
AI is one of those fields where the best winds up much better off than the rest. Superstar researchers at frontier labs earn over ten times more than most of their colleagues, who earn measly million-dollar salaries. They might even earn over a hundred times more than your average AI postdoc:
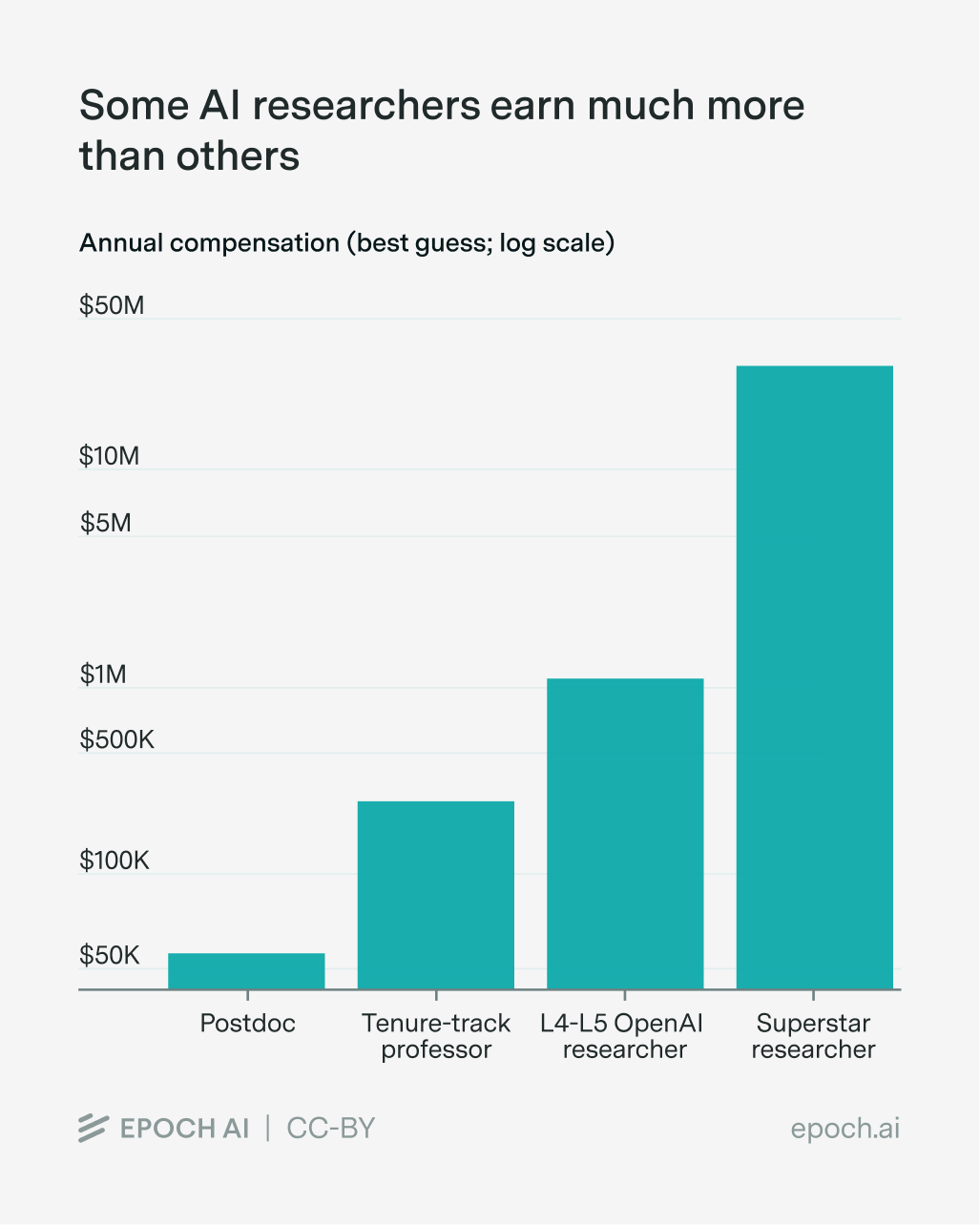
Ballpark estimates of AI researcher compensation. Postdoc compensation is estimated using NSF report data. For tenure-track professors, I anchor on this Taulbee 2024 survey of computer scientists. Compensation for frontier lab researchers is estimated from Levels.fyi for L4-L5 OpenAI researchers, and news reports for superstars.
So why are the differences in pay so large? The naive explanation is that some researchers are just vastly superior. Perhaps the superstar researchers have excellent research taste in designing algorithms and experiments. Or they have a knack for pulling off “yolo runs” — training runs that implement many ambitious changes all at once, relying on deep intuition, whereas most people would need to systematically test the individual changes to make sure they work. Under this framing, superstars are the “10× researchers” that Silicon Valley so deeply reveres, and it’s their quality that makes the difference in pay.1
The problem with this explanation is that it’s very incomplete. In reality, we should expect to see big differences in pay even if superstars were only a tiny bit better than your average postdoc. But why?
The superstar effect
The short answer is this: there’s a well-known economic dynamic which turns small differences in ability into big differences in pay. Here are two illustrative examples:
- In the 100-meter sprint, the gold-medallist gets much more reward and attention than the silver-medallist, despite them being quite literally neck-and-neck for most of the race. Consider the London 2012 Olympics where Usain Bolt won gold. Most people have no idea who won silver, despite finishing just 0.12 seconds behind — do you?
- Some musicians earn much more than others. Consider Taylor Swift: last year, she earned $60-70 million from Spotify. I don’t doubt that she’s a “10× singer” compared to me. But it’s very debatable whether she’s that much better than other extremely popular singers like Ed Sheeran, Blackpink, Charli XCX, and Lana Del Rey, who instead earned closer to $5-25 million.
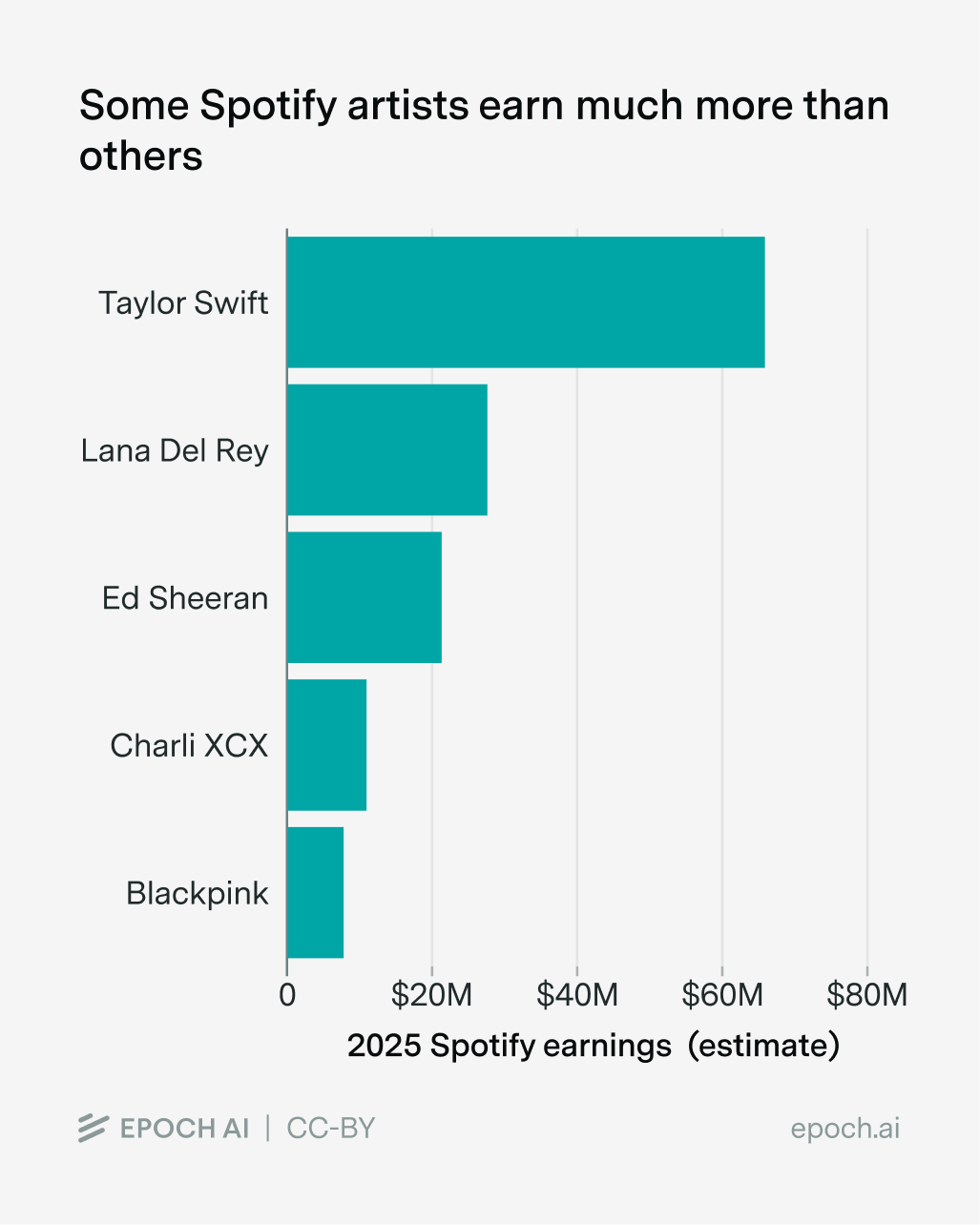
Ballpark estimates of 2025 Spotify earnings of several extremely famous artists. These were estimated by multiplying daily Spotify streams by 365 days, and earnings of $0.004 per stream.
Across these two cases, small differences in ability led to big differences in pay some way or another. Economist Sherwin Rosen called this the “superstar effect,” and it kicks in when two conditions hold.
- One person’s work can reach a big market. Usually this means a market with many people, but a few high-paying people or firms work too. For instance, potentially billions of people watched Usain Bolt win the 100-meter sprint. The more people you can reach, the more pronounced the superstar effects. Across the economy, jobs with broad reach — such as actors, musicians — show far bigger wage dispersion than jobs serving one client at a time, such as plumbers, nurses, and truck drivers:2
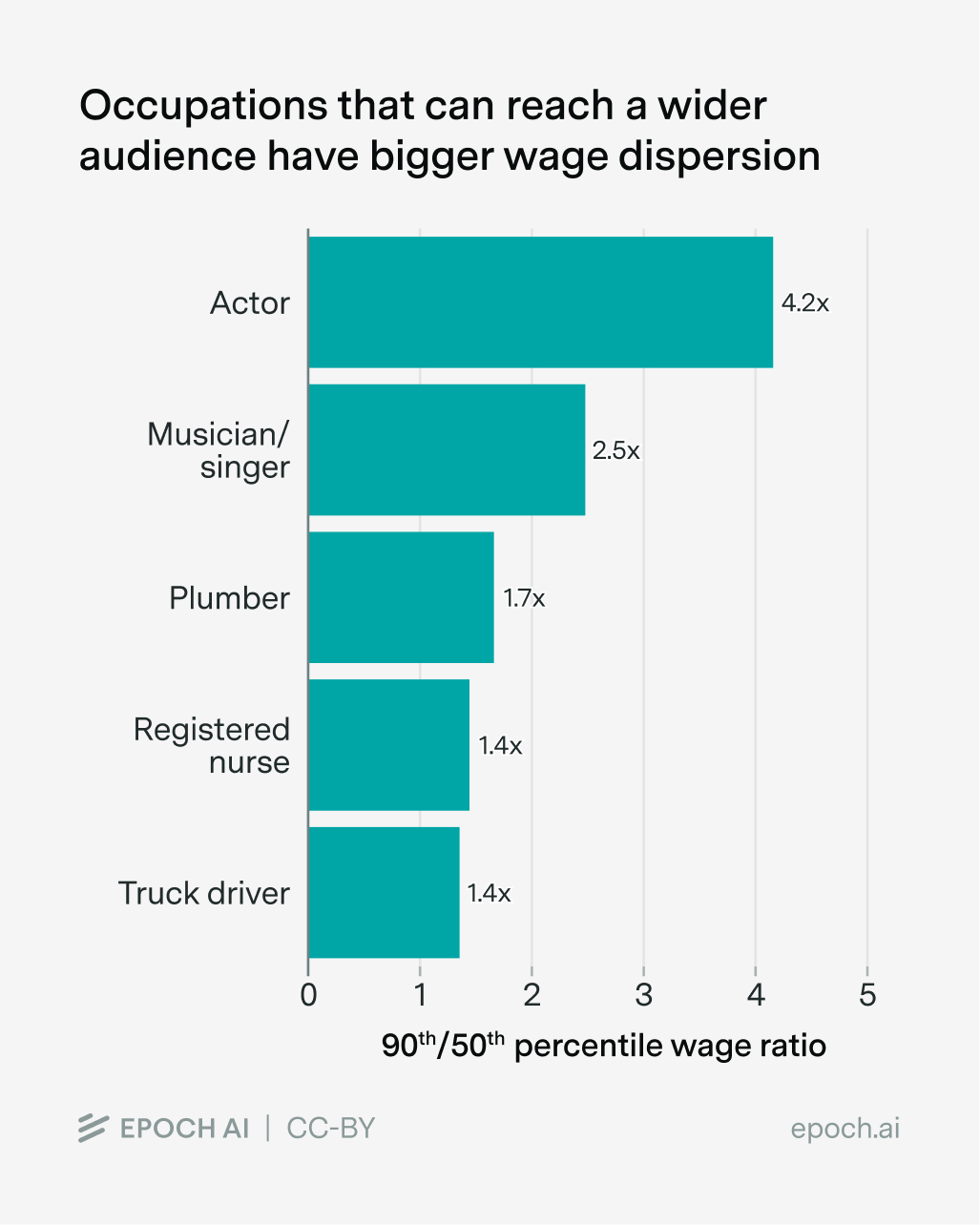
Data from the Bureau of Labor Statistics across different occupations, showing the ratio of 90th percentile earnings to the median. If we had data on the extremes (e.g. 99th percentile), I’d guess the difference in wage dispersion would be even larger.
- Quantity doesn’t easily make up for quality of labor. You can’t have multiple people take the place of a single sprinter, since that would break the rules of the race. And if you like Taylor Swift more than Ed Sheeran, it’s hard to make up for missing a Taylor Swift concert by going to more Ed Sheeran ones.
The first condition means a tiny quality edge captures enormous extra value, making it worth paying a lot for the best — that is, as long as you can’t make up for quality with quantity (the second condition). If you could, you’d just hire a lot more people with lower pay — you wouldn’t need to pay a ton just to hire the cream of the crop.3
Why this applies to AI
AI researchers tick both boxes. There’s a huge market: ChatGPT has almost a billion users, served by the same handful of underlying models, so a single researcher’s contribution could scale to every user simultaneously.
And in AI, researcher quantity doesn’t easily make up for quality: frontier labs are compute-constrained, so they can only run so many experiments to test new software innovations. Two “merely very good” researchers can’t replicate one Noam Brown if what’s needed is deep intuition about which experiments are worth running in the first place. Not to mention the difficulties coordinating researchers if labs are short on time.4
This is how even a 2× researcher could earn far more than the median. Scaled to a billion users, even a small quality edge generates enormous differential value. And if the 2× researcher can add something that multiple 1× researchers can’t, then it’s worth paying a lot to capture this.
Race dynamics amplify the effect
Frontier AI labs are often described as being in a “race”. I’m not sure what exactly they’re racing toward, but it often seems to involve automating huge swathes of human labor, a prize potentially worth tens of trillions of dollars a year — if you win. This incentivizes AI labs to adopt an “all in or nothing” approach, and anything that improves their chances even a little might be worth a lot. Hence Meta’s (alleged) $100 million dollar compensation packages to poach top researchers from OpenAI.
In principle it’s even possible this pushes things well beyond what is socially valuable (however you define that) — it’s like how high frequency traders spend huge sums trying to execute a trade a tiny bit faster, to almost no social benefit.
Reality is complicated, and so is managing an army of AIs
Other forces are at work too. Top researchers carry valuable trade secrets in their heads — the results of expensive experiments competitors haven’t run, and which would cost a fortune to replicate. Many also manage teams, contributing more value than just their raw technical research ability; Noam Brown recently described himself as a “manager at OpenAI.”5 Each of these may contribute to the wage gap, separate from the superstar premium.
Additionally, it’s hard to quantitatively analyze the superstar effect.6 I don’t know of a good way to quantify “researcher quality”. There are some valiant efforts like METR’s RE-bench, but these contain small isolated tasks (think “finetuning GPT-2”) rather than projects with millions of lines of code, fuzzy objective metrics, and lots of coordination between different people.
But despite these complications, I think the superstar effect tells us several useful things. For one, I’ve seen a couple of news articles about Meta’s attempts to poach researchers with exorbitant salaries, in their quest for Personal Superintelligence. But these articles usually miss out on this important superstar effect (though they often do touch on race dynamics).
Another important implication is for how we think about the intelligence explosion. If a 100× pay gap is driven by a 100× researcher quality gap, then simulating a top researcher might speed things up much more than simulating an average researcher.7 But this isn’t the case if much of the pay gap is driven by the superstar dynamic — the gap in researcher quality might actually be much smaller.
Finally, knowing about this effect gives us some hints at what’s to come in the near future. I think that the superstar effect will only become more important moving forward. That’s because lots more people will use AI, and each person will use AI systems much more heavily. And as research increasingly shifts toward managing an army of Claudes, those with deep research intuitions and years of experience as research managers will probably see ever-growing boosts to their productivity, as well as the sizes of their wallets.
So if anything, superstar earnings might become an even bigger deal — $100 million annual compensation quite literally might not be enough.
I’d like to thank Andrei Potlogea, Phil Trammell, Josh You, David Owen, JS Denain, Cheryl Wu, Stefania Guerra, Robert Sandler, Lynette Bye, and many people at Trajectory Labs for their feedback and support. Thanks also to Luis Garicano for inspiring me to write this essay in the first place.
-
Or even “10,000× researchers”!

-
The key difference is what economists call “nonrivalry” — if I watch a Tom Hanks movie, it doesn’t stop you from doing so at the same time, and this can scale to any number of consumers. But not all goods and services are like movies — if a plumber is fixing my sink, they can’t fix your sink at the same time.
-
Strictly speaking, I think there should also be a condition about the distribution of human researcher quality — if you have many superstar researchers, having one more superstar might not add much value, so they might not get paid that much. For example, in Tom Cunningham and Manish Shetty’s (super interesting) apple-picking model of AI R&D, the marginal value of researchers at the same quality drops exponentially. This follows from two assumptions: (1) that researchers sample from the space of ideas independently, and (2) each additional unit of researcher effort finds new ideas at a rate proportional to how many (discoverable) ideas remain. These assumptions are of course debatable — for example, researchers might be able to coordinate to some degree on the kinds of things that they work on, and they also have some amount of diversity. But I think this is an interesting prediction nevertheless.
-
For illustration, imagine that a frontier lab can do ten large-scale experiments at any one time. A superstar researcher is able to get insights from three of these ten experiments, whereas a “merely very good” researcher can get insights from two out of ten. Having more “merely very good” researchers doesn’t help a great deal because they end up with the same two out of ten insights, but having a superstar researcher helps you reach a higher bar because they have slightly better research taste. The important thing is that this research taste is a dimension of quality that’s hard to parallelize, and this tiny edge can matter a lot, in the same way that an absolute quality difference of 0.1s matters a ton in the 100-meter sprint.
-
You could also argue that frontier AI labs might be poorly calibrated about the importance of researcher quality.
-
I’ve also been describing researcher quality as some purely one-dimensional thing, but there may be different kinds of quality — some people are good at coordinating many GPUs in a cluster, some people are good at research engineering, some are good at coming up with new algorithms. In the worst case, I think you could just apply the superstar dynamic along each particular dimension of “researcher quality” that you care about. Interestingly, you could potentially also argue that this even supports the observation of big pay gaps even more. If many different skills are important for being a good researcher, and they combine multiplicatively, then you end up with a heavy-tailed (lognormal) pay distribution, just as the superstar effect predicts.
-
This is an important thing to be aware of, but I also doubt it’s very load-bearing for people who believe in the intelligence explosion.