
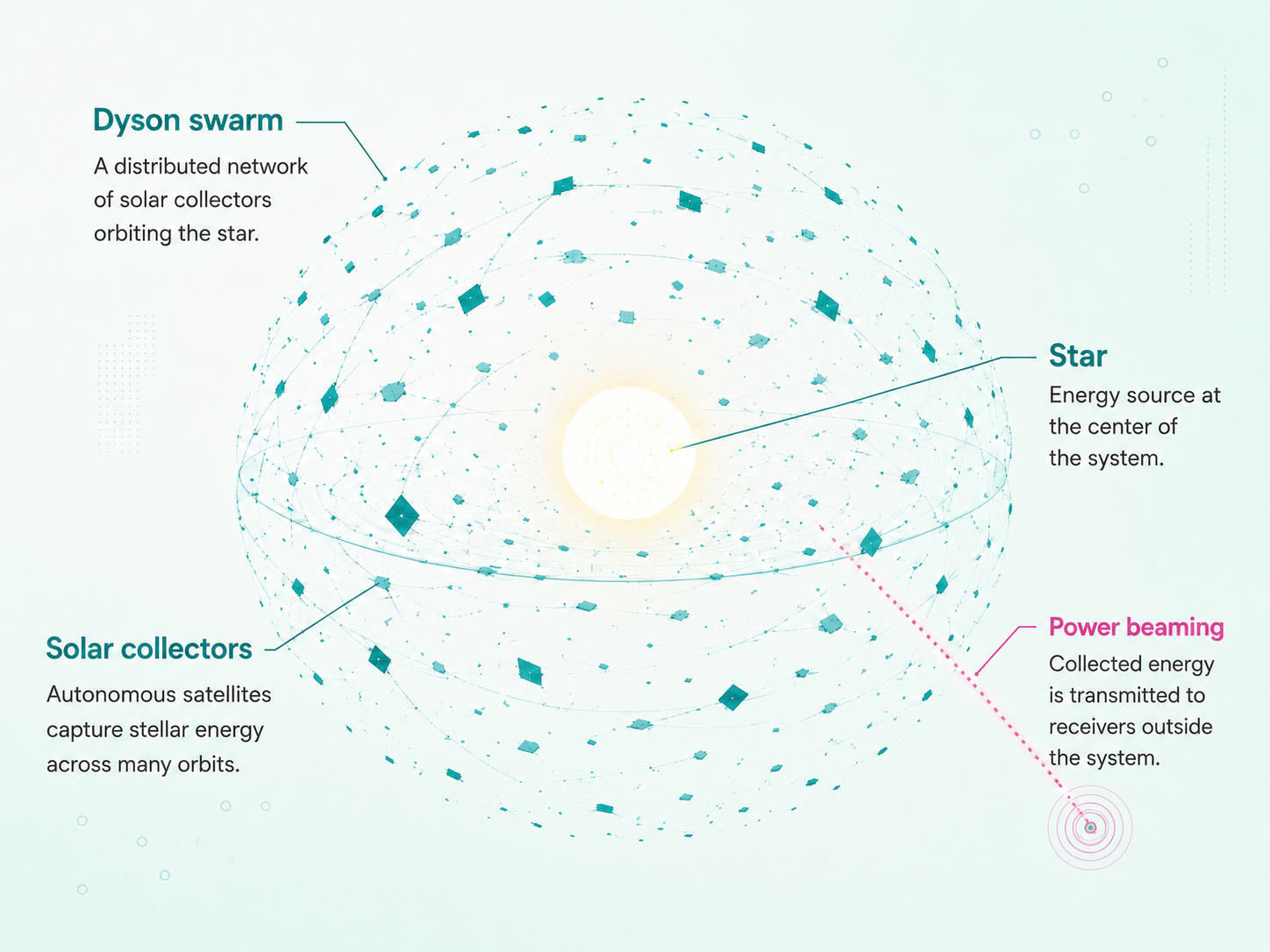
Why we should think a little harder about what it takes to build a Dyson Sphere
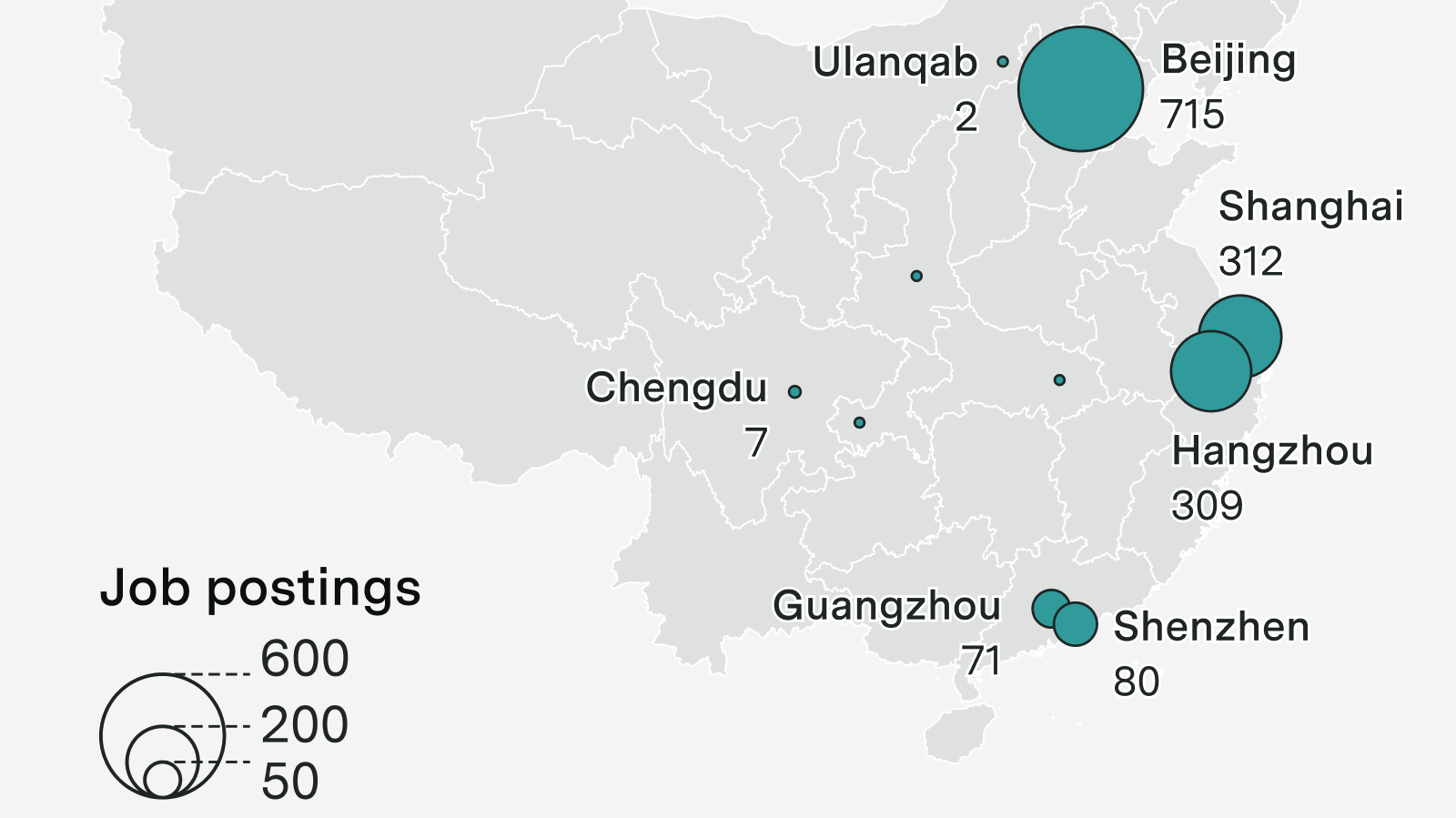
Inferring Chinese AI labs’ strategies from their job descriptions
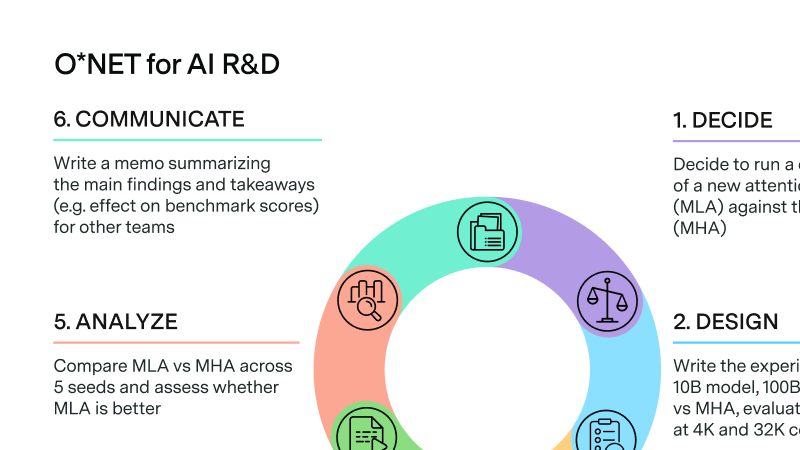
Proposing a new way to track AI research automation
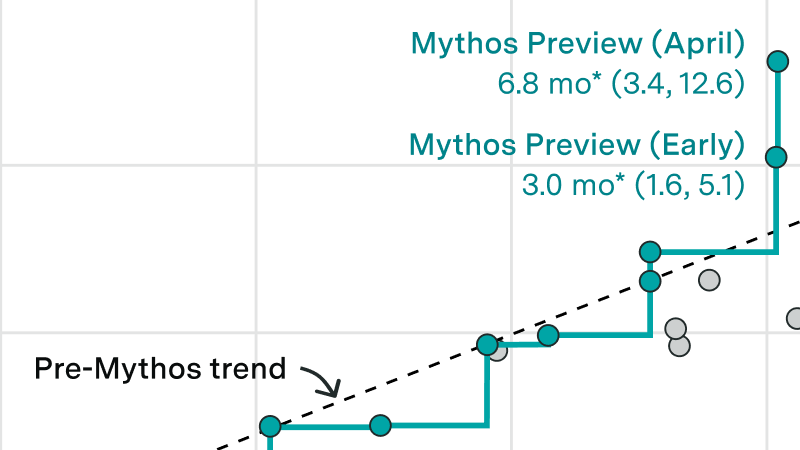
Compiling all the public evidence on Mythos Preview’s cyber abilities
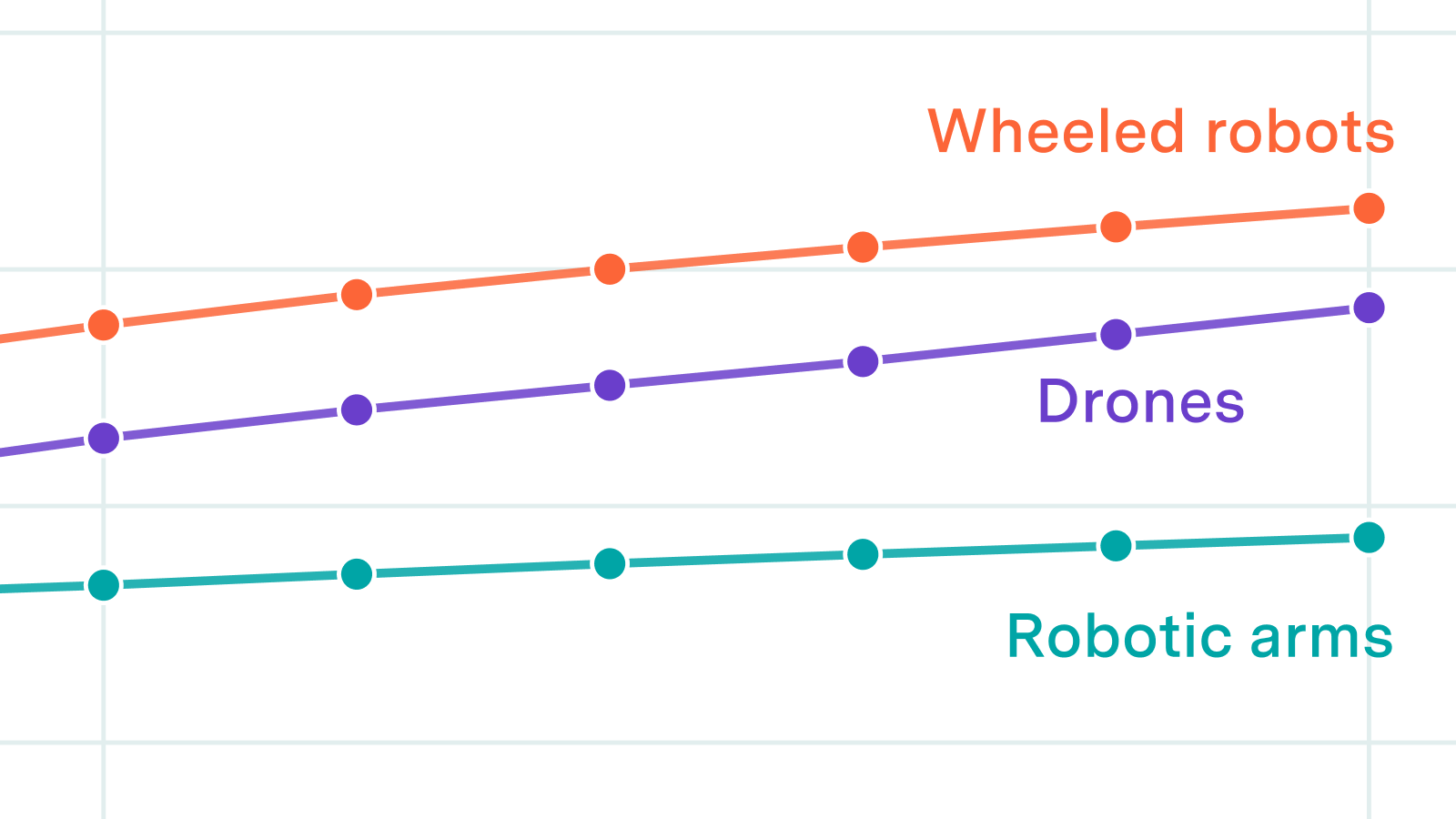
We look at reference classes, factory buildout timelines, and upstream component supply to estimate plausible production rates for humanoids, quadrupeds, robotic arms, wheeled robots, and drones.
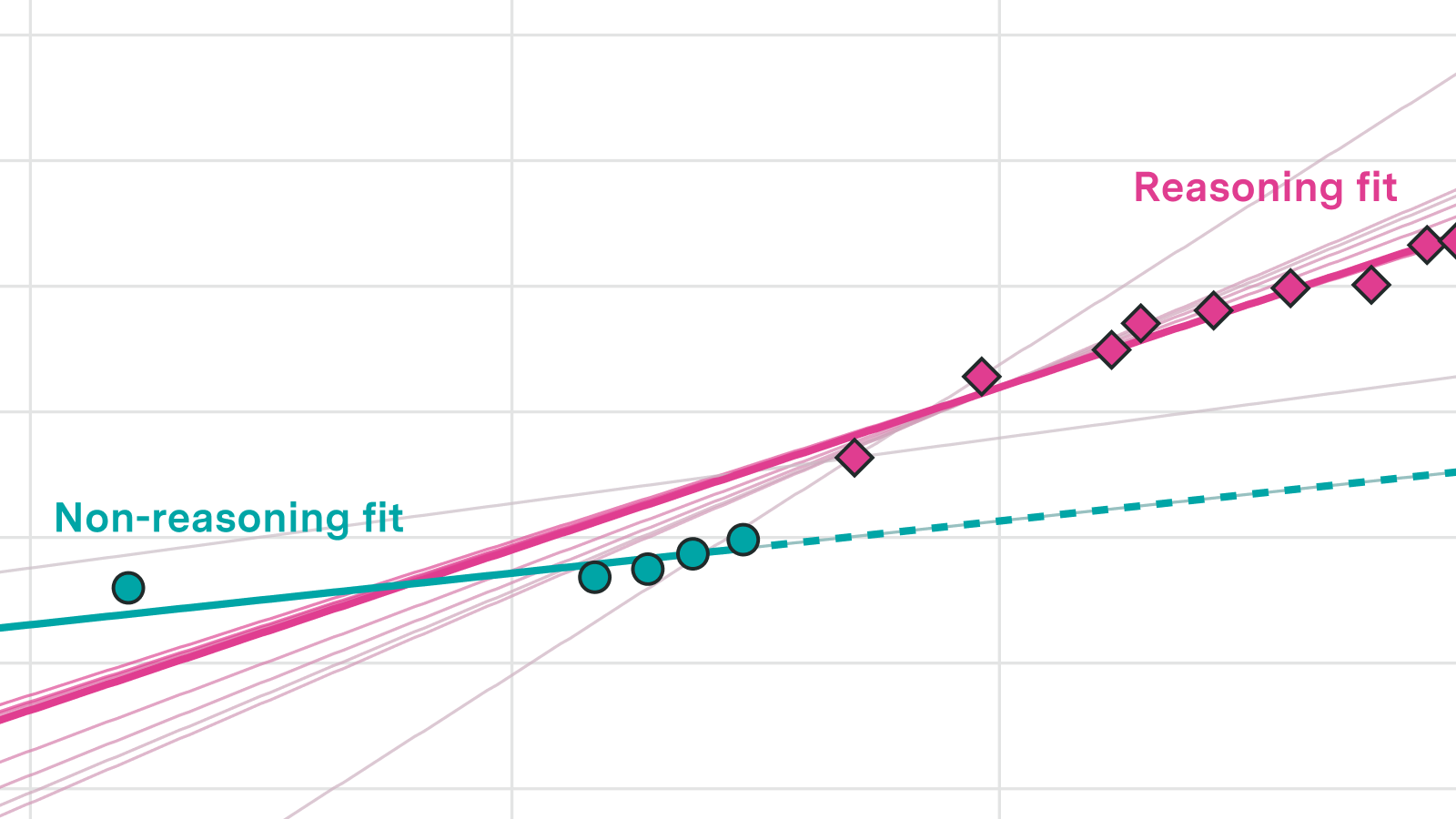
We investigate progress trends on four capability metrics to determine whether AI capabilities have recently accelerated. Three of four metrics show strong evidence of acceleration, driven by reasoning models.
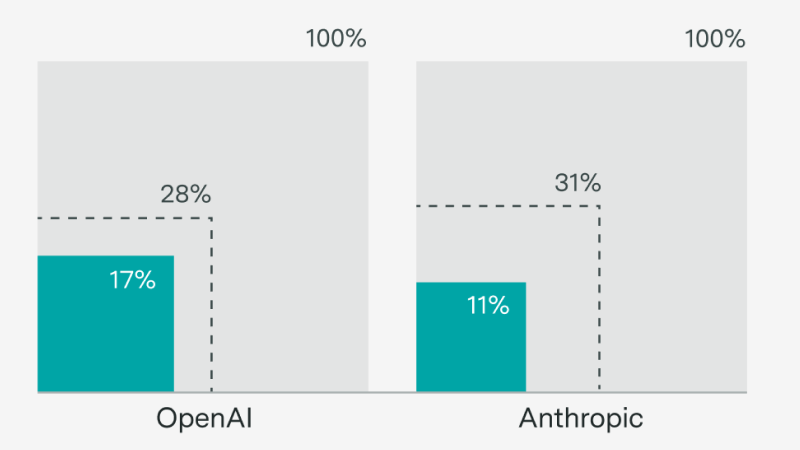
A fast increase in go-to-market roles, and hints about upcoming products
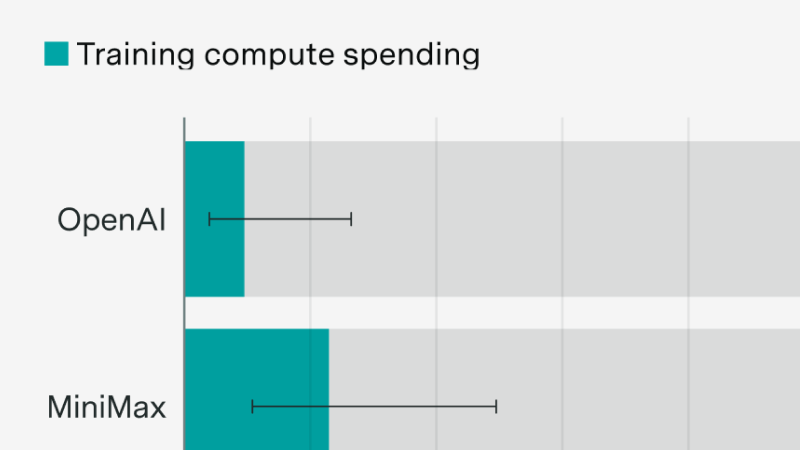
New evidence following the MiniMax and Z.ai IPOs
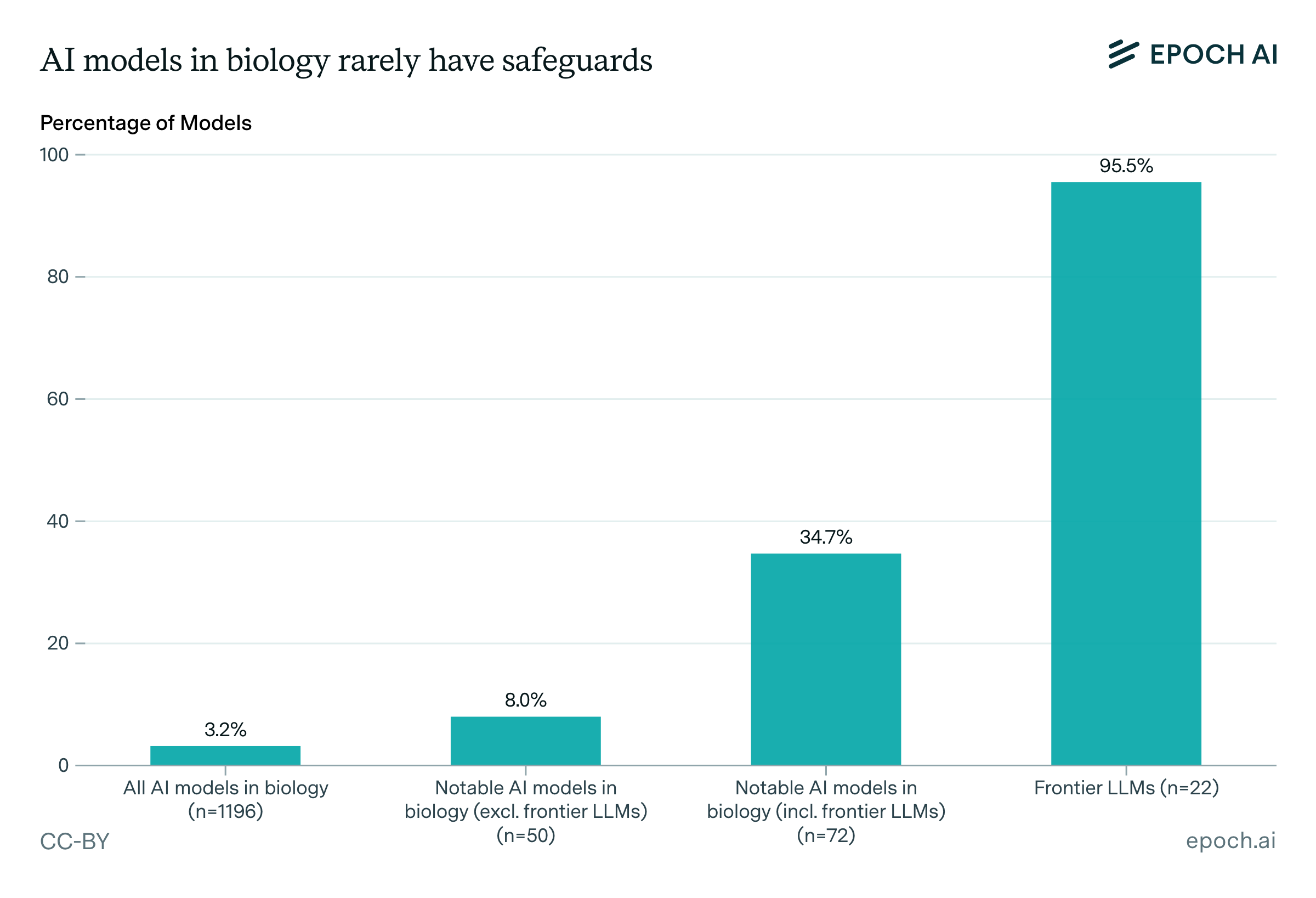
We release a database of over 1,100 biological AI models across nine categories. We analyze their safeguards, accessibility, training data sources, and the foundation models they build on.
Toby Ord argues that RL scaling primarily increases inference costs, creating a persistent economic burden. While the framing is useful, the cost to reach a given capability level falls fast, and the RL scaling data is thin.

We assess the current state of autonomous robotics by evaluating robot performance on concrete tasks across industrial, household, and navigation domains.
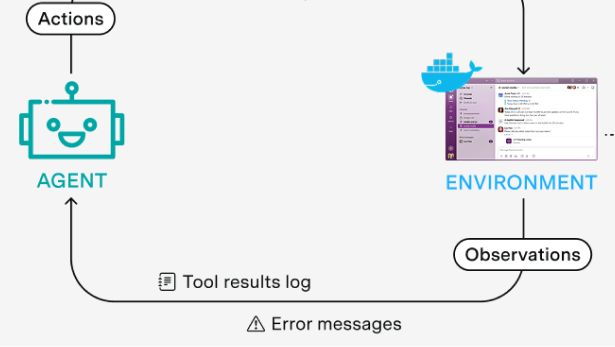
We interviewed 18 people across RL environment startups, neolabs, and frontier labs about the state of the field and where it's headed.
Running benchmarks involves many moving parts, each of which can influence the final score. The two most impactful components are scaffolds and API providers.
Public data as well as our original polling suggest LLM adoption is roughly on trend, but the underlying drivers are shifting.

Why power is less of a bottleneck than you think.

Most benchmarks saturate too quickly to study long-run AI trends. We solve this using a statistical framework that stitches benchmarks together, with big implications for algorithmic progress and AI forecasting.

OpenAI has the inference compute to deploy tens of millions of digital workers, but only on a narrow set of tasks – for now.
OpenAI focused on scaling post-training on a smaller model
Continual learning, scaling RL, and research feedback loops
Many multi-agent setups are based on fancy prompts, but this is unlikely to persist
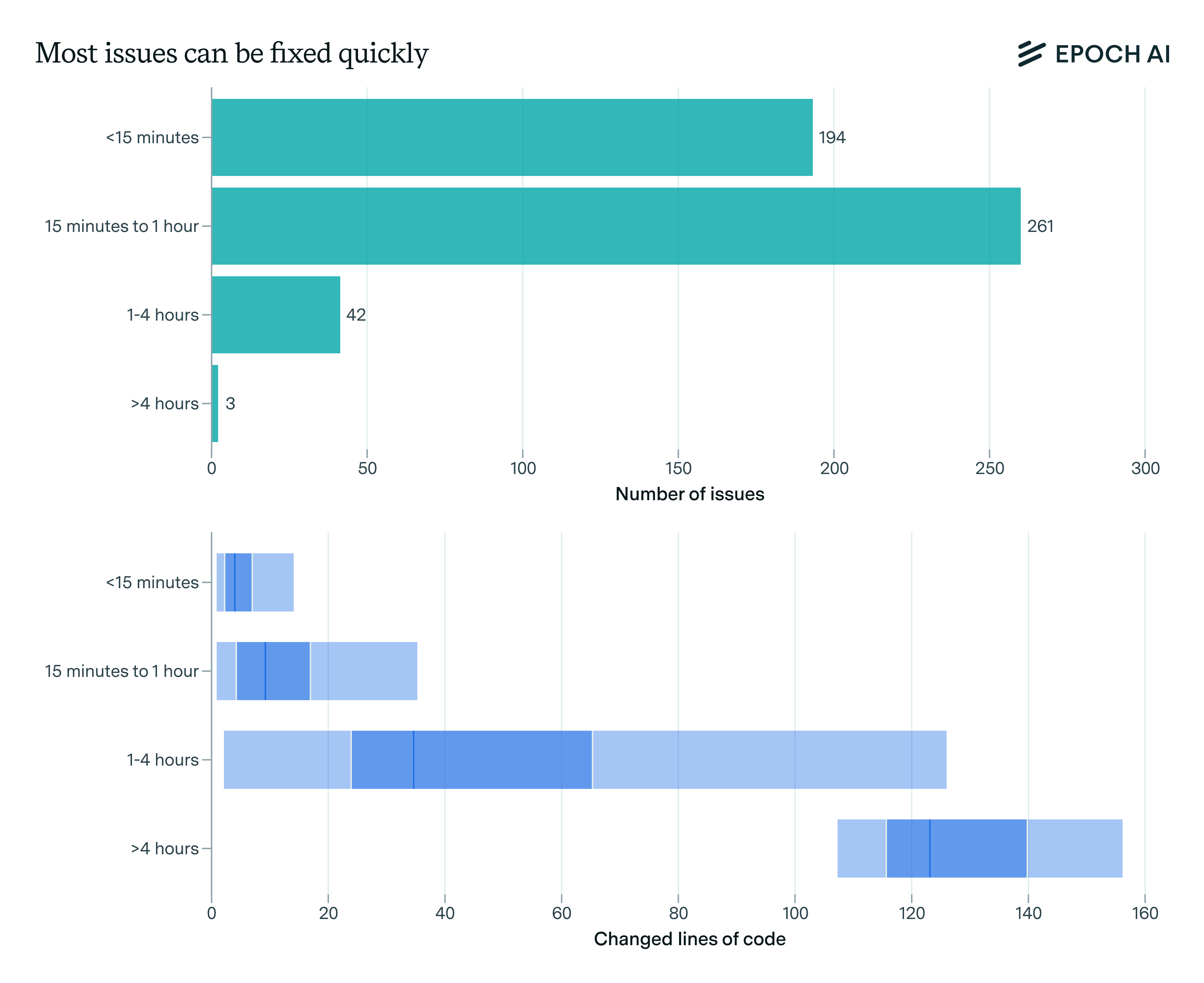
We take a deep dive into SWE-bench Verified, a prominent agentic coding benchmark. While one of the best public tests of AI coding agents, it is limited by its focus on simple bug fixes in familiar open-source repositories.
Examining o3-mini's math reasoning: an erudite, vibes-based solver that excels in knowledge but lacks precision, creativity, and formal human rigor.
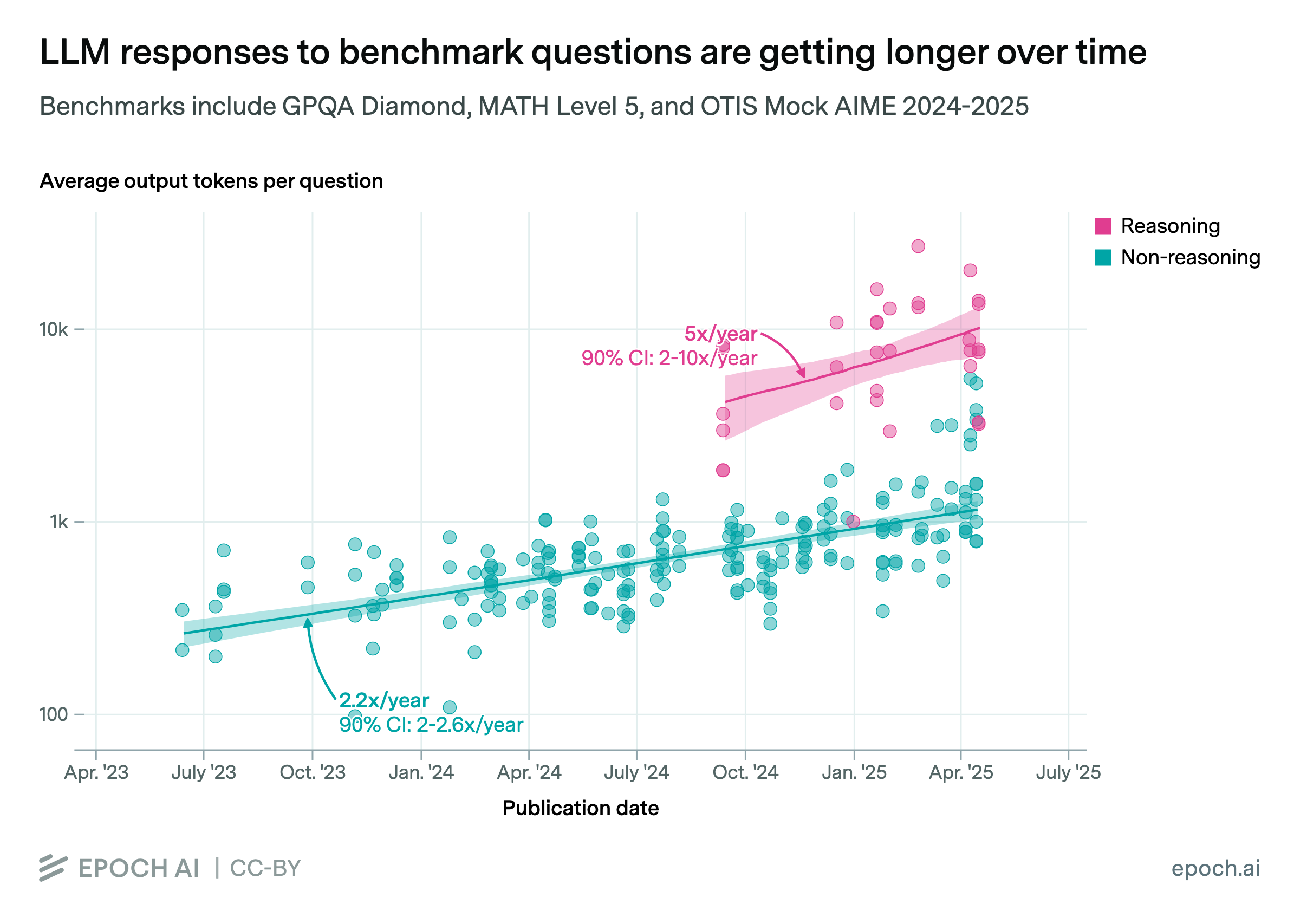
The real reason that AI benchmarks haven’t reflected real-world impacts historically is that they weren’t optimized for this, not because of fundamental limitations – but this might be changing.
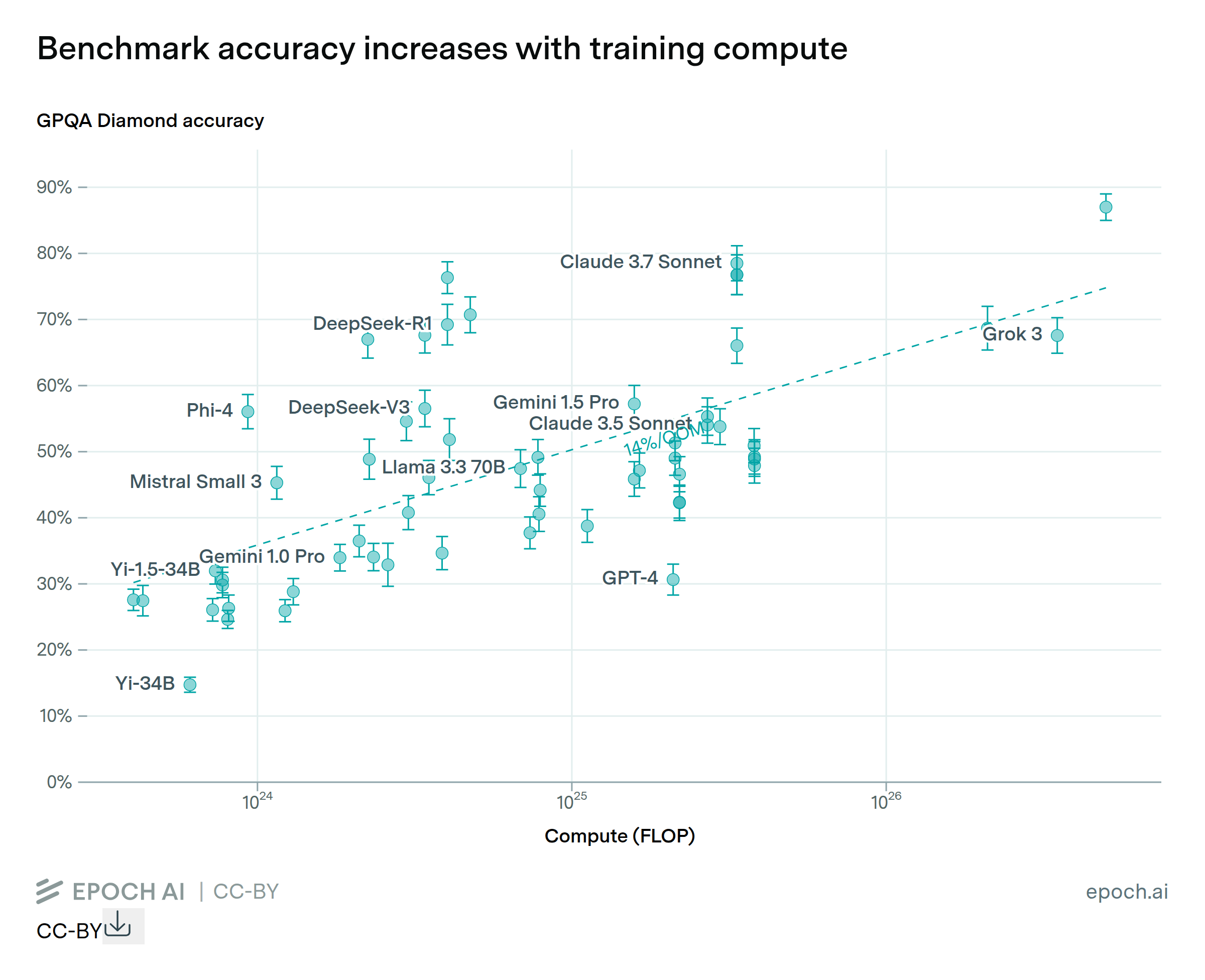
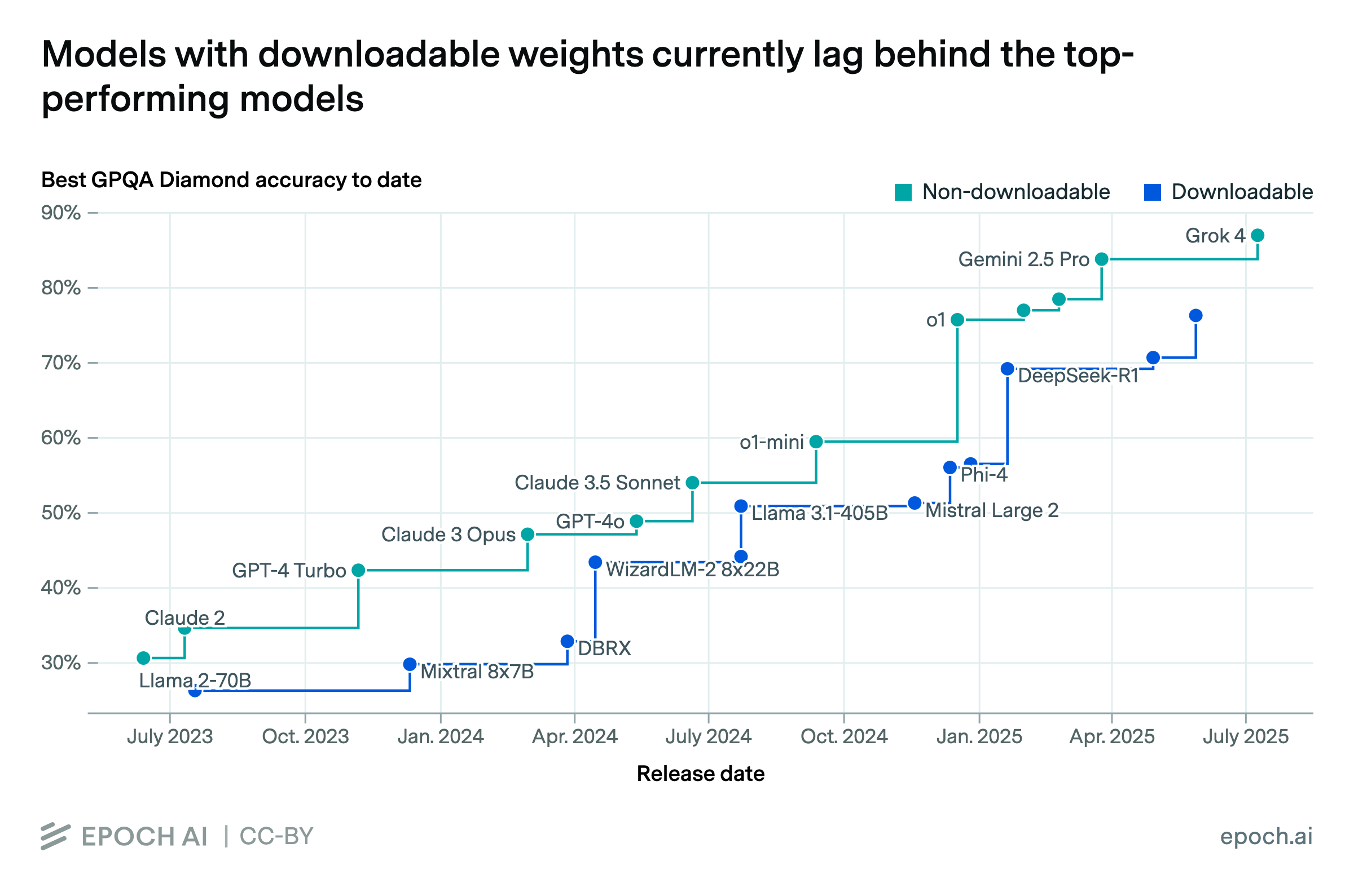
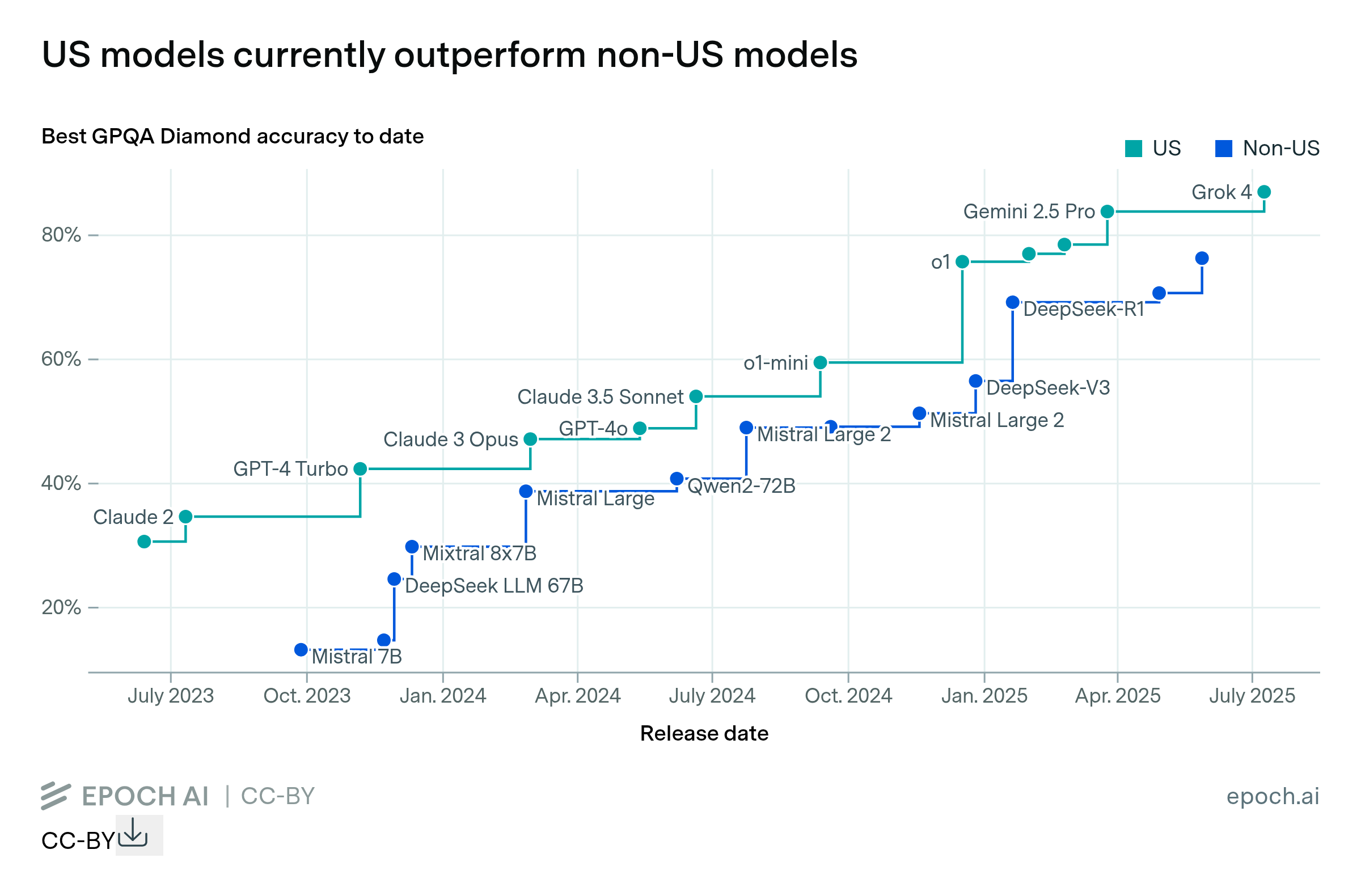
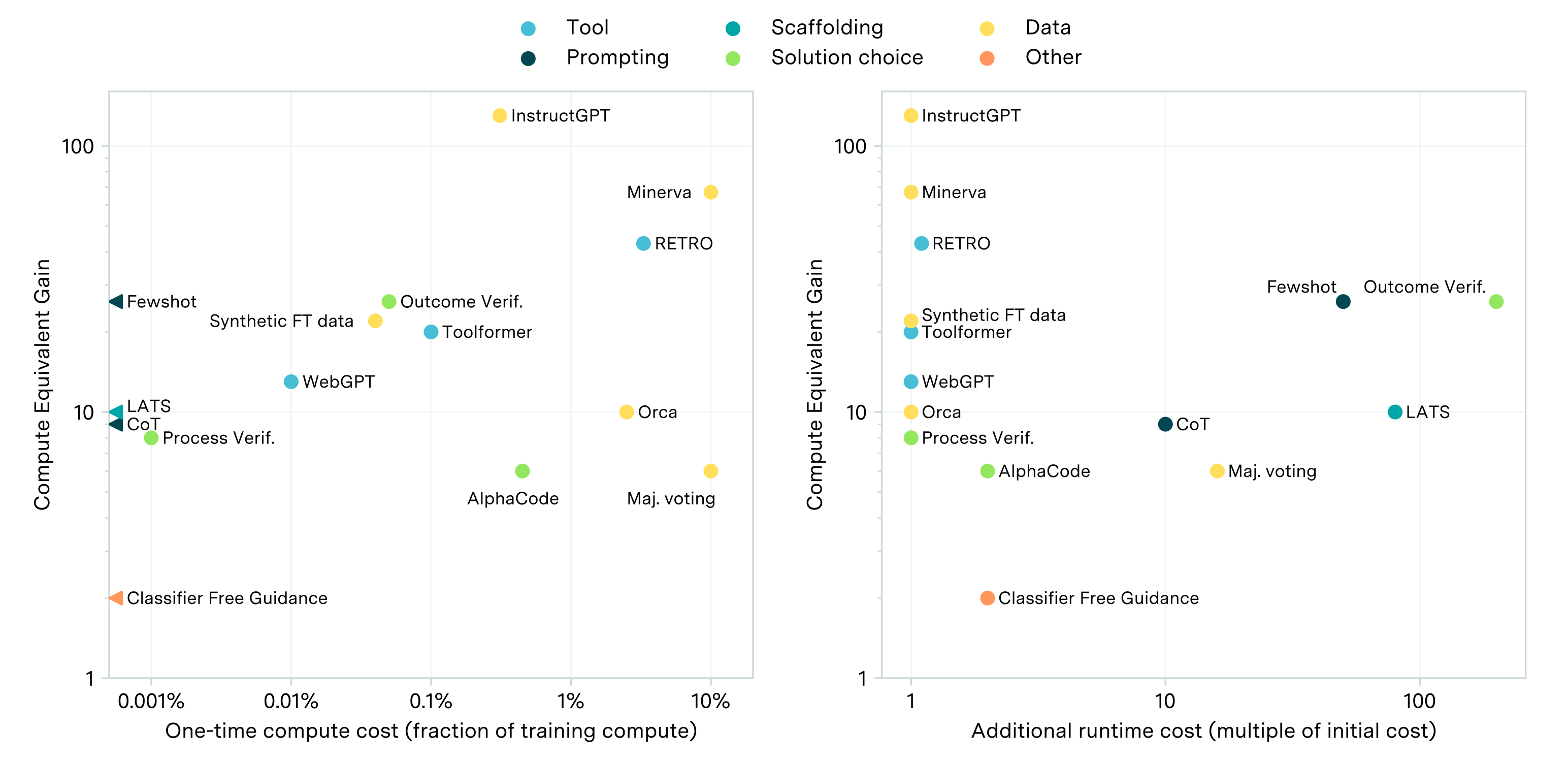
While scaling compute for training is key to improving LLM performance, some post-training enhancements can offer gains equivalent to training with 5 to 20x more compute at less than 1% the cost.