On paper, modern LLMs can ingest many books’ worth of text in one go. For example, Gemini 2.5 Pro has a “context window” of 1 million tokens, enough to stuff in ten copies of Harry Potter and the Philosopher’s Stone.1 But what if we could do lots of inference with much longer contexts? What if LLMs could take in 10 billion tokens of context, and we had the hardware and algorithms to make this usable in practice?
The naive use case is being able to take in ever-longer documents. But we think the implications of long context inference could be much greater:
- It provides an angle of attack on the ability to continually learn new knowledge after the model is deployed, one of the biggest bottlenecks to the real-world utility of current AI systems.
- It supports a ton of RL scaling: doing more reasoning, verifying model outputs, and generating high-quality RL environments.
- But there are also bottlenecks. As RL scales to longer runs, research iteration cycles slow down. And you’ll also need a lot of hardware and algorithmic progress so that long-context inference isn’t prohibitively slow or expensive.
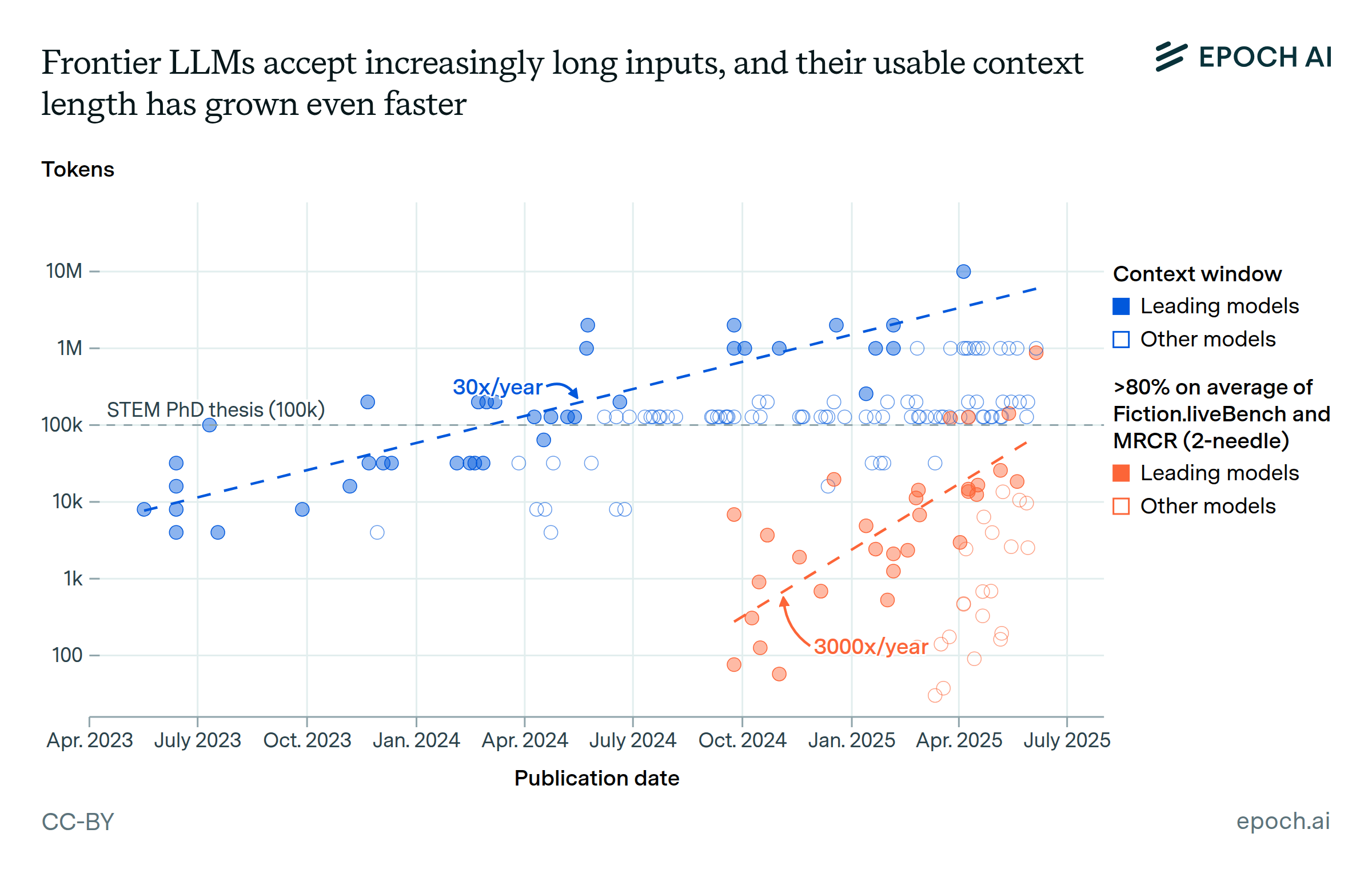
What’s more, context lengths have been growing at 30× per year, and frontier LLMs are getting much better at using these contexts. So if these trends continue even at a fraction of this pace, these huge implications could come to pass very soon.
Extremely long context inference provides an angle of attack on continual learning
To be truly economically useful, LLMs will likely need “continual learning”, the ability to keep acquiring knowledge over time.2 For example, it’s crucial for helping AI systems learn from mistakes or develop research intuitions. But current LLMs don’t have much of a “memory” that they can retain over long chats or across multiple user interactions.
Part of the issue is that LLM context windows aren’t long enough to support much continual learning. For example, if you record work history using screenshots, 1 million tokens of context is only enough for AI agents to do computer tasks for up to half an hour – not nearly enough to acquire much tacit knowledge.3 But we can do a lot more with longer contexts: with 10 million tokens we get around six hours of computer use, and with 10 billion tokens this becomes eight months! More optimistically, if text and audio tokens alone are sufficient to represent work experience, even ~40 million tokens might be enough to acquire multiple months’ worth of “work experience”.4
But if these longer contexts are available, models can learn from previous examples in their context window. For instance, reasoning models have demonstrated some ability to correct their own mistakes in their chain of thought, and retaining these learned corrections in-context could help the model solve problems in the future.
This broad approach of “continual learning with giant context windows and in-context learning” has been raised several times. For example, Aman Sanger alludes to this in a discussion with Cursor’s team, and Andrej Karpathy has also sketched out how this might work on X:

That said, one might object to this approach on the grounds that tacit knowledge is hard to store in a text summary of prior context – it’s just going to lose too much rich information about how tasks are performed. There’s certainly some truth to this, but it doesn’t necessarily undermine the approach.
For one, you could potentially optimize the context a lot with context windows that are orders of magnitude larger than in current models. This could be enough to overcome the challenges with lossy compressions of prior experience. For example, suppose you have an LLM that can store the equivalent of months of work context. You could combine this with “sleep-time compute”, where models use their (potentially scheduled) downtime to learn by forming connections with the new information from their recent use. And the learned context this produces could be extremely efficient, heavily optimized using large amounts of inference compute and RL. Using lots of RL has already significantly improved how current models use their contexts, and as we’ll see in the next section, there’s still a lot of room for improvement.
If storing information in the form of text is the issue, long contexts could also be combined with other approaches that people are actively working on. For one, tokens can serve as a common representation for multiple different modalities. Or perhaps tacit knowledge could be stored within a learned KV cache that serves as a dense representation of prior knowledge – much better than a simple text summary.
That said, whether these techniques actually end up working depends on more than just increasing the size of context windows on paper. It also requires building infrastructure so that more relevant context (e.g. all recent work interactions) can be digitized and shared with LLMs.
We also care about how well the context can be used in practice – even if a model has a 1 million context window on paper, it can start becoming incoherent on inputs well shorter than that. For instance, on the Vending Bench benchmark, models are required to manage simple business tasks to run a vending machine and earn profits. However, models sometimes “derail” and lose large sums of money, well before on-paper context windows are full. And we also see this when using LLMs in practice – models can overindex on prior mistakes in a long conversation, such that users feel the need to simply start afresh in a new chat.
Being able to do lots of long context inference supports more RL scaling
To keep models coherent across long context windows, one approach is to continue the current paradigm of RL and test-time compute scaling. For example, this could mean using some degree of end-to-end RL training, an approach that has contributed to reasonable success in products like OpenAI’s Deep Research. This provides a training signal that helps models stay consistent over a long response to a user query.
Being able to do a lot of long context inference also supports this continuation of RL scaling. One reason for this is that it supports longer rollouts – with larger context windows, you can allow models to output longer reasoning traces to tasks that take longer to complete.
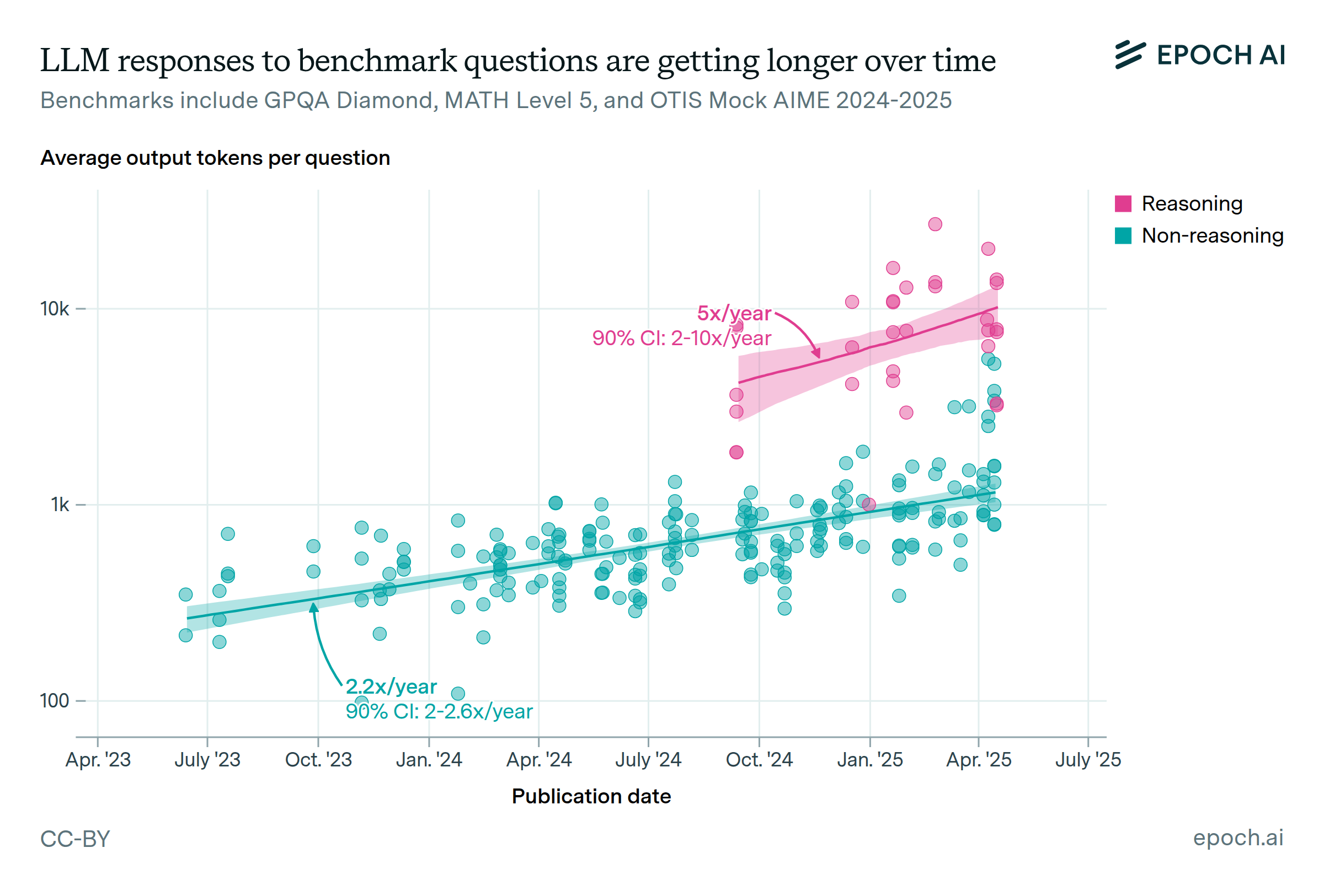
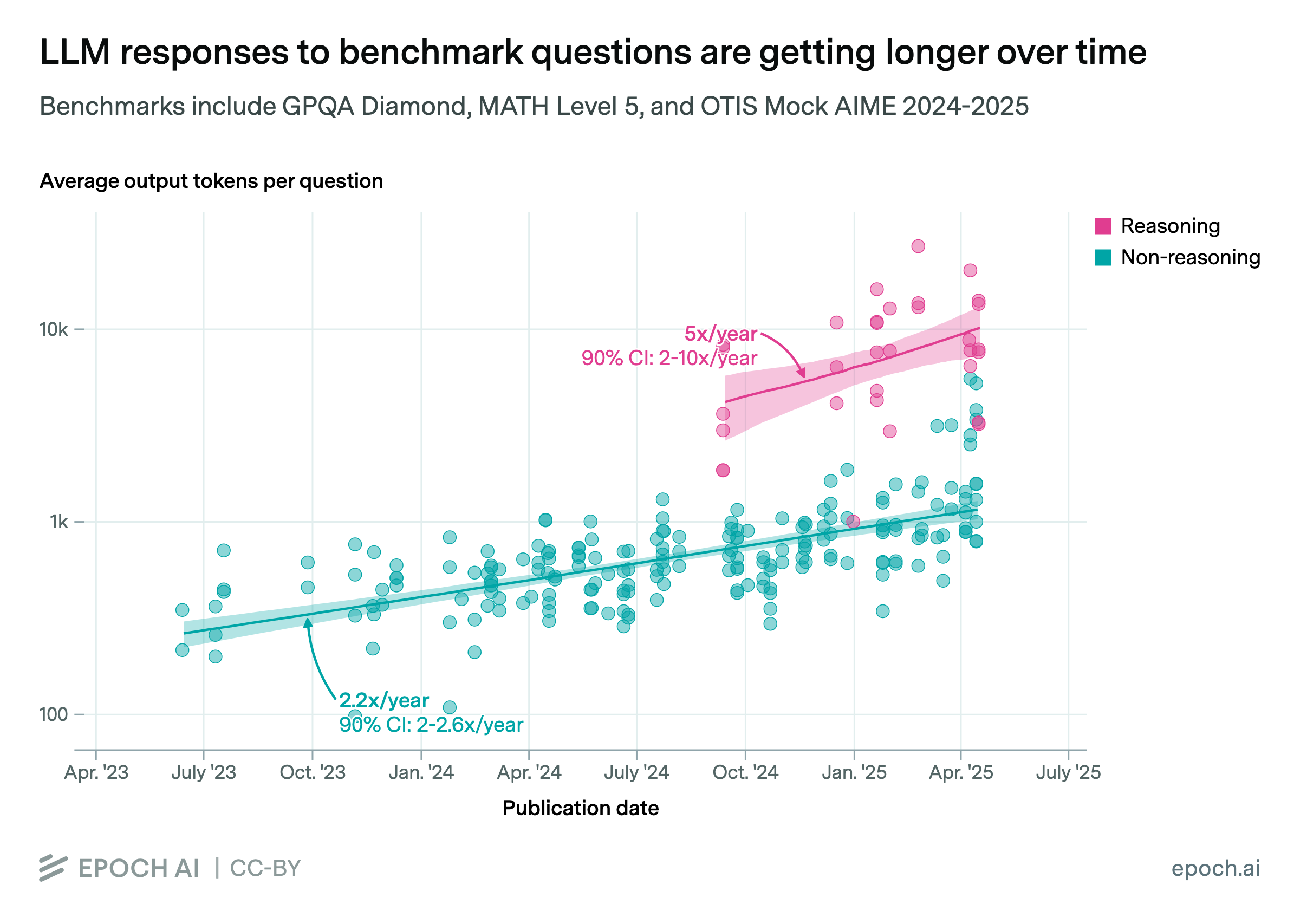
Model responses to benchmark questions are getting longer over time, especially in reasoning models that are typically trained with RL. This increases the demand for long-context inference.
As LLMs are applied to longer and more complex tasks, they might increasingly encounter an issue of sparse rewards, where models only rarely get clear feedback signals about their performance. For example, this might be useful for choosing research directions in AI R&D – where it can take months to formulate hypotheses, design and implement experiments, before getting any signal about whether a research strategy is good or bad. On these tasks, not only is each rollout long, it’s also especially helpful to do lots more of them – this makes it more likely that at least one rollout contains a “success” that the model can learn from.5
Long context inference also helps provide high-quality reward signals to reasoning models, by supporting the long chains of thought required for verifying long model outputs.6 And having high-quality verifiers has been crucial for AI progress already, most notably OpenAI’s “Universal Verifier” used to improve GPT-5.
Moreover, long context inference can help with synthetically generating (parts of) RL environments. For example, part of Kimi K2’s training involved combining MCP servers and using LLMs to automatically generate lots of synthetic tools, agents, tasks and transcripts to help create good post-training data. This process serves as another source of demand for long-context inference, which we think can likely be extended to creating RL tasks in the future.7 At present, many of these environments are procedurally generated, but we expect these environments to increase in quality over time. To build these higher-quality environments, it becomes increasingly important to use long chains of thought or agent interactions, for which long-context abilities would be very helpful.
More concretely, we think long context inference could play a crucial role in scaling reasoning models to perform tasks with horizons of weeks or even months. And if this RL scaling yields anything like the kinds of improvements that we’ve seen from the last year of reasoning models, the implications could be huge.
Bottlenecks: Slower research iteration times and potentially rising costs
Of course, all this RL scaling and continual learning doesn’t happen for free; there are bottlenecks in the way.
One such bottleneck is fundamental – if you scale inference to week- or month-long horizons, it means that you can’t iterate on research as quickly. If it takes weeks to see if your new algorithm improves performance, that can really slow down how quickly new innovations are discovered. Noam Brown makes this point on the Latent Space podcast:
“As you have these models think for longer, you get bottlenecked by wall-clock time. It is really easy to iterate on experiments when these models would respond instantly. It’s actually much harder when they take three hours to respond.”
[…]
you can parallelize experiments to some extent, but a lot of it, you have to run the experiment, complete it, and then see the results in order to decide on the next set of experiments. I think this is actually the strongest case for long timelines.”
Another bottleneck is cost. Even if you can do a lot of long context inference in theory, using it in practice depends on affordability. You need a lot of hardware and inference-time algorithmic improvements, otherwise running the model could be prohibitively slow and expensive. And cost concerns have already manifested in practice – Google DeepMind deliberately chose not to release the 10 million token context version of Gemini 1.5 Pro because of high costs.
But overall, we think that equipping language models with the ability to do long-context inference could be a massive deal. It could help push the current reasoning paradigm much further. It could also enable crucial capabilities for AI systems that make them genuinely useful in real-world tasks. While it does come at some costs, these bottlenecks don’t seem insurmountable. And given current trends in context length and investment, it seems that these implications could be coming pretty fast.
We’d like to thank Will Brown for discussions that inspired many of the ideas in this post, and Lynette Bye for helpful writing feedback. We’d also like to thank Josh You and Jaime Sevilla for their feedback.
-
Harry Potter and the Philosopher’s Stone contains around 75,000 words, or around 100,000 tokens.

-
Note that some definitions of continual learning explicitly include training on new data, i.e. such that model weights get updated. We use a broader definition that doesn’t specify this mechanism, since we’re primarily interested in models’ ability to keep acting on new information that is encountered in-context.
-
This is assuming around 250 tokens per image, and 2 frames per second. With a context window of 1 million tokens, this corresponds to 1,000,000 / (250 * 2) = 2000 seconds, or around 30 minutes. More tokens may be needed in practice, especially when computer streams are text heavy. But this only shortens the timeframe and increases the importance of being able to do long-context inference.
-
For example, suppose that a person reads 30,000 tokens of text per day (equivalent to around three papers). If a person thinks at the same speed as they talk, speaks at a rate of 125 words per minute, and thinks for 6 hours a day at work, this adds up to another 45,000 words (60,000 tokens). The total is thus in the ballpark of 100,000 tokens, which over a year adds up to 12 * 30 * 100,000 ≈ 35 million tokens. In practice it may be higher still, since people are often able to think faster than they talk.
-
Other approaches can also be helpful. For example, intermediate rewards in the research process can likely help models learn more quickly.
-
This does not necessarily have to come in the form of outcome-based rewards — e.g. process-based rewards can also be helpful here.
-
One related example is Tongyi Lab’s AgentScaler, which outlines a pipeline for constructing agentic task environments.
About the authors
Related work