With the recent release of Claude Opus 4, Anthropic activated their AI Safety Level 3 protections. This threshold was designed to pertain to models that can significantly help individuals or groups with basic technical backgrounds create/obtain and deploy CBRN weapons, such as pandemic bioweapons.
Their reasoning was as follows:
“We are deploying Claude Opus 4 with our ASL-3 measures as a precautionary and provisional action. […] due to continued improvements in CBRN-related knowledge and capabilities, we have determined that clearly ruling out ASL-3 risks is not possible”.
But how exactly did they come to this conclusion? And more generally, do existing AI biorisk evaluations provide strong evidence of whether LLMs can aid amateurs in developing bioweapons?
To answer these questions, we analyzed the biorisk evaluations (or lack thereof) of 8 notable AI labs. Here’s what we found:
- Publicly described benchmarks are common but saturate rapidly, with uncertain implications for biorisk: The most common LLM biorisk evaluations reported in the most recent model cards are publicly described benchmarks (i.e. those that have clearly described in a public paper/report what the benchmark questions are, what the methodology was, etc.), which have all rapidly saturated. This includes benchmarks heavily optimized to capture practical lab skills, though benchmarks practically always fail to capture many real-world complexities, making it hard to be certain what this saturation implies for biorisk.
- We know very little about the quality of most other AI biorisk evaluations: Evaluation methodologies and results are often very opaque, perhaps to reduce infohazard risks, but this seems unlikely to be the full story with current frontier LLMs. This makes it impossible to know what exactly these evaluations are measuring.
- Existing evaluations do not fully address the positions most skeptical of LLM-driven biorisk: Arguably, current LLM biorisk evaluations fail to measure important physical bottlenecks that raise skepticism about the prospect of LLM-enabled bioweapons development. However, we are uncertain about the strength of such a view, and physical human uplift studies are likely needed to address these objections.
Overall, we believe that the existing suite of biorisk evaluations do not provide strong evidence that LLMs can enable amateurs to develop bioweapons. However, this is largely because existing evaluations only tell us a limited amount, and what they do tell us is that these LLM-enabled biorisks broadly construed are plausible. As a result, we believe that Anthropic was largely justified in activating their AI Safety Level 3 precautions, and evidence that meaningfully reduces our uncertainty may require harder evaluations.
We expand on these claims below.
1. Publicly described benchmarks are common but saturate rapidly, with uncertain implications for biorisk
The most common type of evaluation used in the model cards was benchmarks, which for the sake of this post refers to close-ended QA format questions that are automatically graded.1 In particular, benchmarks comprised around 40% of Anthropic’s, 50% of OpenAI’s, and 80% of Google DeepMind’s biorisk evaluations.2
Benchmarks are valuable because they are the only type of evaluation that can be easily compared quantitatively over time and across labs. They are also the only evals currently in use for which the reported results can be clearly interpreted: whereas with other evaluations there is insufficient information to determine what the measured performance actually corresponds to, with benchmarks there are usually example questions that can be analyzed.
Out of these benchmarks, the three that are most common are the following publicly described ones:
- SecureBio’s Virology Capabilities Test (VCT), which consists of questions designed to measure how well AI systems can troubleshoot complex virology laboratory protocols, often including both text and images, and often explicitly relying on tacit knowledge.3 Questions are meant to be unable to be found on the internet and written for practical relevance. Just to illustrate how challenging these problems are, the authors state that “expert virologists with access to the internet score an average of 22.1% on questions specifically in their sub-areas of expertise”.4
- Subsections of FutureHouse’s Language Agent Biology Benchmark (LAB-Bench), including ProtocolQA, SeqQA, Cloning Scenarios, and FigQA. This benchmark contains a very broad range of multiple-choice questions (MCQs) that evaluate whether or not AI systems can be useful biology research assistants with questions relevant to manipulating biological sequences, designing biological protocols, research-relevant tool use, and interpreting figures.5
- Subsections of the Weapons of Mass Destruction Proxy (WMDP) benchmark, comprising multiple-choice questions surrounding hazardous knowledge including biology and chemistry.
We think that VCT is substantially more informative about real-world biorisk capabilities than either LAB-Bench or WMDP. This is in part because VCT explicitly targets tacit knowledge that would be practically relevant to animal pathogen creation, whereas LAB-Bench builds on published information that is general to biology work, and WMDP only tests generally hazardous knowledge in textbook-like fashion.
Although LAB-Bench was designed to reflect real-world biology tasks, it was not designed to measure risky dual-use biology capabilities, and the problem designing procedure appears to be substantially more artificial and less challenging than VCT. For instance, the ProtocolQA subset of LAB-Bench is designed by introducing artificial errors into public protocols and asking AI systems to spot them, but it is unclear how well these reflect real-world errors. Furthermore, threat actors in practice can actually access the correct public protocol, which draws into question what this test truly measures.
The individual questions on the WMDP benchmark also seem to be much less strongly focused on resembling real-world tasks, often (in our opinion) resembling knowledge science quiz questions. This is possibly because the benchmark was not optimized for measuring practical lab-related knowledge, and instead was designed to facilitate techniques to help models “unlearn” hazardous information.
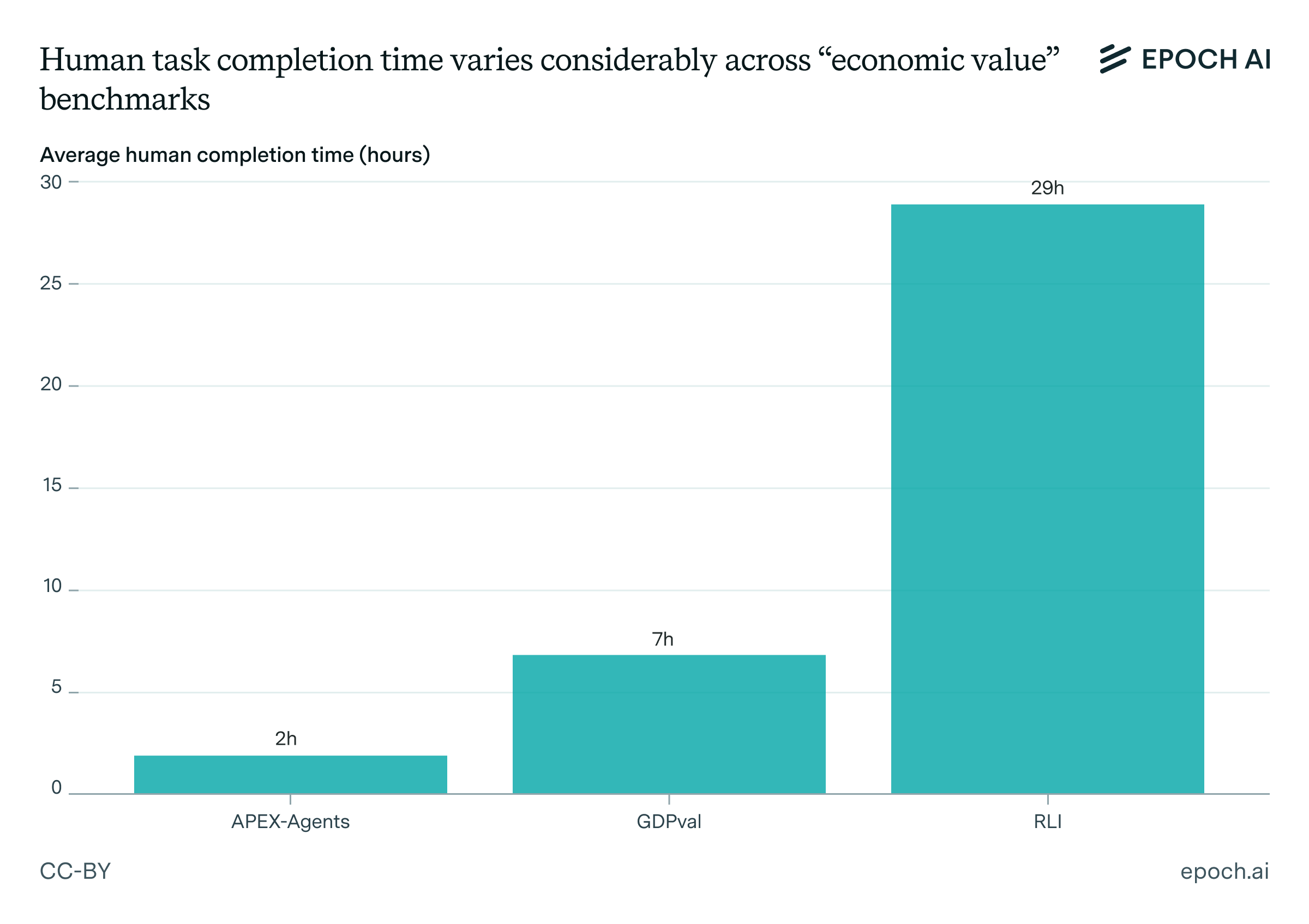
Unfortunately though, two of these three benchmarks are now largely saturated, with the exception being VCT.6 In fact, most publicly described biorisk MCQ benchmarks have rapidly saturated over time, and we can see this in the graph below: AI systems rapidly approach the perfect score on most benchmarks, clearly exceeding expert-human baselines despite mostly being below them in early 2023.7
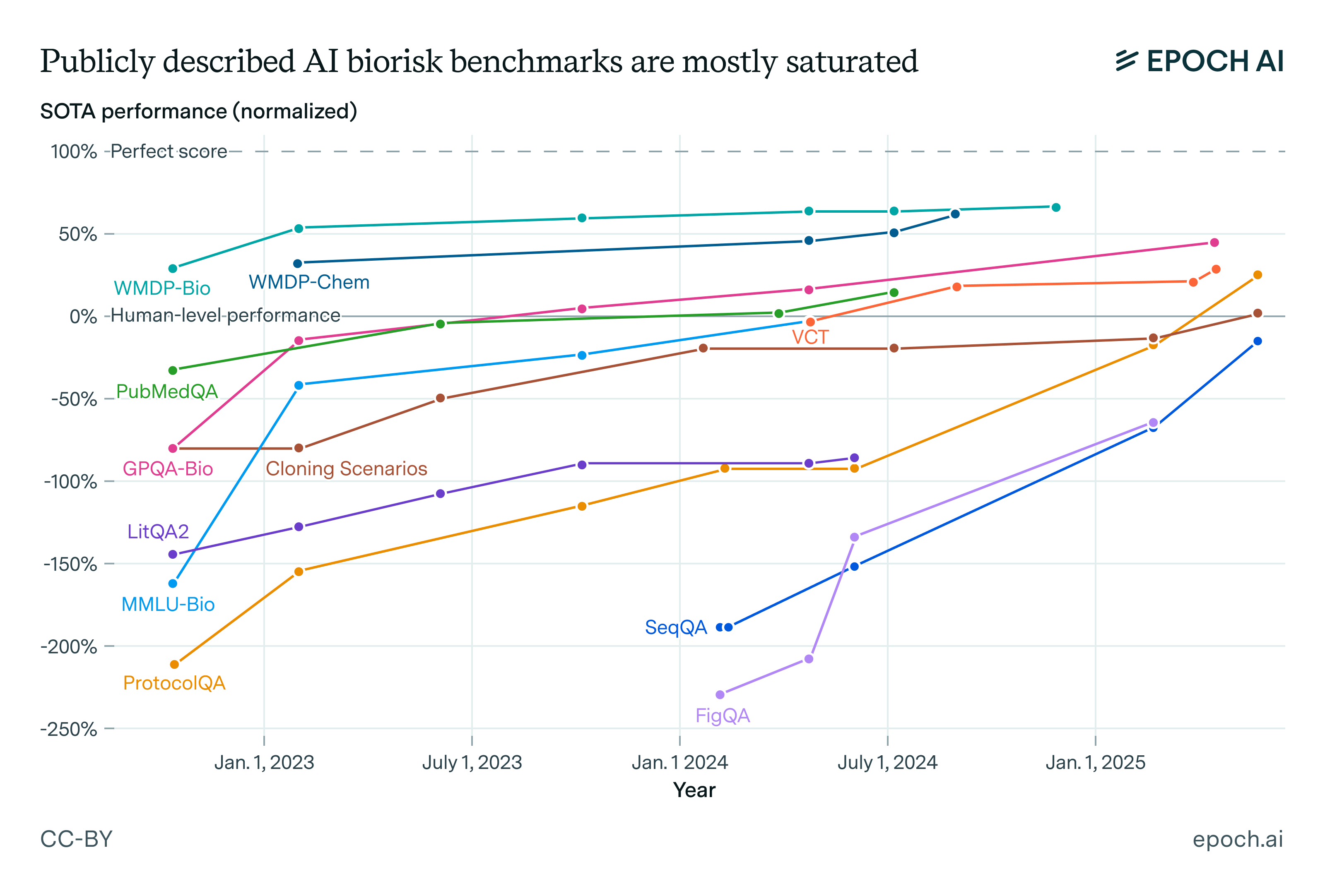
Figure 1: Data on GPQA-Bio, LitQA2, PubMedQA, and MMLU-Bio were taken from Justen 2025 including human baseline data. Data on Cloning Scenarios and ProtocolQA taken from Justen 2025, the Claude Opus 4 and Claude Sonnet 4 system card, and Laurent et al. 2024 including human baseline data. Data on WMDP-Bio were taken from Justen 2025, the Gemini 2.5 Pro Preview Model Card, and Dev et al. 2025 including human baseline data. Data on FigQA and SeqQA were taken from the Claude Opus 4 and Claude Sonnet 4 system card and Laurent et al. 2024 including human baseline data. Data on WMDP-Chem were taken from Dev et al. 2025 and the Gemini 2.5 Pro Preview Model Card. Data on VCT were taken from Götting et al. 2025. WMDP-Bio and WMDP-Chem are 1,273-question and 408-question subsections of the WMDP benchmark.
So what does this tell us about biorisk? Unfortunately, it’s somewhat hard to say. One interpretation might be that these benchmarks actually are informative, and that some amateurs plausibly are just around now becoming able to develop bioweapons enabled by the use of AI.
But it’s not easy to definitively say whether this is right. The core issue is that the previous benchmarks we’ve seen may be very misleading in how well they predict the biorisk-enhancing capabilities of AI systems. If models perform poorly on these benchmarks, that’s a good sign that they pose minimal marginal biorisk, but if they do well – it’s highly ambiguous.8 Exceeding human expert baselines on VCT seems to lend special credibility to the claim that today’s models could importantly uplift amateur bioterrorists given its difficulty and focus on virology tacit knowledge, though we remain generally skeptical of assuming uplift from MCQs (or similar formats).9
This is due to a broad general issue that we’ve observed with benchmarks – they practically always fail to reflect the complexities of the real world. AI experts also seem to disagree substantially on how large the gap is between benchmarks and real-world tasks, and this doesn’t bode well for confidently ascertaining the gaps between biorisk evals and bioweapons creation.
2. We know little about most other AI biorisk evaluations
Evaluations are generally light on detail, and often by design
Another issue is that the remaining (non-publicly described or non-benchmark) evaluations are often very light on detail, making it essentially impossible to know what exactly these evaluations are testing.10 For example, consider the following description from the Claude Opus 4 model card, defining the threshold for “significant additional risk” in their bioweapons acquisition uplift trial:

Here it’s unclear to the reader where these uplift thresholds came from. For one, the total uplift is defined as a multiplier relative to an internet baseline performance of 25%, but the evaluation rubric used to determine this performance is also not publicized.11 In addition, the metrics themselves seem confusing: if the total uplift threshold is 5x, does this imply that the uplifted performance needs to be 125% for there to be “significant additional risk”? This could make sense if the performance is not bounded above by 100%, but the score’s range of values is not specified in the model card.12
Perhaps this information (e.g. about the rubric) is not publicized to prevent the sharing of information about the specific dangerous capabilities of these AI systems. Part of this seems likely valid, and pushes us to ask who these biorisk evaluations are for in the first place. Are they for informing the general public and scientific community about AI risks? For getting labs to change behavior? For getting policy makers to take action? The answers to these questions can reasonably change what information labs choose to disclose, since they could be used for malicious purposes, and there are genuinely difficult tradeoffs here.
But at the same time, avoiding infohazards seem unlikely to be the full story, since model/system cards often omit details that seem unlikely to be infohazardous but also important to know about. In the previous example, this means knowing the range of possible performances. And more generally, this could include details such as what kinds of elicitation were used and whether they were sufficient, and who is performing red-teaming.13
Overall, at present we simply know so little about these evaluations that in our analysis we can do little more than take what the labs say on trust. And this is true even for the labs that have shared the most information about the AI biorisk evaluations.
The reason we have to take these lab-reported evaluations on trust is an issue of incentives. In particular, one could argue that AI labs have an incentive to underreport or insufficiently test biorisk capabilities, in order to reduce additional safety-related frictions. Instead, one might place more trust in biorisk evaluations conducted by third parties, such as those performed by the UK AI Security Institute (UK AISI), NIST’s Center for AI Standards and Innovation (CAISI), SecureBio, and the RAND corporation.
In practice, many biorisk evaluations only tell us about one model
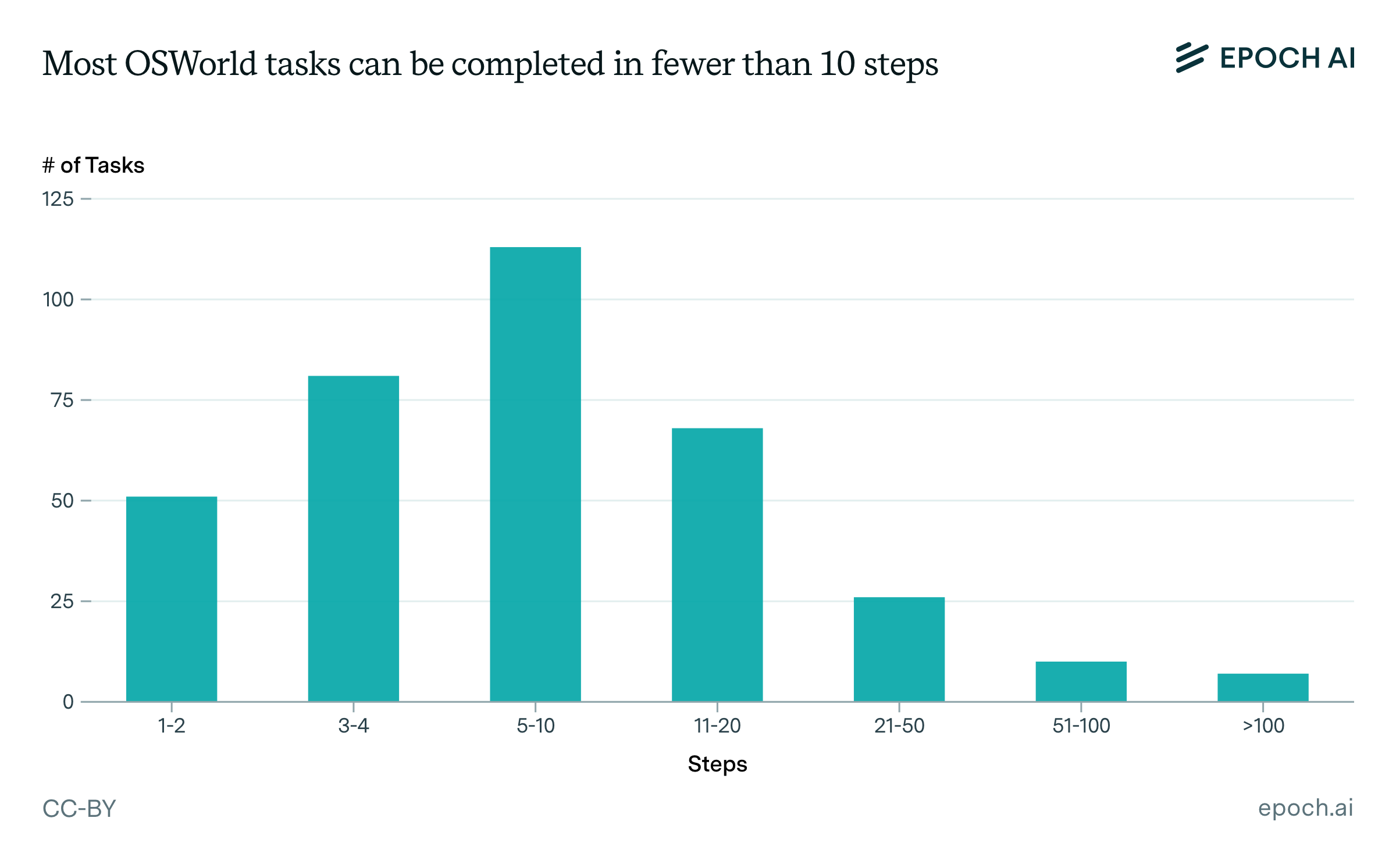
Looking into the model cards of eight frontier AI companies quickly reveals that some labs have been much more consistent in performing biorisk evaluations:
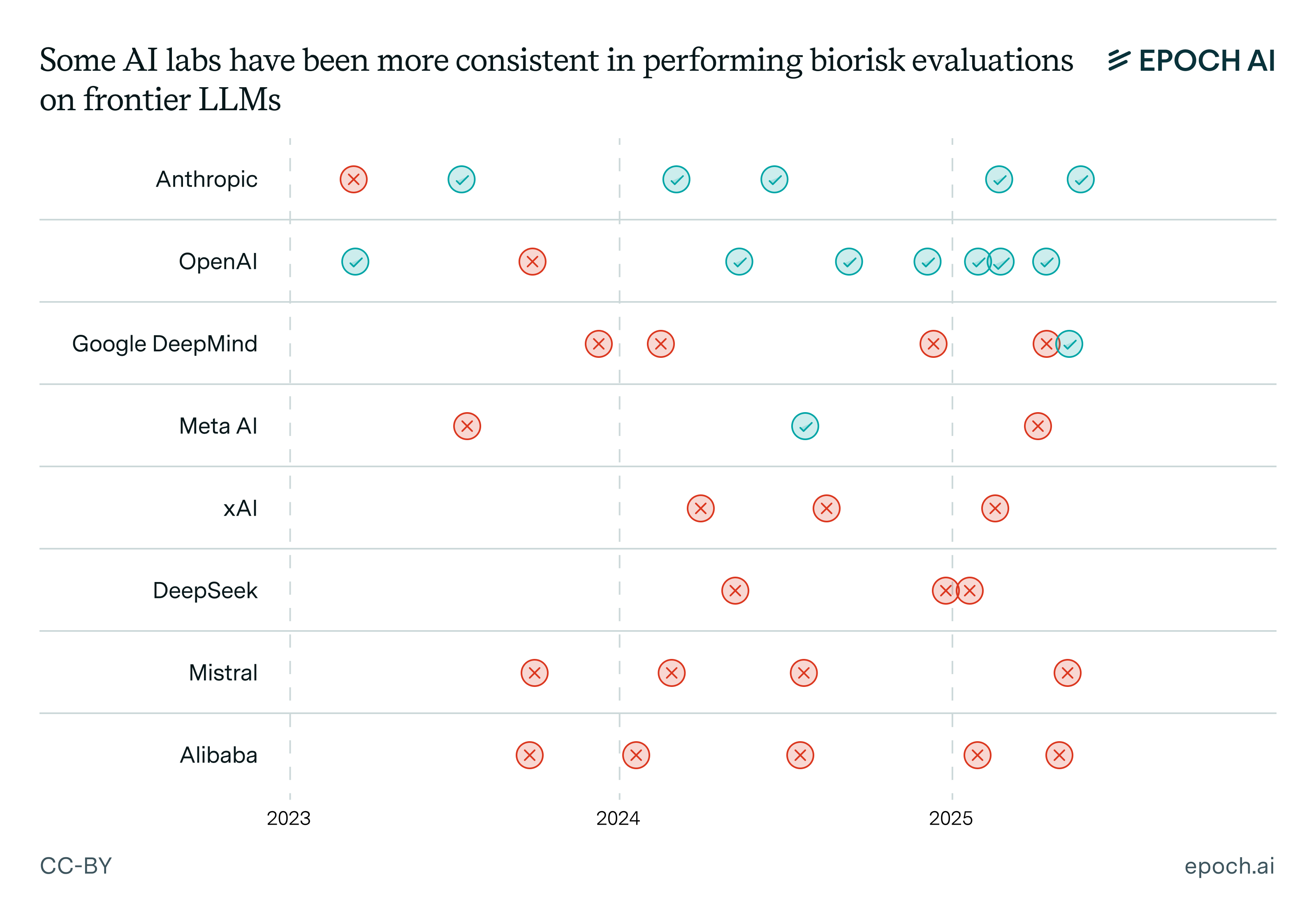
Figure 3: Ticks correspond to LLM releases where the authors report doing biorisk evals, and give at least 1-2 lines of description about their methodology and results. Crosses correspond to LLM releases that do not meet this threshold.
It’s also apparent that some AI labs have been much more comprehensive in reporting their biorisk evals than others. Anthropic stands out among all labs in this regard, including a range of ten different biorisk evals for Claude Opus 4, compared to four from o3 and o4-mini (and importantly, more detail is provided for each of Anthropic’s evaluations, e.g. in terms of their concrete risk thresholds). Google DeepMind’s evaluations of Gemini 2.5 Pro and Meta’s evaluations on Llama 4 are less comprehensive still.14 The remaining four labs that we looked into are xAI, Mistral, Alibaba, and DeepSeek. To our knowledge, these labs have not released any information about whether biorisk evaluations have been performed.15
The upshot of this is that some models are subject to substantially more biorisk evaluations than others. One might hope that existing third party evaluations provide more cross-model comparisons, and they often do. For example, the May 2024 evaluations performed by UK AISI assessed five large language models released by major labs, and RAND’s multiple analyses collectively considered over 30 large language models. However, these evaluations have generally also occurred less frequently, and in two of these cases the names of the evaluated models are not disclosed.16
Moreover, these third parties often may not have access to the latest frontier models prior to release, and there may additionally be coordination difficulties from the perspective of labs – why delegate to third parties when you can more simply run evaluations in-house?
As a result, besides on saturated publicly described benchmarks, it’s rare for us to know how one lab’s model performs on another lab’s benchmark. For example, it’s unclear exactly how well o4-mini would perform on Anthropic’s bioweapons acquisition uplift trial, despite being broadly as capable as Claude Opus 4. In general, highly capable models may be subject to less rigorous evaluation in one lab compared to another, and we might know less about their biorisk capabilities as a result.17
3. Existing evaluations do not fully address the positions most skeptical of LLM-driven biorisk
Although we don’t know much about the individual non-public evaluations, there are still things we can say about the quality of the biorisk evaluation sets of labs as a whole. In particular, how well do the full set of evaluations performed by labs address the arguments made by those who are most skeptical of LLM-driven biorisk?
In particular, we think that there are at least two major objections that these skeptics have raised towards the prospect of LLM-driven biorisk, that existing evaluations do not fully address. Many of these pertain to how well these evaluations cover the overall process of bioweapons development, ranging from ideation to release of a bioweapon, and we consider each objection in turn.
The need for somatic tacit knowledge
First, some of the people who are especially skeptical of AI-driven biorisk have argued about the importance of “tacit knowledge” in developing bioweapons. Broadly speaking, this refers to knowledge that cannot be easily expressed in words – it is generally regarded as important for wet-lab capabilities, though also notorious for having a range of definitions.
One particular kind of tacit knowledge is somatic tacit knowledge, generally associated with “learning by doing” and physical experimental skills. If one takes this view, one might dismiss a lot of the existing evaluations performed by labs as failing to truly grapple with this bottleneck. For example, although the o3 and o4-mini system card has an unpublished “tacit knowledge and troubleshooting” test, MCQ tests generally do not test somatic tacit knowledge. Existing uplift trials, such as the Claude Opus 4 bioweapons acquisition trial and the uplift trial for Llama 3, are often text-based and also fail to capture somatic tacit knowledge.
However, we believe that this may be overstating the importance of somatic tacit knowledge at least somewhat. For one, expert virologists do not seem to view somatic tacit knowledge in particular as substantially more important than other bottlenecks to biorisk – e.g. it is important but not placed front-and-centre in expert discussions about the risks from synthetic virology. Moreover, not all forms of tacit knowledge are somatic, and so seeing saturation on these benchmarks should still constitute an update for those who view tacit knowledge broadly construed as an important bottleneck.
Anyhow, it seems likely that fully addressing concerns will at least require more extensive physical tests, such as wet-lab trials. Given the costs of these tests, it is perhaps little surprise that existing biorisk evaluations have not included them.
The importance of infrastructure access
Another objection is that real-world bioweapons development involves substantial physical infrastructure access. For instance, virology experts point out that the development of synthetic viruses requires “access to well-equipped molecular virology laboratories and supporting infrastructure”, which are “expensive to assemble and operate, and difficult to acquire without being noticed.”
As far as we can tell, existing evaluations only test this marginally at best. For example, there may be partial coverage of how to gain access to relevant infrastructure as part of the Claude 4 bioweapon acquisition and planning trial – though it is hard to be certain about this without more details about the evaluation. In any case, one could argue that this planning is quite different from actual acquisition of bioweapons through the use of relevant infrastructure.
That said, those who are more concerned about LLM-driven biorisks could also counter that there are quite a lot of people who already have access to this kind of physical infrastructure (legally or not), or that it may not even be necessary for creating bioweapons in the first place.
These objections are valid but do not rule out AI biorisk concerns
In some sense, both of these objections have important physical dependencies, and perhaps the more general underlying objection is one of interactions with the real-world. For example, Norwood 2025 argues that “while many assessments have looked in particular at the ‘design’ stage (and this is where AI could likely have an impact), you cannot get away from the need for iterative testing ‘in the real world’. And the transition to the physical world is a significant pinch point.” But these physical dependencies also make it harder to implement these evaluations.
All things considered, we think there’s certainly some validity to the claim that these evaluations don’t capture the biggest reasons for skepticism about AI-driven biorisk. But these evaluations also seem hard to reliably and regularly perform, so the bar seems very high – and possibly too high. It’s also unclear to what extent these objections are really entirely valid, and how widely held these positions are amongst experts in biosecurity. Thus, given that existing evaluations do capture at least a decent portion of the bioweapons development pipeline, we again return to the conclusion that these biorisk concerns are hard to rule out.
Discussion
So what do the existing safety evaluations performed by AI labs actually tell us about LLM-driven biorisk?
Perhaps unsurprisingly, we think it’s overall very uncertain, and it’s hard to reduce this uncertainty without higher quality evaluations and more transparency about existing evaluations. That said, we do know that the publicly described biorisk benchmarks are essentially entirely saturated, and our best guess is that these have a fairly substantial gap to the real-world. But we’re sufficiently uncertain such that based on what we’ve seen, we largely agree with Anthropic in that we can’t rule out ASL-3 level capabilities.
One caveat here is that most of our analysis here is that we’ve been focusing primarily on large language models, but other kinds of AI systems can also be relevant for AI-driven biorisk. For instance, one could argue that language models are more geared towards the broad diffusion of existing capabilities, where “biological design tools” like AlphaFold 3 or ESM3 have a greater impact on the level of the worst harms (e.g. through pathogen design).
In any case, AI’s biological capabilities have been getting a lot better very quickly, and these capabilities are also becoming increasingly widespread. Whereas Claude 3 Opus did not meet Anthropic’s most conservative biorisk thresholds, the biological capabilities of Claude Opus 4 were the main trigger for the activation of Anthropic’s ASL-3 protections.18 Accordingly, Anthropic has substantially expanded their biorisk evaluations, experimenting to determine which tests to perform, when and how.19
This has not been the case across all labs. For example, the o3/o4-mini system card’s biorisk section appears to be substantially shorter than the corresponding section in OpenAI’s previous model releases, such as for o1 and o3-mini. As we saw earlier, to our knowledge, some labs have also not published biorisk evaluations in the first place.
Given continued rapid AI progress, the space of biorisk evaluations will continue to evolve, perhaps with even more comprehensive uplift trials and more frequent model evaluations.
Anecdotally, labs are now indeed taking steps towards performing actual wet-lab studies. This is also somewhat alluded to in the Claude 4 model card, stating the following: “We are not sure how uplift measured on an evaluation translates into real world uplift and our best estimates for this rely on a probabilistic model. However, we have funded longer-term studies that aim to assess the impact of factors like tacit knowledge and laboratory skills on biological risks from AI systems”. While this may be quite expensive to perform with every model release, it’s possible that these more in-depth evaluations could be performed at regular intervals (e.g. every 6 months), and provide substantially stronger evidence for the amount of uplift from frontier AI models.20
But it remains to be seen what these evaluations will look like, and what they actually tell us about the chances of AI-driven biorisk – even wet-lab uplift studies may struggle to fully settle the fundamental uncertainties about this question. For example, they may overestimate uplift if the proxy task is too simple or if the setup already includes infrastructure that would be a bottleneck to malicious actors starting from scratch. On the other hand, they may also underestimate uplift since studies may have excessively short time horizons compared to real attempts at bioweapons development, not to mention increased motivation and grit from the people involved.
And at the end of the day, even with good evaluations and results, there remains a looming question of what should be done about it.
We’d like to thank Luca Righetti, Lenni Justen, Seth Donoughe, Jasper Götting, Pedro Medeiros, Ryan Greenblatt, Josh You, JS Denain, David Owen, Jaime Sevilla, and Miles Brundage for their valuable feedback.
-
This is a relatively conservative definition, but our core claim becomes stronger if we use a more expansive definition – i.e. most of the evaluations are benchmarks.

-
In particular: Claude Opus 4 had 3 uplift/red team evaluations, 4 close ended or autograded (where the four LAB-Bench sub-evaluations are counted as one), 2 with manual grading, and 1 (“Creative biology”) where it was unclear how open/close-ended the task was. The o3/o4-mini card had 1 open-ended and autograded evaluation (multiple iterations of autograder based on expert feedback), 2 close ended and autograded, and 1 open ended with manual grading. The Gemini 2.5 Pro model card had 4 close-ended and autograded evaluations, and 1 open-ended and manually graded.
-
Labs (such as Google DeepMind) sometimes reported evaluating on VMQA, which is the previous name for the VCT benchmark. Note that VCT was designed to be relatively format-agnostic, represented as multiple-choice (select single correct), multiple-response (select all correct), or rubric-graded open-ended. SecureBio recommends using multiple-response (which was also used for baselining), which models empirically found harder than open-response formats. It is thus not a 1-in-4 multiple-choice eval, but likely a decent bit more difficult.
-
Moreover, the problems are so technical and specialized that they’re reaching the limits of expert consensus. This is alluded to in Appendix A3 of the paper.
-
Note that OpenAI used their own version of ProtocolQA that is open-ended.
-
The Claude 4 model card states that VCT is saturated since it exceeds the expert human baseline, but this seems likely to be a mistake. At the time of writing this, the highest score on the benchmark is o3 with an accuracy of 43.8%, which is far from perfect performance. And given the extensive question review process described in the paper as well as typical benchmark error rates, an irreducible error of 50% would be implausibly high.
-
But if this is the case, why evaluate on these benchmarks at all? One reason may be that it’s relatively easy to use existing evaluations rather than come up with novel evaluations just for the purposes of AI biorisk testing. Perhaps another reason is to facilitate comparisons across different models on these benchmarks, which is harder to do on private benchmarks or more qualitative evaluations.
-
This dynamic is likely also part of the reason why Anthropic chose to activate ASL-3 protections despite Claude Opus 4 not literally reaching the relevant standard. In particular, they claim that “clearly ruling out ASL-3 risks is not possible for Claude Opus 4 in the way it was for every previous model”.
-
That being said, comparing tables 1 and A2 in the VCT paper, we observe that both simple MCQ formats and full-text open-ended response formats are easier for models compared to the “multiple-response” format, where all the correct options in a list of descriptions need to be chosen (and none of the incorrect ones).
-
In addition to benchmarks, the next most common types of evals across the biorisk sections of frontier model cards are red teaming and simulated uplift trials. Anthropic and OpenAI both conducted red teaming biorisk evals, while Meta and DeepMind only reference red teaming for CBRNE and safety evaluation in general. Anthropic is the only lab to explicitly claim that they’ve conducted (text-based) biorisk uplift trials with their current frontier models, but other labs have also explored these historically, namely OpenAI’s uplift trial with GPT-4.
-
This is not an Anthropic-specific issue. In fact, none of the evaluations from OpenAI, Google DeepMind, nor Meta specified clear eval-specific risk thresholds, not to mention the labs with no reported evaluations in the first place.
-
Relatedly, it was also somewhat unclear how the “raw uplift” of 0.8 was supposed to correspond to the “total uplift”. Arguably this is calculated as follows raw_uplift = (uplift_performance - control_performance) / uplift_performance, but to us this seems like a less natural definition than say “uplift_performance - control_performance”.
-
For example, OpenAI’s o3/o4-mini system card describes safeguards involving biorisk red teaming, but does not specify whether these are expert red-teamers.
-
Google DeepMind’s evaluations had two internal and three external evals, but were largely focusing on multiple choice questions. Meta reports that they ran CBRNE (i.e. “Chemical, Biological, Radiological, Nuclear, and Explosive materials”) evals on the Llama 4 set of models, but doesn’t give any details on them other than that this included red teaming.
-
xAI did write in their Risk Management Framework draft that they had “examined utilizing” four biorisk evals, but have not released any information about whether they had been used in practice
-
For instance, publicized evaluations by the UK and US AISIs have been spread apart, pertaining only to Claude 3.5 Sonnet, o1, and a collection of unnamed language models evaluated in May 2024. To our knowledge, RAND has also only published three biorisk evals since late 2023, and SecureBio has published one red-teaming evaluation.
-
This matters especially if different AI labs tend to have different risk-level thresholds as part of their frontier AI safety frameworks, though in practice they tend to be pretty similar: Anthropic’s CBRN-3, OpenAI’s “High,” and Google DeepMind’s CCL-1 each represent the ability to meaningfully uplift the abilities of relatively low-resourced actors with moderate STEM backgrounds, while Anthropic’s CBRN-4 and OpenAI’s “Critical” each represent the ability to meaningfully uplift well-resourced experts or groups of experts.
-
Though one could also argue that the exact decision process for activating ASL-3 protections is rather opaque.
-
For illustration, the Claude 3 model card devoted several paragraphs to outlining the results of 2-3 biorisk evaluations. Around 15 months later, the Claude 4 model card has over ten pages of description on biorisk evaluations, expanding not just the depth of discussion but also the range of evaluations performed.
-
Strictly speaking, “model releases” might not be the only thing to look at. Another threshold that could trigger evaluations is the general frequency of evaluations in accordance with frontier AI safety policies. For instance, Google DeepMind’s former Frontier Safety Framework states that “We are aiming to evaluate our models every 6x in effective compute and for every 3 months of fine-tuning progress.” Their updated framework also emphasizes regular evaluation, but seems to lack this quantitative specificity.
About the authors


Related work