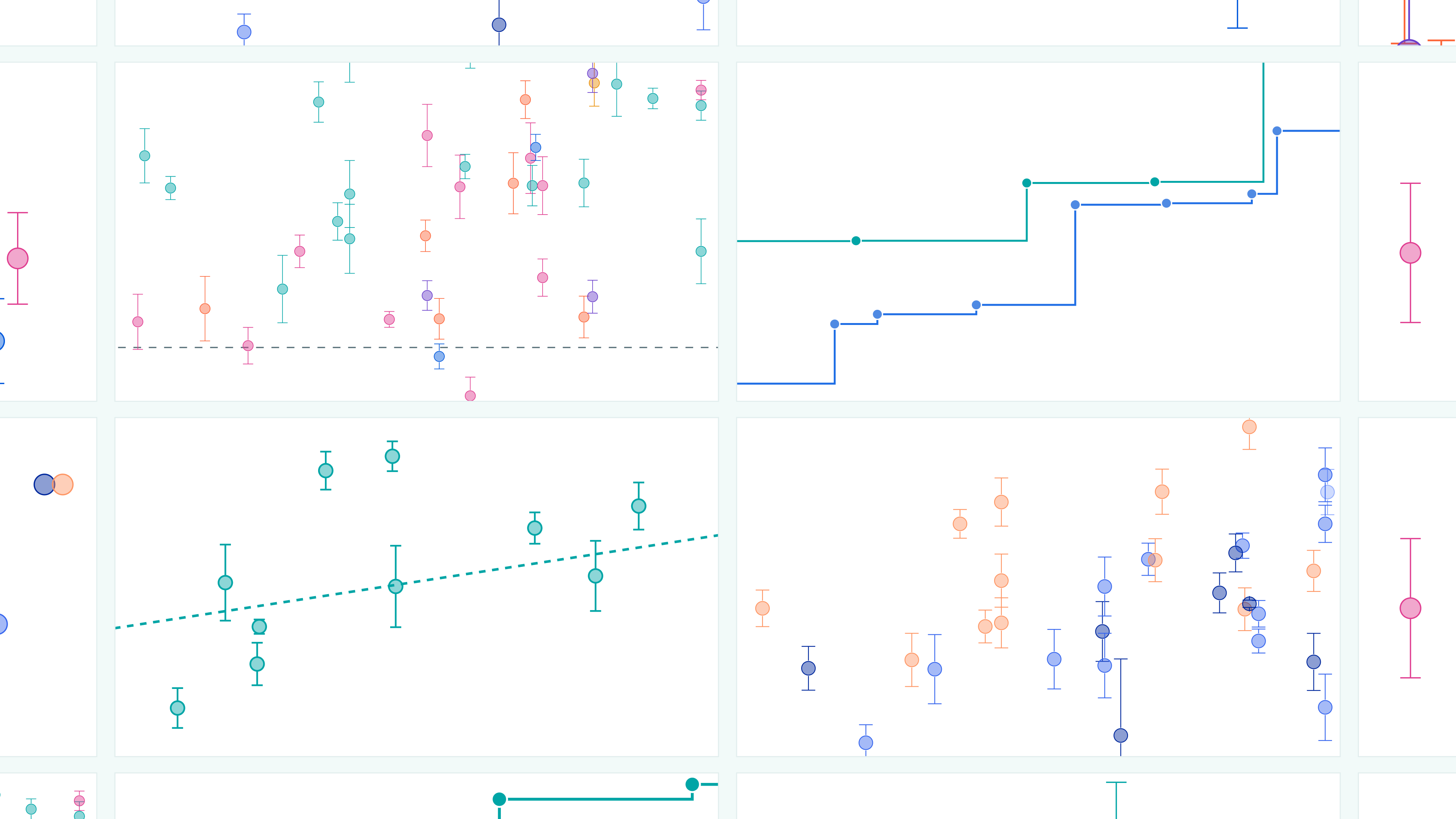

Introduction
Back in November, we released the Epoch AI Benchmarking Hub. This platform hosts the results of evaluations of notable AI models conducted by Epoch AI, including visualizations and additional analysis. Its goal is to shed light on what today’s AI systems are capable of—and where they are headed. Data on the platform is publicly accessible under a permissive license, allowing other members of the research community to use it for their own analyses.
Today, we are publishing a major update of the Benchmarking Hub. Our visualizations still look very similar, but we have completely overhauled the process by which we run AI benchmarks and share results. We’ve made significant engineering investments in our infrastructure that allow us to be more transparent, systematic, and up-to-date.
The most noticeable changes for you as a user are:
- You have access to richer data about each evaluation and the model being evaluated
- The database will be much more frequently updated
Key features of the AI Benchmarking Hub
Our database fills a gap in the publicly available data about AI benchmark performance by being:
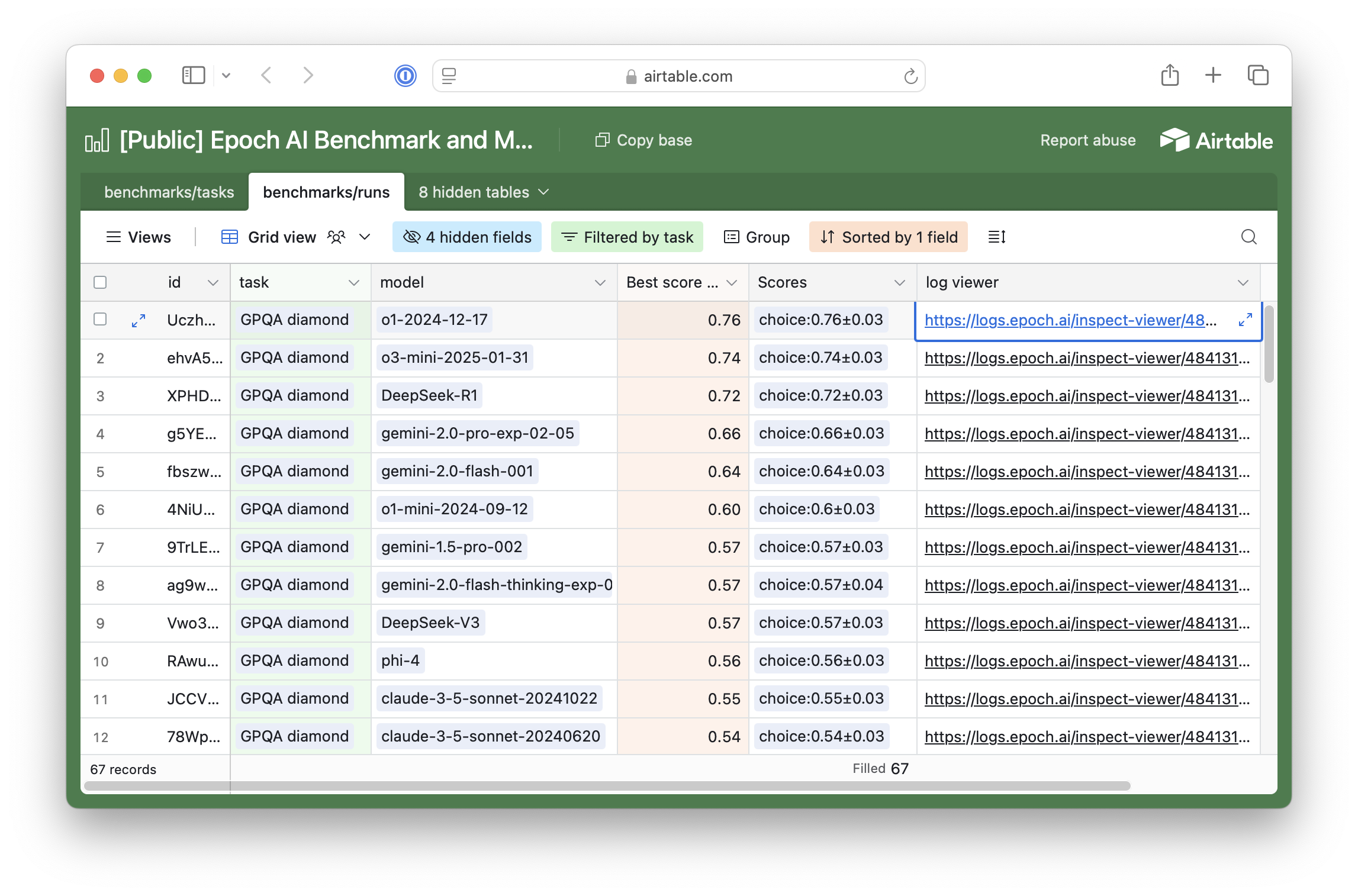
Transparent. We store not just the average score on a benchmark, but also a comprehensive record of the prompt, AI response, and score for each question. We display this information in the interactive log viewer provided by the Inspect library. For example, click here for DeepSeek R1’s results on GPQA Diamond.
Furthermore, we share the code used to run and score the evaluation. At the moment, we do this approximately by sharing static GitHub gists that may have minor differences. Internally, our system provides full auditability by linking each evaluation with the exact git revision it was run with. We plan to make this available publicly soon.
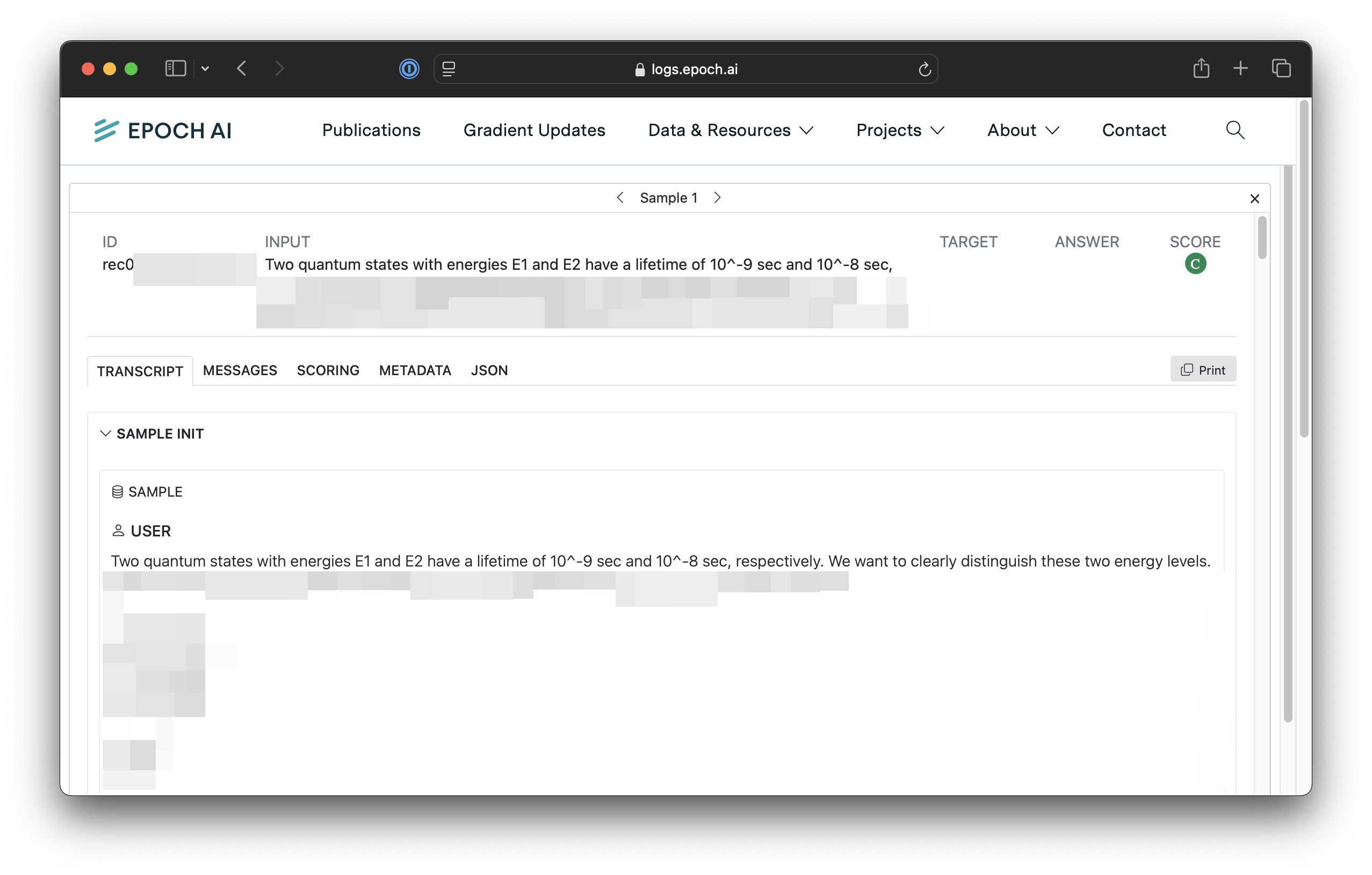
The Inspect log viewer showing a sample from the evaluation of DeepSeek R1 on GPQA Diamond. To mitigate the risk of accidental leakage into LLM training corpora, bots are prevented from accessing the log viewer, so you will need to solve a CAPTCHA to access it.
Systematic. We run benchmarks across a wide range of models, not just a few recent ones. This helps us study broad trends in AI capabilities. We cover recent as well as older models, small models and large models. We track both open and proprietary models.
Up to date. Some benchmarking databases or leaderboards are updated infrequently or no longer maintained. We have the capability to add results for new models to our database quickly after they are released (in many cases, results will be added the day a model is released). We will expand the set of benchmarks and continue to maintain and improve this database.
Integrated with our data about AI models. Each evaluation is linked to detailed information we collect about the model, including its release date, the organization behind it, and in some cases our estimate of the amount of computation used to train the model.
The Epoch AI client library
Today, we are also releasing the open-source Epoch AI Python client library (pip install epochai). This library offers an additional way to access our data: via the Airtable API.
The library comes with some example scripts for common tasks, e.g. tracking the best-performing model for a benchmark over time or showing the performance ranking on a benchmark.
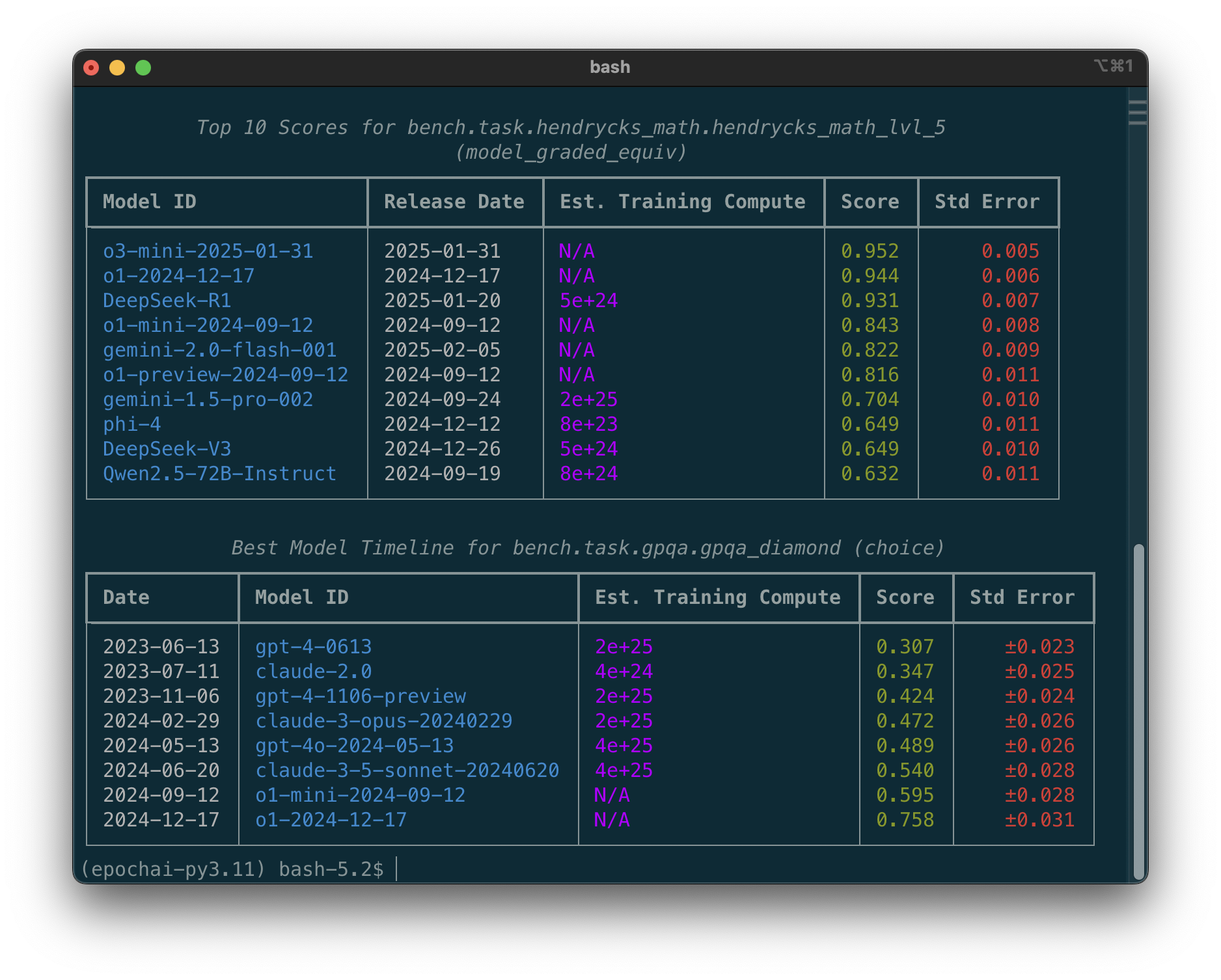
The library makes it easy to query relationships between benchmark results and other entities in our database, like release dates, our estimates of training computation, the organization that released the model, and so on.
Evaluation platform
We use the UK Government’s open-source Inspect library. Inspect is a powerful platform that helps us rapidly implement evaluations, collect comprehensive information about evaluation settings, and display that information in Inspect’s log viewer.
Our benchmark implementations draw on Inspect Evals, a repository of community-contributed LLM evaluations for Inspect.
Next steps
Our first priority is to expand the Hub to add more benchmarks, starting with FrontierMath, our benchmark of challenging mathematics problems.
Stay tuned for regular updates as we continue to expand our benchmark suite and model coverage.
About the authors
Related work