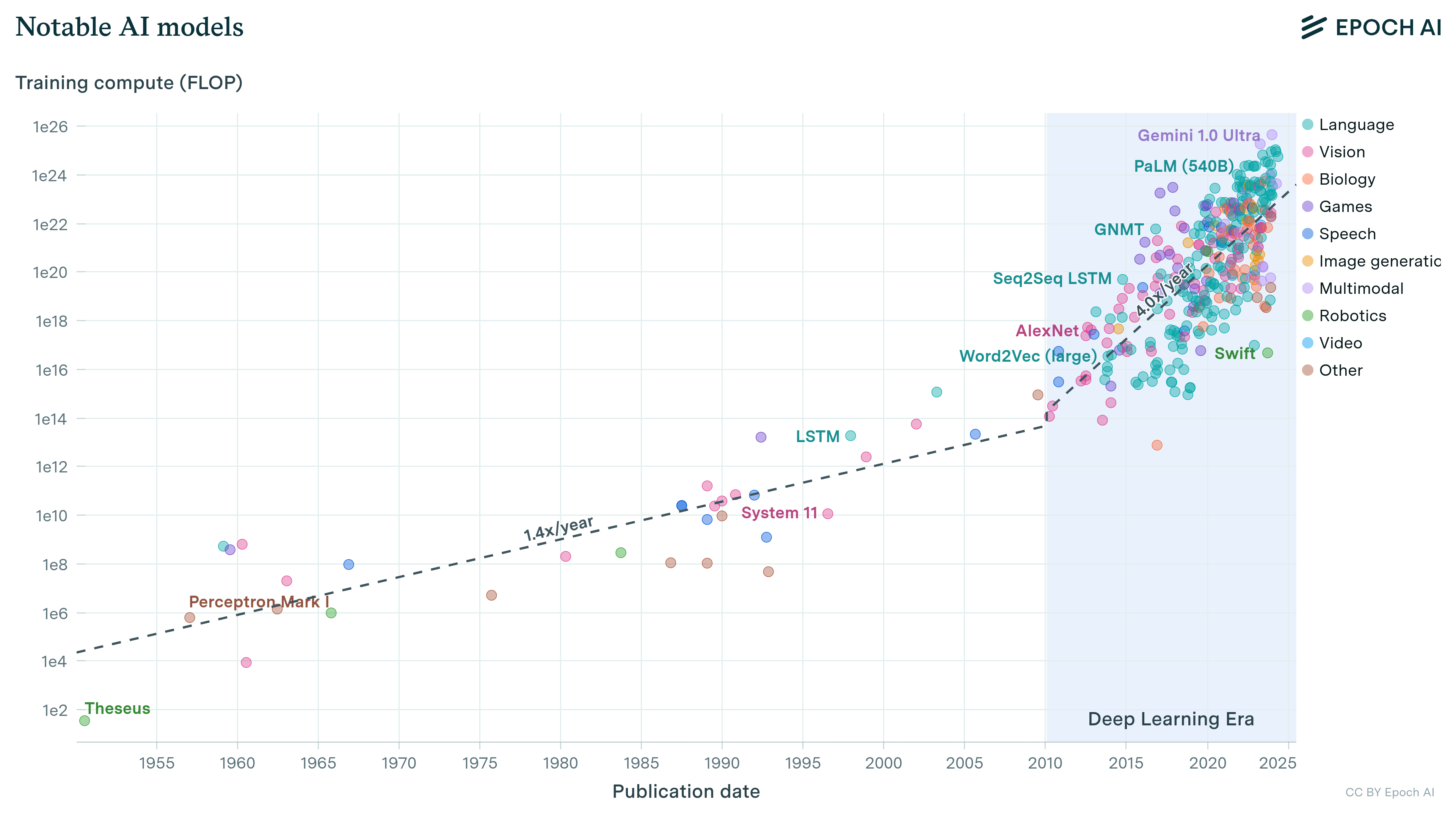
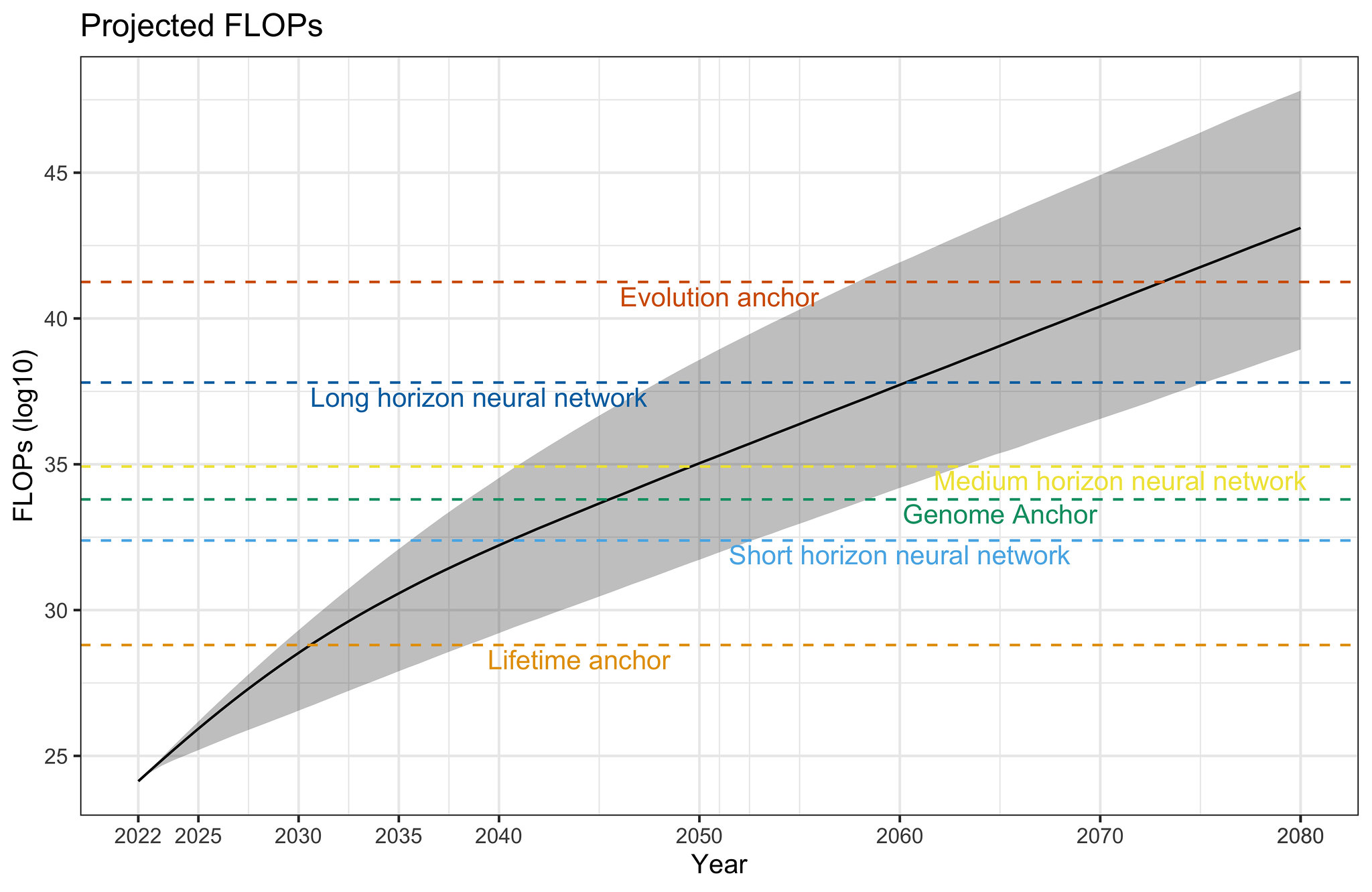
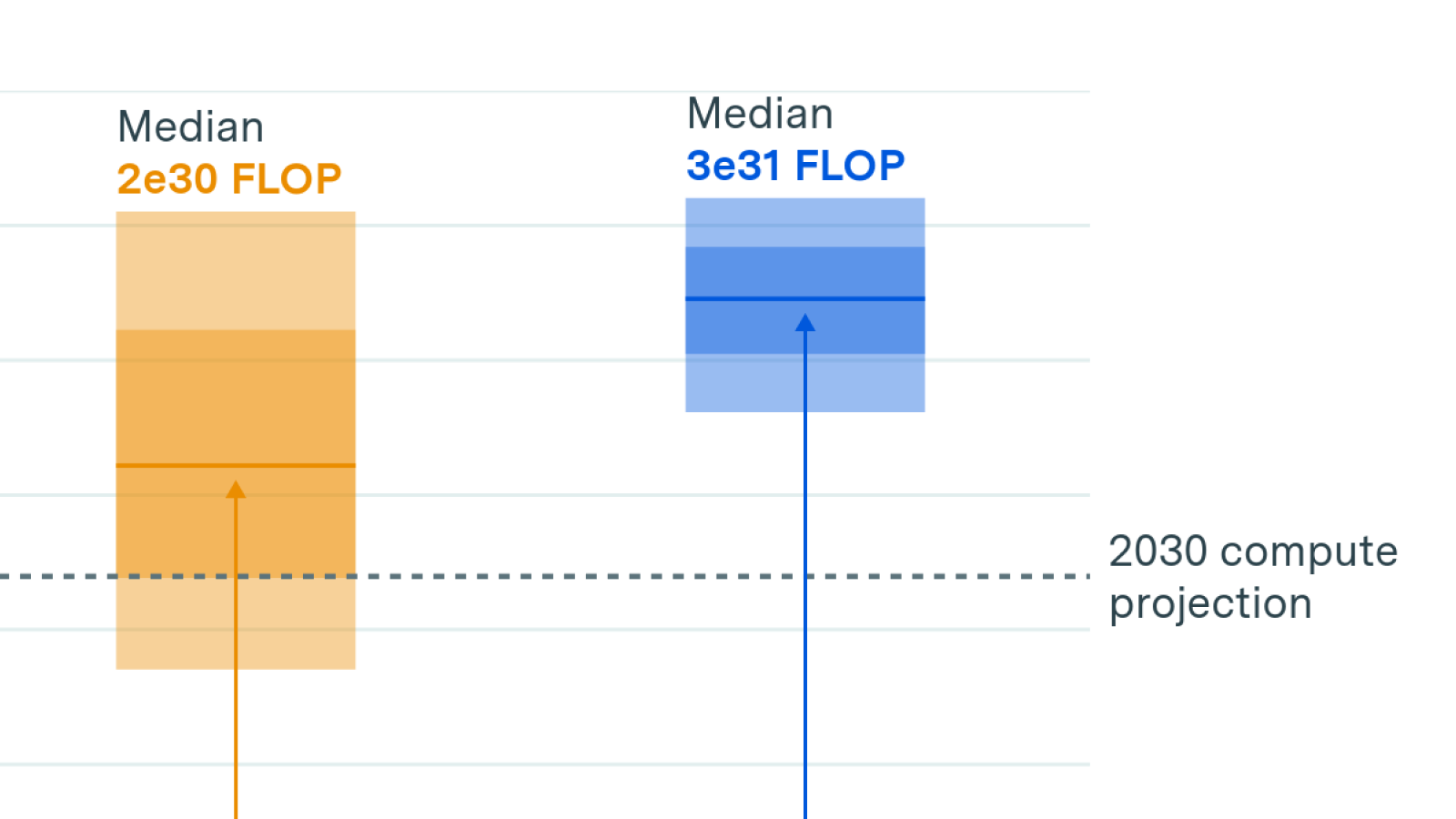
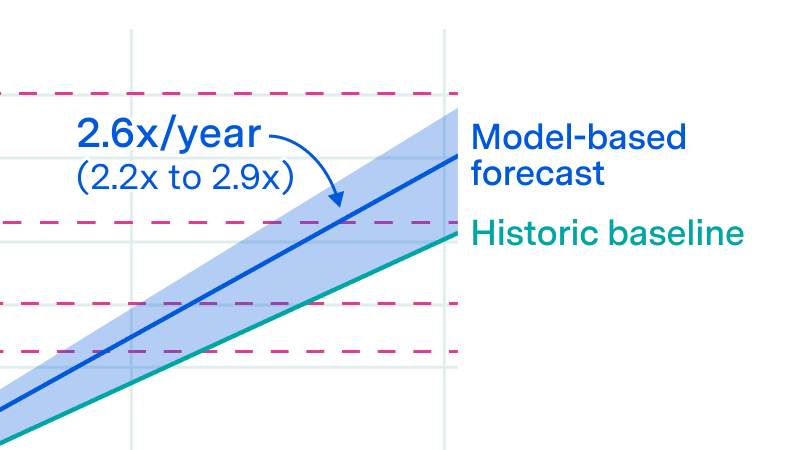
Previous work: Grokking “Forecasting TAI with biological anchors“, Grokking “Semi-informative priors over AI timelines”
Highlights
- The review includes quantitative models, including both outside and inside view, and judgment-based forecasts by (teams of) experts.
- While we do not necessarily endorse their conclusions, the inside-view model the Epoch AI team found most compelling is Ajeya Cotra’s “Forecasting TAI with biological anchors”, the best-rated outside-view model was Tom Davidson’s “Semi-informative priors over AI timelines”, and the best-rated judgment-based forecast was Samotsvety’s AGI Timelines Forecast.
- The inside-view models we reviewed predicted shorter timelines (e.g. bioanchors has a median of 2052) while the outside-view models predicted longer timelines (e.g. semi-informative priors has a median over 2100). The judgment-based forecasts are skewed towards agreement with the inside-view models, and are often more aggressive (e.g. Samotsvety assigned a median of 2043).
Introduction
Over the last few years, we have seen many attempts to quantitatively forecast the arrival of transformative and/or general Artificial Intelligence (TAI/AGI) using very different methodologies and assumptions. Keeping track of and assessing these models’ relative strengths can be daunting for a reader not familiar with the field. As such, the purpose of this review is to:
- Provide a relatively comprehensive source of influential timeline estimates, as well as brief overviews of the methodologies of various models, so readers can make an informed decision over which seem most compelling to them.
- Provide a concise summarization of each model/forecast distribution over arrival dates.
- Provide an aggregation of internal Epoch AI subjective weights over these models/forecasts. These weightings do not necessarily reflect team members’ “all-things-considered” timelines, rather they are aimed at providing a sense of our views on the relative trustworthiness of the models.
For aggregating internal weights, we split the timelines into “model-based” and “judgment-based” timelines. Model-based timelines are given by the output of an explicit model. In contrast, judgment-based timelines are either aggregates of group predictions on, e.g., prediction markets, or the timelines of some notable individuals. We decompose in this way as these two categories roughly correspond to “prior-forming” and “posterior-forming” predictions respectively.
In both cases, we elicit subjective probabilities from each Epoch AI team member reflective of:
- how likely they believe a model’s assumptions and methodology to be essentially accurate, and
- how likely it is that a given forecaster/aggregate of forecasters is well-calibrated on this problem,
respectively. Weights are normalized and linearly aggregated across the team to arrive at a summary probability. These numbers should not be interpreted too literally as exact credences, but rather a rough approximation of how the team views the “relative trustworthiness” of each model/forecast.
Caveats
- Not every model/report operationalizes AGI/TAI in the same way, and so aggregated timelines should be taken with an extra pinch of salt, given that they forecast slightly different things.
- Not every model and forecast included below yields explicit predictions for the snapshots (in terms of CDF by year and quantiles) which we summarize below. In these cases, we have done our best to interpolate based on explicit data-points given.
- We have included models and forecasts that were explained in more detail and lent themselves easily to a probabilistic summary. This means we do not cover less explained forecasts like Daniel Kokotajlo’s and influential pieces of work without explicit forecasts such as David Roodman’s Modelling the Human Trajectory.
Results
Model based forecasts
See this appendix for the individual weightings from respondents and the rationale behind their aggregation.
(Italicized values are interpolated from a gamma distribution fitted to known values. Note that this extrapolation has an important subjective component and we expect it will not correctly capture the beliefs of the respondents in some important ways.)
Judgment based forecasts
See this appendix for the individual weightings from respondents and the rationale behind their aggregation.
(Italicized values are interpolated from a gamma distribution fitted to known values. Note that this extrapolation has an important subjective component and we expect it will not correctly capture the beliefs of the respondents in some important ways.)
| Timeline | Probability of TAI/AGI by… | Quantile | Subjective weight1 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2030 | 2050 | 2100 | 10% | Median | 90% | |||||
| Model-based | ||||||||||
| Ajeya Cotra’s bio anchors | 8% | 47% | 78% | 2031 | 2052 | >2100 | 0.50 | |||
| Semi-informative priors | 6% | 11% | 20% | 2044 | >2100 | >2100 | 0.28 | |||
| Insights-based model | 4% | 8% | 15% | 2060 | >3000 | >3000 | 0.03 | |||
| Whole Brain Emulation | 1% | 25% | 88% | 2047 | 2064 | >2100 | 0.03 | |||
| Phase transitions and AGI | 3% | 8% | 21% | 2042 | >2100 | >3100 | 0.16 | |||
| Weighted Linear Average of Probabilities | 8% | 27% | 54% | 2032 | 2089 | 3022 | ||||
| Judgment-based | ||||||||||
| AI Impacts survey (2022) | 12% | 40% | 74% | 2029 | 2059 | 2148 | 0.08 | |||
| Metaculus | 29% | 63% | 83% | 2025 | 2039 | 2193 | 0.23 | |||
| Samotsvety report | 28% | 60% | 89% | 2024 | 2043 | 2104 | 0.40 | |||
| Ajeya Cotra | 15% | 60% | 97% | 2026 | 2040 | 2077 | 0.17 | |||
| Holden Karnofsky | 24% | 44% | 67% | 2024 | 2060 | 2241 | 0.12 | |||
| Weighted Geometric Average of Odds | 25% | 57% | 88% | 2025 | 2045 | 2107 | ||||
Weights to use when calculating each average:
Model-based forecasts:
Judgment-based forecasts:
Model-based forecasts
Model-based forecasts involve specifying an explicit model for TAI/AGI arrival dates and estimating parameters. They can loosely be divided up into “inside-view” and “outside-view” models, with the former taking into account more granular data on, e.g., compute and algorithmic progress, and the latter focusing on more big-picture base-rates.
Forecasting TAI with biological anchors (inside view)
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 8% | 47% | 78% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2031 | 2052 | >2100 |
The approach of this report is to forecast TAI timelines by taking cues from the computational work required to create general intelligence in nature, and extrapolating economic trends to estimate when training a model with equivalent modern-day compute resources would be feasible. The main inputs to the model are:
- Choice of “bio-anchor” to benchmark necessary computation to – these include computation in the brain across a human lifetime, total computation performed by evolution to create a human brain, and the number of parameters in the human brain or human genome. For bio-anchors relating to model size (e.g., the human brain), the report also investigates a range of “effective horizons” – crudely speaking, how much thinking a model will have to do on each forward pass – to estimate total compute required to train such a model effectively.
- Estimate of future compute availability, to assess when the compute requirements of part (1.) will be economically feasible. This estimate itself is decomposed into three main ingredients: (a) rate of algorithmic progress, i.e., training compute efficiency, (b) reduction in hardware/compute costs, (c) greater willingness to spend on compute for training ML models.
Estimates for total computational requirements are understandably very wide given the different approaches and the sources of uncertainty even within each approach, spanning several orders of magnitude (e.g., 10^24 on the lower end of the human-lifetime bio-anchor to 10^52 on the upper end of the evolution anchor). The report weights these various models to arrive at an overall distribution over compute requirements, which is combined with economic estimates to give a range over possible TAI arrival dates.
Semi-informative priors over AI timelines (outside view)
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 6% | 11% | 20% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2044 | >2100 | >2100 |
This approach takes an extremely “outside view” approach to forecasting AI, effectively asking what our probability of TAI by a given year would be given only (a) a reasonable prior over timelines one would have at the very beginning of research towards AI, (b) knowledge of the inputs to subsequent AI research over time (compute, researcher hours, etc.), and (c) the fact that AI has not yet been achieved.
For concreteness, the author focuses on the estimate on P(AI by 2036 | No AI by 2020), and models the problem by looking at generalizations of Laplace’s Rule of Succession – a formula for estimating the probability of success of a trial given historical data on trials and their successes. Here we model AI research as a series of “trials” to create AI, each of which has so far been a failure. The author investigates the effect of a family of update rules, of which Laplace’s Rule is a special case. By choosing an appropriate update rule given a common-sense understanding of the problem (e.g., our initial, “first-trial probability” of succeeding at AI should not be 0.5 as Laplace’s Rule suggests, appropriate reference classes, etc.), we can arrive at a range of “semi-informative priors” over AI timelines. Moreover, given a candidate set of update rules giving semi-informative priors, we can form a hyper-prior over these models and update our weights on them as we observe trials.
Some of the main sources of variance in the model besides choice of update rule, which the author investigates the sensitivity of the model to, are:
- Choice of “start-date” for the period of observation – a natural choice the author discusses is 1956, when the field of Artificial Intelligence is widely accepted to have been born, but other plausible candidates exist and the author investigates the sensitivity of the model to these choices.
- Definition of “trial” – should we count ourselves as observing a failure to create TAI every calendar year? Every month? Every researcher-year?
- Choice of “first-trial” probability – what should our ex-ante probability of immediate success have been at the outset of AI research?
Insight-based AI timelines model (outside view)
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 4% | 8% | 15% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2060 | >3000 | >3000 |
This approach first places a distribution over what fraction of insights/discoveries necessary for AI have so far been achieved, and then extrapolates a CDF of AI arrival dates by assuming a linear progression of insights over time. Users can either specify their precise prior over current insight-based progress towards AI, or else use a Pareto distribution. The authors estimate the linear progress of insight discovery by examining historical data of discoveries deemed to be at least as significant as LSTMs, and fitting a linear regression to the data since 1945. Some key sources of uncertainty and sensitivity in this modeling approach are:
- Choice of prior over insight progress – the CDF is sensitive both to the number of insights assumed to be necessary for AI, as well as the parameters of the chosen Pareto distribution.
- The assumption of linearity is key to this model and there are plausible reasons to doubt this assumption – one could think either that this assumption is optimistic if we have been picking “low-hanging fruit” in our insights so far, or else pessimistic if one thinks increased research investment/effectiveness will speed up the discovery process.
Whole Brain Emulation (inside view)
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 1% | 25% | 88% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2047 | 2064 | >2100 |
This model does not explicitly model the arrival date of TAI, but instead looks at the timelines for when high-fidelity modeling of an entire human brain will be feasible. Since humans are general intelligences, sufficiently cheap WBE would be a transformative source of economic productivity. The paper models the arrival date of WBE technology by decomposing the problem into four questions:
- When will we have sufficient hardware/compute to run a WBE?
- When will we have a project with sufficient funding to afford such compute?
- When will we be able to scan a human brain at sufficient resolution?
- When will we have sufficient understanding of neuroscience to interpret/run a WBE from such a scan?
The author fits parametric models to the above variables using a mixture of historical data and the author’s priors. Using Monte Carlo simulation, WBE arrival date is then modeled as argmaxing over the arrival dates of the necessary components to WBE – i.e., WBE arrives whenever the last key ingredient arrives. Some key sources of uncertainty/sensitivity in this model are:
- The arrivals of components are modeled independently, but there is likely some correlation/endogeneity in the model, e.g., rapid progress in scanning technology will likely accelerate neuroscience progress.
- The components arrival dates are distributed with very subjective probability distributions of the author, and the overall CDF of WBE arrival is very sensitive to some of these choices.
The connection of this paper to overall TAI timelines is also tricky, since affordable WBE is not necessary for TAI. This approach should maybe be thought of as putting an upper bound on TAI arrival dates conditional on other methods such as ML being unsuccessful/very slow. There are also issues with this interpretation, since the progress in WBE is likely not independent of progress in ML, i.e., there will be less economic incentive to develop WBE if we have TAI from another path.
Phase Transitions and AGI (outside view)
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 3% | 8% | 21% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2042 | >2100 | >3100 |
This model takes another outside-view approach, looking at when we should expect qualitative “phase changes” to new and substantially better modes of economic production. The model builds on work by Robin Hanson which investigates the historical frequency of phase changes, and the number of economic doublings that occurred between each. Using this, the approach models a distribution over how many economic doublings we should expect before the next phase change. Some key sources of variance/uncertainty in this approach are:
- Choice of distribution to model the arrival times of phase changes. For instance, the post examines the implications of modeling wait times as exponentially vs. Pareto distributed, with much greater waiting times expected in the latter case due to fatter tails.
- Given a distribution over when a phase change might next occur, inside-view assumptions are required to turn this into a distribution over AI timelines, by, e.g., estimating the probability that the next phase change will be caused by – or will soon lead to – TAI.
Judgment-based forecasts
Judgment-based forecasts are subjective timelines in which predictions are given by an individual or group of individuals without an explicit model. They may be incorporating model-based timelines as inputs to their predictions, and should be viewed as more of an “all-things considered” prediction than model-based forecasts. We mainly include aggregated timelines from experts and/or forecasters, but have included timelines from individuals if they are both explicit and influential.
AI Impacts Survey (2022)
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 12% | 40% | 74% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2029 | 2059 | 2148 |
AI Impacts researches trends in AI development. 738 researchers who published either in NeurIPS or ICML (leading AI conferences) in 2021 provided forecasts on a number of AI-related questions, from arrival date to expected impact of AI on various professions. It should be noted that the survey was sent to 4271 researchers initially, for a 17% response rate. As such, there may be some sampling bias in these numbers, e.g., if researchers with more aggressive timelines are also more inclined to respond to such surveys.
Metaculus: Date of Artificial General Intelligence as of 2022-10-11
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 29% | 63% | 83% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2025 | 2039 | 2193 |
Metaculus is a platform aggregating user predictions on a variety of forecasting questions, including a number relating to AI development. Historically the performance of forecasters on Metaculus has been strong (https://www.metaculus.com/questions/track-record/), but for obvious reasons the accuracy of users’ long-term AI forecasting specifically is unclear. As of writing there are 314 distinct forecasters whose predictions have been aggregated into this projection.
Samotsvety’s AGI Timelines Forecasts
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 28% | 60% | 89% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2024 | 2043 | 2104 |
Samotsvety are a team of forecasters selected for strong performance on Metaculus and various forecasting contests. Their track record can be found here. Eight people from their team submitted forecasts for the date at which “a system capable of passing the adversarial Turing test against a top-5% human who has access to experts on various topics is developed.”
Note: This report was initially published prior to the most recent update of Samotsvety timelines. Although all numbers have been updated to reflect the newer forecasts, it might be of interest to readers that the timelines implied here are significantly shorter than those of the original Samotsvety report (cf. September 2022). The updated post elaborates on some reasons, but a large factor seems to be an overall shift away from outside-view models to inside-view ones - where the latter as we have noted tend to have more aggressive timelines.
Note: The numbers found here differ slightly from the aggregates listed in Samotsvety’s post. In a process analogous to the one described in this appendix, we fit CDFs to each individual forecast, and combined them using the geometric mean of odds. You can see that process implemented here.
Two-year update on my personal AI timelines
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 15% | 60% | 97% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2026 | 2040 | 2077 |
This is a forecast by Ajeya Cotra, the author of the Bio-anchors model discussed above. Here she discusses her updated timelines in response to factors such as (a) lowering her estimate of what would be considered TAI, increased probability of scaling Deep Learning taking us to TAI, etc. The resultant timelines are shorter than her initial bottom-lines in her first Bio-anchors report, but are still derived using the same model so readers’ updates on this second report will largely be a function of (a) how much they put weight on this model to begin with, and (b) to what extent the evidence Cotra is updating on was already incorporated by readers in her initial modeling.
Forecasting transformative AI: what’s the burden of proof?
| Probability of TAI/AGI by… | ||
|---|---|---|
| 2030 | 2050 | 2100 |
| 24% | 44% | 67% |
| Quantile | ||
|---|---|---|
| 10% | Median | 90% |
| 2024 | 2060 | 2241 |
Holden Karnofsky writes a short series of posts explaining his reasoning around AI timelines, drawing from a number of the models discussed above. Karnofsky’s conclusion: “I think there’s more than a 10% chance we’ll see … ‘transformative AI’ within 15 years (by 2036); a ~50% chance we’ll see it within 40 years (by 2060); and a ~2/3 chance we’ll see it this century (by 2100).” Although timelines are given, the piece is less focused on explicitly modeling timelines than it is on dealing with “meta-level” arguments around the fruitfulness and tractability of modeling/forecasting long-term AI trends.
Note: To produce our extraplation, we fit the two points given explicitly (for 2060 and 2100) with the method described in the appendix, ignoring the probability given for 2036. Readers should be aware that we expect this extrapolation to fail to capture some important aspects of the author’s beliefs.
Conclusion
There are a number of radically different approaches to modeling timelines in these forecasts, and we want to stress again that the purpose of this piece is to be descriptive rather than evaluative, and to primarily be a jumping-off point/consolidated source for readers to familiarize themselves with the different approaches and predictions out there.
That being said, there are some notable takeaways from this set of forecasts:
- Due to the vastly different timelines of different model-based forecasts, aggregate timelines are sensitive to subjective weightings, and even more so to choice of aggregation methodology, so these should be taken with a large pinch of salt. This is less of a pronounced effect for aggregating judgment-based timelines due to the lower variance and less heavy tails.
- Among model-based predictions, inside-view models are more aggressive than outside-view models. This is largely driven by the much heavier tails given by outside-view models, with significant probability mass on arrival dates several centuries out. In practice, this most likely corresponds to futures where TAI/AGI requires several as-yet-unforeseen breakthroughs to emerge, in contrast with inside-view models which extrapolate currently-understood input progress.
- Judgment-based forecasts tend to be even more aggressive still, suggesting that peoples’ all-things-considered timelines are influenced by a lot of information or reasoning not contained in any of the explicit models included here. The extent to which timelines here are disagreeing because (a) they put low (or zero) weight on the methodology of the models, or (b) they find the reasoning plausible but have different input parameters (e.g., in the case of the Bio-Anchors model) is unclear. However, it seems likely that most of the judgment-based forecasts are taking an inside-view based on recent ML progress and trends in research inputs rather than an outside-view, which would explain a lot of the gap.
- The models and forecasts Epoch AI has ranked higher are Ajeya Cotra’s biological anchors and Samotsvety’s AGI Timelines Forecasts. Within our team, we are split between people who weight equally outside-view and inside-view models, and people who weight inside-view models more highly.
In the future, we hope to revisit this post to potentially update with any new significant models and/or forecasts.
We thank Zach Stein-Perlman, Misha Yagudin, Ben Cottier and the rest of the Epoch AI team for their comments on this piece. We specially thank the Epoch AI team who contributed their guesses of the relative weights of each forecast.
Appendix: Individual weightings, extrapolation and aggregation
We asked Epoch AI staff to provide subjective weights quantifying the relative trustworthiness of each model and forecast.
For each model and forecast we linearly aggregated the weights. Some comments on patterns in these weights across respondents are given below
| Ajeya Cotra’s bio anchors | Semi-informative priors | Insights-based model | Whole Brain Emulation | Phase transitions | |
|---|---|---|---|---|---|
| Respondent 1 | 0.76 | 0.15 | 0 | 0.02 | 0.08 |
| Respondent 2 | 0.42 | 0.5 | 0.02 | 0.02 | 0.04 |
| Respondent 3 | 0.83 | 0.08 | 0 | 0 | 0.08 |
| Respondent 4 | 0.40 | 0.40 | 0.01 | 0.01 | 0.18 |
| Respondent 5 | 0.14 | 0.43 | 0.07 | 0.07 | 0.29 |
| Respondent 6 | 0.68 | 0.14 | 0.01 | 0.03 | 0.14 |
| Respondent 7 | 0.49 | 0.20 | 0.15 | 0.01 | 0.15 |
| Respondent 8 | 0.46 | 0.30 | 0.02 | 0.04 | 0.18 |
| Average | 0.50 | 0.28 | 0.03 | 0.03 | 0.16 |
| AI Impacts survey (2022) | Metaculus | Samotsvety report | Ajeya Cotra | Holden Karnofsky | |
|---|---|---|---|---|---|
| Respondent 1 | 0.04 | 0.16 | 0.55 | 0.15 | 0.10 |
| Respondent 2 | 0.01 | 0.27 | 0.54 | 0.09 | 0.09 |
| Respondent 3 | 0.06 | 0.18 | 0.24 | 0.47 | 0.06 |
| Respondent 4 | 0.05 | 0.15 | 0.25 | 0.3 | 0.25 |
| Respondent 5 | 0.03 | 0.34 | 0.47 | 0.05 | 0.11 |
| Respondent 6 | 0.14 | 0.14 | 0.29 | 0.21 | 0.21 |
| Respondent 7 | 0.18 | 0.4 | 0.35 | 0.05 | 0.02 |
| Respondent 8 | 0.11 | 0.24 | 0.48 | 0.07 | 0.10 |
| Average | 0.08 | 0.23 | 0.40 | 0.17 | 0.12 |
Now, we use these average weights to combine the different models and forecasts.
For each model or forecast, we fit a Gamma distribution to the known pairs of year and arrival probability. This gives us a CDF, which we can use, together with the other interpolated CDFs, to combine the forecasts into a single aggregate CDF. (This is the same procedure used by AI Impacts’ 2022 expert survey to extrapolate the beliefs of their respondents.) Note that this extrapolation has an important subjective component and we expect it will not correctly capture the beliefs of the respondents in some important ways.
For model-based forecasts, we use a weighted linear average of the CDFs to aggregate the models. Each model starts from different assumptions, so we can decompose the probability as P(TAI) = P(Model 1 assumptions) x P(TAI | Model 1 assumptions)+ … + P(Model N assumptions) x P(TAI | Model N assumptions), using the weight assigned to each model as a proxy for the credence we should give to its assumptions.
When aggregating judgment-based forecasts, we use the weighted, continuous version of the geometric mean of odds to aggregate the forecasts. In this case, we are aggregating all-considered forecasts of experts, so it makes more sense to aggregate their information according to forecasting best practices.
You can find a notebook implementing the process described above here.
Comments on weights
Model-based forecasts:
Bio anchors and semi-informative priors combined were given the majority of weight by all respondents, with the main difference in relative weight being how strongly the respondent preferred inside-view vs. outside-view approaches to the question. Overall, respondents preferred approaches taking an inside-view, although had low weight on the WBE model given how unrelated current AI progress is to brain emulation, and its reliance on compute projections which have not since borne out empirically.
Judgment-based forecasts:
Samotsvety’s report received the most weight from the team, with respondents unanimously scoring it highly. The Metaculus consensus likewise received fairly high weight across the board – both of these being reflective of the fact that most respondents at Epoch AI had familiarity with and relatively high trust in the forecasting capability of these two sources. There was significantly more disagreement over the weights on more general AI researcher consensus, with some of this being explained by differences in how respondents rated the methodology (this being the only forecast from an opt-in survey). The individual forecasts contained in this survey were also given varying weights across respondents, with, e.g., the weighting for Cotra’s personal timeline tending to correlate with the weighting for the Bio anchors model.
-
See this appendix for the individual weightings from respondents and the rationale behind their aggregation.

About the authors



Related work