When trying to forecast future capabilities of AI systems and the economic and social impacts these capabilities will have, there are two different common methods that people use:
-
Look at past AI capabilities along with how fast they’ve changed and try to extrapolate that knowledge to the future.
-
Use first principles reasoning based on the capabilities and resource use of the human brain, the availability of training data across different domains, how expensive it is to get reward signals on different tasks, etc. to estimate the difficulty of automating tasks.
There are further details about how each method may be used in practice, but they represent two fundamentally different ways of forecasting AI capabilities. The first method is often preferred by economists: for instance, Robin Hanson used a variant of it in 2012 by asking AI experts how much progress towards human-level capabilities we had made over the past 20 years and extrapolated their answer to reach human-level AI timelines of a century or longer.
People following this method often assume that the tasks AI will find easiest in the future are the ones that to us look similar to the tasks AI can do at the time they make their forecast. The following quote from Frey and Osborne (2013), an influential economics paper trying to estimate how susceptible different jobs are to computerization, encapsulates this well:
…the tasks computers are able to perform ultimately depend upon the ability of a programmer to write a set of procedures or rules that appropriately direct the technology in each possible contingency. Computers will therefore be relatively productive compared to human labor when a problem can be specified—meaning that the criteria for success are quantifiable and can readily be evaluated.
This prediction may have seemed reasonable at the time, however it was proven wrong by advances in the field of deep learning over the subsequent decade. Today, large language models are capable of performing many tasks without humans ever understanding the model’s internal computations, and insofar as clear problem specifications are important, they matter for different reasons; e.g. because they make it easier to improve model performance on the task through reinforcement learning.
Following the deep learning revolution, another framing that became popular in the economics of AI was thinking of AI systems as “Prediction Machines”. This new extrapolation was a reaction to the capability profile of AI systems at the time: between 2012 and 2019, supervised learning methods which were well-suited to prediction tasks dominated the field, and extrapolators made the old mistake of believing the future of AI could be predicted by assuming AI systems would be like the supervised learners of the mid-2010s, except better. Some quotes from the book I link to above make this clear:
“… the advances that we have seen are in machine learning which is more properly characterized as an advance, albeit a significant one, in statistics; in particular, in statistics to generate predictions.”
“What will new AI technologies make so cheap? Prediction. Therefore, as economics tells us, not only are we going to start using a lot more predictions, but we are going to see it emerge in surprising new places.”
Just as it was with the prediction from Frey and Osborne (2013) that computerization would depend on the ability of programmers to explicitly plan for every contingency, this new extrapolation was also overturned by later developments in the field, most notably the switch to unsupervised learning and what’s now called “generative AI”.
In contrast with these examples, the method of first-principles reasoning has often been used by AI researchers and futurists. Perhaps the most famous example is Ray Kurzweil, who in 1999 estimated the brain’s computational power at around 10^16 operations per second and combined this with Moore’s law to predict that human-level AI systems would be created in 2029. I’ve also used a similar approach in Gradient Updates before, for instance in a past issue on Moravec’s paradox in which I draw on evolutionary arguments to speculate about the future order in which different tasks are likely to be automated by AI.
In this issue, I will argue that while the first method is often more reliable in predicting the rate of progress on tasks that AIs can already do at some minimal level of competence, the second method is much better for making performance forecasts on tasks that current AIs cannot do at all, or can only do very poorly. In addition, because most of the future economic gains of AI can be expected to come from tasks AI cannot yet perform, a forecaster focusing narrowly on the first approach of extrapolation should be expected to dramatically underestimate the future pace, breadth, and impact of AI progress.
The perils of extrapolation
Using a simple model to extrapolate past data to the future is a well-tested approach for forecasting, and one I would endorse in many other domains. However, when it comes to AI, I think it has severe deficiencies if used by itself.
The most important one is that these methods, by anchoring us to past and present capabilities, lead us to underestimate the extent to which future AIs will be capable of performing tasks that current AIs can’t perform at all. Even when forecasters using this method explicitly try to make allowances for this possibility, they still tend to think that future AI will be similar to present AI, except its sphere of competence will gradually expand to tasks adjacent to what AI can do now.
The present iteration of this mistake is to view recent developments in AI through the narrow frame of “generative AI”. Just as with the “prediction machines” that came before, this way of thinking biases people using it to think the future capabilities of AI can be adequately forecasted by assuming that we will get something like today’s image generators and chatbots except at a lower cost and higher quality.
The problems with predicting the future of AI this way are hard to overstate. As both an illustration and a reminder, I provide a table below of what people considered to be important capabilities of AI systems in 2016.

Figure 1: A table from a 2016 Harvard Business Review article by Andrew Ng about what AI systems of the time could and couldn’t do.
Note that none of the capabilities that appear salient to us in 2025 – question answering, reading comprehension, image generation, programming, mathematics – appear in the table at all. These were all new capabilities that emerged as a result of scaling and algorithmic progress, ones that would have been off the radar of anyone who was using naive extrapolation to predict the performance of AI systems in 2025. We should expect, by default, that the difference between the current capabilities of AIs and their capabilities a decade from now will be just as substantial.
A recent influential paper that I believe makes the mistake of relying too much on this method of naive extrapolation is Acemoglu (2024). Drawing on the work of several other authors who have produced estimates of the exposure of different economic tasks to LLM automation and the cost savings that might reasonably be expected on such exposed tasks, Acemoglu estimates that we can expect economic output to go up by 0.7% over the next ten years due to AI. This number comes out of combining three different estimates:
- Eloundou et al. (2023)’s estimates imply that around 20% of tasks by wage bill in the US are exposed to automation by large language models.
- Svanberg et al. (2024) estimate that out of the tasks currently exposed to automation by computer vision systems, only 23% would be cost-effective to actually automate.
- On these automated tasks, Acemoglu assumes an average labor cost saving of around 30% relative to having the tasks be performed by humans.
- Finally, Acemoglu estimates that around 50% of the cost of these tasks is actually labor cost, so that the total cost savings on these tasks is around 15%.
The rough GDP impact of this can be calculated by taking the share of tasks which experience cost reduction, which is around 0.2 * 0.23 = 4.6%, and multiplying this by the implied productivity gain of around 1/0.85 = 17.6%, which yields a total factor productivity impact of around 4.6% * 17.6% = 0.8%.
This is a reasonable estimate of the economic output impact of a hypothetical technology that could be summarized as “LLMs, but better”. However, that’s not actually what we should expect from future AI systems at a time horizon of 10 years: we should expect them to become capable of performing many tasks that current AI systems cannot perform at all. For instance, below is a plot of the impact of the test-time compute paradigm shift on the mathematics performance of language models:
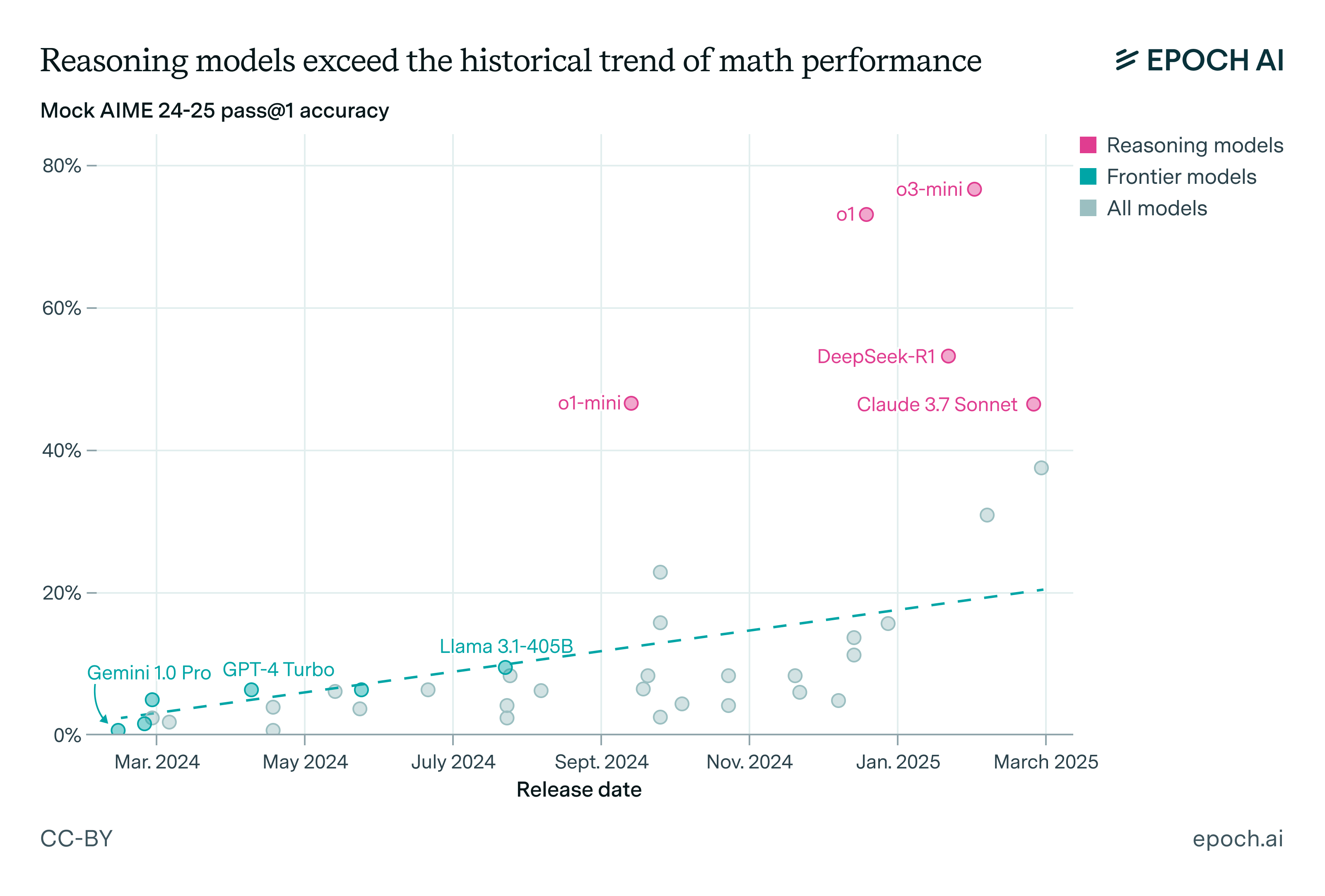
We should, on priors, expect many such discontinuities and capabilities that suddenly emerge over the next decade. So even though looking at what AI can currently do seems like the more grounded and reasonable way to make predictions, it’s in fact likely to be grossly inaccurate, and more speculative approaches that allow for abrupt accelerations of progress and the appearance of novel capabilities will likely make better predictions.
What is the alternative?
There’s no way of getting around the problem that predicting the future is difficult, and this becomes even more so in the absence of clear trends to extrapolate into the future. For instance, we currently lack high-quality benchmarks for remote work tasks and robotics, and even if we had such benchmarks we would see that current systems all perform very poorly on them and a linear extrapolation might put their saturation date decades, if not centuries, out from today. This is clearly not a reasonable way to make projections about when AI will be performing well on these tasks, because we’ve seen time and time again that benchmark scores are not linear functions of time.
For these “pre-emergence” tasks that humans can perform but current AIs cannot perform at all, I think our forecasts should be informed by the existence proof given by the human brain and its resource demands. For any cognitive task that the human brain can perform, we can say the below should at least be sufficient to build a neural network that performs the task:
-
1e15 FLOP/s of runtime compute, as this is roughly how much compute the brain is estimated to perform.
-
1e24 FLOP of training compute, as a human lives for around a billion seconds until the age of 30.
-
A training algorithm that’s much smaller than 100 MB in size and takes much less compute than 1e45 FLOP to discover via some variant of evolutionary search.
The size bound comes from the size of the genome, and the search computation bound comes from thermodynamic limits on how much useful computation could have happened throughout evolution. -
As much training data as a human sees during lifetime learning.
Out of these, we can currently achieve (1), (2), and (4) on most tasks, which is a new development as the training compute of frontier AI systems only crossed the 1e24 FLOP threshold around two years ago. The fact that we don’t yet have AI systems demonstrating superhuman capabilities is evidence that our algorithms remain inferior to the human brain in many domains: we’ve not yet fulfilled condition (3).
Given that there isn’t a trivial way to narrow down our uncertainty over the actual computational demands of the algorithmic search relevant to point (3), a conservative solution is to assume that the compute we need to spend to discover a suite of algorithms that can beat out the human brain is uniformly distributed in log space between what we have spent cumulatively thus far (probably between 1e26 and 1e30 FLOP) and 1e45 FLOP. A reasonable estimate is that this cumulative computation will go up by around 1000x by the end of the decade, and from our current starting point this implies around 20% chance of hitting upon the right algorithm. Even if we discount this by e.g. a factor of two due to model uncertainty, this gives a 10% chance of human-level AI by 2030.
This is not even taking into account the possibility that, unlike evolution, we will be able to trade off the compute spent on the algorithmic search, model training, and model inference; as well as amortize training compute over all deployed instances of a model. This could allow us to use a worse algorithm and compensate for this with greater training and inference compute, as in fact I expect the first human-level AI systems to do. Factoring this in should result in our probability being significantly higher than 10%, though it’s not clear how much higher.
This picture, combined with Moravec’s paradox, even gives us an idea as to which tasks we should expect AI to reach human-level performance in first: they are precisely the tasks for which AIs have more of a data advantage and less of an algorithmic disadvantage compared to humans. For instance, even though Eloundou et al. (2023) concludes that a task requiring scientific skills is a reason to expect it to resist LLM automation, I think this broader view actually suggests it is a reason for it to be exposed to AI automation in general. The reason is that scientific reasoning is not the kind of task humans would have highly efficient algorithms to perform relative to sensorimotor and perception tasks.
Conclusion
The basic takeaway is that what AI can currently do is not the story. If you want to predict the future of AI beyond a horizon of a few years, it’s not a good idea to anchor on the present capabilities of AI systems, or even on the present rate of change of those capabilities. You should instead think in terms of the intrinsic difficulty of various tasks, many of which current AI systems cannot perform at all, and what that means for the resource demands of automating those tasks using AI.
When we do this, we get a much more bullish picture of AI progress that I think seems to fit recent history better. Many of the arguments people now advance in favor of the capabilities of “generative AI” systems being intrinsically limited would have performed quite poorly had they been deployed e.g. in 2016 about the limitations of AI systems of the time, and if we wish our predictions to fare better, we should not rely on forecasting methods that haven’t performed well in the past.
About the authors

Related work