
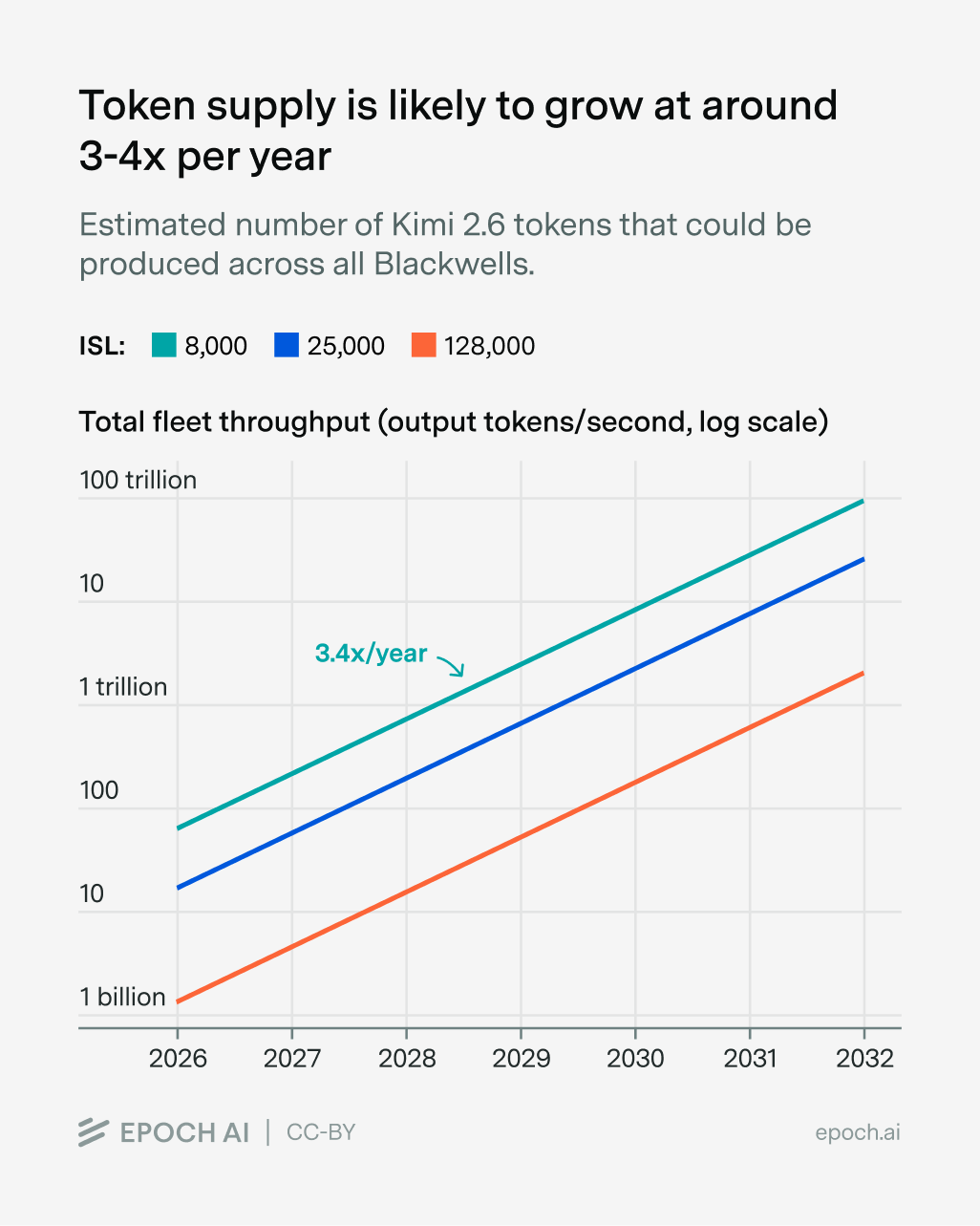
We estimated trends in global inference capacity and found that token demand appears to be growing much faster than supply.
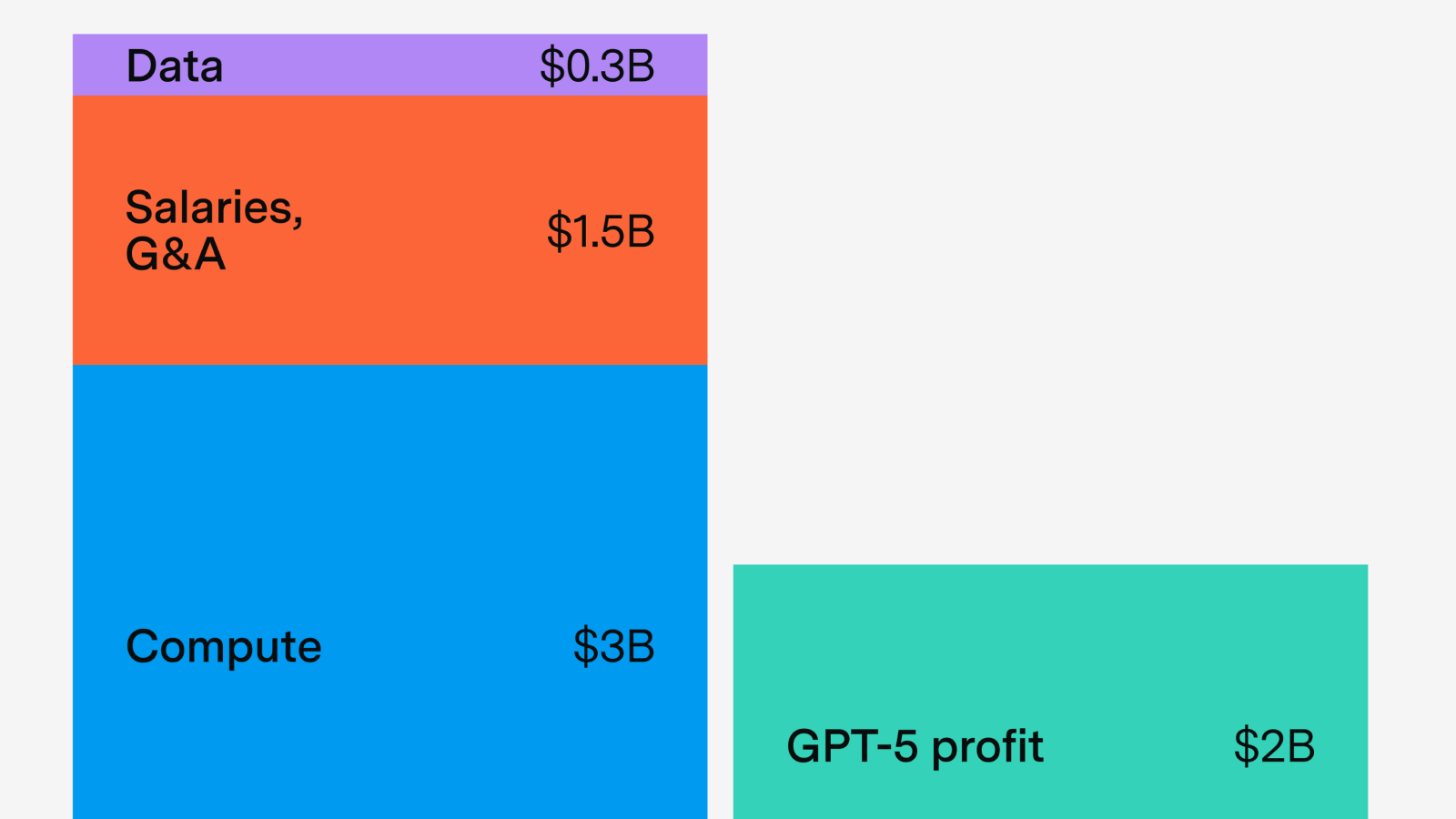
Lessons from GPT-5’s economics
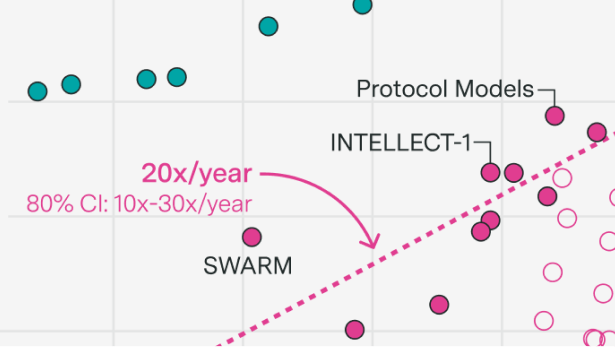
Decentralized training over the internet promises to scale training to the limits of the internet.
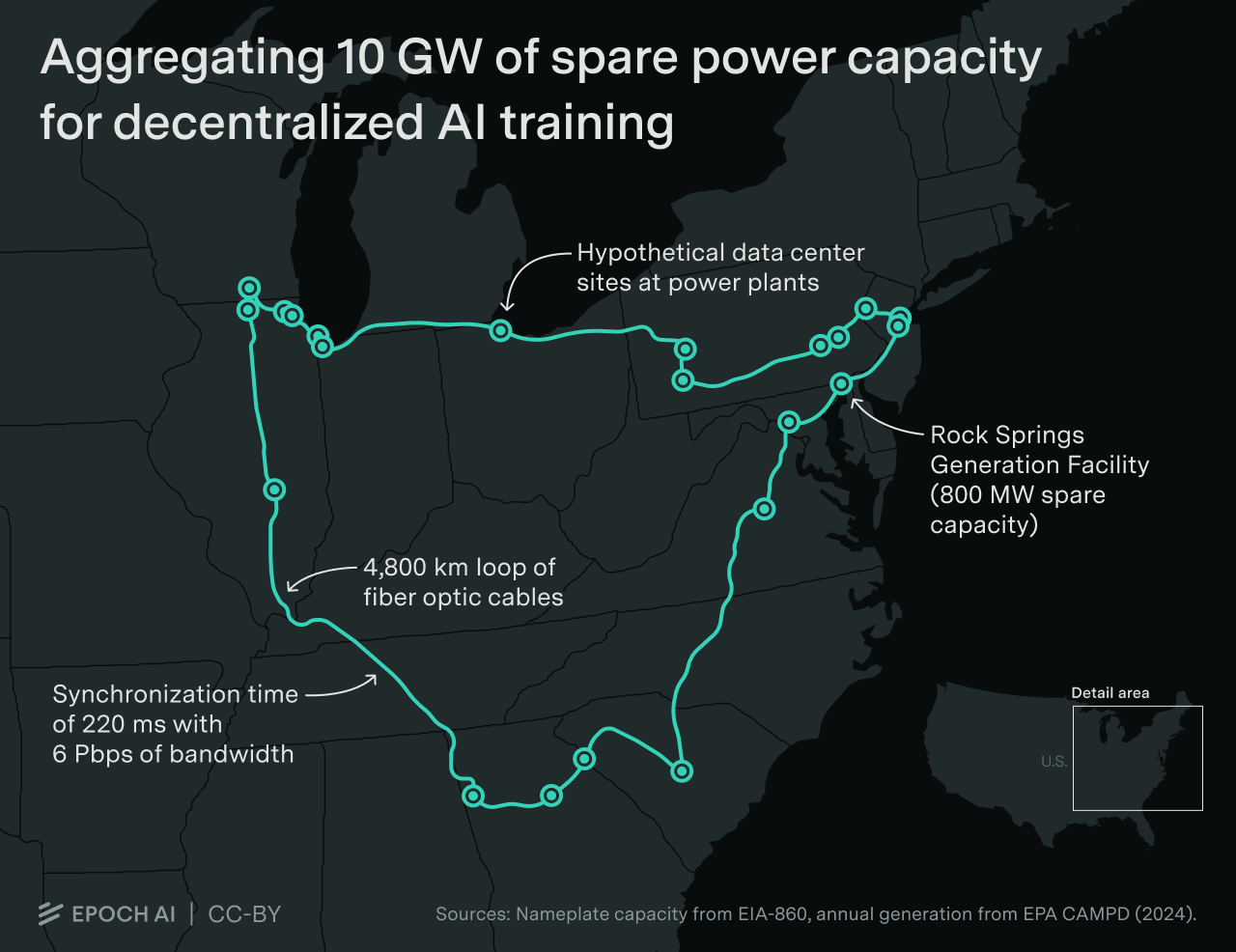
We illustrate a decentralized 10 GW training run across a dozen sites spanning thousands of kilometers. Developers are likely to scale data centers to multi-gigawatt levels before adopting decentralized training.

OpenAI has the inference compute to deploy tens of millions of digital workers, but only on a narrow set of tasks – for now.
OpenAI focused on scaling post-training on a smaller model

Epoch AI researchers Jaime Sevilla and Yafah Edelman forecast AI progress to 2040: coding automation, 10% GDP growth, and wild uncertainty after 2035.

Our director explains Epoch AI’s mission and how we decide our priorities. In short, we work on projects to understand the trajectory of AI, share this knowledge publicly, and inform important decisions about AI.

We clarify that OpenAI commissioned Epoch AI to produce 300 math questions for the FrontierMath benchmark. They own these and have access to the statements and solutions, except for a 50-question holdout set.

Epoch AI presents their first podcast, exploring AI scaling trends, discussing power demands, chip production, data needs, and how continued progress could transform labor markets and potentially accelerate global economic growth to unprecedented levels.
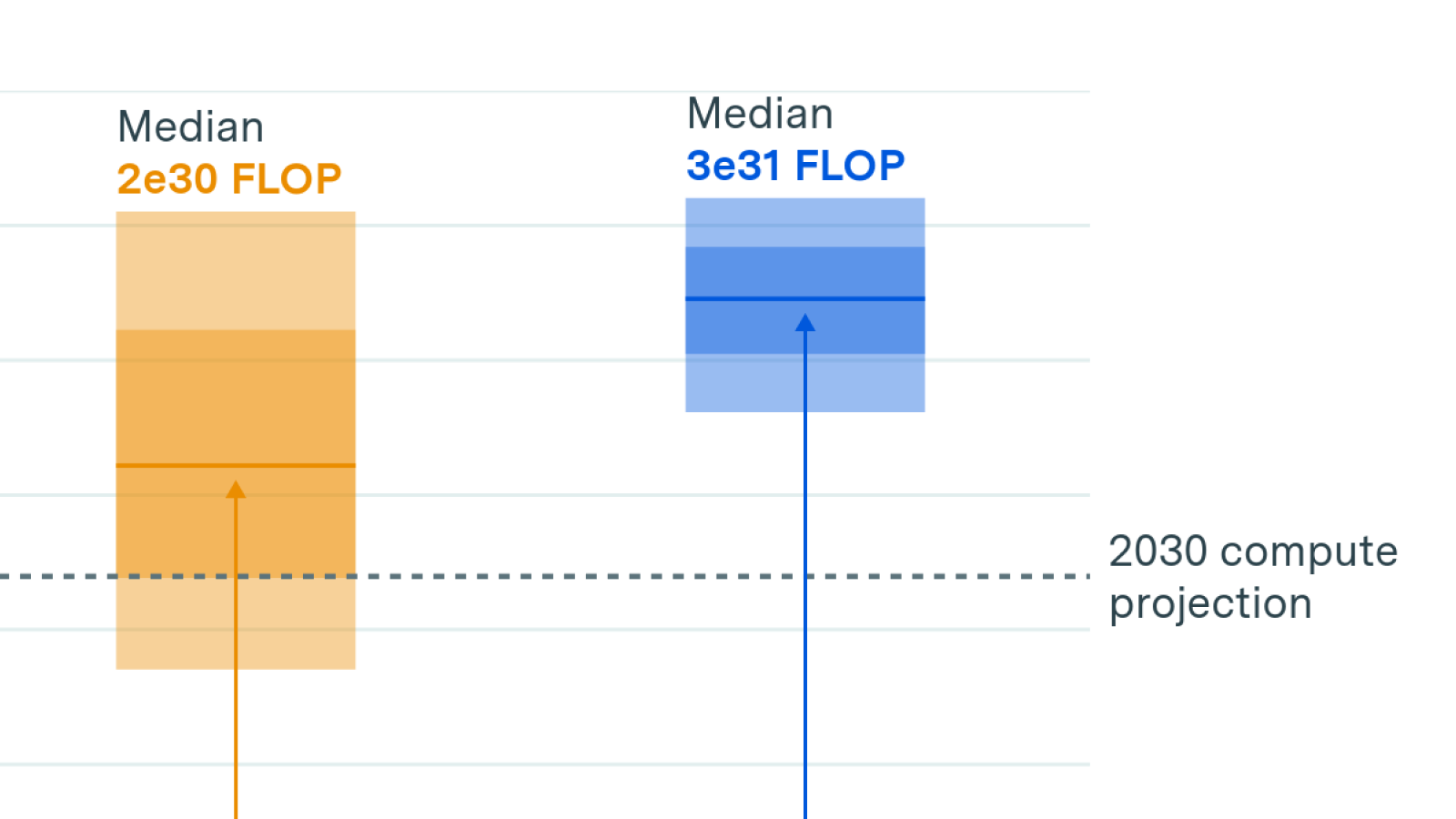
We investigate the scalability of AI training runs. We identify electric power, chip manufacturing, data and latency as constraints. We conclude that 2e29 FLOP training runs will likely be feasible by 2030.
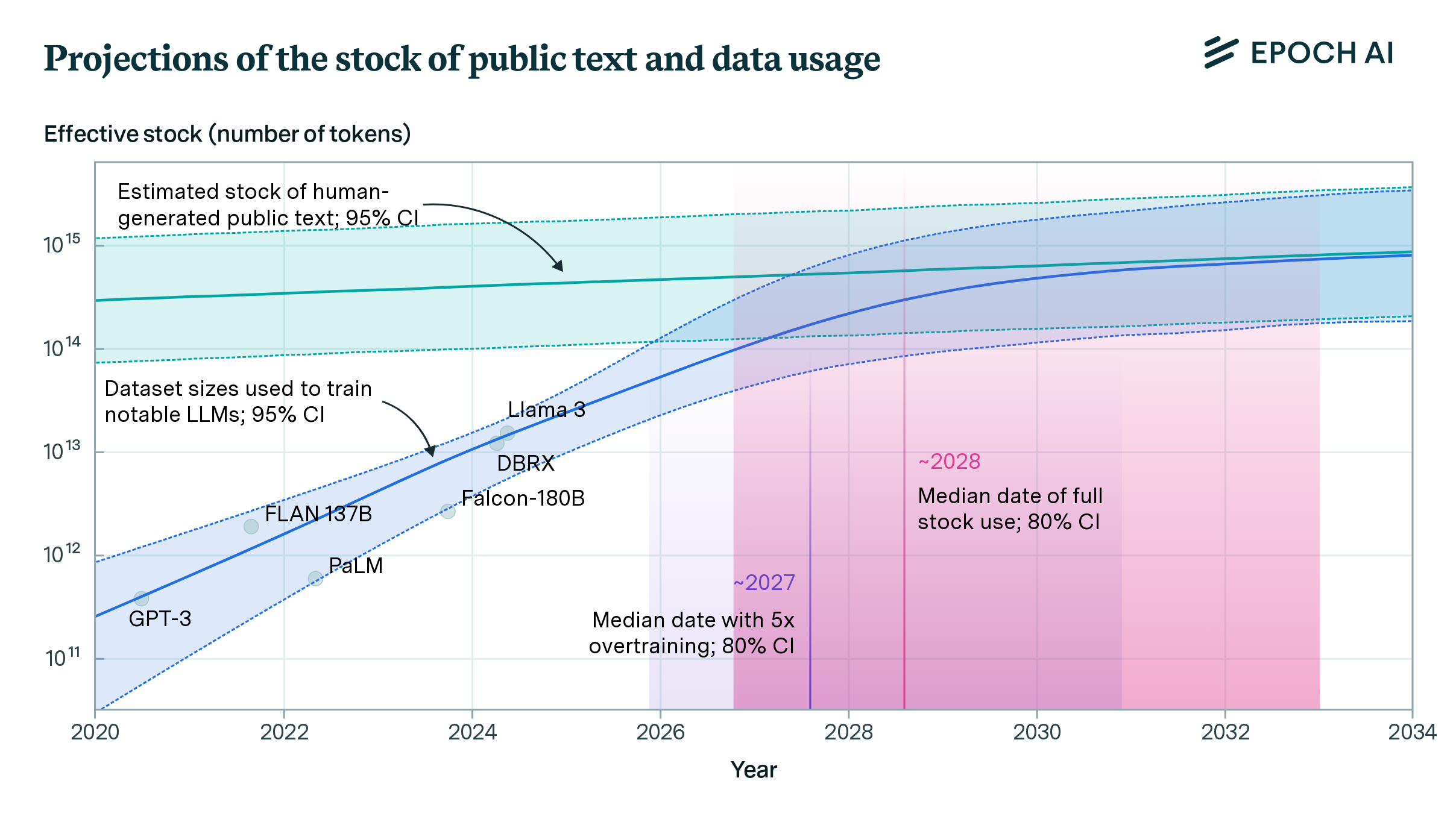
We estimate the effective stock of quality and repetition adjusted human-generated public text for AI training at around 300 trillion tokens. If trends continue, language models will fully utilize this stock between 2026 and 2032, or even earlier if intensely overtrained.
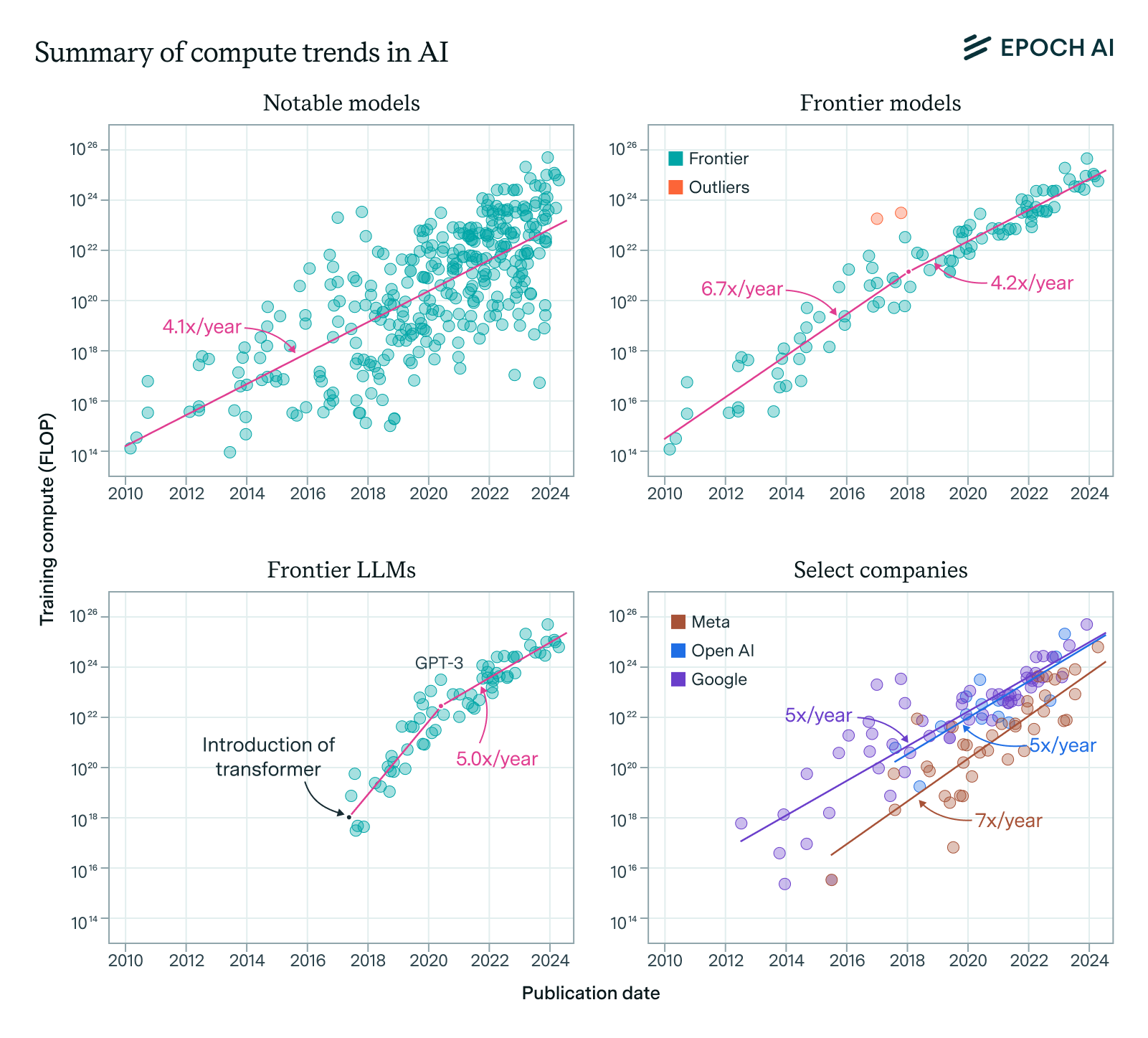
Our expanded AI model database shows that the compute used to train recent models grew 4-5x yearly from 2010 to May 2024. We find similar growth in frontier models, recent large language models, and models from leading companies.

Progress in pretrained language model performance surpasses what we’d expect from merely increasing computing resources, occurring at a pace equivalent to doubling computational power every 5 to 14 months.

Compute is essential for AI performance, but researchers often fail to report it. Adopting reporting norms would support research, enhance forecasts of AI’s impacts and developments, and assist policymakers.
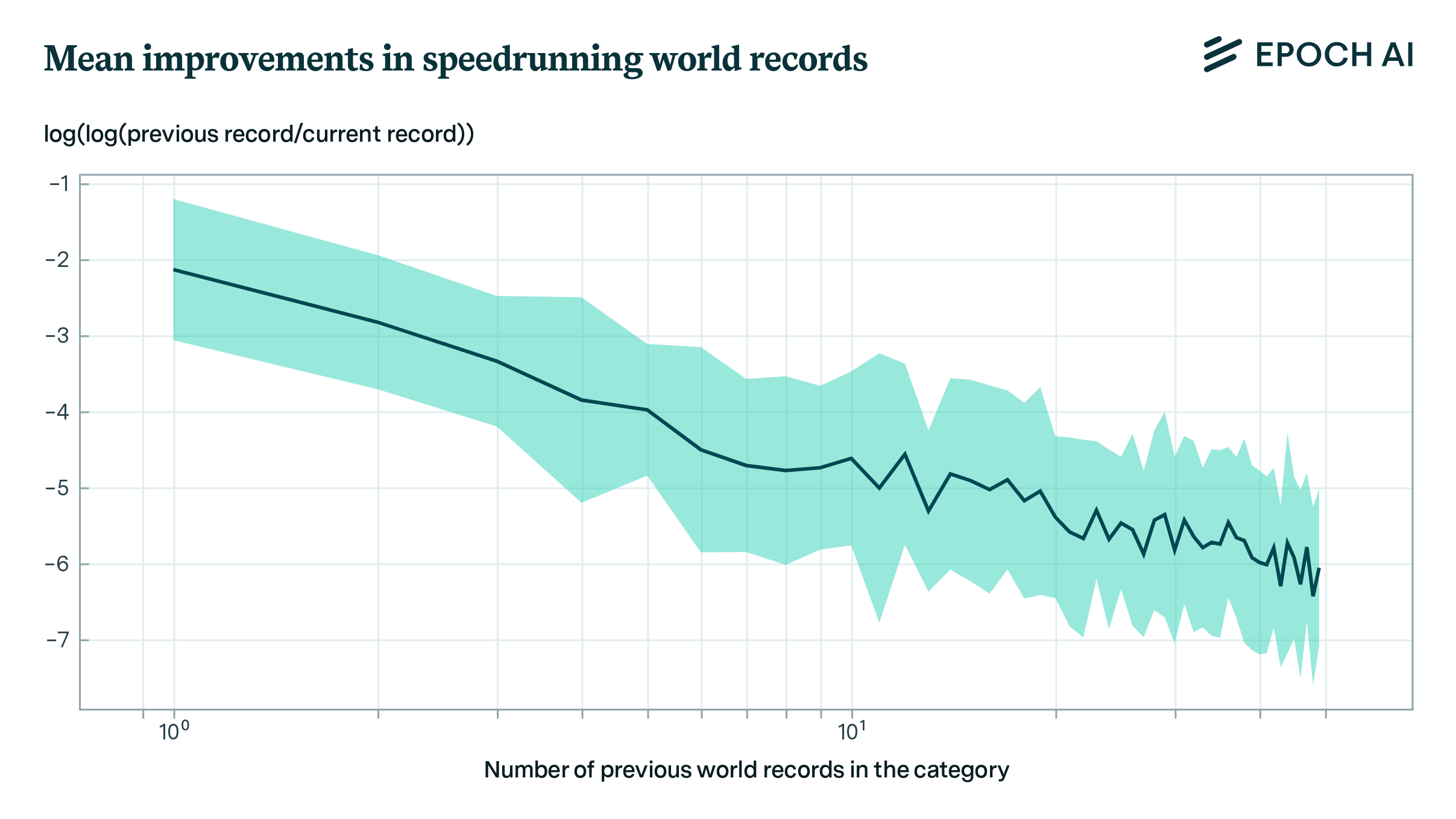
We develop a model for predicting record improvements in video game speedrunning and apply it to predicting machine learning benchmarks. This model suggests that machine learning benchmarks are not close to saturation, and that large sudden improvements are infrequent, but not ruled out.
We have developed an interactive website showcasing a new model of AI takeoff speeds.
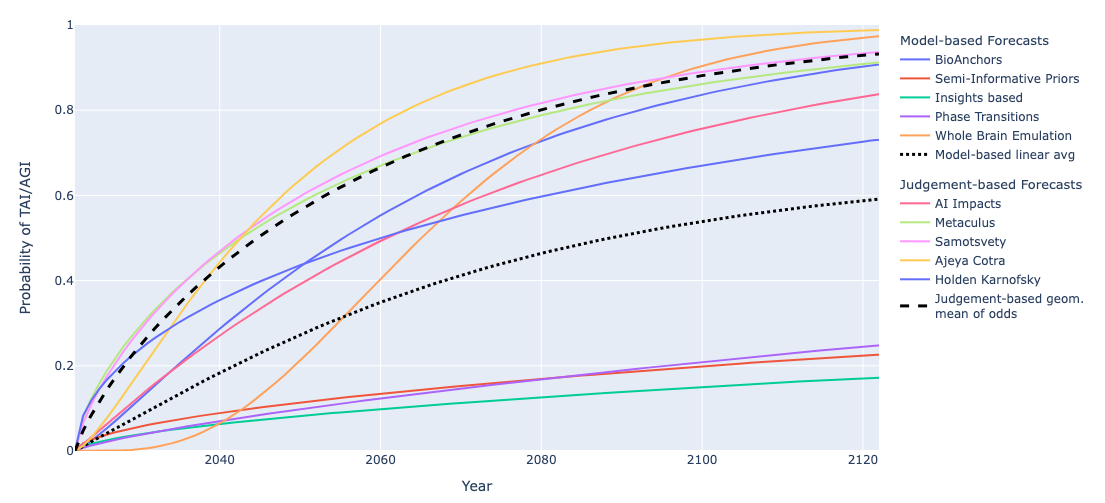
We summarize and compare several models and forecasts predicting when transformative AI will be developed.
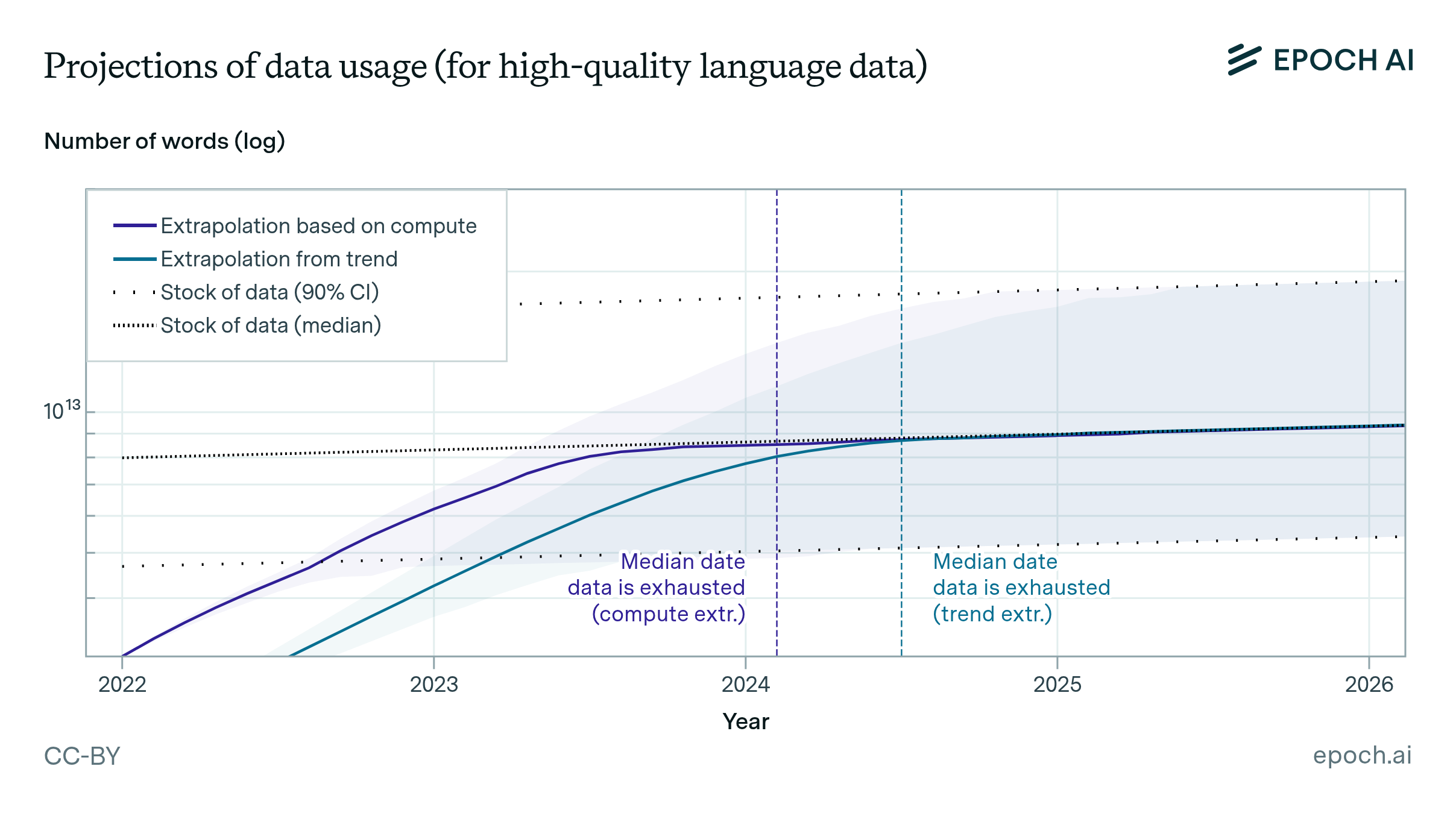
Based on our previous analysis of trends in dataset size, we project the growth of dataset size in the language and vision domains. We explore the limits of this trend by estimating the total stock of available unlabeled data over the next decades.
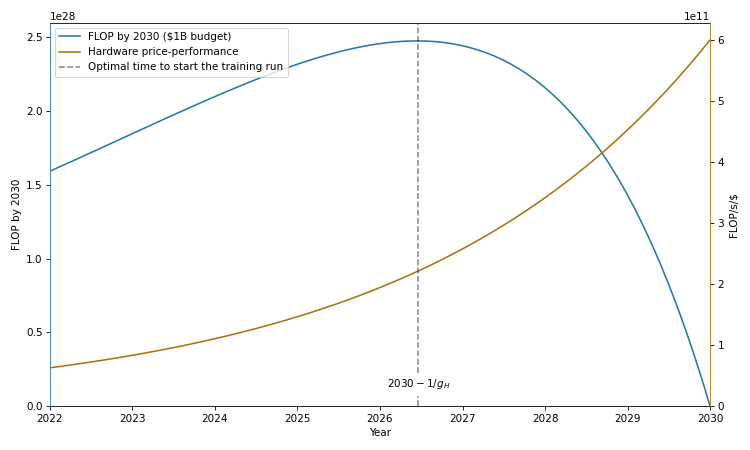
Training runs of large machine learning systems are likely to last less than 14-15 months. This is because longer runs will be outcompeted by runs that start later and therefore use better hardware and better algorithms.
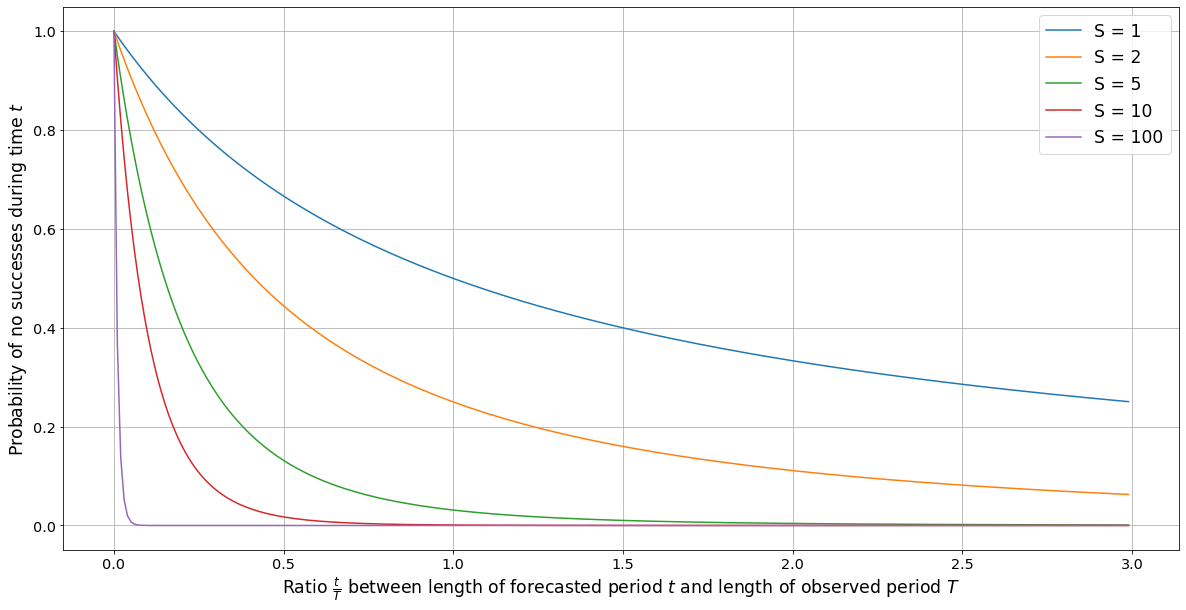
We explore how to estimate the probability of an event given information of past occurrences. We explain a problem with the naive application of Laplace’s rule in this context, and suggest a modification to correct it.
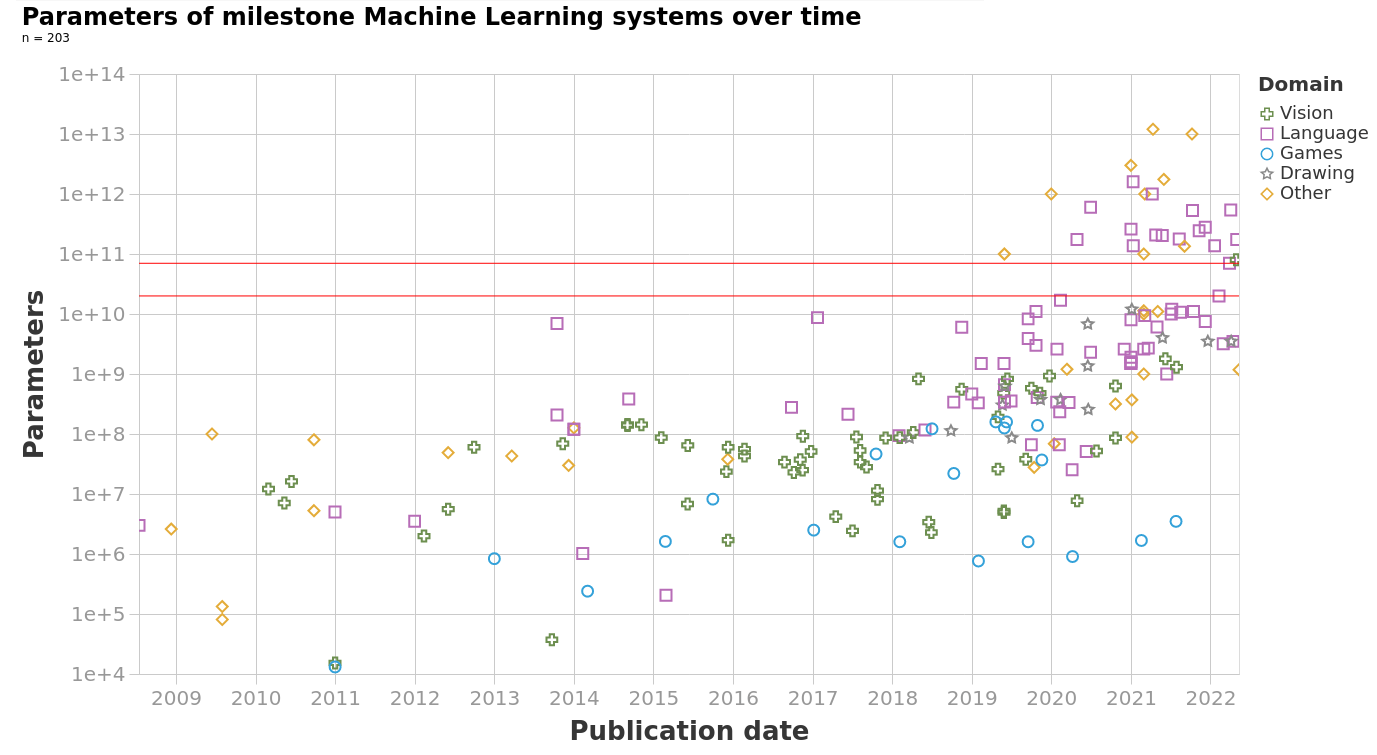
The model size of notable machine learning systems has grown ten times faster than before since 2018. After 2020 growth has not been entirely continuous: there was a jump of one order of magnitude which persists until today. This is relevant for forecasting model size and thus AI capabilities.
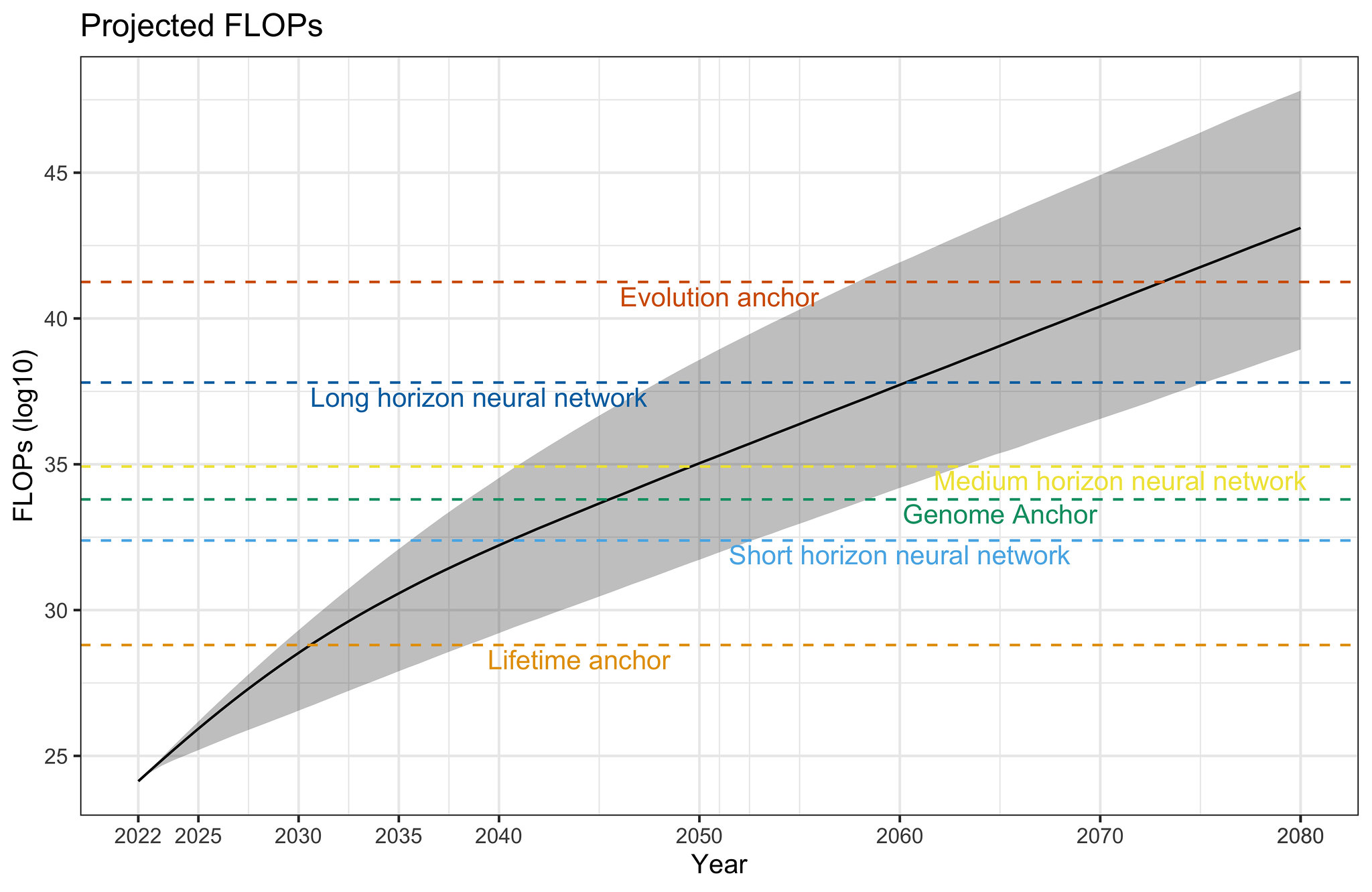
Projecting forward 70 years' worth of trends in the amount of compute used to train machine learning models.
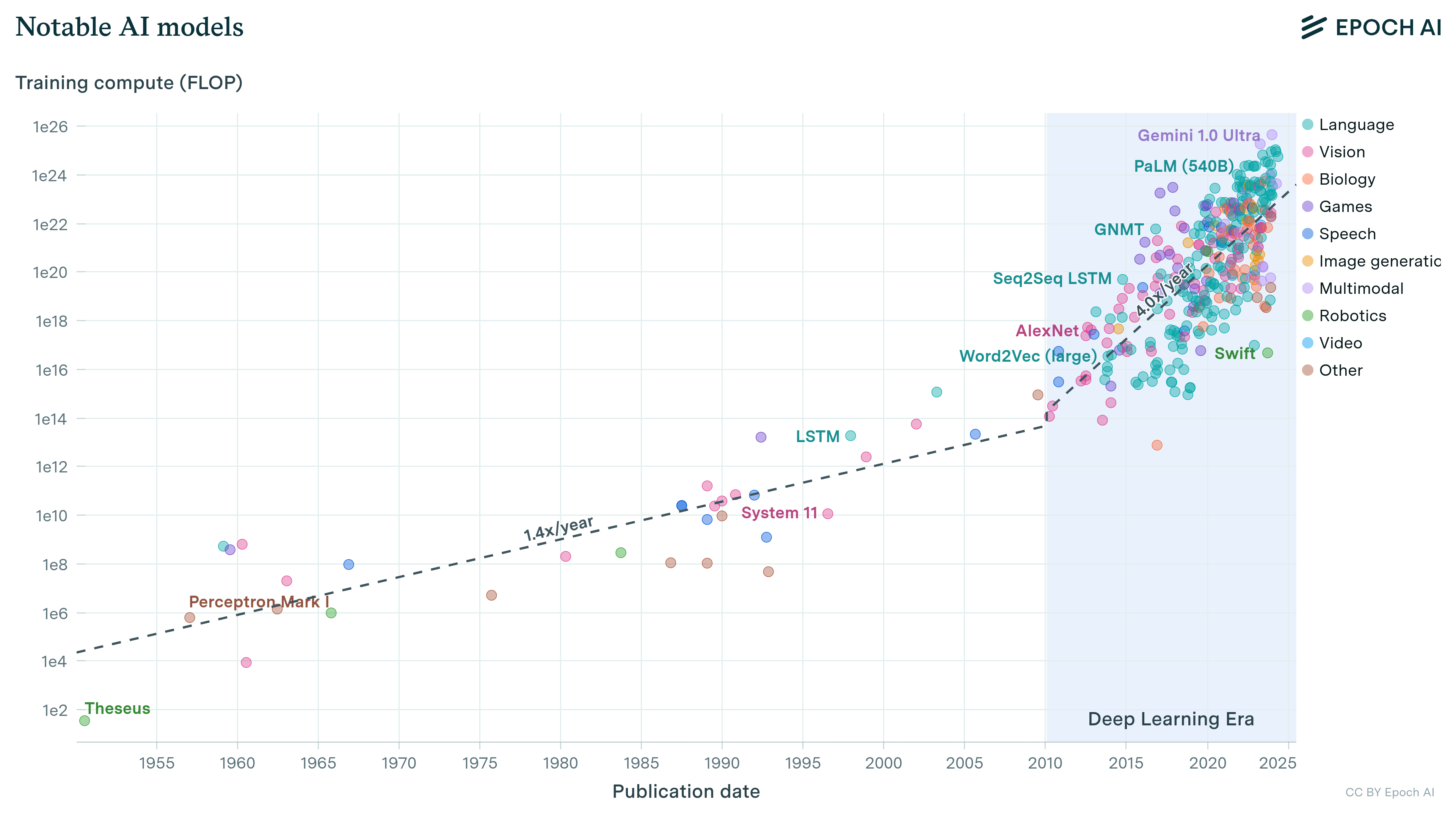
We’ve compiled a dataset of the training compute for over 120 machine learning models, highlighting novel trends and insights into the development of AI since 1952, and what to expect going forward."
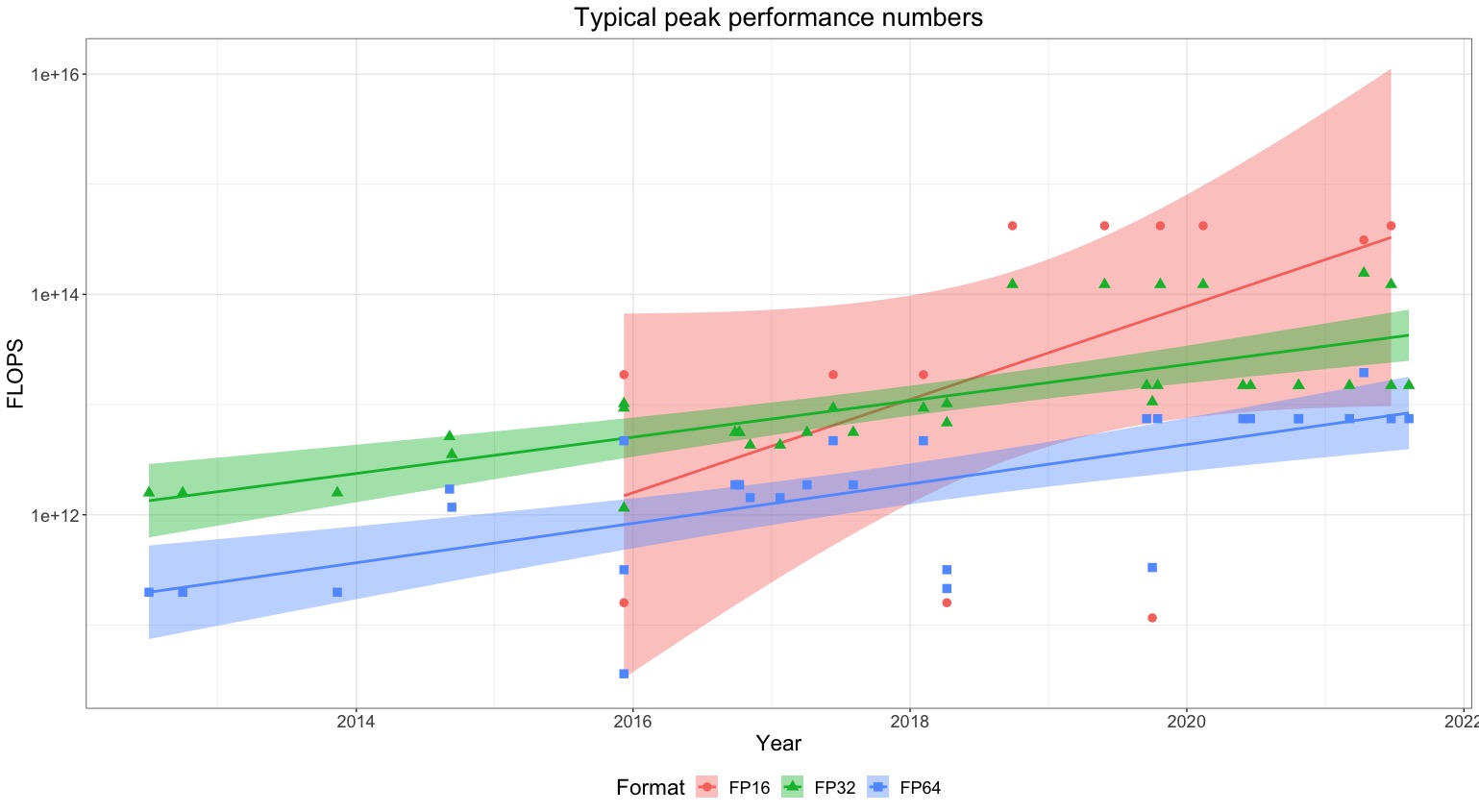
We describe two approaches for estimating the training compute of Deep Learning systems, by counting operations and looking at GPU time.
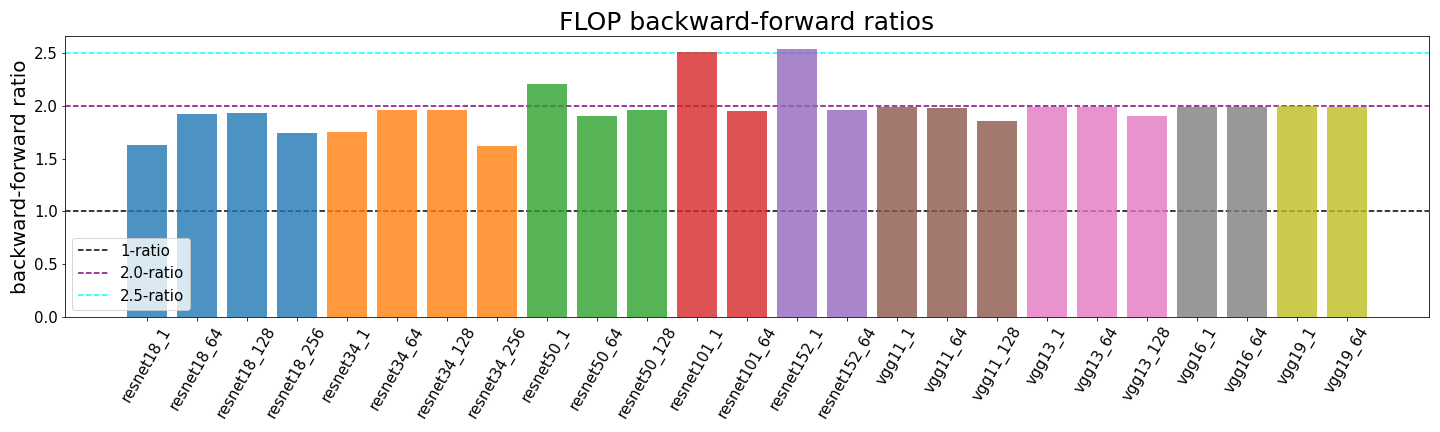
Determining the backward-forward FLOP ratio for neural networks, to help calculate their total training compute.
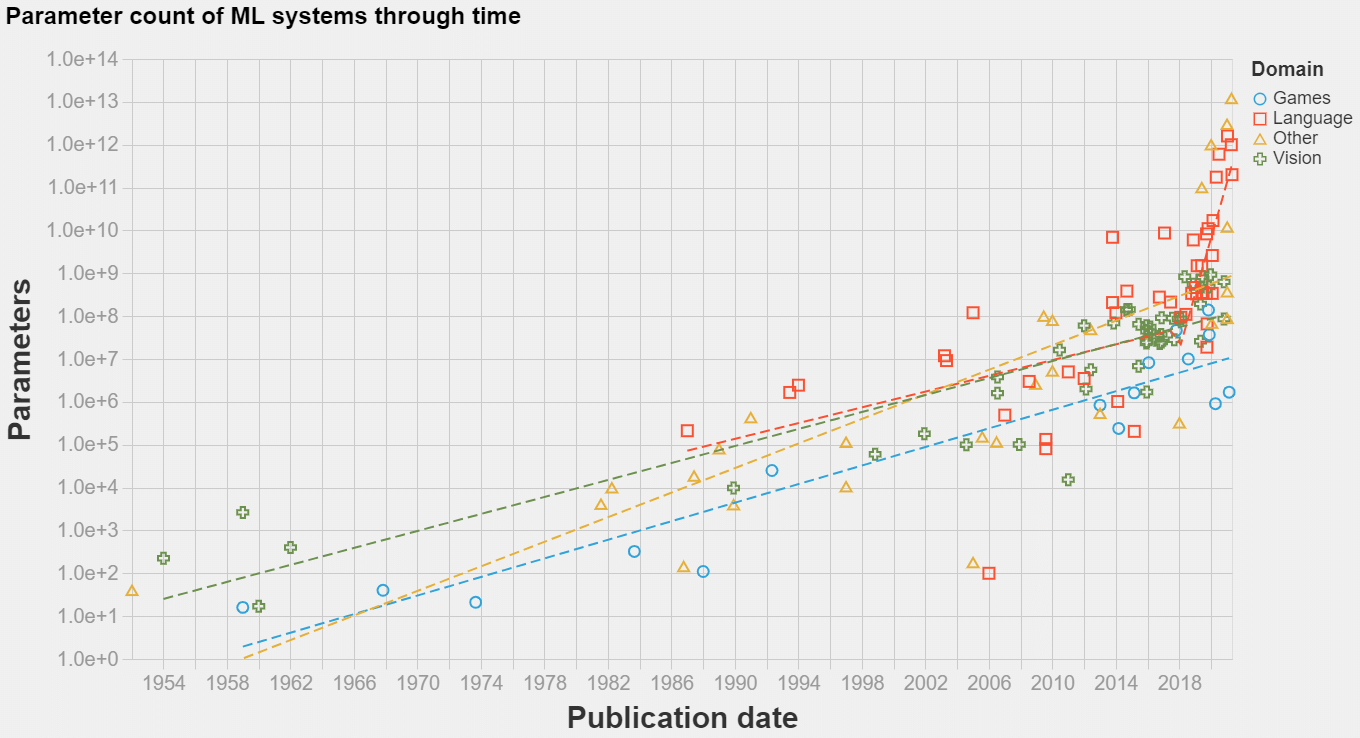
Compiling a large dataset of machine learning models to determine changes in the parameters counts of systems since 1952.