This report presents an expanded database of AI models in biology, commissioned by Sentinel Bio and building on our 2024 collaboration, in which Sentinel Bio funded Epoch AI to collect and organize information about AI models in biology. The goal of this new report is to expand coverage to new categories of biology-relevant AI models and to capture releases since September 2024.
To build the database, we searched major academic databases and preprint servers for papers introducing AI models in biology, then used language models to filter candidates and extract structured metadata from the remaining papers. The most important models received additional manual review. The full methodology is described in the Appendix.
Key findings
The final database contains 1,196 models, of which 1,124 were annotated using AI assistance only while 72 received dedicated manual annotation. We also manually checked every entry for which we reported safeguards being used. Here are the main findings from our analysis:
Pre-release risk assessments and risk-related evaluations are rare. Only 2.5% of models have documented risk assessments, and 2.3% report running risk-related evaluations. These practices are more common among notable models, but this is largely driven by frontier LLMs, which account for 60% of the models in our database reporting risk assessments, and 68% of those reporting evaluations.
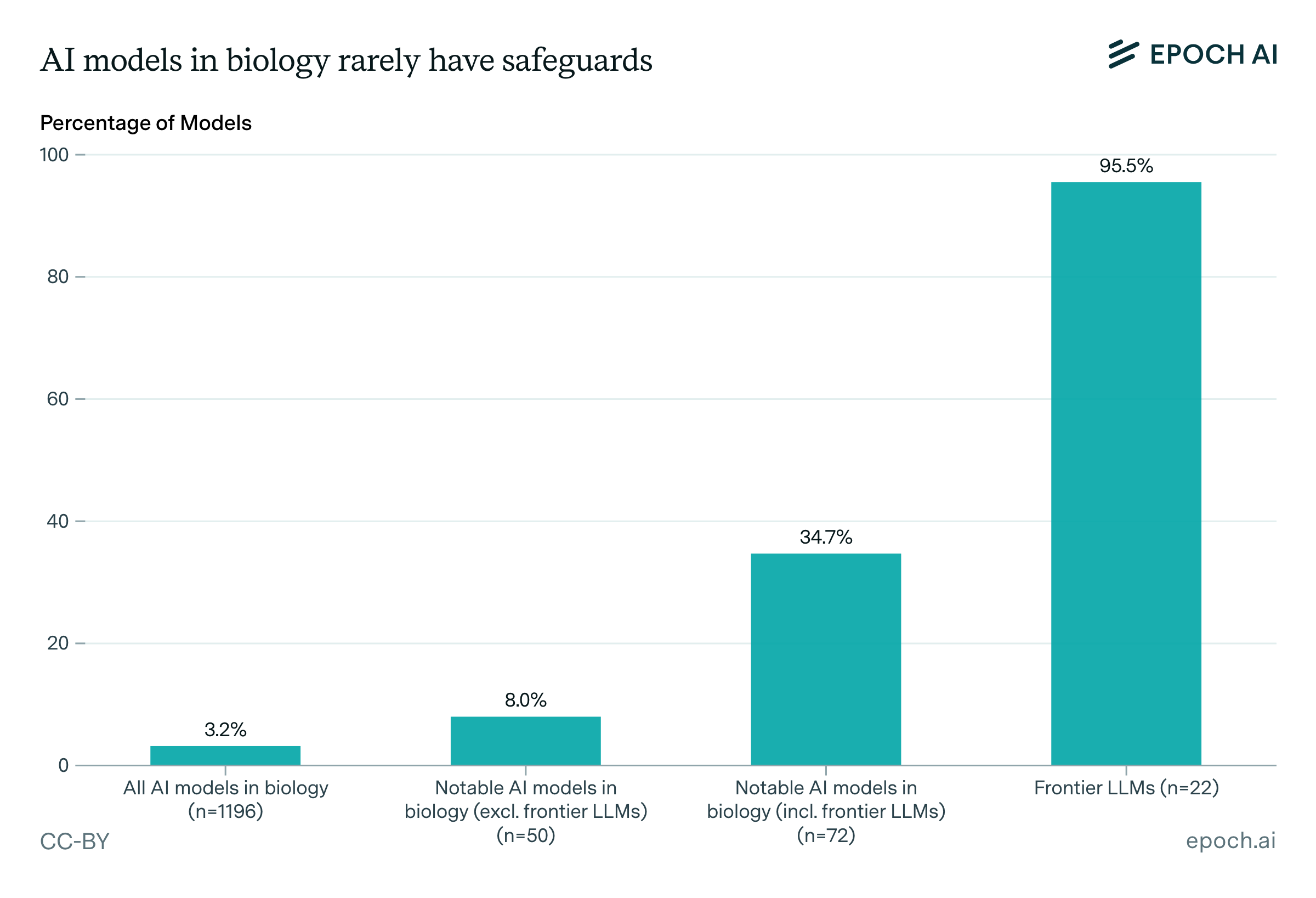
Safeguards are rare: only 3.2% of all models have any documented safeguards. Among notable models, 35% have safeguards, but again this is driven by frontier LLMs, 95% of which have safeguards, compared to just 1.4% of non-LLM biological AI models. Frontier LLMs account for over half of all models with safeguards.
When safeguards do exist, the types differ between frontier LLMs and other models. Frontier LLMs rely heavily on inference-time filtering, while non-LLM biological AI models with safeguards rarely use inference-time filtering, though they more commonly use post-training safety techniques or filter training data.
Most models share their code and data, though open weights are less common. About 58% of models provide open inference code and 46% share their training data. Open weights are released for about 23% of models.
Protein engineering and small biomolecule design are the largest model categories. These two model categories account for nearly half of the models in the database. Correspondingly, the most widely used training datasets are the Protein Data Bank and UniProt for protein-related, and ChEMBL for small molecule design models.
Many models build on a small number of foundation models. About one in five models in our database (253 of 1,196) are finetuned from an existing model rather than trained from scratch. The ESM-2 family of protein language models is by far the most common base.
Data access
The database containing the 1,196 models released after September 2024 is available at this link, with safeguard-related information redacted. Researchers and other parties with a legitimate interest in the safeguard data can request access by contacting data@epoch.ai.
Methodology overview
We aimed to capture AI models in biology1 released since September 2024, spanning nine categories: protein engineering, small biomolecule design, viral vector design, genetic modification, immune system modeling and vaccine design, pathogen property prediction, general-purpose biology AI, biology research agents, and biology desk research agents. We also included frontier large language models as part of the “general purpose” category.
Our process had four main stages. First, we searched for candidate papers across SemanticScholar, OpenAlex, and ChemRxiv using keyword and concept-based queries, yielding roughly 34,000 results. Second, we filtered these in two stages using AI-assisted screening: first on titles and abstracts, then on full paper texts. Third, we extracted structured metadata from the remaining papers (model name, category, parameters, training data, safeguards, accessibility, and other fields) using a prompted language model. Finally, we manually reviewed and annotated the 72 models we designated as “notable” based on criteria such as high citation counts, publication in top journals, or development by prominent research groups.
The full methodology, including search terms, extraction prompts, and detailed descriptions of each pipeline stage, is available in the Appendix.
Analysis
1. Dataset Overview
Our database contains 1,196 AI models in biology, of which 72 are designated as “notable” based on criteria including publication in prestigious journals, development by prominent research groups, or high citation counts. This section provides an overview of the landscape: where these models come from, who builds them, and what they do.
Category distribution
The distribution of AI models in biology across categories reveals the field’s current priorities. The two largest categories are protein engineering (e.g. given a target binding site, generate an amino acid sequence that folds into a protein that binds to it) and small biomolecule design (e.g. given a protein target, generate a small molecule that binds to it with high affinity). Together these constitute around half of the database. These, in addition to “Genetic modification” (13% of models), are the core “design” capabilities: tools for creating new proteins, drugs, and genetic sequences.

Pathogen property prediction (e.g. given a viral sequence, predict how transmissible or drug-resistant it is) is smaller but particularly relevant from a biosecurity perspective, given its dual-use potential. General-purpose models, a mixed category containing both frontier LLMs and biology-specific foundation models like ESM3 and Evo 2, account for about 13% of the database.
Geographic distribution
The geographic distribution of biological AI development is heavily concentrated. The United States and China together account for the majority of models, reflecting their dominant positions in both AI research and life sciences. A second tier of countries (the United Kingdom, Canada, Germany, and Switzerland) contribute meaningfully but at a much smaller scale. The remaining models are distributed across a long tail of countries, each contributing only a handful.
About 29% of models (249 of 865 with organization data) involve collaborations between organizations from multiple countries. This number likely underestimates the amount of international collaboration, since we track the country an organization is headquartered in, but many organizations have researchers located in multiple countries.

Institutional distribution
Universities produce the vast majority of publicly documented AI models in biology, followed by research institutes and corporations. This stands in contrast to frontier language model development, which is dominated by well-resourced industry labs. The pattern suggests that biological AI remains primarily an academic field, with much of the publicly accessible work driven by research groups rather than commercial entities. However, we have limited insight into biological AI models developed in-house at biotech and pharmaceutical companies.

Note that our organization data is incomplete: we link models to organizations through their associated papers, which does not always capture all contributing institutions, and geographic and institutional information is available for only about 72% of models. These figures should be treated as indicative of broad patterns rather than precise counts.
Notable models
Our database designates 72 models as “notable” based on several criteria: publication in prestigious journals, development by prominent research groups, or high citation counts. This subset allows us to examine patterns among the most impactful and visible models in the field.
The notable models subset reveals interesting differences from the full dataset. Corporations are far more prominent among notable models, a reversal of the pattern in the full dataset where universities dominate. This suggests that while academic labs produce the majority of AI models in biology, the most impactful and visible models tend to come from industry. The United States is also more preeminent among notable models compared to its share of all models.
The category distribution among notable models is dominated by “general-purpose” models, which includes both frontier LLMs and biology-specific foundation models like ESM3 and Evo 2.
2. Risk management practices
Some AI models in biology could potentially be misused to design or modify pathogens, toxins, or other harmful biological agents. Understanding how the field is addressing these risks is central to biosecurity policy discussions.
We track pre-release risk assessments as well as risk related evaluations. A pre-release risk assessment is a formal process conducted before deciding to release a model, such as threat modeling, documented risk analysis, or consultation with biosecurity experts. A pre-release risk-related evaluation is a test of whether the model can actually perform a risk-relevant task, for example by benchmarking its ability to generate pathogenic sequences or by conducting red-teaming exercises to probe for dangerous capabilities.
We also track which models implement safeguards to address biosecurity risks. Safeguards are measures taken by model developers to reduce potential harms. In the context of biological AI, relevant safeguards include filtering of harmful outputs, restrictions on who can access the model, and curation of training data to exclude dangerous sequences (such as those from human-infecting viruses).
The efficacy of safeguards is not assessed here and is beyond the scope of this analysis. Some safeguards can be easily removed. For instance, if data is purposefully excluded from pre-training, but the model weights are shared, the model can be fine tuned with task-specific data to recover the capability. For this reason, the mere presence of safeguards should not be interpreted as evidence that a model cannot be used for harm. There is ongoing work to develop and adapt a range of more robust safeguards to models of different types, but there may be technical limits to the extent to which open weights models can be secured.
Risk assessments and risk-related evaluations
Pre-release risk assessments and risk-related evaluations are rare. Only 2.5% of models have documented risk assessments, and 2.3% report running risk-related evaluations, and 3% of models report running at least one of the two. These practices are more common among notable models, but this is largely driven by frontier LLMs, which account for 60% of the models in our database reporting risk assessments, and 68% of those reporting evaluations.

Among frontier LLMs, pre-release risk management is now standard practice. Models like GPT-5.2, Claude Opus 4.6, and Gemini 3.0 Pro all report conducting both risk assessments and evaluations for dangerous biological capabilities before release. Outside of frontier LLMs, a smaller number of biology-specific models have adopted similar practices, including Evo 2 (a genomic foundation model from Arc Institute) and Google’s AI Co-Scientist.
Safeguards
Safeguards are rare: only 3.2% of all models have any documented safeguards. Among notable models, 35% have safeguards, but again this is driven by frontier LLMs, 95% of which have safeguards compared to just 1.4% of other models. Frontier LLMs account for over half of all models with safeguards.

When safeguards do exist, the types differ between frontier LLMs and biology-specific models. Frontier LLMs rely heavily on inference-time filtering (present for 95% of Frontier LLMs with safeguards) or access restrictions (62%), while biology-specific models with safeguards rarely use inference-time filtering (6%). Instead, biology-specific models more commonly use post-training safety techniques (65%) or filter training data to exclude dangerous sequences (35%). For example, Evo 2 and the open-weights version of ESM3 filter training data to exclude certain viral and other pathogen-related sequences.

3. Accessibility
Accessibility refers to how openly model developers share their work. We track several dimensions, which are not mutually exclusive (e.g. a model can be open weights but not open data, or vice versa):
- Open inference code: The code needed to run the model is publicly available.
- Open training code: The code used to train the model is shared.
- Open weights: The model’s learned parameters are released, allowing others to use the model without retraining.
- Open data: The training dataset is available.
- API access: The model can be queried through a programming interface, typically with some access controls.
- Web interface: The model is accessible through a browser-based tool.
- Unreleased: The model has been described in a publication but is not publicly available.

Most models do not restrict access. About 58% of models provide open inference code, and 46% share their training data. Open weights (23%) and open training code (28%) are less common but still substantial. Only a small fraction of models are available only through API access (3.8%).
4. Building Block Models
Many AI models in biology are not trained from scratch but are instead “finetuned” from existing foundation models. Finetuning involves taking a pre-trained model and adapting it to a specific task using a smaller, specialized dataset. This approach is efficient because the base model has already learned general patterns (like protein structure or sequence relationships) that transfer to downstream tasks.
In biology, common finetuning tasks include predicting protein function, identifying binding sites, classifying sequences by organism or function, or predicting the effects of mutations. The base models are typically large language models trained on biological sequences (like protein or DNA sequences) that have learned rich representations of biological structure and function.

Among the 253 models in our database that are finetuned from another model, ESM-2 is by far the most common base model, with 58 models built on top of it (this count aggregates across ESM-2 versions of different sizes). ESM-2 is a protein language model trained on millions of protein sequences.
Other common base models include ProtBERT (15 models), AlphaFold2 (7 models), and ProtGPT2 (7 models). The prominence of these protein-focused models reflects the field’s emphasis on protein engineering and design.
5. Training Data, Parameters, and Compute
Training datasets
Among the 1,009 models with training dataset information, the Protein Data Bank (PDB) is the most widely used, appearing in 159 models. UniProt is second (93 models), followed by ChEMBL (69 models) which is most useful for small molecule and drug design. GISAID (38 models), which comes next, contains influenza and coronavirus sequences and is primarily used for pathogen-focused models.

Protein and small molecule datasets account for the bulk of reported training data usage: this is consistent with those categories having the most models. Genomic databases are overall less prominent.
Parameters, data size, and compute
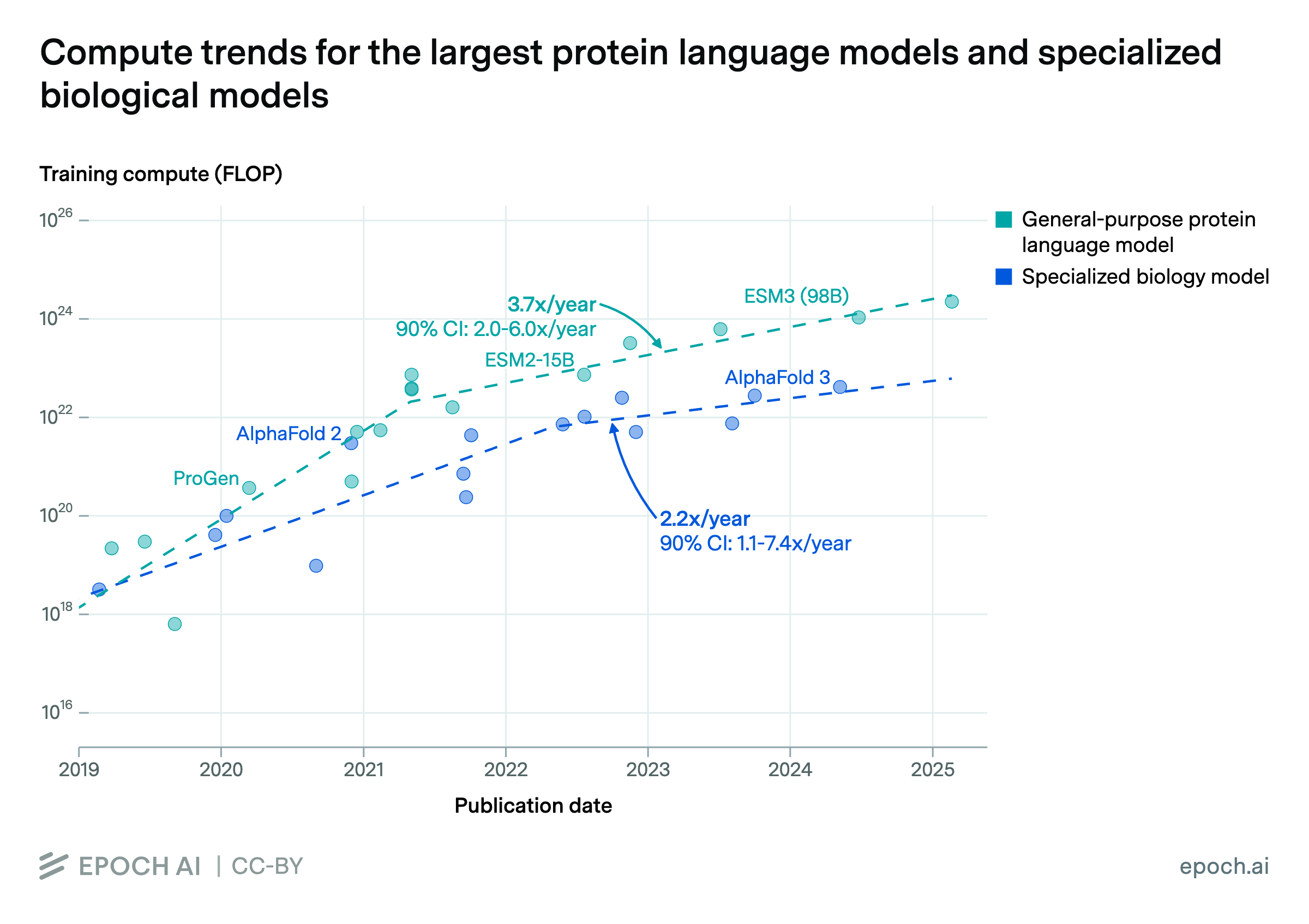
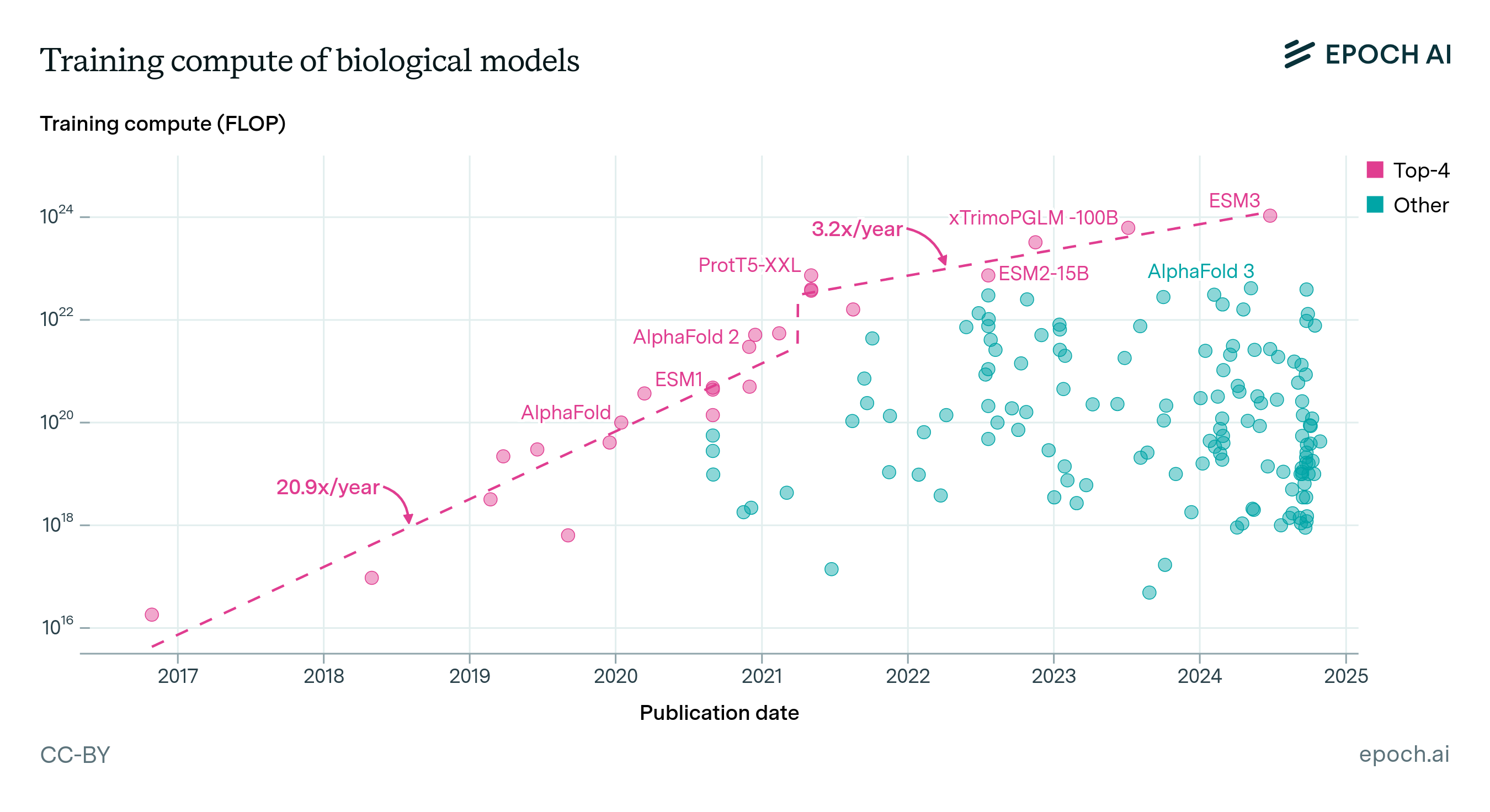
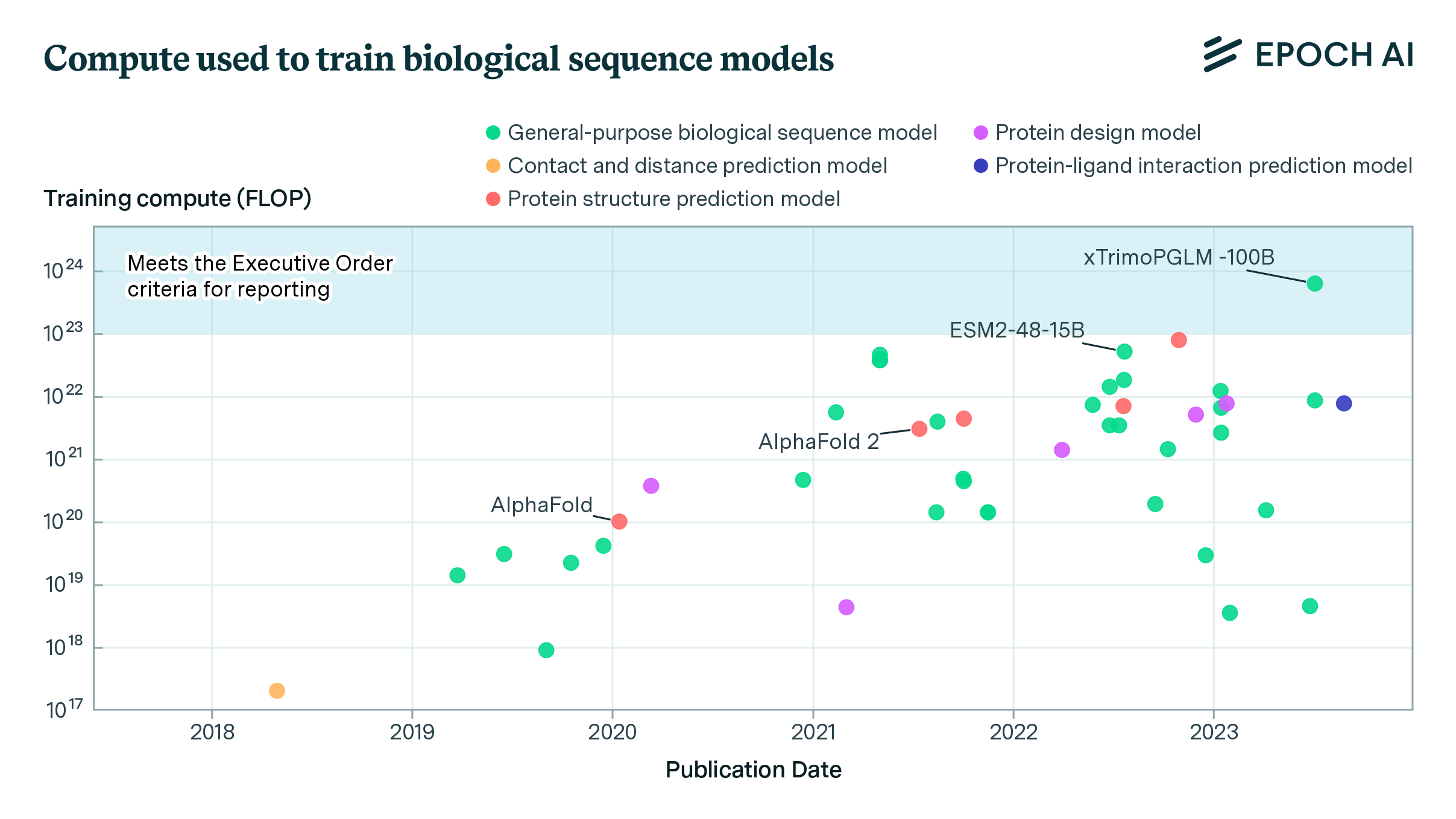
This report differs from typical Epoch AI outputs on frontier models, where training compute is often the central focus. For biological AI, we do not emphasize compute as heavily. The long tail of model architectures makes compute estimation much harder than for language models, where a few well-understood architectures cover most of the field. But more importantly, compute does not appear to be the primary bottleneck for biological AI capabilities (and might be even less relevant when considering capabilities related to misuse risks); progress seems more constrained by data availability and quality than by raw compute. That said, some observations are worth noting:
Parameters: Biological AI models span many orders of magnitude in size. Most models in our database are relatively small by modern standards, ranging from tens of millions to a few billion parameters. The largest biology-specific models, like Evo 2 (40 billion parameters) and xTrimo’s 100 billion parameter model, approach the scale of medium-sized language models but remain smaller than frontier systems like GPT-5 or Claude.
Compute: Training compute estimates are available for only a small subset of models. Where reported, values range from 1017 to 1024 FLOP, roughly spanning from a single GPU-day to a small fraction of frontier language model training runs (in the high millions of dollars for a 1024 FLOP run). The largest biology-specific training runs remain 2 orders of magnitude smaller than frontier AI training.
Appendix
Appendix A: Detailed methodology
Appendix B: Database Fields
Appendix C: Search terms
Appendix D: Prompts
-
We focus particularly, although not exclusively, on biological AI models, defined as “AI models that can aid in the analysis, prediction, or generation of novel biological sequences, structures, or functions.”

About the authors



Related work