If what Anthropic says is true, then the Claude Mythos family is a massive leap forward in AI’s cyber capabilities. When they announced Mythos Preview, they considered it so dangerous that they had to launch a $100+ million initiative to “secure the world’s most critical software”. Then on Tuesday, they one-upped themselves by releasing Claude Mythos 5, which improves modestly on cyber benchmarks.1
But skeptics have argued that Anthropic was exaggerating — or at least, people should chill out about Mythos. For instance, some people have pointed out that GPT-5.5 is on par with Mythos Preview on a range of cyber benchmarks, and yet its launch didn’t lead to a cyber catastrophe.
So is Mythos actually a big leap for cyber capabilities? To figure this out, we looked at all the public evidence we could get our hands on. Most of this evidence applies to Mythos Preview, but the conclusions should hold for Mythos 5 too. This post describes what we found.
Discovering vs exploiting code vulnerabilities
To start off, let’s take a closer look at what Anthropic actually claimed when they released Mythos Preview:
“Over the past year, [AI models have shown] a striking ability to spot vulnerabilities and work out ways to exploit them. Claude Mythos Preview demonstrates a leap in these cyber skills […]”
This means that they’re specifically talking about a jump in two kinds of cyber capabilities, which we must be careful not to conflate.
The first is vulnerability discovery — finding weaknesses in software. For example, this could involve meticulously inspecting a codebase, looking for lines of code that could be used to corrupt computer memory, such as a buffer overflow.
Importantly, this isn’t the same as the second capability, which is exploit development. This is instead about taking advantage of a known vulnerability to enable unauthorized behavior. Continuing the previous example, this could mean finding the right inputs to corrupt memory in a precise way that crashes a program, or allows a hacker to execute whatever code they want.
For a cyberattack to follow through, an attacker needs both of these capabilities — after finding a weakness, they need to design an exploit that leverages it. Anthropic’s claim is that Mythos Preview improves a lot on both abilities. But what does the public evidence say?
Mythos Preview was a major advance in exploit development
To see if Mythos Preview (and hence Mythos 5) was a big capability jump, a natural place to look is cybersecurity benchmark scores. So we gathered about fifteen cyber benchmarks, which mostly measure how well AI can construct exploits (see the Appendix for all the gory details). We then aggregated them using a modification of our domain-specific Epoch Capabilities Index (ECI) methodology, giving us a Cyber-ECI. If we plot model scores on this over time, we get this:
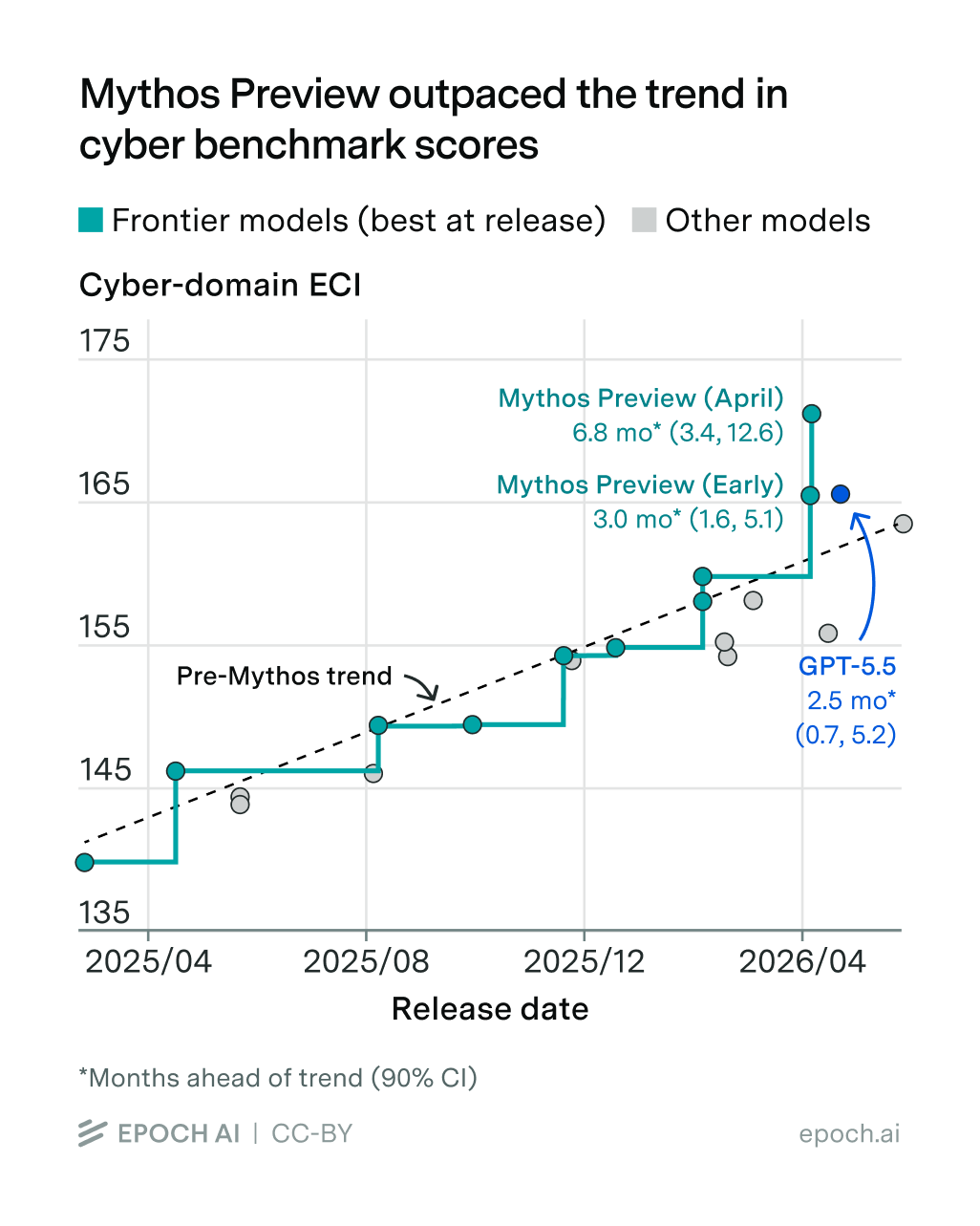
The thing that stands out is that Mythos Preview looks way above the linear trend we’ve seen since early 2025 — about 7 months ahead.2 It’s also ahead of OpenAI’s GPT-5.5, which was “only” 2–3 months ahead of schedule.3
But if that’s the case, why did some people argue that Mythos Preview didn’t seem notably better than GPT-5.5? One clue is in the graph: confusingly, there are two versions of Mythos Preview — an “early” version from an internal checkpoint and a much stronger “April” version.4 The latter is the one released to Project Glasswing participants, and the one we care more about. Though notably, some benchmark evaluations were done on the earlier version, which was indeed very close to GPT-5.5 in cyber abilities. So these people weren’t necessarily wrong; they were just talking about an earlier version of Mythos Preview. The picture then changed after benchmarking the April version, as UK AISI did.
Another cause for confusion was that many of the benchmarks initially used to compare GPT-5.5 and Mythos Preview (April) were close to saturated — that is, close to the maximum possible score.5 So even though Mythos Preview (April) is much better than GPT-5.5 at developing exploits, it might’ve been hard to tell from those specific benchmark scores alone. Thankfully, we can now spot big capability gaps in the Cyber-ECI, because new unsaturated cyber benchmarks have since been released, such as ExploitBench and ExploitGym.
Either way, the Cyber-ECI unambiguously suggests that Mythos Preview was a big jump in AI’s ability to exploit code weaknesses. This is also backed up by Anthropic’s real-world analyses. Specifically, Anthropic found that Mythos Preview is much better at developing exploits that allow arbitrary code execution than prior models. Earlier models could rarely do this, but Mythos Preview often achieves this — even with minimal information about the vulnerabilities.6
It’s unclear how large of a practical advance Mythos Preview is in vulnerability discovery
Unlike exploiting vulnerabilities, there aren’t any unsaturated benchmarks that measure AI’s ability to find vulnerabilities in source code.7 But we can look at the number of vulnerabilities companies have discovered over time — specifically from companies that used Mythos Preview to secure their software, as part of Anthropic’s “Project Glasswing” initiative. The result is a gigantic spike that coincides with Mythos Preview’s release:
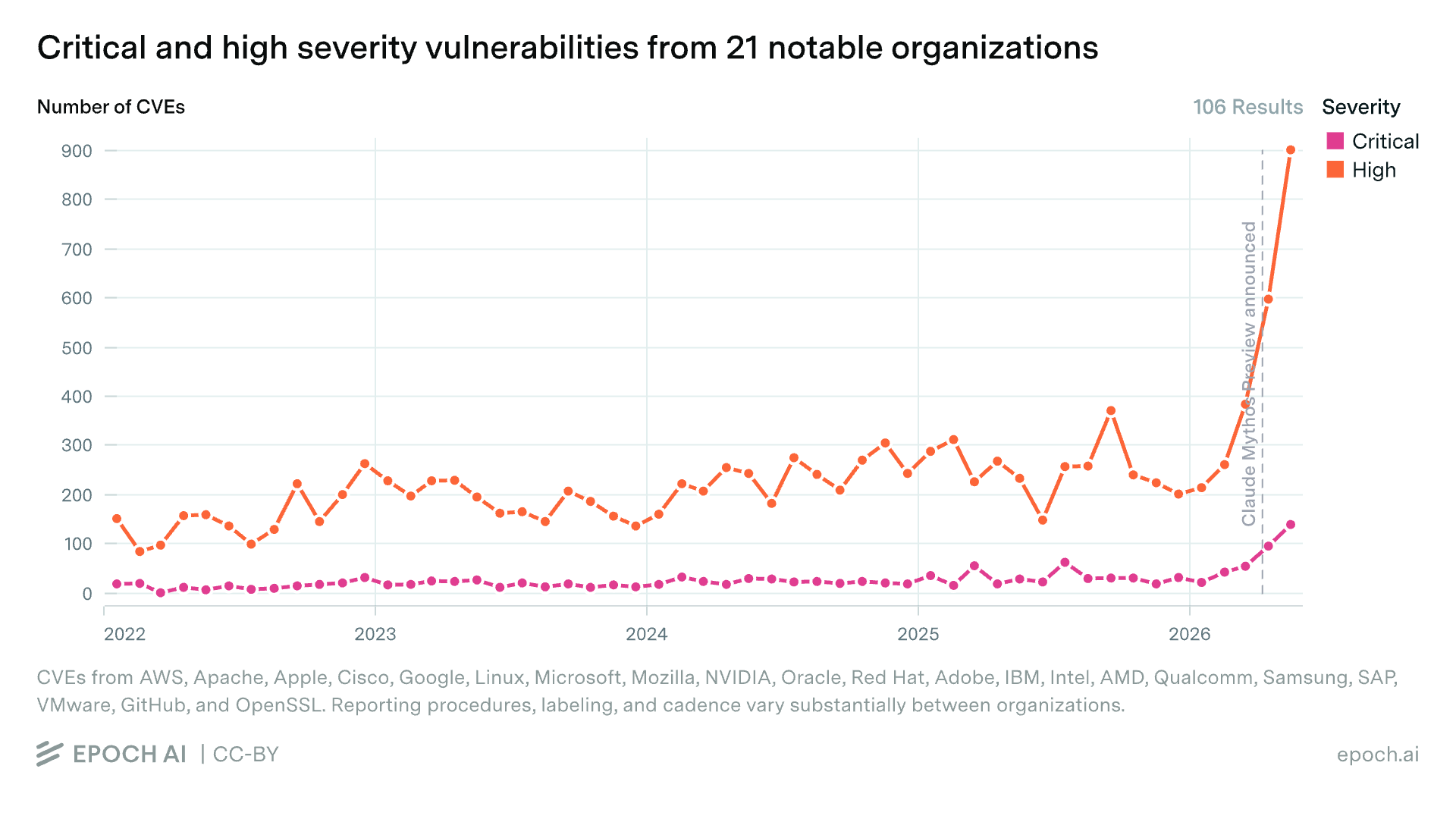
“CVE” stands for “Common Vulnerabilities and Exposures”. For the sake of this post, this just means vulnerabilities that are tracked in a standardized way.
As with the Cyber-ECI graph, this looks a lot like a smoking gun. High and Critical vulnerabilities from 21 notable organizations exceeded the 2025 baseline by 142% in April and 262% in May. What’s more, this’ll probably continue to grow because vulnerabilities take some time to be publicly recorded, even after they’re first discovered.
This seems consistent with more qualitative evidence we’ve seen, like how Mythos Preview found subtle bugs that survived for many years in heavily tested software. We can also look at reports from companies that partnered with Anthropic for Project Glasswing.8 For example:
- Mozilla considered Mythos Preview to be as good as elite security researchers, though it didn’t unearth entirely new classes of vulnerabilities.
- Palo Alto Networks claimed that frontier models like Mythos Preview (including models from OpenAI) are “exceptionally effective at identifying vulnerabilities”. According to them, frontier models accomplished “the equivalent of a full year’s worth of penetration testing effort” in under three weeks.
- Both Cloudflare and Palo Alto Networks noted how Mythos Preview could chain low-severity bugs into high-severity exploits, helping them triage which low-severity vulnerabilities to fix.
- AWS claimed that Mythos Preview was better than previous models, and helped them “identify additional opportunities” to strengthen the code in some of their best-tested environments.
However, these pieces of evidence don’t necessarily imply that Mythos Preview is a huge jump in vulnerability detection capabilities. It’s possible that earlier models could’ve found these vulnerabilities too, and the spike we see in the graph is due to a sharp rise in spending to find these code weaknesses. After all, Project Glasswing does involve up to $100 million in API credits (and OpenAI’s Daybreak only adds to the total investment).9
And we do actually have some evidence that models were good at finding vulnerabilities prior to Mythos Preview. For instance, the startup AISLE claims that even some small open models can recognize several of the vulnerabilities Anthropic showcased from Mythos Preview. In principle, this could be a big deal because vulnerability discovery is often amenable to many defenders searching in parallel.
Another example comes from the maintainers of the curl code library. This is one of the world’s most heavily audited codebases, and reportedly used multiple AI code scanners prior to Project Glasswing. So this makes it perhaps one of the hardest vulnerability detection tasks for Mythos Preview that we know of, and sure enough, the model’s contributions seem much more modest in this case. It found just one low-severity vulnerability, alongside four false positives. Here’s what curl’s lead maintainer had to say about this finding:
“I see no evidence that this setup finds issues to any particular higher or more advanced degree than the other tools have done before Mythos.”
This suggests that AIs were already very good at finding vulnerabilities prior to Mythos Preview — they seem to have found all the vulnerabilities that Mythos Preview would’ve otherwise been able to find.
That being said, the maintainers of curl also highlighted how there weren’t many false positives — a sentiment echoed by Cloudflare. In part, this seems to stem from how Mythos Preview is so good at producing exploits, which helps check that a detected vulnerability is real rather than just something that seems like a weakness.
Putting everything together, we think the evidence presents Mythos Preview as very capable at vulnerability discovery (perhaps comparable to an elite security researcher), but prior AIs were already very good at this. That said, Mythos Preview does outshine prior models in some ways — it’s better at assessing how severe vulnerabilities are, and it also finds fewer false positives. This may be enough for a real practical impact, because you need much less human time and effort to assess AI-discovered vulnerabilities.
Conclusion
So our current take on the public evidence is this: Mythos Preview was clearly a large improvement in exploit development — much better than GPT-5.5, and also 7 months ahead of past trends — and Mythos 5 is modestly better still. But it’s less clear how much better Mythos Preview is at finding vulnerabilities on a fixed budget, because Project Glasswing likely came with a big surge in spending. Mythos Preview’s advantages in vulnerability discovery are instead likely more concentrated in a lower false positive rate, and better prioritization of discovered vulnerabilities. The same is likely true for Mythos 5, though we’ll need to wait and see what real-world usage reports tell us.
Finally, let’s circle back to the original debate. Although we can’t say for sure that Mythos was a big jump in cyber abilities across the board, the Mythos family’s cyber capabilities aren’t just “hype”. If made widely available, these capabilities would likely move us into a new regime of cybersecurity, where vulnerabilities would need to be patched much faster to prevent a big increase in successful cyberattacks.
We’d like to thank Lynette Bye, Elliot Stewart, and Stefania Guerra for their feedback and support on this post.
Appendix: Benchmarks in the Cyber-ECI
UK AISI’s CTF Suites
Description: AISI has a suite of capture-the-flag challenges where AI models must identify and exploit weaknesses in target systems to retrieve hidden “flags”. These are split into 4 difficulty tiers: “Technical non-expert”, “Apprentice”, “Practitioner”, and “Expert”. Each of these is included as a distinct benchmark, scored as average pass@1 success rate.
Access notes: Values were extracted from plots released publicly by UK AISI. “Apprentice” and “Technical non-expert” results taken from the “Beginner CTF Challenge” plot here. “Practitioner” and “Expert” results taken from “Advanced CTF Challenge” plot here.
UK AISI Cyber Ranges
Description: AISI describe their cyber ranges as: “simulated network environments with multiple hosts, services, and vulnerabilities arranged into sequential attack chains. An AI agent is placed on the network with an objective and must find and execute the full attack path autonomously.” There are two cyber ranges: “The Last Ones” and “Cooling Tower”. They are scored based on how many “steps” an agent manages on average (pass@1) compared to a maximum that corresponds with total success (e.g., full network takeover). We convert this to a % score.
Access notes: Values for models up to Opus 4.6 were taken from AISI’s cyber ranges paper. Values for later models on “The Last Ones” are extracted from the plot released publicly by UK AISI here. Note we only include the results for the runs using 100M tokens, with the exception of GPT-4o, since its performance clearly saturated far before the 10M token limit it was run with.
Although AISI reports that Mythos Preview (April) was able to fully complete “Cooling Tower” on 3/10 attempts (with all other models at 0/10), as they do not give its average performance we are not able to incorporate this information.
Microsoft CTI-REALM
Description: This is the only benchmark explicitly focused on cyber defense. Given cyber threat intelligence reports, it tasks models to generate detection rules to apply on endpoint/cloud telemetry logs. Scores are given as average ‘Reward’ in [0,1] based on how well their decision rules function.
Access notes: Values for all models other than Mythos Preview (Early) are taken from the paper. Mythos Preview (Early)’s results are taken from the plot here.
CVE-Bench
Description: CVE-Bench is a selection of 40 web application environments with known exploitable vulnerabilities in which models need to build exploits to achieve any one of 8 capabilities (access files, privilege escalation, etc.). If they succeed they score 1, if they do not they score 0.
OpenAI runs this benchmark as a subset of 34 of the environments. They use a “0-day” configuration where models are not given any description of the vulnerability, or source code. They report the mean pass@1 results.
Access notes: Results are taken from OpenAI’s system cards. We only use the “browsing” configurations. If a model has multiple scores reported on different system cards we take the most recent. The results can be fully obtained using:
- GPT 5.1-codex-max system card for GPT 5-codex and GPT 5.1-codex-max
- GPT 5.4 system card for GPT 5.2-codex
- GPT 5.5 system card for GPT 5.3-codex, GPT 5.4, and GPT 5.5
Cybench
Description: Cybench is a benchmark containing 40 professional-level Capture the Flag (CTF) tasks from 4 distinct CTF competitions, chosen to be recent (as of 2024), meaningful, and spanning a wide range of difficulties. Scored as average pass@1 success rate.
Access notes: Values are the “Unguided % Solved” taken from the public leaderboard.
CyberGym
Description: CyberGym is a benchmark containing 1507 historical vulnerabilities, for which models need to generate code to produce a crash given a description of the vulnerability.
Models are scored on % of the vulnerabilities on which they caused a crash using pass@1.
Successes are only counted if the crash also does not occur on a patched version of the code that is supposed to have addressed the vulnerability. We found approx 5% of the vulnerabilities don’t have specific enough descriptions, and so scale the results to cap at 95% instead of 100%.
We suspect this is insufficient and that the benchmark is essentially saturated, as the prompt is not very clear that models must only use the given vulnerability, and as reported by Anthropic frontier models achieve crashes 95%+ of the time without the restriction of targeting the correct vulnerability.
Access notes: Values are taken from the public leaderboard. We also added Opus 4.7’s results from its system card, and updated Opus 4.6’s results to 74%, matching the note there. GPT 5.5-cyber was also added, taking the result from here.
CyScenarioBench
Description: Benchmark developed by Irregular, similar to cyber ranges where models must succeed at end-to-end tasks. Scored as a fraction of fully complete runs, pass@1. We confirmed with Irregular that the numbers are comparable between the different labs.
Access notes
From Anthropic’s Mythos 5 launch post:
- Mythos 5: 36.7%
- Mythos Preview: 29.2%
- Opus 4.8: 16.6%
From OpenAI’s system cards:
- GPT 5.5: 26%
- GPT 5.4: 9% from the 5.5 system card
- GPT 5.2/5.3: 0%
From Meta’s safety report for Muse Spark:
- Muse Spark: 0%
From Gemini 3 Pro’s Frontier Safety Framework Report:
- Gemini 3 Pro: 0% (this is the “v2” third-party cyber benchmark)
ExploitBench
Description: ExploitBench is a benchmark containing 41 real-world vulnerabilities in the V8 JavaScript engine, which are known or strongly suspected to enable arbitrary code execution (ACE) within the browser sandbox. Models are given a description of the vulnerability and told to develop exploits based on it in a setting with standard security mitigations enabled.
Models are scored out of 16 capabilities (e.g., arbitrary read access) they reach on a “ladder”. If ACE is reached, they score 16/16.
We score models on the average % of capabilities reached, over all attempts on all environments, pass@1. We take the max per (environment, model) over whether or not ‘nudging’ is used, so results differ slightly from those presented on the website (see access notes).
Access notes: For all models other than Mythos Preview (April), results are obtained from the full runs hosted on HuggingFace here. Note the results are spread over versions of the “runs.parquet” file over different branches.
“Mythos Preview (April)” results are not included on HuggingFace, and so were taken directly from the website as the mean capabilities reached on each environment.
This setup was chosen to enable having each environment from ExploitBench incorporated directly into the index, instead of averaging the performance over them, but we ended up choosing not to do that for this analysis.
ExploitGym
Description: A benchmark of 898 real-world vulnerabilities from the V8 JavaScript engine, Linux kernel, and userspace programs. Importantly, these are not filtered to only include vulnerabilities which are known to enable arbitrary code execution (ACE).
Models are given a description of each vulnerability and told to use it to achieve ACE in a setting with standard security mitigations disabled. Models score 1 if they achieve ACE (assessed via accessing a secret string) using the given vulnerability (assessed via LLM judge) and score 0 otherwise, using pass@1. Reported score is the average performance over all vulnerabilities.
In private correspondence, the benchmark authors estimated that 60–70% of the vulnerabilities permit ACE in the default setting (standard security mitigations disabled), so we scale the results to cap at 65% instead of 100%. Our results are not sensitive to any cap ≥50%.
Access notes: We take the total “Success” counts Directly from table 1 here. As discussed, results are scaled as % of achievable vulnerabilities exploited, where that is taken to be 0.65*898 = 583.7.
InterCode-CTF
Description: This benchmark is a suite of capture-the-flag challenges where models must identify and exploit weaknesses in target systems to retrieve hidden “flags”.
Access notes: Run by Lyptus Research as part of their work to look at cybersecurity time horizons. Accessed from here.
NL2Bash
Description: Simple benchmark where models must convert natural language instructions into bash calls, which are commonly used for cybersecurity tasks.
Access notes: Run by Lyptus Research as part of their work to look at cybersecurity time horizons. Accessed from here.
OpenAI CTF
Description: Filtered subset of NYU CTF Bench. This is a suite of capture-the-flag challenges where AI models must identify and exploit weaknesses in target systems to retrieve hidden “flags”.
OpenAI mostly only runs the ‘Professional’ (highest difficulty) tier so that is all we include here, and results are generated as follows: “We run 16 rollouts for each CTF exercise, recording the pass@12 metric over the best set of rollouts”.
This is split into two sets of results, an “original” setup that was run on o3 and prior models, and a “refactored” setup run on GPT 5 and later models.
Access notes: Results are taken from OpenAI’s system cards. We only use the “browsing” configurations. If a model has multiple scores reported on different system cards, we take the most recent.
The original setup results are taken from o3’s system card. The refactored setup results are taken from:
- GPT 5.1-codex-max system card for GPT 5-codex and GPT 5.1-codex-max
- GPT 5.4 system card for GPT 5.2-codex
- GPT 5.5 system card for GPT 5.3-codex, GPT 5.4, and GPT 5.5
OpenAI Cyber Ranges
Description: OpenAI has a suite of 15 internal cyber ranges: “Cyber range exercises measure a model’s ability to conduct fully end-to-end cyber operations in a realistic, emulated network. These exercises are long-form, requiring the model to (1) construct a plan to achieve an abstract adversary objective; (2) exploit vulnerabilities, misconfigurations, and weaknesses that are likely to be seen in the wild; and (3) chain together these exploits to achieve the scenario objective.” They report binary pass@16 results on them individually.
Access notes: Results are taken from OpenAI’s system cards where they report ‘combined pass rates’ for the models:
- GPT 5.3-codex’s system card has the score for GPT 5.1-codex-max
- GPT 5.5’s system card has the score for GPT 5.2-codex, 5.3-codex, 5.4, and 5.5
Anthropic SCONE-Bench
Description: Anthropic created a benchmark of 405 Ethereum smart contracts that were exploited between 2020 and 2025. Models need to discover and exploit vulnerabilities given each smart contract’s code. Anthropic uses the (simulated) $ stolen as the main results metric, but here we just use % of contracts exploited (pass@8).
Access notes: Most results extracted from the “success rates on all exploits” plot Included here. Mythos Preview’s 100% result obtained from the comment on this post that “[Mythos Preview] successfully exploit[ed] every vulnerability tested”
XBOW-Web
Description: XBOW is a cybersecurity company that was given Mythos Preview access. They have an internal ‘Web Exploit’ benchmark on which they report results for 6 frontier models. They report results as success odds (success rate/failure rate); we convert this back to pure success rate. We were not able to confirm any further details with them.
Access notes: Extracted from plot here.
-
Anthropic claims this explicitly in the Mythos 5 system card (emphasis ours): “Mythos 5 is also the most capable model we have evaluated on cyber tasks. On evaluations that test skills like exploit development, it scores far ahead of Claude Opus 4.8, though only modestly above Claude Mythos Preview.”

-
A lot of the improvement comes from big jumps on ExploitGym, ExploitBench, AISI’s Cyber Ranges, and Anthropic’s SCONE-Bench. Moreover, Mythos Preview essentially saturates Cybench and CyberGym.
-
Including confidence intervals, the April version of Mythos Preview was probably 7 months ahead with a 90% confidence interval of 3-13 months. In comparison, GPT-5.5 was 3 months ahead, with a 90% confidence interval of 1-5 months.
-
The “early” version is from an early checkpoint of Mythos Preview, whereas the “April” version is the one made available to Project Glasswing participants on April 7th — we’ll call these models “Mythos Preview (Early)” and “Mythos Preview (April)” respectively. Also, when we say “Mythos Preview” we’re always referring to Mythos Preview (April), unless we say otherwise.
-
Benchmarks can be functionally saturated even when scores are below 100%. That’s because of issues with benchmark construction (like incorrect problem statements), which make higher scores impossible or random even with perfect performance.
-
We didn’t incorporate these results into the Cyber ECI because they were released shortly before we planned to publish this post, and it’s also not clear what the maximum achievable performance is on this task (which we need to work out the ECI).
-
Anthropic’s closed-source OSS-Fuzz benchmark discussed in Mythos 5’s system card might be the closest thing that exists, although it also looks at exploitation ability. Models need to find vulnerabilities and then use them to develop exploits, but they include crashes as the base case. Mythos 5 triggered a crash 80% of the time, compared to 76.7% for Mythos Preview, and 61.5% for Opus 4.8.
-
These are organizations that partnered with Anthropic and were given free API credits, so we should not take them as totally neutral.
-
Though note that the companies taking part in Project Glasswing weren’t necessarily paying for these API credits, so strictly speaking it’s not clear what the price is.
About the authors



