
Models receive what a repository maintainer would see: the codebase before the fix and the issue description(s). They are tasked to write a code patch for the problem. The patch is then applied and tested by running the two sets of tests from the sample (Pass-to-Pass and Fail-to-Pass).
The setup of the benchmark is realistic and tests the agentic coding skills of the model, which are important for increasingly popular tools and agents like Cursor, Claude Code or Codex.
The error rate in SWE-bench Verified is relatively low
One of the most important aspects of benchmarks is the error rate, i.e., the percentage of tasks that are either incorrect, ambiguous, or impossible to solve. We are confident that the rate of flawed or problematic instances in SWE-bench Verified is relatively low, between 5% and 10%.
There are two main reasons for this assessment. First, only issues that were merged by maintainers of the repositories are included. Therefore, every sample was vetted by the repository maintainers. Second, and more crucially, SWE-bench Verified is a verified subset of the original, 1600-sample SWE-bench dataset (SWE-bench by Jimenez et al.). For each sample, three independent human annotators, following a detailed rubric, assessed the clarity of the issue description, the appropriateness and robustness of the test suite, and overall solvability. This filtered out over two-thirds of the original samples, resulting in the final set of 500 high-quality instances.
However, annotations are never perfect, and our careful inspection of the dataset revealed some remaining problematic cases. We analyzed the outputs of the top five submissions from the SWE-bench leaderboard and identified 85 issues (17%) that none of the model-scaffold combinations could solve. We manually evaluated 40 of these particularly challenging issues, looking for unclear issue descriptions or overly restrictive tests1. Our analysis identified 14 invalid samples2. Applying this rate to the 80 samples that remained unsolved by all models suggests a 6% error rate. Extending this same error distribution to problems solved by only one or two of the five submissions would yield a total error rate of 10%. This suggests an overall invalid sample rate between roughly 5% and 10%. A looser assessment criterion, or judgments relying more on expert-specific repository conventions, could place the error rate closer to 5%.
Beyond direct problems with the samples, it is also possible that a model generates code which, while passing the provided tests, might inadvertently introduce new bugs not covered by the existing test suite3. This means that reported scores on SWE-bench Verified might be overstated.
Crucially, while the selection process for SWE-bench Verified samples is necessary to evaluate models, it also means that the benchmark tests a somewhat biased subset of real-world coding, where the issue is clearly written and the solution is unambiguously defined. This is not the messy reality most engineers face in their day-to-day work.
Most tasks are simple bug fixes
While SWE-bench Verified has a relatively low error rate, it does not measure models’ ability to resolve GitHub issues in general: around 90% of the tasks are fixes that experienced engineers could complete in under an hour. Therefore, the benchmark really tests whether AI can make simple codebase edits.
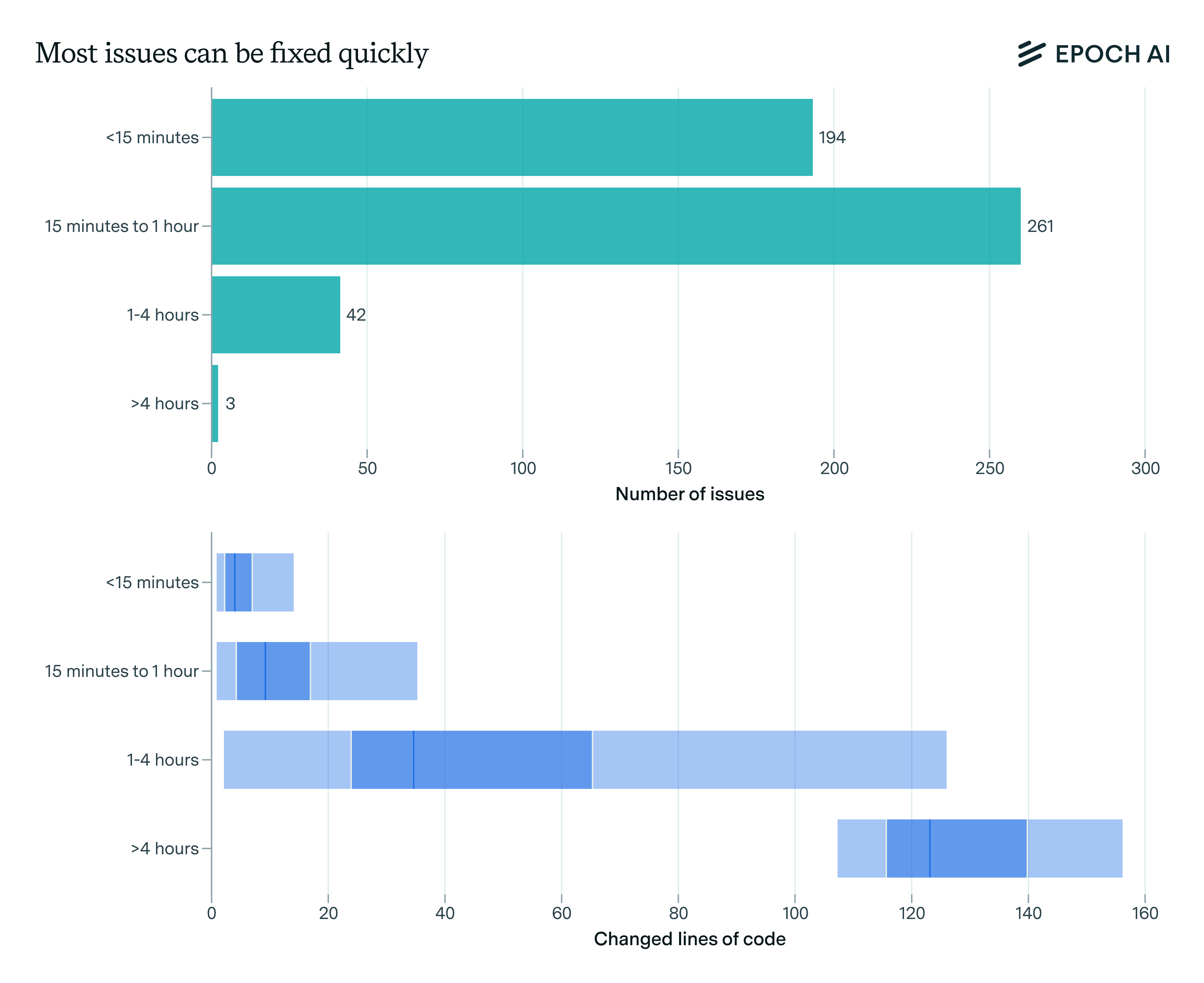
The SWE-bench Verified annotators estimated the time required to fix each issue by an experienced software engineer familiar with the codebase. 39% of tasks were rated as “trivial changes” requiring less than 15 minutes, while 52% were rated “small changes” taking between 15 minutes and 1 hour. Just three were estimated to require >4 hours.
METR found that these time estimates are too optimistic.4 On the other hand, the time estimates correlate well with the amount of code changed in the gold patch: quick fixes (<15 min) average only 5 changed lines of code (LOC), while tasks in the “15 min - 1 hour” bucket average 14 changed LOC. The “1-4 hours” category, representing just 8% of the benchmark, involves an average of 50 changed LOC, and the largest category (“>4 hours”) contains only three issues in total.
Amazon’s analysis of SWE-bench Verified supports this finding: they find that 78% of changes only touch functions, not classes (or both), with 1.87 functions needing to be changed on average. Furthermore, the vast majority of issues in SWE-bench Verified are classified as Bug Fixes (87%), with the rest being Feature Requests (9%) and Refactorings (4%).
The dominance of small issues can be explained by the curation process of the benchmark. Filtering for merged PRs that also change the test suite heavily favors small, isolated bugs. The human annotation, while crucial, also filters out issues that are not scoped clearly but might have been solvable with more context. However, the tasks human software engineers face are more diverse, as they also need to design and implement new features and refactor code. Descriptions and requirements might be more vague, with those requesting the changes relying on the intuition and experience of the SWE to implement these changes.
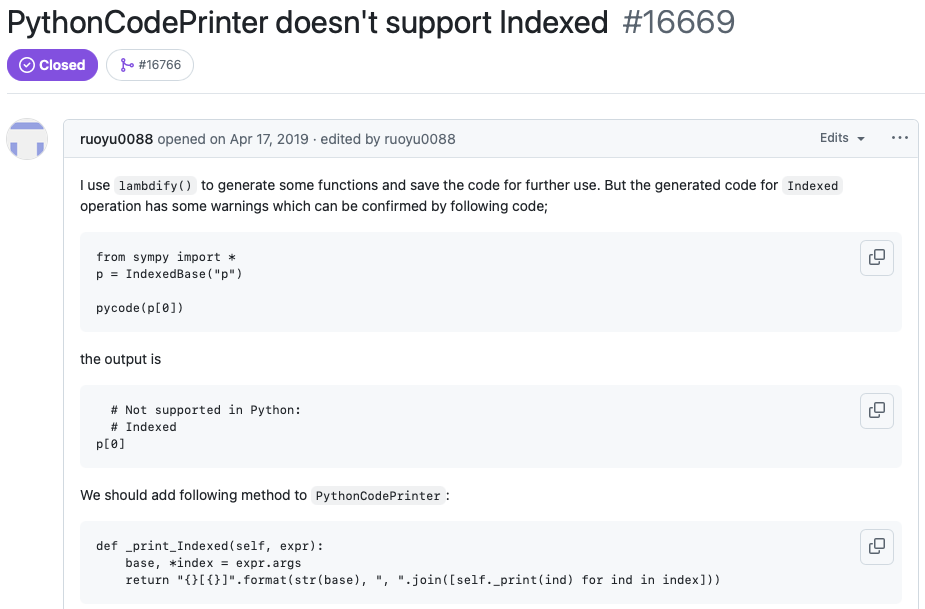
Let’s look at a concrete example that illustrates the simplicity of many issues in the benchmark. This issue from the sympy repository describes a straightforward problem that is easy to understand, even for someone not deeply familiar with the sympy codebase. The human annotators classified this particular task as a “<15 min fix,” and indeed, the corresponding PR affected only five lines of code.
In this particular example, the issue text also suggests a possible solution, though the final patch merged into the repository was slightly different than the suggestion. Suggested fixes are not uncommon: Aleithan et al. also analyzed SWE-Bench and refer to this as “solution leak”, implying that these hints make the benchmark unrealistic and too simple. We disagree with this characterization. Well-specified bug reports with reproducible examples and even suggested fixes are common in open-source projects, and many repositories ask for suggested fixes in their issue templates. Therefore, these “leaked solutions” are features of real bug reports, not flaws in the benchmark design. Still, this factor is worth considering when interpreting results.
The low diversity of codebases limits external validity
SWE-bench Verified sources its issues from highly popular Python projects. Although it aims for diversity, it uses only twelve repositories, limiting how well it represents broader software engineering work.
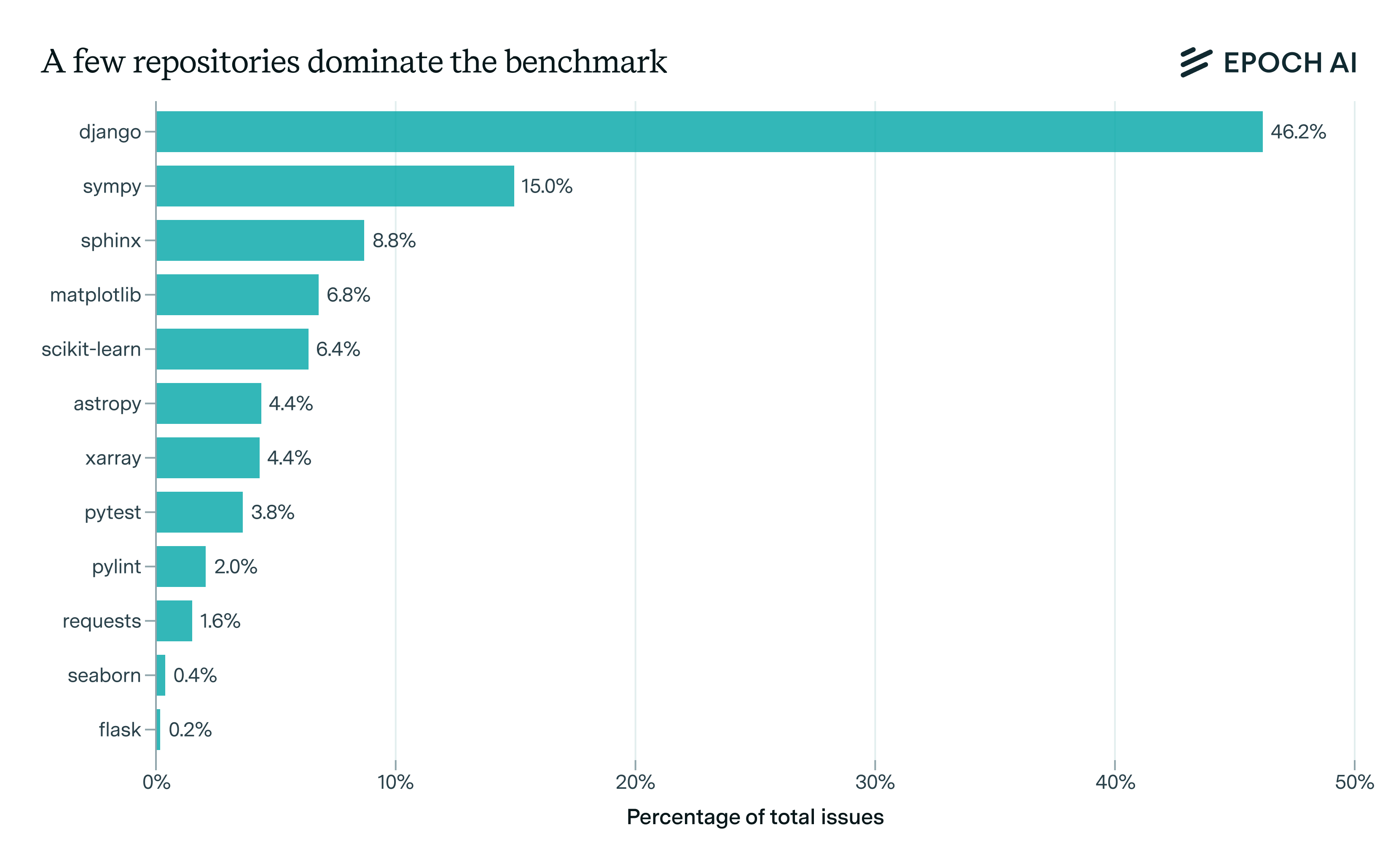
Aside from the low diversity, the distribution of those repositories is heavily skewed. One repository, the web framework Django, comprises nearly half of all issues. The five largest repositories (django, sympy, sphinx, matplotlib, scikit-learn) account for over 80% of the benchmark, whereas the five smallest repositories represent only about 8% of the total.
This heavy concentration means that LLMs have likely encountered these repositories during training, making their architecture, style conventions, and even specific issues familiar to the models.5 Consequently, the benchmark might be easier to solve compared to truly novel, closed-source repositories of similar complexity.
Half the benchmark tests issues from before 2020
SWE-bench Verified is a static benchmark, so the age of its samples raises concerns about its relevance to current software development practices and increases the risk of data contamination.
The underlying SWE-bench dataset, from which Verified is drawn, was created in October 2023. Unlike benchmarks such as LiveCodeBench, the set of issues is not updated over time. Therefore, it is safe to assume that all current and future models have likely been trained on the relevant codebases, their respective changes over time and even the issues themselves, as these public repositories are an important source of training data. Indeed, on Huggingface one can find open datasets containing GitHub issues and PRs, such as The Stack or SWE-Fixer.
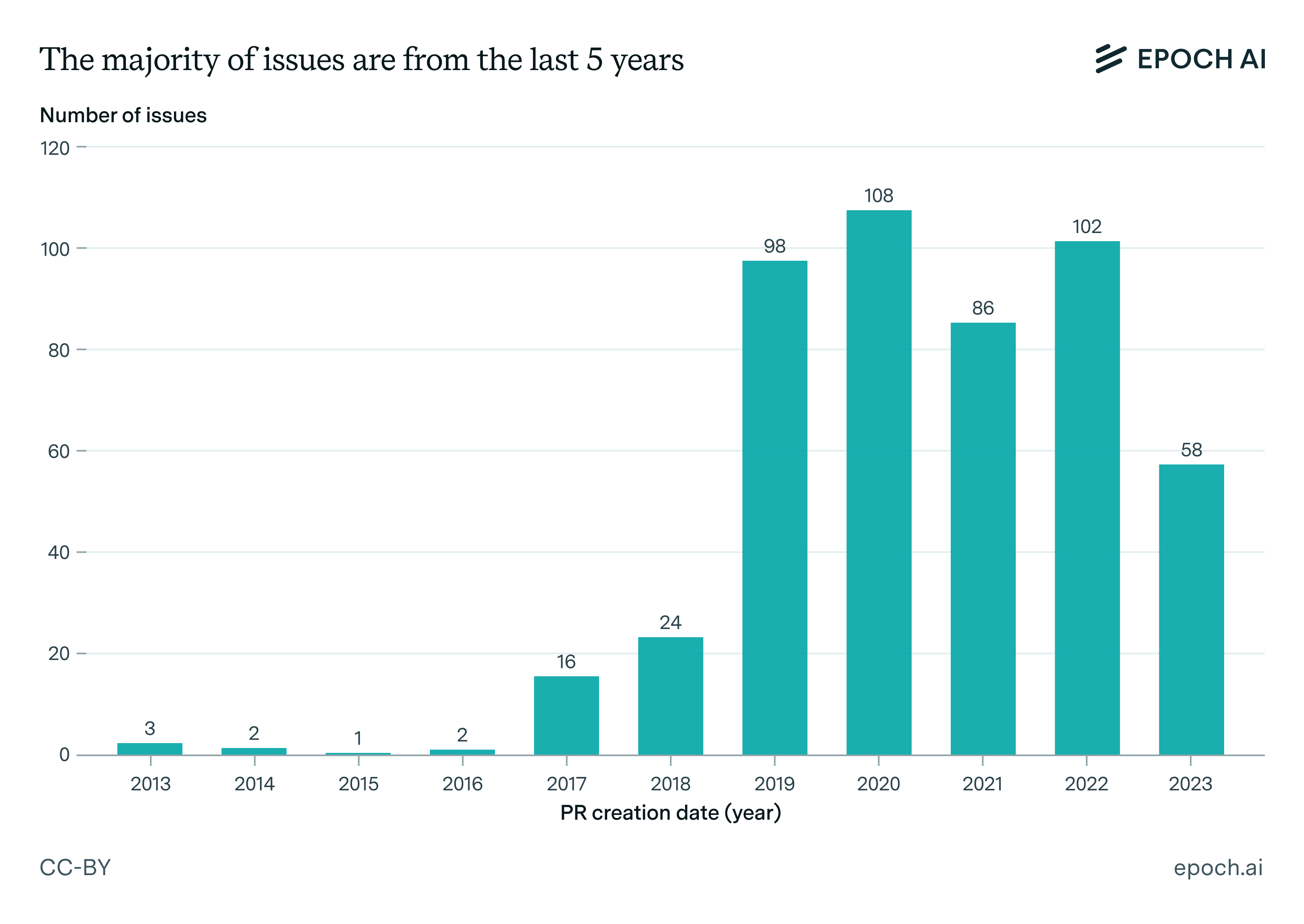
Half of the issues in SWE-bench Verified are from 2020 or earlier, with some dating back as far as 12 years. To put this into perspective, Python 3.9, released in 2020, will be declared End of Life (EOL) in October 2025. Consequently, the benchmark often asks models to work in codebases with Python features that will soon be phased out.
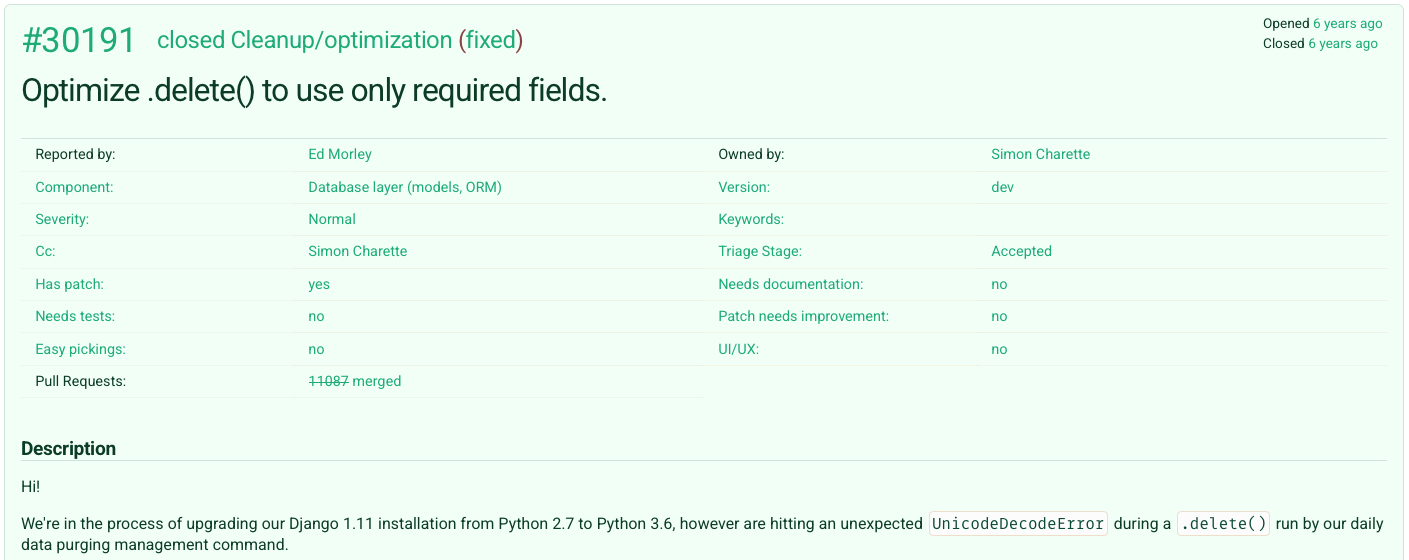
The issue from the screenshot, which can be found here, is about the migrating Django projects between versions when switching from Python 2 to 3 and was created in 2019, a few months before the EOL date. We found a few similar issues and found that the code that fixed those bugs uses Python features that still work today. While dealing with legacy codebases is indeed part of real-world software engineering, with enterprises being slow to update their software and use it beyond EOL, Python users in general are quick to adopt new Python versions, with features such as type hinting becoming increasingly popular. The selection of the issue dates and repos does not capture those “modern” features.
Scaffolds matter as much as models
The repositories in SWE-bench Verified require models to actively manipulate codebases, not just generate code. To accomplish this, models operate within scaffolds: frameworks providing specialized tools, structured prompts, and controlled environments that enable models to edit files and navigate directories. Some scaffolds include advanced inference methods like generating multiple solutions, runtime error checking, and context window management.
For example, the SWE-Agent scaffold works with various models like GPT-4o and Claude Sonnet. It provides a special file viewer showing only 100 lines at once, an edit tool with integrated linter, as well a custom tool to search for strings in a directory. Those tools offer better performance than just using standard shell commands.
A good scaffold can increase performance by up to 20%6: This means that performance on SWE-bench Verified reflects the sophistication of the scaffold as much as the capability of the underlying model. In our runs, which use the Inspect Framework with the tools from SWE-Agent 1.0.1, we found that some models are often unable to call the provided tools, which then results in a failed run for this sample. Creators optimize their models for some scaffolds more than others, leading to non-transferable performance when evaluating with different tooling.
This scaffold dependency has three major implications: first, benchmark scores become difficult to interpret since results with one scaffold often do not transfer to another scaffold. Second, scaffolds optimized specifically for SWE-bench Verified may not generalize to real-world coding tasks. Third, scaffold choice becomes a major factor in evaluation cost: some scaffolds generate multiple solution attempts before selecting the best one, achieving better performance at a higher cost. An important metric to watch is the single-trace pass@1 score, as this more closely reflects the actual user experience in tools like Claude Code.
Conclusion
SWE-bench Verified mainly tests the ability of models (and their associated scaffolds) to navigate a Python codebase and fix well-defined, small issues with clear descriptions. It is a much more realistic test for agentic coding than benchmarks that evaluate models on isolated LeetCode-style problems: the model has to fix issues submitted by real users facing real problems, and models have to successfully use tools to find where to make changes in complex codebases. The extensive and thorough human annotation process, combined with the fact that all issues were merged by codebase maintainers, ensures the high quality of the problems.
However, all the codebases and their respective issues used in SWE-bench Verified are openly available. This means models are likely familiar with these codebases, and there is a high risk of contamination. Therefore, generalizing these findings to software engineering as a whole is challenging, as most SWEs work on closed-source codebases that models will not be familiar with. The low diversity of codebases (with five repositories accounting for >80% of the benchmark samples) and the age of some of these issues are another aspect to be aware of.
Overall, SWE-bench Verified does not capture the full spectrum of software engineering work, focusing instead on a narrow slice: bug fixes in familiar, open-source Python repositories. However, reaching high scores on SWE-bench Verified still means that human engineers can focus on tasks that the benchmark does not capture, such as system design, developing new features, and creative problem solving.
-
For example, this issue suggests using a FutureWarning, which the PR did not use. Another instance is this ticket in the Django repository, which mentions a test patch which the model has no access to.

-
We intentionally were very strict in our assessment to estimate an upper bound. As an example for a strict assessment, we found this issue explicitly mentions negative hours failing, whereas the test suite is more general and also tests for negative minutes. We label this task as an erroneous task.
-
Wang et al. found that some patches generated by models lead to regressions when running the whole test suite (SWE-bench Verified only uses the tests in the file(s) of the test patch). Furthermore, they assess that the test suites from the repositories might not catch all possible bugs, leading to model-generated patches which pass the tests but introduce new bugs. However, introducing new tests which are only passable by the gold patch makes the task harder, if not impossible, for the model to generate a patch which passes all the tests.
-
METR used engineers to fix six issues from SWE-bench Verified, four of them being in the “<15 min fix” bucket, with engineers needing 8, 26, 67 and 84 minutes to fix the issues, and two of them being in the “1 hour - 4 hours” bucket. However, the sample size (1% of the benchmark) is too small to draw strong conclusions. Furthermore, the familiarity of the engineers with the respective repositories is not specified.
-
In SWE-bench Multimodal, the authors found that the model performed better on issues after the cutoff date. However, the sample size is too small and the issues might be easier compared to the rest of the benchmark.
-
Claude 3.7’s performance increases from 62.3% to 70.2% with a custom scaffolding, while the performance from 4o increases from 23% with the “SWE-Agent” scaffold to 33.2% with the “Agentless” scaffold. DeepSeek R1-0528 achieves a performance of 33% with our tooling, while DeepSeek reports 57.6% with the Agentless scaffold.
About the authors


Related work

