What trends are we extrapolating?
A common way that experts forecast AI timelines is so simple it’s hard to believe: trend extrapolation. Sure they also use numerical models that bake in things like runaway feedback loops, but the bread and butter of AI forecasting is to draw a line on a graph and extend it as far as you dare. Somehow this works well enough to be a state-of-the-art approach. However, the trends they extrapolate share a common weakness: they lean heavily on easy-to-measure things, not what we directly care about — how close AI is to doing AI research itself.
Many experts want to know when we’ll fully automate AI research, because this would massively speed up AI progress, kicking off an “intelligence explosion”.1 If that’s right, it’s hugely important to know how close we are. But historically, there haven’t been many points of direct evidence to point to, because full automation of AI R&D has been so hard to measure. Instead, researchers have been forced to rely on proxies.
One such proxy is in key AI inputs like compute, data, and energy. Take Situational Awareness, which extends “effective compute” five years into the future until AI research gets automated:
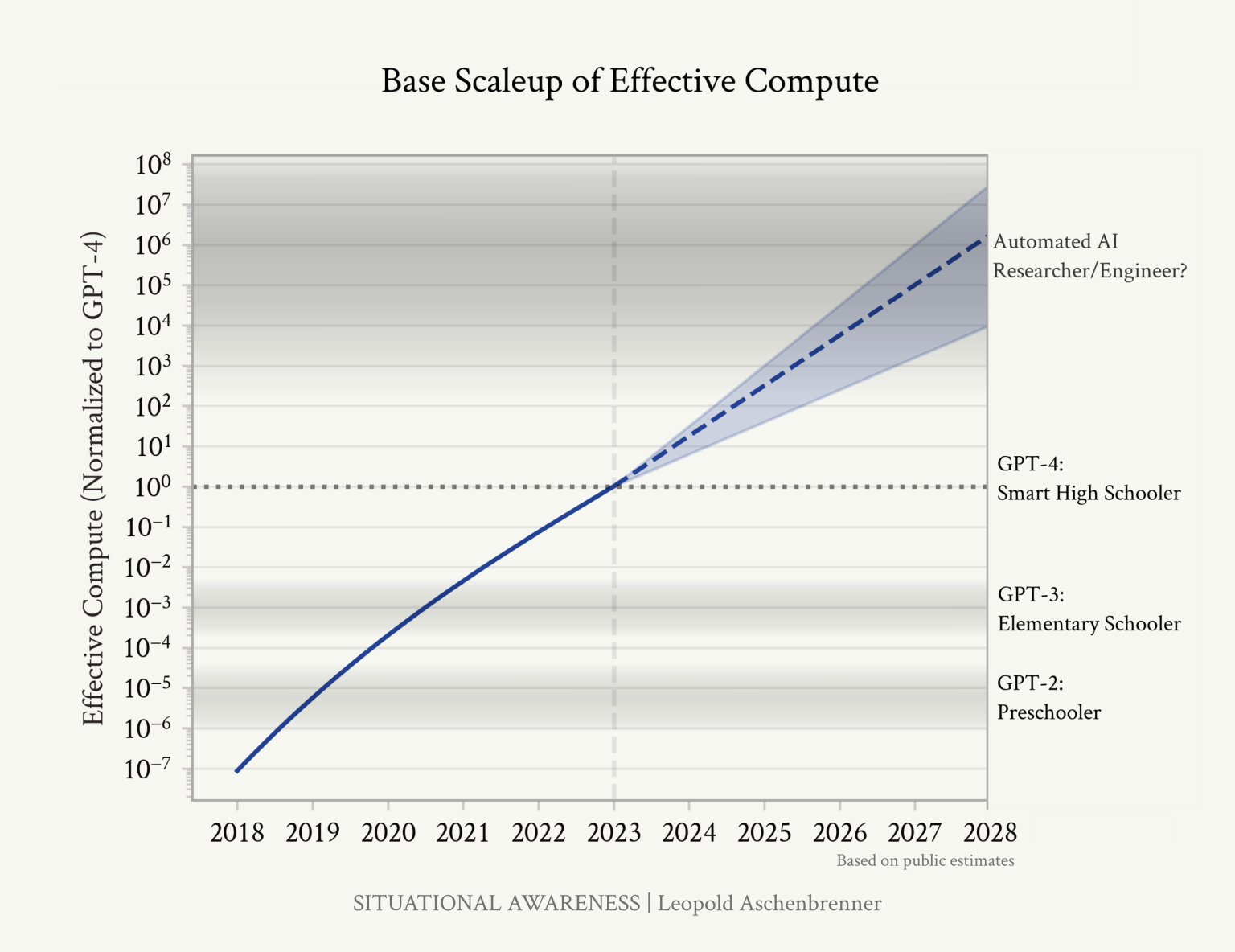
But these inputs are only rough proxies for capabilities and you need to go on “vibes” to say how much compute you need to match the world’s top AI researchers.
A second approach is to track the length of tasks that AIs can complete, where “length” is how long a skilled human takes. This is what METR did with their “time horizon” metric, which was then extrapolated in the famous AI 2027 scenario to forecast when AIs would become “superhuman coders”, before automating AI R&D.
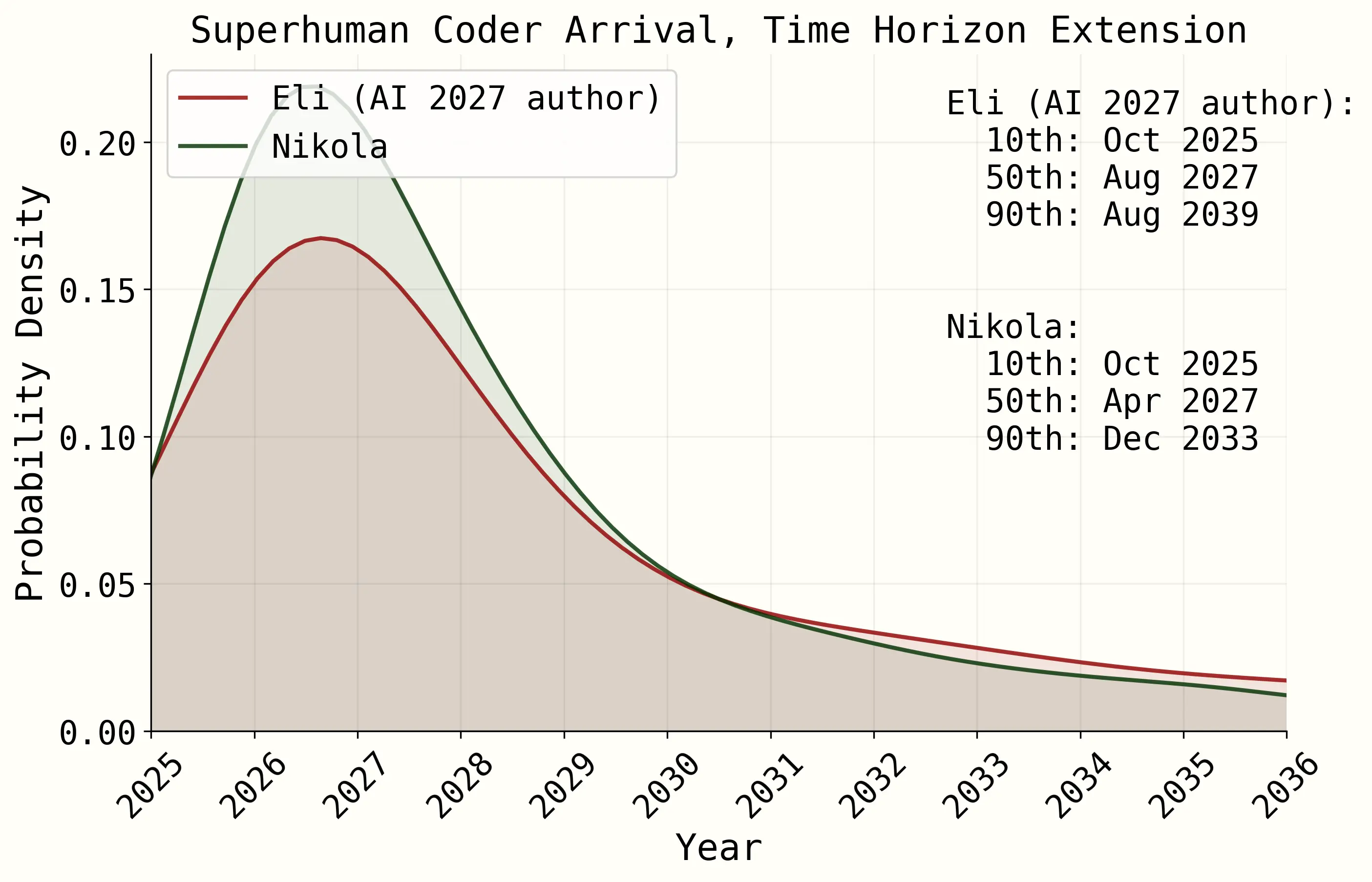
But the benchmarks used to construct METR’s time horizon miss out on many of the tasks and complexities of research. It’s one thing to be able to finetune a small GPT-2 model, and another to be able to coordinate five projects at the same time, dealing with a million lines of code, without a clear criterion for success or failure.
So it would be nice to know everything that AI R&D actually consists of. Otherwise we’ll always be at risk of streetlighting (extrapolating whatever happens to be easiest to measure). We can better avoid this if we have a list of the tasks involved in AI R&D, to track what we’re aware of and what we’re not investigating.
Armed with such a list, we could better interpret the extrapolations we already have: when a benchmark score climbs, a task list tells us which parts of the job that improvement covers, and which parts it doesn’t touch. And we could build new trends to extrapolate, like the fraction of tasks that are automated, or how much uplift researchers get on each one.
In this post, we present a first version of such a taxonomy with six categories spanning a frontier AI company’s research workflow, based on literature review and brainstorming. The categories are broken into over sixty tasks, each rated from 0 to 5 on how much we think current AIs automate it. The full taxonomy lives in a companion doc, which is the main artifact of this work.
We think of it as our best first attempt at developing a comprehensive taxonomy of tasks contributing to AI R&D, in order to more robustly understand and predict AI R&D automation. If we described tasks incorrectly, or missed some entirely, we’d love to hear about it and receive feedback.
An O*NET for AI R&D
We’re not the first to want a task list like this; breaking jobs down into tasks is how economists usually track automation in the economy. The standard tool here is O*NET, which describes about 1,000 jobs in the US economy as well as the tasks and skills that people need to do them.
Armed with O*NET, economists can then do a bunch of empirical work and forecasts about AI’s economic impacts, such as:
- Look at the fraction of American workers whose jobs might be heavily impacted by LLMs
- Estimate how AI might impact GDP growth over the next decade (however accurately or inaccurately)
- Design AI benchmarks to cover a wide range of knowledge work
- Taxonomize how people use frontier AI models
- Predict the consequences of automating remote work
But while O*NET is a widely used source, it doesn’t help us track AI research automation very well — the tasks in the dataset are just way too broad and high-level. Consider the job “Computer and Information Research Scientists”, which is probably about as close as you can get to “frontier lab AI researcher” within O*NET. In this case the work tasks look like this:

The first listed task is to “Analyze problems to develop solutions involving computer hardware and software”. But that’s really vague — what kinds of problems or solutions? What exactly does or doesn’t count as “involving computer hardware and software”? You could make the case that almost everything about an AI engineer’s job involves computer software, so it’s not a very granular description to say the least. And yet this is the most granular task description you can find in O*NET, and the same issue applies to pretty much every other task.
Part of the issue here is practical feasibility: O*NET was designed for the ambitious endeavor of mapping out the tasks in the entire US economy, before the days of LLMs. So it’s probably too much to ask for these tasks to be so granular for everything as new and niche as “frontier lab AI research”.
That’s why our proposal is to build an O*NET for AI R&D specifically. If we keep our focus narrow, we’re in a much better position to come up with a fine-grained decomposition of an AI researcher’s job. If this works well, we could look at the fraction of tasks that are automated over time. It could also help us interpret benchmark results and how significant they are. There’s a long-standing phenomenon where AI benchmarks haven’t fully reflected the complexities of the real world, and so it’s important to juxtapose benchmark results with what’s happening on the ground.
It could also serve as a framework for additional studies about AI’s impact. This could mean surveying AI researchers on the uplift they get on different work tasks. It could also mean classifying internal AI usage logs into different use cases, like “writing experiment code” or “deciding what experiment to run next”. This is similar to how Anthropic’s Clio system helps study real-world AI usage while preserving people’s privacy.
More generally, an O*NET for AI R&D would help establish a common vocabulary between researchers, such as in frontier labs’ model cards. This could help model developers summarize where AI does or doesn’t help in finer detail, and help standardize information across different sources, like in METR’s most recent Frontier Risk Report.
This being said, we’re not saying that an “O*NET for AI R&D is all you need” to monitor and forecast progress to automation. Even if we’re armed with a perfectly comprehensive dataset of tasks, we’d still need to measure how AI performs on each task, for example. But even still, having a task dataset would help ground the debate about AI’s actual impacts on AI research, and give us “situational awareness” about how close we might be to an intelligence explosion, supporting evidence from other sources.
A first proposal
So what would this “O*NET for AI R&D” actually look like? This is of course not trivial to answer — AI R&D is very messy and changes fast. But we figured we’d have an initial attempt at it and let you readers bombard us with feedback. To that end, we compiled over sixty representative tasks at frontier AI labs, accompanied by descriptions and concrete examples — see the full writeup here.
The first step was to make a big list of all the tasks currently involved in AI R&D, which we grouped into six categories, inspired by some earlier work.2 These categories correspond to different parts of the AI research cycle:
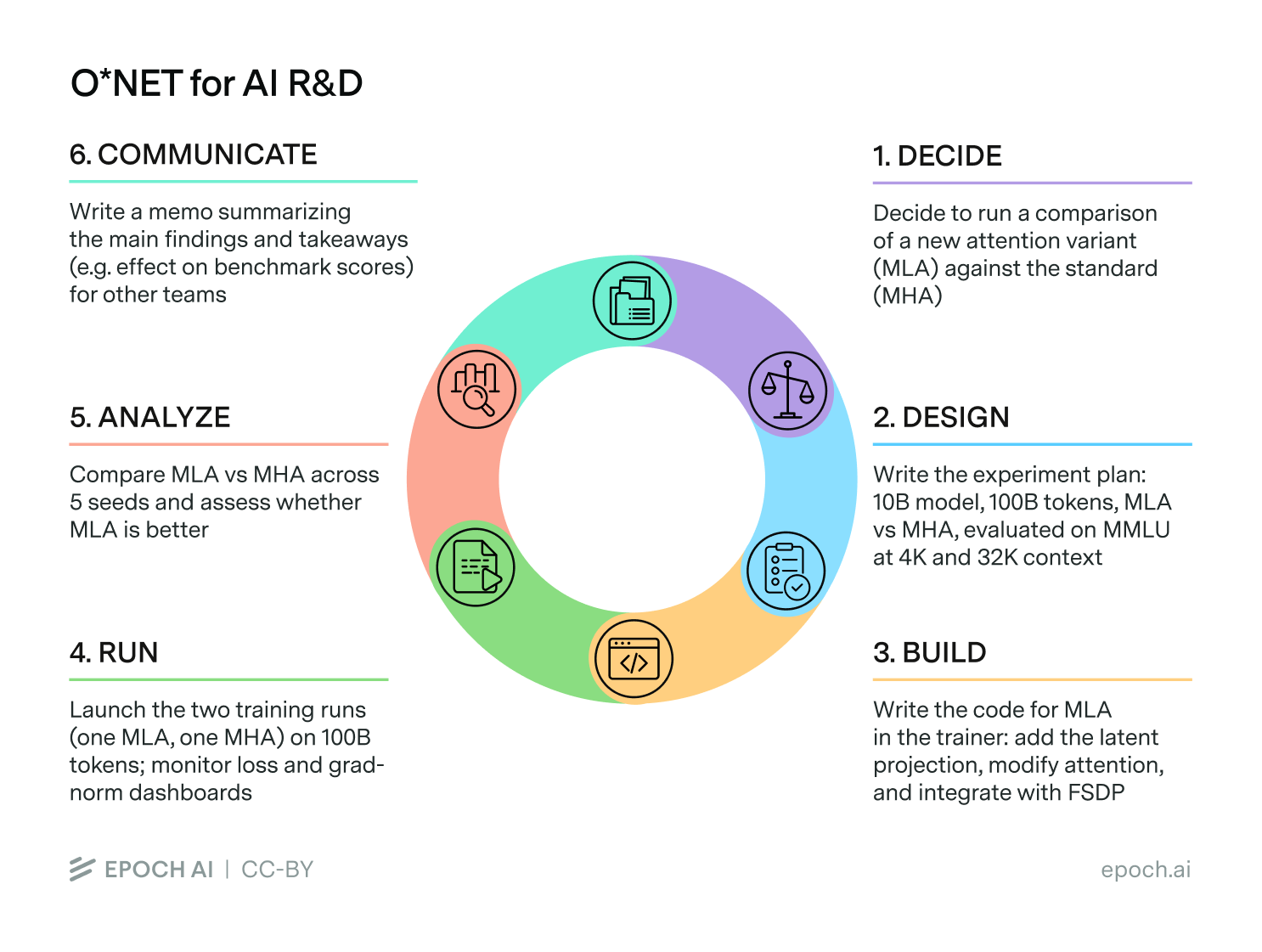
Each category has its own inputs and outputs. For example, consider Category 4 (“Run”), which as the name suggests is about “running” stuff — think executing training runs or deploying AI systems to the public. So the input could look something like a benchmark with all supporting scaffolds and related infrastructure, and the output could be a set of final results.
Each category is then split into several subcategories. Category 4 is split into three, each with its own inputs and outputs:
-
4.1 Monitoring runs: watch training, RL, and eval runs in flight; catch problems as they emerge; restore the run to a healthy trajectory
-
4.2 Hardware infrastructure operations: keep large clusters healthy, well-utilized, and quickly recoverable
-
4.3 Inference reliability engineering: keep production serving stable, performant, and recoverable
And finally the subcategories contain a thorough list of different tasks. For example, here are the tasks for “4.1 Monitoring runs”:

So you can see that this is way more granular than developing “solutions involving computer hardware and software” — our task descriptions get to the level of monitoring runs, and catching potential issues when they arise.
One thing you’ll notice about each task is that it includes a number next to it — that reflects our initial approach to estimating automation impact across tasks. Specifically, we rate how much we think current AIs automate each task on a scale of 0 to 5, based on the following rubric:
| Rating | AI’s automation |
|---|---|
| 0 | Not used, AI adds nothing |
| 1 | Marginal, occasionally convenient for lookups, brainstorming, or polishing writeups, but doesn’t change how the work is done or who is doing it |
| 2 | Assists, with meaningful speed ups or improvements to parts of the task; human mostly drives and reviews everything |
| 3 | Collaborates, with AI doing large chunks under close human direction; human still makes calls and stitches things together |
| 4 | Leads, completing most of the task end to end from a high-level ask; human supervises, course-corrects, and approves outputs. |
| 5 | Autonomous, end to end with little or no human involvement |
We provide examples of each of these in the full proposal.
This is of course quite subjective and there’s a ton of room for people to develop better ways to evaluate this, such as through internal benchmarks. Optimistically, an improved version of this could be used to construct a metric that we can extrapolate over time. This could be quite tricky, because we’d need to know which tasks need to be automated to kick off an intelligence explosion, and there might be new tasks. For example, perhaps AIs don’t need to “write a memo summarizing key takeaways” (unlike human researchers), if they have other ways of communicating with other AIs.
But our overall hope is simply that our full collection of tasks gives us an additional signal about what AI can and can’t automate at any point in time, supporting existing evidence we have from benchmarks and things like METR’s time horizons.
What’s next?
It goes without saying, but just to be excessively clear, this was an initial attempt at an O*NET for AI research. The most natural next step is to build on what’s here and add tasks we missed, sharpen descriptions to be more precise and accurate, taxonomize to be more mutually exclusive and collectively exhaustive, and re-rate the list as AI improves.
A step further would be to find other ways of organizing the taxonomy. For example, we thought about organizing all the tasks around the usual stages of model development, namely pre-training, post-training, and inference. We opted against it because it runs into several problems: (1) many tasks like “writing code for experiments” would be repeated across multiple stages, and (2) some tasks won’t fit naturally in these categories, not least because the training process can look super complex in practice. But just because we decided against this categorization doesn’t mean that it’s not workable.
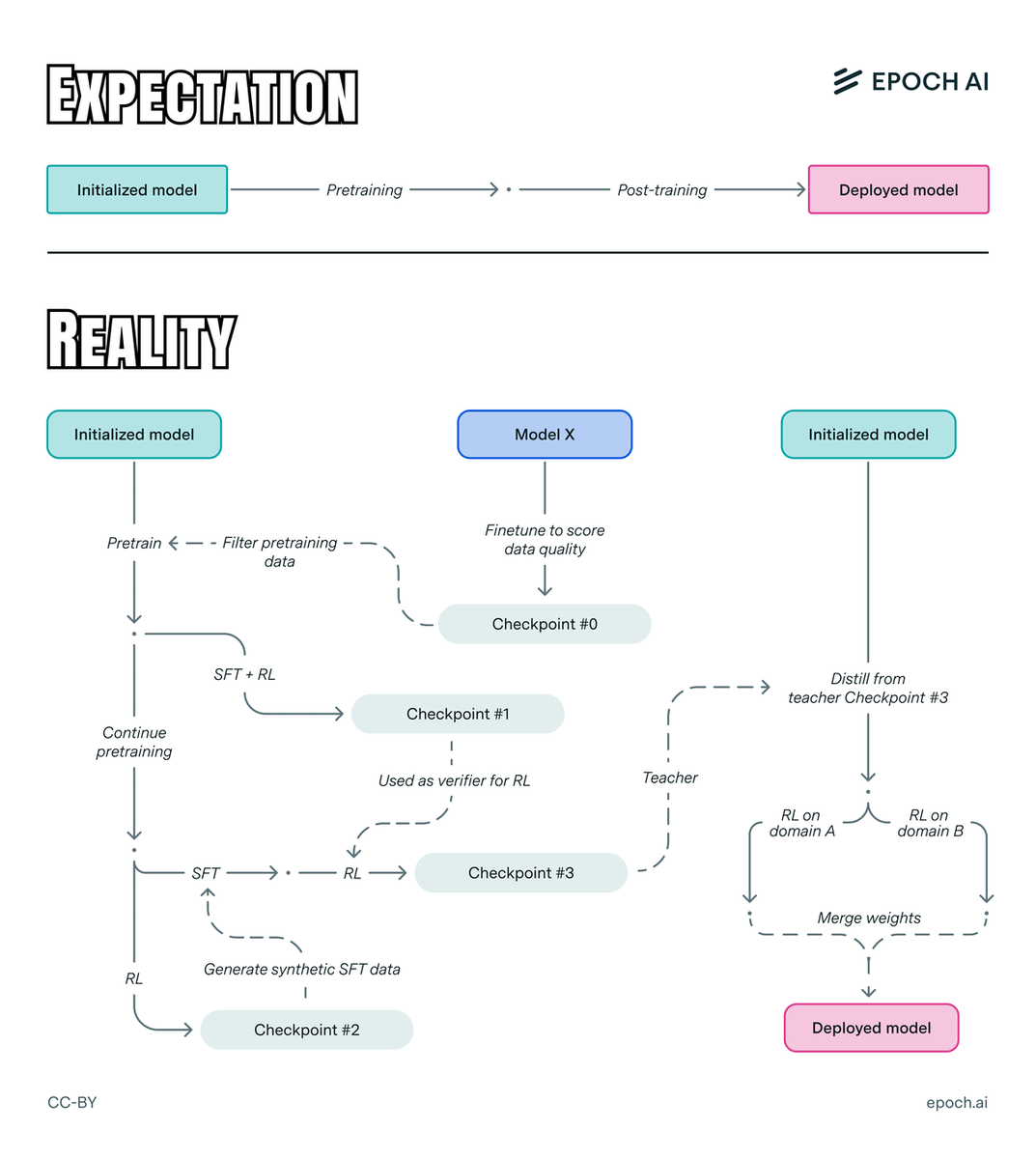
Training isn’t just a matter of “pre-training + post-training” — it’s way more complicated than that.
And we can say similar things about how we split up tasks: we’d ask if a task could be split into subtasks that would plausibly be automated at very different times — if we could, we’d split it up. We also tried to be more granular around tasks that require some amount of “taste” (such as whether to scale up a particular post-training recipe), since people seem to disagree about this. But you could choose different levels of granularity for sure.
In general, we’d be very excited about collaborating with people to improve on our initial attempt. If you’re an AI researcher and think that we’ve messed up something in our classification or task descriptions, please share feedback or reach out! Or if you’re somebody who’d use something like an O*NET for AI R&D in your work, we’d love to talk to you and understand how we can improve things to suit your needs.
If this project goes well, we hope that it’ll serve as a stepping stone toward more directly tracking AI R&D automation, helping AI forecasters extrapolate trendlines further forward — and hopefully also tell us if the intelligence explosion is upon us.
We’d like to thank David Owen, Stefania Guerra, Robert Sandler, and Elliot Stewart for their feedback and support.
Please also see our initial attempt and the accompanying feedback form. For direct corrections or specific inquiries, you can email js@epoch.ai.
-
Depending on how you define it, an intelligence explosion could “start” well before fully automating AI research, because AIs would likely provide substantial uplift prior to that.

-
It’s possible that future AI systems make progress through routes that just really do not resemble current human AI R&D. If so, a task list based on current human workflows would completely miss the action, and our ontology would need to be updated at the very least.
About the authors


