Credit to Alex Erben and Ege Erdil for substantial help with research and calculations. In this issue, “we” refers to our collective judgment.
A commonly-cited claim is that powering an individual ChatGPT query requires around 3 watt-hours of electricity, or 10 times as much as a Google search.1 This is often brought up to express concern over AI’s impact on the environment, climate change, or the electric grid.
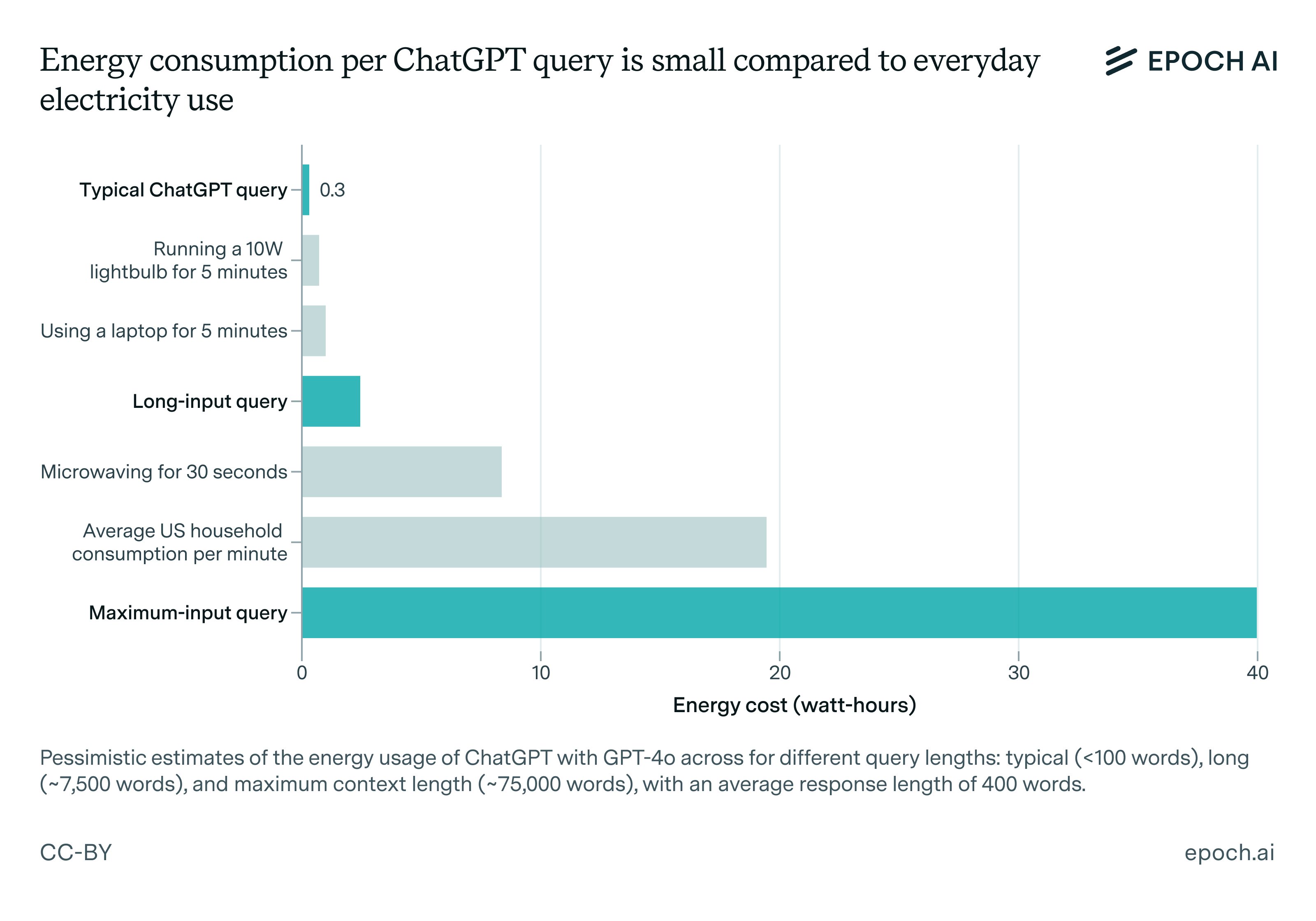
However, we believe that this figure of 3 watt-hours per query is likely an overestimate. In this issue, we revisit this question using a similar methodology, but using up-to-date facts and clearer assumptions. We find that typical ChatGPT queries using GPT-4o likely consume roughly 0.3 watt-hours, which is ten times less than the older estimate. This difference comes from more efficient models and hardware compared to early 2023, and an overly pessimistic estimate of token counts in the original estimate.
For context, 0.3 watt-hours is less than the amount of electricity that an LED lightbulb or a laptop consumes in a few minutes. And even for a heavy chat user, the energy cost of ChatGPT will be a small fraction of the overall electricity consumption of a developed-country resident. The average US household2 uses 10,500 kilowatt-hours of electricity per year, or over 28,000 watt-hours per day.3
This estimate of 0.3 watt-hours is actually relatively pessimistic (i.e. erring towards high energy costs), and it is possible that many or most queries are actually much cheaper still. However, this will vary with use case—queries with long input lengths or with longer outputs (e.g. using reasoning models) may be substantially more energy-intensive than 0.3 watt-hours. And training and inference for future models may consume much more energy than using ChatGPT today.
See this spreadsheet for sources for everyday electricity uses.
Estimating the energy cost of a query
ChatGPT and other chatbots are powered by large language models (LLMs). Running these models (also known as inference) requires compute, and the chips and data centers that process that compute require electricity, roughly in proportion to the amount of compute required.
Below, I’ll walk through a summary of how to estimate the compute and energy cost of a ChatGPT query. You can find a more detailed version with arguments for every assumption in the appendix.
-
ChatGPT actually runs on several different models, but let’s use GPT-4o as a reference model, because this is still OpenAI’s leading general-purpose model. OpenAI’s new reasoning models (o1, o3-mini, and the upcoming o3) likely require more energy, but are probably less popular, at least right now. In particular, OpenAI’s new Deep Research product, which is rate-limited and requires their $200/month subscription tier, is certainly far more compute-intensive than a simple ChatGPT query. Meanwhile, GPT 4o-mini is smaller and cheaper than GPT-4o. We’ll discuss these other models in more detail in a later section.
-
LLMs generate outputs in units called tokens—for OpenAI, a token represents 0.75 words on average. Floating-point operations (FLOP) is a standard unit for measuring compute, and generating a token requires approximately two FLOP for every active parameter in the model. We previously estimated that GPT-4o has roughly 200 billion total parameters (likely between 100 and 400 billion). It is also most likely a mixture-of-experts model, meaning not all of these parameters are activated at once. Pessimistically taking the high estimate of total parameters, and assuming ¼ are activated at a time suggests 100 billion active parameters. This means that 2 * 100 billion = 200 billion FLOP are needed to generate one token.
-
I assume that a typical number of output tokens per query is 500 tokens (~400 words, or roughly a full page of typed text). This is somewhat pessimistic—for example, Chiang et al. found an average response length of 261 tokens in a dataset of chatbot conversations. This is also assuming text-based conversations—it’s unclear how many tokens are needed in conversations with GPT-4o’s advanced voice mode, and we don’t consider the cost of generating images here.
-
This leads to 500 * 2 * 100 billion = 1e14 FLOP for a GPT-4o query with 500 output tokens. There is also an additional cost for queries with lengthy inputs, which I discuss below.
Next, we can find the energy cost of this compute based on the power consumption of the necessary AI chips:
-
I assume that OpenAI uses Nvidia H100 GPUs for ChatGPT inference. These have a power rating of 700 watts, but H100 clusters can consume up to ~1500 W per GPU due to the overhead costs of servers and data centers.4
-
H100s can perform up to 989 trillion (9.89e14) FLOP per second. At that rate, it takes 1e14 / 9.89e14 ~= 0.1 seconds of H100-time to process a query (though in reality, many queries are processed in parallel in batches, so end-to-end generation time is much longer than this).
-
However, GPUs can’t actually achieve their max FLOP/second output in practice. I use 10% as a rough estimate of typical utilization rates for inference clusters. This increases the number of GPUs needed to process queries by 10x, so roughly one second of H100-time is required to process a ChatGPT query.
-
On the flip side, average power consumption per GPU will be less than 1500 W in practice. One estimate from the literature suggests that inference GPUs may consume around 70% of peak power on average.5
Putting this together: one second of H100-time per query, 1500 watts per H100, and a 70% factor for power utilization gets us 1050 watt-seconds of energy, which is around 0.3 watt-hours per query. This is around 10 times lower than the widely cited 3 watt-hour estimate!
One last factor to account for is the cost of processing input tokens. This is negligible for simple questions that are manually typed, but when the inputs are very long, processing inputs becomes significant relative to the cost of generating outputs. Some chatbot use cases involve uploading large documents, codebases, or other forms of data, and GPT-4o supports an input window of up to 128,000 tokens.
In the appendix, we estimate that a long input of 10k tokens (similar to a short paper or long magazine article) would substantially increase the cost per query to around 2.5 watt-hours, and a very long input length of 100k tokens (equal to roughly 200 pages of text) would require almost 40 watt-hours of energy. Note that this input processing is an upfront cost, so if you have an extended chat exchange after uploading a long document, this cost is not incurred with each message. Additionally, it is almost certainly possible to dramatically improve how the cost of processing inputs scales with very long inputs, but we’re not sure if OpenAI has done this yet.6
Why is our estimate different from others?
The original three watt-hour estimate, which has been widely cited by many different researchers and media outlets, comes from Alex de Vries (2023).
The most important reason our estimate differs is that we use a more realistic assumption for the number of output tokens in typical chatbot usage. We also base our estimate on a newer and more efficient chip (NVIDIA H100 vs A100), and a model with somewhat fewer active parameters.
In the original estimate, De Vries cites a February 2023 estimate from SemiAnalysis of the compute cost of inference for ChatGPT. This calculation assumed 175B parameters for GPT-3.5 (vs our assumed active parameter count of 100B for GPT-4o), running on A100 HGX servers (less efficient than the more modern H100), and most importantly, assumed 4000 input tokens and 2000 output tokens per query. This is equivalent to 1500 words, which is likely quite unrepresentative of typical queries (for context, it is about half as long as this newsletter issue, besides the appendix). De Vries then converts this compute cost to energy using the A100 server’s max power capacity of 800 W per GPU, while we assume servers consume 70% of peak power.
In addition, Luccioni et. al. measured a ~4 Wh energy consumption per query for BLOOM-176B, a model comparable in size to GPT-4o. However, this was for a model deployed for research purposes in 2022: their cluster handled a relatively low volume of requests, likely with low utilization, and didn’t use batching, a basic inference optimization that is standard in any commercial deployment of LLMs (see the appendix for more details on this paper).
What about other models besides GPT-4o?
While GPT-4o serves as our reference model, there are numerous other models available both within ChatGPT and in chatbot products from other companies. OpenAI offers GPT-4o-mini, which, based on its API pricing at under one-tenth the cost of GPT-4o, likely has a significantly smaller parameter count7 and therefore energy cost. In contrast, OpenAI’s o1 and o3 reasoning models may consume substantially more energy to operate.
o1’s parameter count (and cost per-token) is unclear, but its compute and energy costs per query are most likely higher due to the lengthy chain-of-thought that it generates. This cost is even higher with the $200/month o1 pro, which uses the same o1 model but scales up inference compute even further.
The newly-released o3-mini deserves special attention here, because it is powerful while also being fast enough that it could significantly displace GPT-4o in usage in the coming months, especially if it receives new product features like image/file upload and voice mode. o3-mini also has an undisclosed parameter count, though it is advertised as a “small” model and its per-token cost on the API is only 44% as much as GPT-4o’s. So there is a good chance that o3-mini has a lower per-token energy cost than GPT-4o, but this could easily be outweighed by long reasoning chains.
I informally tested o3-mini and o1 using OpenAI’s API8, and found that they both generate around 2.5x as many tokens as GPT-4o. This was based on a small sample of my own chats and a more rigorous analysis would be useful here.9 Overall, it is currently unclear if o3-mini queries consume more or less energy than GPT-4o queries, but o1 queries most likely require more energy.
Today, the “o”-series models are almost certainly much less popular than 4o and 4o-mini, which are available for free,10 are faster, and have more features (e.g. o1 and o3-mini do not have PDF upload or voice mode as of writing). Also, o1’s superior reasoning abilities are unnecessary for most of today’s chatbot use cases, like answering simple questions or drafting emails. It is possible that a shift to reasoning models significantly drives up energy costs for the average chatbot user, but if that happens, that probably means that AI usage has shifted towards much more difficult or complex problems compared to how they are used today. OpenAI’s new, o3-powered Deep Research product is an early sign of this.
Beyond OpenAI and ChatGPT, other major chatbot products include Meta’s AI assistant (likely powered by Llama 3.2 11B or 90B since Meta’s product is multimodal), Anthropic’s Claude (powered by Claude 3.5 Sonnet, which we estimate has 400B parameters), and Google’s Gemini (powered by Gemini “Flash” and “Pro” models, with undisclosed parameter counts). We don’t have full details on all of these models, but they are probably all roughly comparable to either GPT-4o or 4o-mini in energy costs. Finally, DeepSeek-V3, which we wrote about recently, and its R1 reasoning variant, offers strong performance with just 37B active parameters (out of 671B total parameters), so there is a good chance that it is less energy-intensive per token than GPT-4o.
Moving forward, it’s unclear how energy costs for AI chatbots will evolve—it could easily go up or down over time, and this could diverge dramatically by use case. Holding capabilities constant, language models will become more energy-efficient over time due to both hardware and algorithmic improvements. The AI and tech industry have been developing more efficient hardware, continually improving the capabilities of smaller models, and inventing inference optimizations like multi-token prediction, all of which drive energy costs down.11 However, if consumers shift to increasingly powerful chatbots and assistants that do increasingly complex tasks, this may eat these efficiency gains through larger models or models that generate increasingly large numbers of reasoning tokens.12
Training and other upstream costs
Another thing to consider is the upstream energy costs in producing ChatGPT and other LLM products, in addition to the cost of using them.
The most obvious one is the energy required to train the models. The training runs for current generation models that are comparable to GPT-4o13 consumed around 20-25 megawatts of power each, lasting around three months. This is enough to power around 20,000 American homes. Since ChatGPT has 300 million users, the energy spent on GPT-4o’s training run is not very significant on a per-user basis. The same article also mentions that ChatGPT users send 1 billion messages per day: using our 0.3 Wh estimate, this suggests that overall ChatGPT inference requires ~12.5 MW of power. This is comparable to the power (temporarily) required to train GPT-4o, but language models are typically used for longer than they are trained (GPT-4o has been available for nine months).
One might also wonder about the upstream energy costs of constructing the GPUs and other hardware, also known as “embodied” energy, in addition to the direct energy cost of running them. A full accounting here would be difficult, but these embodied energy costs are likely much smaller than the direct energy costs.
Luccioni et. al. looked at the embodied carbon emissions of the servers and GPUs used to train BLOOM, a 176 billion parameter LLM, estimating that the embodied emissions (amortized over the length of the training run) were ~11.2 tonnes of CO2. This is less than half of the 24.7 tonnes of CO2 emitted by training the model.14 However, the ratio of embodied energy to training energy is even lower, because those training emissions came from clean French electricity, which is around 5 to 10 times less carbon-intensive than the electricity in most countries.15 So the embodied energy cost was likely a small fraction of the direct energy cost.
Another data point is that TSMC, which manufactures a large majority of the world’s AI chips, consumed a total of 24 billion kWh in 2023, which is equivalent to an average power consumption of 2.7 gigawatts. This is in the same ballpark as the power consumption of the GPUs that TSMC produced last year (very roughly, 1 kW per GPU over several million GPUs produced per year). However, GPUs last for multiple years, so the total stock of GPUs probably consumes more than TSMC’s fabs put together. Additionally, much of the 2.7 GW consumed by TSMC actually goes to producing non-AI chips. Overall, his means that it probably takes much less energy to manufacture AI chips than it takes to run them.
Rigorously measuring all these upstream costs would be difficult, but given the available information, they are probably comparable to or less than the direct cost of inference compute for ChatGPT. And in the case of training, this cost is an upfront cost that doesn’t affect the marginal energy cost of using ChatGPT, since AI models don’t wear out after they are trained.
Discussion
With reasonable and somewhat pessimistic assumptions, a GPT-4o query consumes around 0.3 watt-hours for a typical text-based question, though this increases substantially to 2.5 to 40 watt-hours for queries with very long inputs. As shown in the charts below, this is somewhere between a negligible to a small portion of everyday electricity usage.
There is a lot of uncertainty here around both parameter count, utilization, and other factors—you can find more estimates with a wider range of assumptions in this spreadsheet, as well as sources for the other everyday uses of electricity. I’ve tried to err on the side of pessimism (higher energy costs) with every assumption, but different assumptions about parameter counts, utilization, and token output can bring the cost into the 1 to 4 watt-hour range, or down to around 0.1 watt-hours. And again, maxing out GPT-4o’s context window could bring the energy cost into the tens of watt-hours, though this input scaling can be improved with better algorithms.
More transparency from OpenAI and other major AI companies would help produce a better estimate. Ideally we could use empirical data from the actual data centers that run ChatGPT and other popular AI products. This may be difficult for AI companies to reveal due to trade secrets, but it seems to me that public confusion on this topic (including many exaggerated impressions of the energy cost of using AI today) is also not in AI developers’ interests.
Taking a broader view, by some estimates AI could reach fairly eye-popping levels of energy usage by 203016, on the order of 10% of US electricity.17 For this reason, I don’t dismiss concerns about AI’s overall impact on the environment and energy, especially in the longer run. However, it’s still an important fact that the current, marginal cost of using a typical LLM-powered chatbot is fairly low by the standards of other ordinary uses of electricity.
Appendix
1. Compute cost
To find the compute cost of inference for an LLM, we have to consider the size of the model and the tokens generated. LLMs generate text in units called tokens (for OpenAI, 1 token represents 0.75 words on average). Generating a token requires two floating-point operations (FLOP) for every parameter in the model (plus some compute required to process inputs, which we’ll discuss below). Note that we are ignoring advanced techniques like speculative decoding or multi-token prediction that could reduce this token generation, because we don’t know whether or not OpenAI uses them.
How many parameters do ChatGPT models have? As of writing, ChatGPT users can choose between several different models, including GPT-4o, GPT-4o mini, o1, and o1-mini, and o3-mini.
GPT-4o is the full-featured model for paid subscribers, and GPT-4o-mini is a cheaper and less powerful variant (free users have limited access to GPT-4o and more access to 4o-mini). Meanwhile, o1 and o3 are OpenAI’s new “reasoning” models, which likely require much more compute and energy, but they are also probably much less popular among typical users.
I’ll use GPT-4o as a reference for typical ChatGPT use, though GPT-4o mini might be more popular while requiring much less compute.18 Unfortunately, we don’t know the exact parameter count for GPT-4o or the other models, but we previously estimated that it has 200 billion total parameters, which could be off by roughly a factor of two.
It’s also likely that GPT-4o is a mixture-of-experts (MoE) model, meaning not all of these parameters are activated at once. This is likely because MoE seems to be the standard approach for frontier models due to its compute efficiency: for example, GPT-4 is reportedly an MoE model, Gemini 1.5 Pro is an MoE, and nearly all DeepSeek models including V3 and R1 are MoE.
The ratio of total parameters to active parameters in MoE models can range from roughly 3.6 to 1 for Mistral’s Mixtral 8x7B and 8x22B, to almost 20 to 1 for DeepSeek-V3, which has 37B parameters against 671B total. So we’ll use a 4 to 1 ratio and assume that GPT-4o has 100B active parameters against 400B total parameters. If GPT-4o turned out to be dense, this would also be consistent with the lower end of our estimate for GPT-4o’s total parameters.19 Overall, this is more pessimistic than our best guess for GPT-4o’s active parameters, though there is substantial uncertainty here.
Next, we need to multiply this by the number of tokens that ChatGPT generates per query. This can vary widely by use case, but Chiang et al. found an average response length of 269 tokens in a large dataset of LLM chats. We’ll pessimistically bump this up to 500 tokens, which is equivalent to ~400 words or about half a page of typed single-space text. If your ChatGPT usage tends to produce much longer or shorter responses than this, you can adjust our final estimate in proportion to understand your own footprint.
Putting this together, we get 500 * 2 * 100 billion = 1e14 FLOP for a query with 500 output tokens.
2. Energy cost of compute
Next, we need to find the energy cost of producing this much compute.
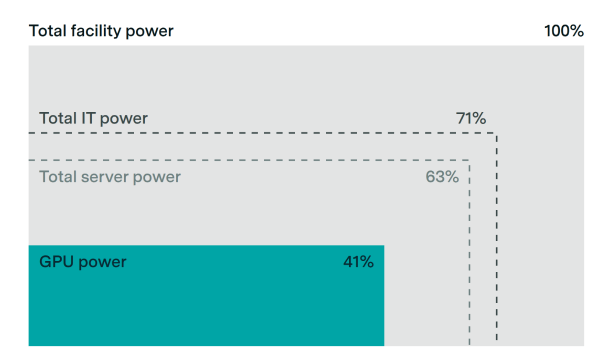
The leading AI chip for companies other than Google is NVIDIA’s H100 GPU, so I’ll assume ChatGPT inference uses H100s. OpenAI may still use some older and less efficient A100s20, but they will also transition to more efficient Blackwell chips sooner or later. The H100 has a power rating21 of 700 watts, but H100 clusters can consume up to ~1500 W per GPU due to the overhead costs of servers and data centers. For example, a DGX server with 8 H100s, a common server configuration for H100s, has a max power usage of 10.2 kW (1275 W per GPU), and there is an additional 10-20% overhead at the data center level.
H100s can produce up to 989 trillion (9.89e14) FLOP per second. This assumes 16-bit FLOP without sparsity, though many inference providers for open models use 8-bit inference, and H100s can produce twice as many 8-bit FLOP as 16-bit FLOP. Note that NVIDIA’s spec sheet for the H100 reports sparse FLOP/s, so we divide all those number by 2.
If the H100s running ChatGPT achieve this peak output, then the 1e14 FLOP required to answer a query would take 2e14 / 9.89e14 = 0.1 seconds of H100-time (in reality, servers process many parallel requests in batches, so generation takes much longer than that end-to-end).
Multiplying 0.1 seconds by 1500 watts yields an energy cost of 150 watt-seconds, or ~0.041 watt hours, which is much lower than the common-cited estimate of 3 watt hours. However, this is too optimistic, because GPUs don’t produce 100% of max output in practice. We need to adjust for compute utilization, which is actual compute output divided by the theoretical maximum. Lower utilization increases how many GPUs are required to process queries, which increases energy costs.
How much utilization is achieved during LLM inference? It’s hard to know for sure, but 10% is a reasonable, though rough assumption. We know that utilization is lower for inference than it is when training AI models (often 30-50%), due to memory bandwidth bottlenecks in inference.22
Another line of evidence is the price per token for open-weight models. Open models have known parameter counts, and hosting APIs for open models is a competitive business (since anyone can download an open model and offer an API for it), so API provider margins are likely low, and their prices are evidence of the true cost of serving the models.
This makes it possible to estimate utilization based on token prices, assuming a 0% profit margin:
- Llama 3.1 405B has 405 billion parameters, so 2 * 405B = 810B (8e11) FLOP are needed per token, and 8e17 FLOP per one million tokens.
- An H100 can perform 2000 teraFLOP/s at peak output (in FP8 FLOP, which is standard for open model providers), or 7.2e18 FLOP per hour. H100s cost around $2 per hour to rent, so at 100% utilization, API providers could achieve 3.6e18 FLOP per dollar.
- This means that if their GPUs ran at 100% utilization, the compute cost of generating a million Llama 3.1 405B tokens would be around 8e17 / 3.6e18 dollars, which is 22 cents.
- In fact, according to prices compiled by Artificial Analysis, Llama 3.1 405B costs $3.50 per million output tokens on average, which is more than 10 times more expensive.
The cost of renting GPUs is almost certainly the biggest cost of running these APIs, so this suggests that providers need about 10x as many GPUs compared to if they achieved 100% utilization. This means that utilization is roughly 10%, increasing the GPUs required, and hence our energy estimate, by 10x.
One final consideration is that a GPU cluster’s average power consumption will be lower than peak consumption, especially given the low compute utilization during inference. We can’t know the actual power consumption of OpenAI’s servers absent specific, real-world data, but there is some literature on measuring inference power consumption for other models.
Patel et. al., a team of Microsoft Azure23 researchers, did experiments on inference power consumption for several LLMs and found that GPU power consumption is typically around 60-80% of thermal design power, spiking up to 100% when processing input tokens during prefill (Figure 6). Luccioni et. al. also measured inference power consumption, finding that mean power consumption was only about 25% of TDP. However, their setup was very different from ChatGPT’s; for example, they only handled 558 requests per hour, which were processed without batching. By contrast, Patel et. al. sent a “steady stream” of inference requests intended to maximize power utilization, so their result of ~70% may be more representative of large-scale deployments, if somewhat pessimistic. Using this figure means we are pessimistically ignoring the possibility of GPUs being idled on occasion due to fluctuations in user demand, which is a plausible consequence of 10% FLOP throughput, and would reduce power consumption further.
A compute utilization of 10% and a power utilization of 70% would increase our earlier native energy estimate by 7x (first divide by 10%, i.e. multiply by 10x, and then multiply by 70%). Applying this to the earlier result, we get 0.041 * 7 ~= 0.3 watt-hours for a GPT-4o query with 500 output tokens. This is almost 10 times lower than the widely-cited 3 Wh estimate!
3. Energy cost of input tokens
Processing long inputs can be expensive for language models. Transformer models have an attention mechanism describing the relationships between all of the tokens in the input. In the prefill phase, the model processes the input and computes the values of two matrices used in attention (known as the key and value matrices, or K and V), which are then stored in a KV cache.
This cost of processing attention scales proportionally to the product of the model dimension, the model depth, and the square of the input length. Given an assumed parameter count for GPT-4o, we can find reasonable estimates for the model depth and the dimension of each layer that would produce this parameter count, which allows us to estimate the FLOP cost of attention calculations for any given input length. There is also an added cost of generating tokens given a long input, but this cost is relatively minor for very long inputs.
Because prefill cost scales quadratically with input length for large inputs, this methodology leads to high compute and energy costs for long inputs. For an input of 10k tokens and an output of 500 tokens, the total cost increases to around 2.4 watt-hours, and 100k input tokens and 500 output tokens would cost around 40 watt-hours of energy. Note that because of the KV cache, this is an upfront cost, and a multi-turn chat conversation that begins with a very long input such as an uploaded document will not incur this cost multiple times.
You can find the full calculation in this Colab notebook.
Importantly, quadratic scaling would also imply very high compute and energy costs for inputs of 1 million tokens or more—processing 1M input tokens would be around 100 times more costly in total than processing 100k tokens. However, Google DeepMind has been offering 1 to 2 million token context windows starting with Gemini 1.5, and this was almost certainly enabled by innovations that improve on quadratic scaling. Additionally, more efficient attention mechanisms have been proposed in the literature. So we know it is possible to improve how input costs scale with input length, but we don’t know which innovations, if any, OpenAI in particular has adopted.
-
The comparison with Google searches comes from a very old estimate from Google in 2009 that each search consumes 0.3 Wh. Estimating Google search’s energy cost today is outside the scope of this post. It could easily be lower today due to increased chip and data center efficiency, or higher if Google searches have become more complex over time (and/or because Google search now has AI features like AI Overviews).

-
Household usage is lower than total usage, since the energy used to e.g. manufacture the goods you own are not incurred inside your house.
-
You can read this essay from Andy Masley for more useful context on how much energy this is, as well as discussion on AI’s water usage.
-
A DGX server with 8 H100s, a common server configuration for H100s, has a max power usage of 10.2 kW (1275 W per GPU). And there is an additional 10-20% overhead at the data center level.
-
This pessimistically assumes a constant stream of inference requests, ignoring the possibility of GPUs idling due to demand fluctuations.
-
Google DeepMind has almost certainly improved on input scaling, in order to enable 2 million token input windows for its Gemini models, though we’re not sure whether OpenAI has adopted these sorts of innovations yet.
-
Parameter count is not necessarily proportional to API prices, since OpenAI could charge different profit margins for different models, and it is possible to serve models more cheaply by reducing token generation speed (GPT-4o-mini is relatively slow for a “mini” model).
-
This was necessary because the full reasoning chain is hidden from users, but the API tells you how many tokens were generated.
-
I asked GPT-4o, o1, and o3-mini five questions from my chat history and found an average response length of 1374 tokens for o3 and 1392 tokens for o1, versus 540 tokens for GPT-4o. (I used reasoning effort=medium, which is the default in ChatGPT, though I didn’t use ChatGPT’s system prompt). So o1 and o3-mini both generated just over 2.5x as many tokens. Meanwhile DeepSeek-R1 returned an average of 1794 tokens for these questions. This is just a rough sanity check that reasoning models can generate much more tokens, and should not be taken as a representative average.
-
o3-mini is also available for free, likely with serious rate limits.
-
See our earlier issue on LLM model sizes for more discussion on this point.
-
Some possible signs of the growing popularity of reasoning models are DeepSeek R1, which is DeepSeek’s new reasoning model, reaching the top of Apple’s app store, and the fact that o3-mini is available to free users.
-
We don’t know how many GPUs were used to train GPT-4o but we do know this for models we believe to be of comparable scale, such as Llama 3.1 and the original GPT-4.
-
This is training, not inference, but because they divide the total embodied emissions over the computer equipment’s lifetime by the length of the training run, the conclusion isn’t dramatically different compared if you compare embodied emissions amortized over the very short time period where a cluster serves an inference query, versus the energy cost of that query.
-
Most of France’s electricity comes from nuclear power. Luccioni et. al. assume a carbon intensity of 57 grams CO2 per kWh for BLOOM training, which is around 5-10x cleaner than the electricity in most other countries, and the embodied emissions presumably mostly came from outside France.
-
This is from a starting point of around 0.3% today: Goldman Sachs estimated that AI data centers would consume about 11 terawatt-hours of electricity in 2024, which is about 0.3% of the US’s total consumption of 4 trillion kWh (calculation here).
-
These are both roughly consistent with our projection of electricity supply constraints for AI.
-
GPT-4o mini is substantially smaller, given that it is over 10x cheaper on OpenAI’s API. But I don’t know whether 4o-mini is actually more typical than 4o because the message limits for free users are opaque.
-
These two claims (whether or not GPT-4o is an MoE and its total number of parameters) are not completely independent, since we know GPT-4o was a highly capable model by mid-2024 standards, and this is harder to accomplish as the active parameter count goes down.
-
NVIDIA sales have grown dramatically since the H100 was introduced in late 2022, so the H100 is likely much more common.
-
Officially called “thermal design power”, which is roughly equal to the GPU’s peak power draw.
-
See this blog post from Databricks for more discussion.
-
Microsoft is OpenAI’s main compute provider, though this paper did not test OpenAI models, much less a commercial deployment for ChatGPT.
About the authors
Related work