The core argument for how AI could drive explosive economic growth is that you can dramatically scale up the number of AI “digital workers”. The idea is that growth is constrained by labor, so rapidly expanding the workforce would hugely accelerate growth rates.
This is where AI comes in. While you can’t double the human population each year, you can double the number of AI chips – as we’ve seen with NVIDIA and OpenAI.1 So if AI can fully substitute for human workers, the workforce could grow many times faster than today. As a result, the economy could grow many times faster too.
If this framing is right, then to know how far we are from explosive growth, we need to answer three questions. First, how many AI “digital workers” can be deployed today? Second, how far is AI from fully substituting for human workers? And third, how are both of these changing over time?
In this post, we’ll take a stab at the first question: On the tasks that AIs are able to perform today, how many “human-equivalent digital workers” could frontier AI labs deploy to work on them?
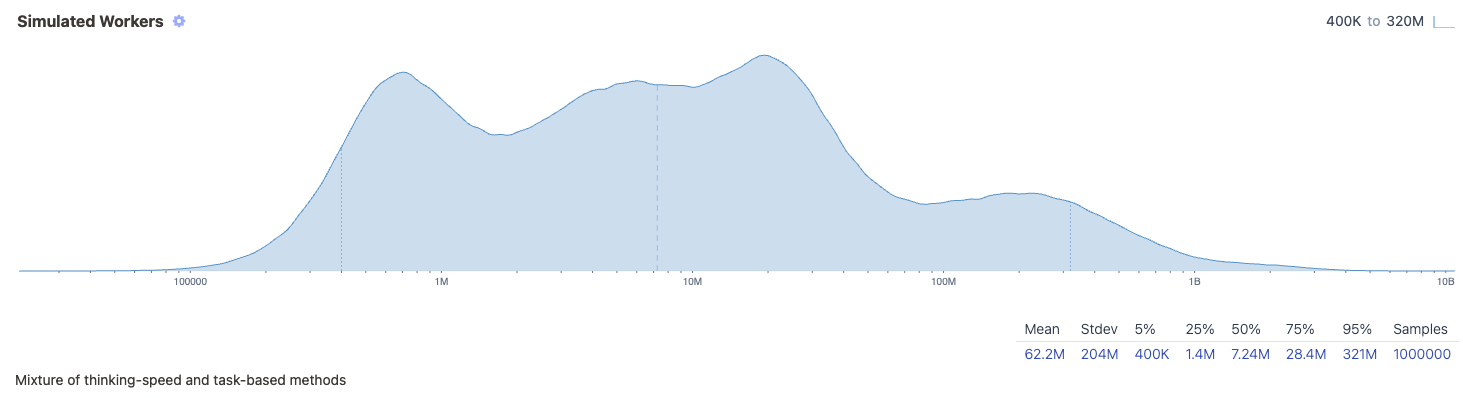
Based on a speculative back-of-the-envelope calculation, we estimate that companies like OpenAI have the hardware to deploy on the order of 7 million digital workers, with a wide 90% confidence interval of 400,000 to around 300 million.2 This doesn’t mean that OpenAI could do the jobs of 7 million human employees today, because AIs can’t fully substitute for humans. But as AI progress continues, AIs will be able to perform an increasing fraction of the tasks that humans currently do.
Estimating the number of digital workers that frontier labs can deploy
But where does this 7 million number come from? There’s no “AI employee count” webpage from the Bureau of Labor Statistics. So what we need to do is somehow figure out how much “work” is being done by running AIs at frontier labs.
Our approach is to compare the number of tokens that AIs process daily to the number of effective tokens that a human worker “processes” over a day when they read, think, and write. Then when you take the ratio of these two, you get the number of digital workers on the tasks that AIs can currently solve.
The first step is thus to figure out how many tokens frontier labs produce each day, and for concreteness let’s consider OpenAI’s GPT-5.
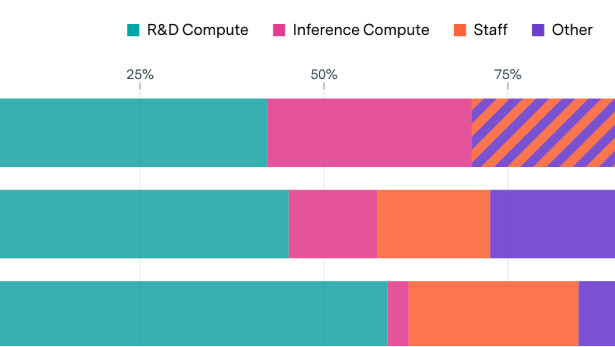
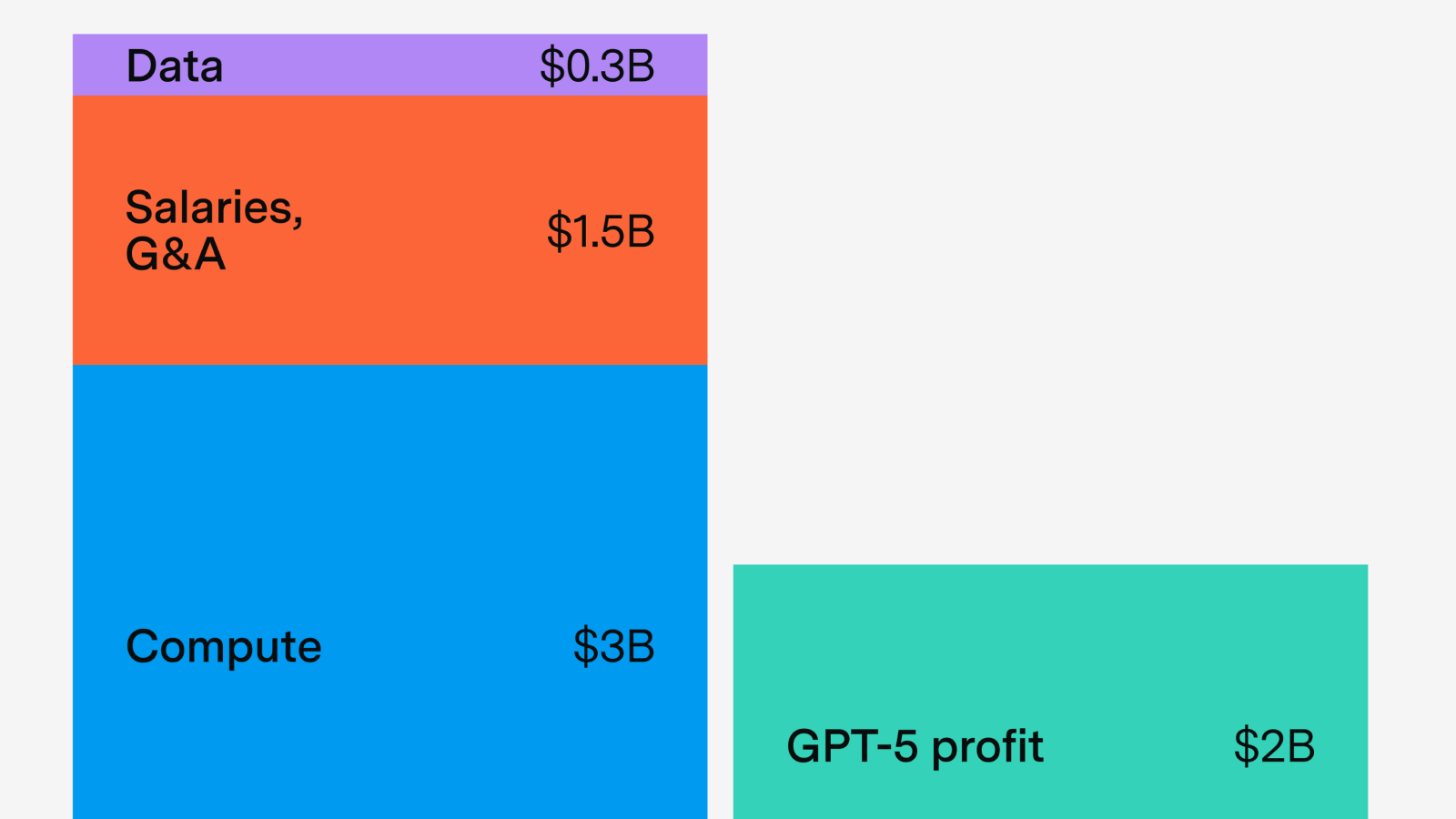
One approach is to look at OpenAI’s inference compute budget. Based on reporting from The Information, we think they currently have around 480,000 H100 equivalents for running models,3 which is enough for around \(10^{25}\) FLOP each day.4 It probably takes on the order of 100 to 600 billion FLOP for GPT-5 to generate each token,5 so that works out to around 10 to 100 trillion tokens per day.
For another approach, we also look directly at usage statistics: ChatGPT likely sends around 4 billion messages each day.6 If API costs contribute a quarter of the tokens of ChatGPT, and the mean message length is four thousand tokens long, then that implies GPT-5 generates around 20 trillion tokens per day.
For our final calculations we simply take a mixture of the predictions of these two approaches (with confidence intervals to capture uncertainty), with a median of around 19 trillion tokens a day. This is comparable to the 35 trillion tokens per day generated by Google’s AI models, so we think this is probably in the right ballpark.7
Now that we know the number of tokens, the next step is to convert these token numbers to “human-equivalent digital workers”. Essentially, how many effective tokens does a human employee “process” in a day?
We could look at the number of words spoken or the number of words written. But this would likely be an underestimate, since humans do a lot more thinking than they do speaking or writing. So we instead anchor to human thinking speeds of around 380 words per minute. If we convert this to tokens, and assume that each human works for 8 hours a day, that implies that each human worker processes around 240 thousand tokens a day.
Given this number, it’s really tempting to say “GPT-5 outputs 19 trillion tokens a day and each human processes around 240 thousand tokens, so there are 19 trillion / 240 thousand = 80 million digital workers”. But this assumes that each token is worth the same as each GPT-5 token, which might not be true.
So we can consider an alternative approach, that relies on a study by METR – this looks at whether AIs can perform a (software-related) task that takes humans a specified amount of time to perform. For example, one task might involve debugging a particular program, which typically takes human coders an hour to complete. The idea is then to look at how many tokens GPT-5 needs to do the same task and multiply it by the number of hours in a work day, representing the tokens needed to match a human over a day. In the case of the METR tasks, GPT-5 typically uses 100 thousand to 1 million tokens, so over an eight hour workday that’s 800 thousand to 8 million tokens. And if we divide 19 trillion by this, we end up with 2.4 million to 24 million digital workers.
Combining these two approaches suggests a median estimate of 7 million digital workers, but with very wide confidence intervals.8

What do these numbers tell us?
7 million digital workers is a lot – for comparison, the world’s largest employer has 2.1 million employees. This estimate is quite different compared to prior approaches. For instance, some works estimate the number of digital workers by dividing a compute stock by the computational power of a human brain.9 Given that OpenAI has enough compute to do \(10^{25}\) FLOP per day, and the human brain needs \(10^{15}\) FLOP/s to run, then that amounts to around 100,000 workers – around 500× smaller than our estimate!10
Of course, as we alluded to earlier, it’d be wrong to conclude that 7 million workers are about to lose their jobs, because current AI systems aren’t able to do all the tasks that humans can.11 Humans and AIs have different skill profiles, and currently humans are able to do many tasks that AIs can’t do regardless of how much inference compute they use. But as AI progress continues, AIs will substitute humans for a wider and wider range of tasks, and our calculation approach becomes more directly meaningful - at least as a lower bound on AI’s economic impact, since AIs will also be capable of tasks that no human could perform.12
In particular, suppose AIs became good enough to automate a decent chunk of the tasks in the world economy, including the jobs of software engineers and remote workers. Even if we were stuck with the same number of digital workers, the impacts could be pretty notable. On the tasks that AIs can perform, they can typically perform them much cheaper than humans. For example, suppose a software engineer takes an hour to debug some code – then they might be paid $50 to $100. But if GPT-5 is able to do the same task, it would instead cost $1 to $10.13 Such a substantial cost difference would provide a strong incentive to use the AIs instead of humans on the automated tasks, potentially impacting the jobs of tens of millions of workers.
Moreover, if millions of digital workers can be deployed in parallel, learn from their real-world interactions and share the resulting knowledge, this would allow AI systems to accumulate knowledge much more quickly than humans. So there’s the potential for AIs to learn missing skills very quickly.
On the other hand, one could argue that these 7 million workers are still peanuts compared to the overall economy – the world’s working population is still two orders of magnitude larger, so this wouldn’t be enough to drive explosive growth. With current compute stocks and automation costs, this is true even if we had AI that could fully substitute for humans.
But some have also raised the possibility of a more extreme scenario – if these digital workers were primarily concentrated into AI R&D, that could substantially accelerate AI progress, further increasing the number of digital AI researchers, and so on. While 7 million workers is small on a global scale, it’s likely still substantially higher than the world’s current population of AI researchers.14
So the implications of our estimate could change pretty substantially depending on several factors. We need to know how quickly AI automates more tasks. We need to know how much more compute there’ll be to run digital workers over the next few years, and whether researchers can use this compute more efficiently at inference. And we also need to know how likely we are to see dynamics like explosive economic growth and a software intelligence explosion. These are questions that we’ll investigate in forthcoming issues.
We would like to thank Lynette Bye for her feedback on this post.
-
For example, OpenAI’s compute spending grew from $6 billion mid-2024 to $13 billion mid-2025 – but this growth rate might also slow down.

-
You can find the full code for our analysis here.
-
Specifically, based on reporting from The Information we estimate that they currently have around 1.1 million H100 equivalents in total compute stock, and we place a 90% credible interval on this from around 800 thousand to 1.4 million H100 equivalents. Around 44% of this goes to inference compute, as opposed to training or experiments.
-
This depends on several assumptions. First, we assume that inference runs on FP4 on hardware that supports it (e.g. GB200s) and on FP8 otherwise (e.g. H100s). Second, we assume an inference utilization of around 5% to 30%, in part based on our estimates of Llama 3.3’s and DeepSeek-R1’s utilizations. The full calculation can be found in the code.
-
We estimate that GPT-5 has between 50 billion and 300 billion active parameters, so at 2 FLOP per active parameter, we get 100 billion to 600 billion FLOP per token.
-
In June 2025, ChatGPT daily message counts were 2.627 billion, compared to 451 million one year earlier. This corresponds to a growth rate of 2627 / 451 = 5.8× per year, such that we expect around 4 billion daily messages by September 2025.
-
In July 2025, Google’s AI models reportedly processed 980 trillion tokens per month, or around 35 trillion tokens per day.
-
We combine these two approaches in part because we’re uncertain about how many “human tokens” equals one GPT-5 token. This can vary a lot depending on the task – for example, GPT-5 does translation with far fewer tokens than a human would need based on thinking time. So we don’t want to anchor too much on a 1:1 ratio or tasks like those from the METR study.
-
This is true at a coarse level, where some inference compute budget is divided by some runtime compute cost. But in practice things can be more complicated, e.g. in the GATE model the runtime compute requirements can change substantially depending on the task.
-
Of course, both our approach and this compute-based approach are highly uncertain – e.g. because it’s hard to pin down just how many FLOP/s the brain is doing.
-
We’ve also glossed over details like how fast AI systems are run.
-
One dimension of these capability improvements is on long-context tasks, which could impact our estimate of the number of digital workers. For example, long context decoding (but not prefill) is typically bottlenecked by memory bandwidth. In our analysis, this would translate into lower compute utilizations, but a more sophisticated approach could also directly model labs’ total memory bandwidth stock, as AI Futures attempted in the AI 2027 report. This may be the case even with improvements in inference efficiency.
-
This is based on the METR task example we gave earlier. If an GPT-5 takes 100,000 to 1 million tokens to perform a task that takes humans an hour, then at $10 per million output tokens this would add up to $1 to $10.
-
This is especially true if we restrict ourselves to research that occurs on frontier models. For example, if we sum the number of employees at frontier AI labs, we likely get on the order of 10,000 employees. This is already multiple orders of magnitude lower than our estimate, not to mention that the actual number is likely lower, since not all employees are researchers.
About the authors



Related work