
Can AI systems improve at challenging tasks on the fly, performing them over and over and learning from mistakes? It’s one of the biggest open questions in AI capabilities right now, with large economic and safety implications. Our latest benchmark, EBR-bench, tests AI systems for this ability by having them play Earthborne Rangers, a complex board game, repeatedly. So far, we see little evidence of AI learning from experience. With EBR-bench as part of our benchmarking suite, we have a new tool for detecting if and when that changes.
Learning to play games is a proxy for important capabilities
An AI system that could pick up unfamiliar tasks on the fly would be much more capable than we’re used to. Even if it didn’t perform well out of the box on some economically relevant task, it could still learn “on the job”. It would also be harder to determine whether it had dangerous capabilities prior to release, since it could gain such capabilities through learning. We think learning to play games is a reasonable proxy for these more impactful kinds of learning. Whether it’s a new job or a novel scientific understanding, the core activity of figuring something out from scratch is similar.
But not every game is a good test: we want games where AI systems start out weak, but nothing obviously prevents them from improving. To avoid AI systems being familiar with the games from training, it’s useful that they be somewhat obscure. Since AI systems are already fairly capable at a wide range of one-off puzzle games, it’s useful for the game to require a layered mix of strategy and tactics and to play out over a relatively long time horizon. We also prefer text-based games since many AI systems are weaker at multimodal reasoning: we want to rule that out as the primary cause of poor performance.
Earthborne Rangers (EBR) fits this bill well. It’s a campaign-style game where a player explores a wilderness landscape, overcoming obstacles and pursuing objectives. The game is relatively obscure, almost entirely card-based with very little spatial reasoning, and requires a mix of strategy and tactics around deck-building and turn-by-turn play. A single playthrough of the part of the game our benchmark covers takes humans 2–4 hours, and mastering the game can require dozens of playthroughs.12
AI doesn’t improve at EBR with repeated play
In our setup, we have AI systems play through the game many times (10 or 30, depending on settings). We give them the rulebook, a card database, and the game’s map of locations.3 We tell them their goal is to maximize the score they achieve on the final 20% of playthroughs. We encourage them to take notes and learn from mistakes. And yet we see very little evidence that the AI systems are learning from their engagement with the game.
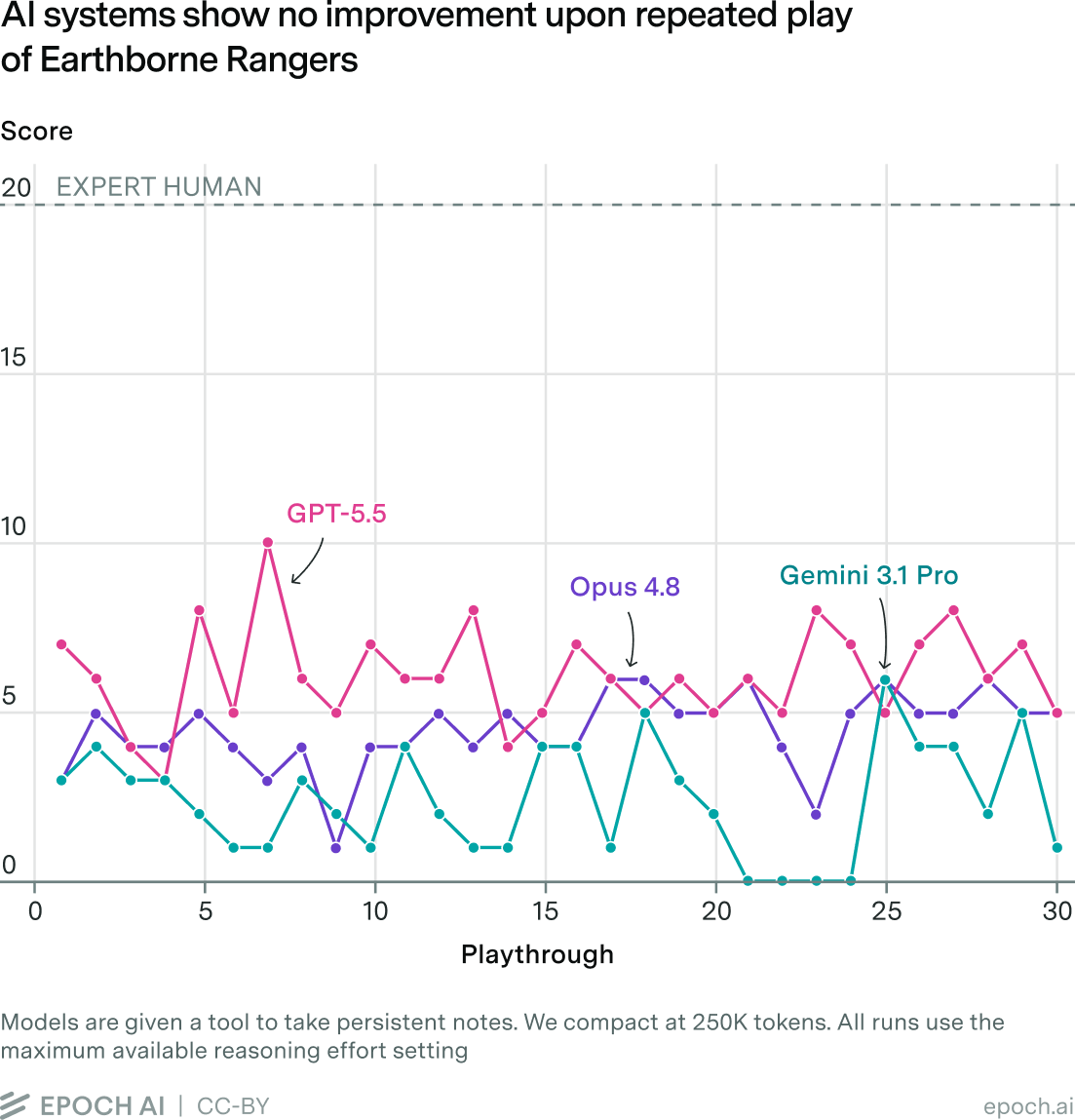
Frontier AI systems aren’t terrible at the game. We expect that they achieve stronger performance on their first playthroughs than many inexperienced humans would.4 Their scores have also improved modestly over the past year, with GPT-5.5 and Opus 4.8 outscoring GPT-5 and Opus 4.1.5 However, this is due to higher initial scores, not on-the-fly learning. We see no evidence that the ability to learn on the fly has improved at all over this time period.

In the rest of this post, we’ll discuss AI performance on the game in more detail, describe future plans to see if we can elicit better performance, and conclude with some discussion of how these results affect our broader understanding of AI capabilities.
Agents manage tactical execution poorly
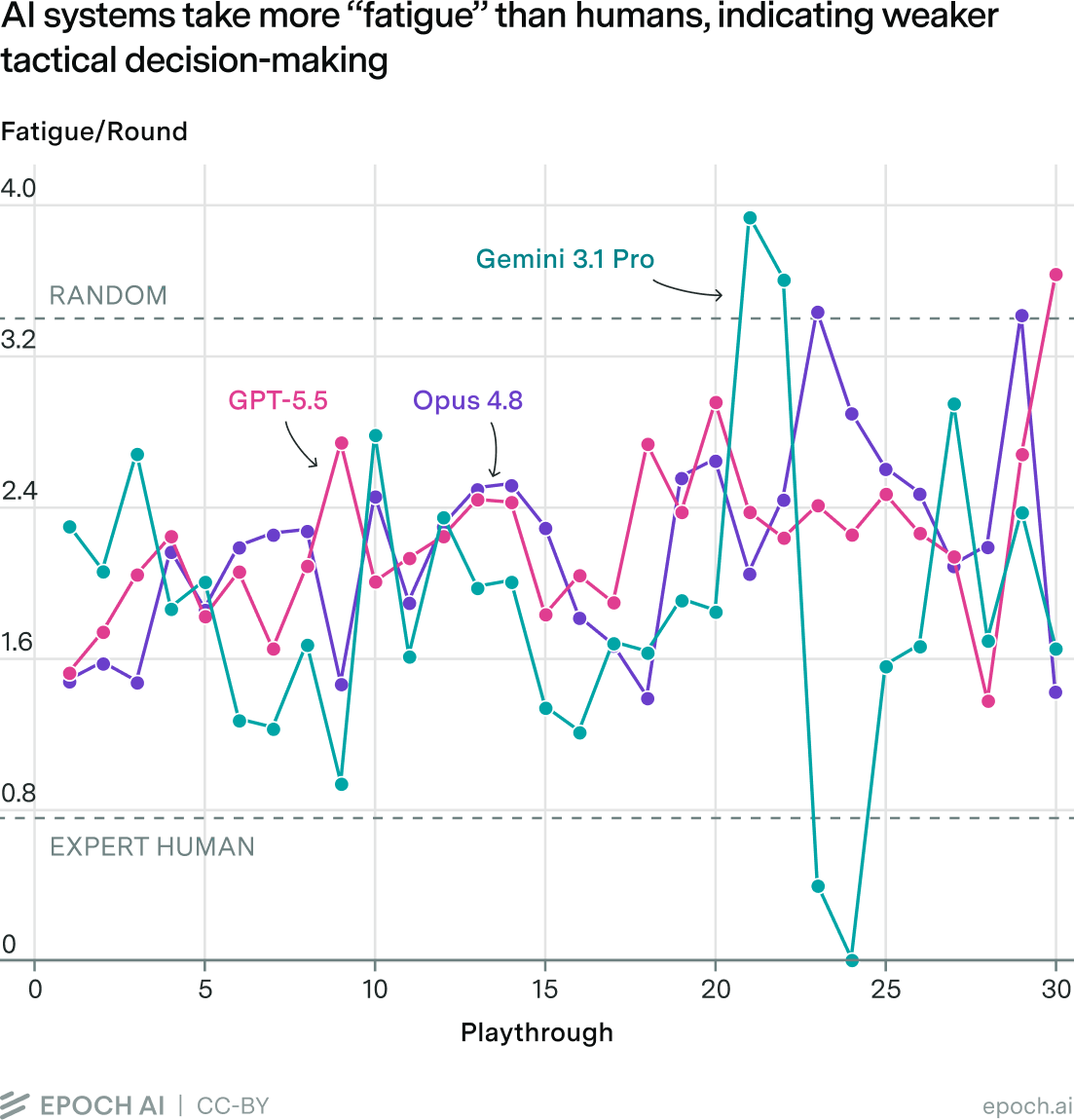
The primary tactical mistakes that the agents make involve an in-game mechanic called “fatigue”, which is similar to “damage” in other games. The twist Earthborne Rangers adds is that, rather than damage reducing the player’s health points, incoming fatigue instead moves cards from the top of the player’s deck to their “fatigue stack”, and an in-game day ends when their deck runs out of cards. As such, the player’s “health bar”, “remaining time”, and “card resources” are all represented simultaneously by the number of cards left in their deck. So, in Earthborne Rangers, minimizing fatigue is key to success.
Managing fatigue is a tactical challenge that requires analyzing the current game state correctly and using cards efficiently. Enemy creatures and obstacles harry the player if the player fails to neutralize them before pursuing objectives. An expert human player will cost-efficiently neutralize sources of fatigue each round, leaving plenty of resources to pursue objectives. In contrast, AI agents often recklessly pursue objectives and take on unnecessary fatigue; they also often underutilize their resources.
An expert human player can keep average fatigue per round to about 0.6, which corresponds to a player having about 15 rounds of gameplay per day before their deck is exhausted. Completely random gameplay incurs 3.5 fatigue per round, corresponding to only about 5.3 playable rounds per day. AI systems are closer to the random baseline, with GPT-5.5 and Opus 4.8 both incurring 2.1 fatigue per round, enabling about 7.7 rounds of play per day.6 Fewer rounds mean less ability to achieve objectives. More than anything else, AI agents’ lack of improvement at basic tactics, failing to avoid the game’s main means of attack, puts a hard cap on their scores.
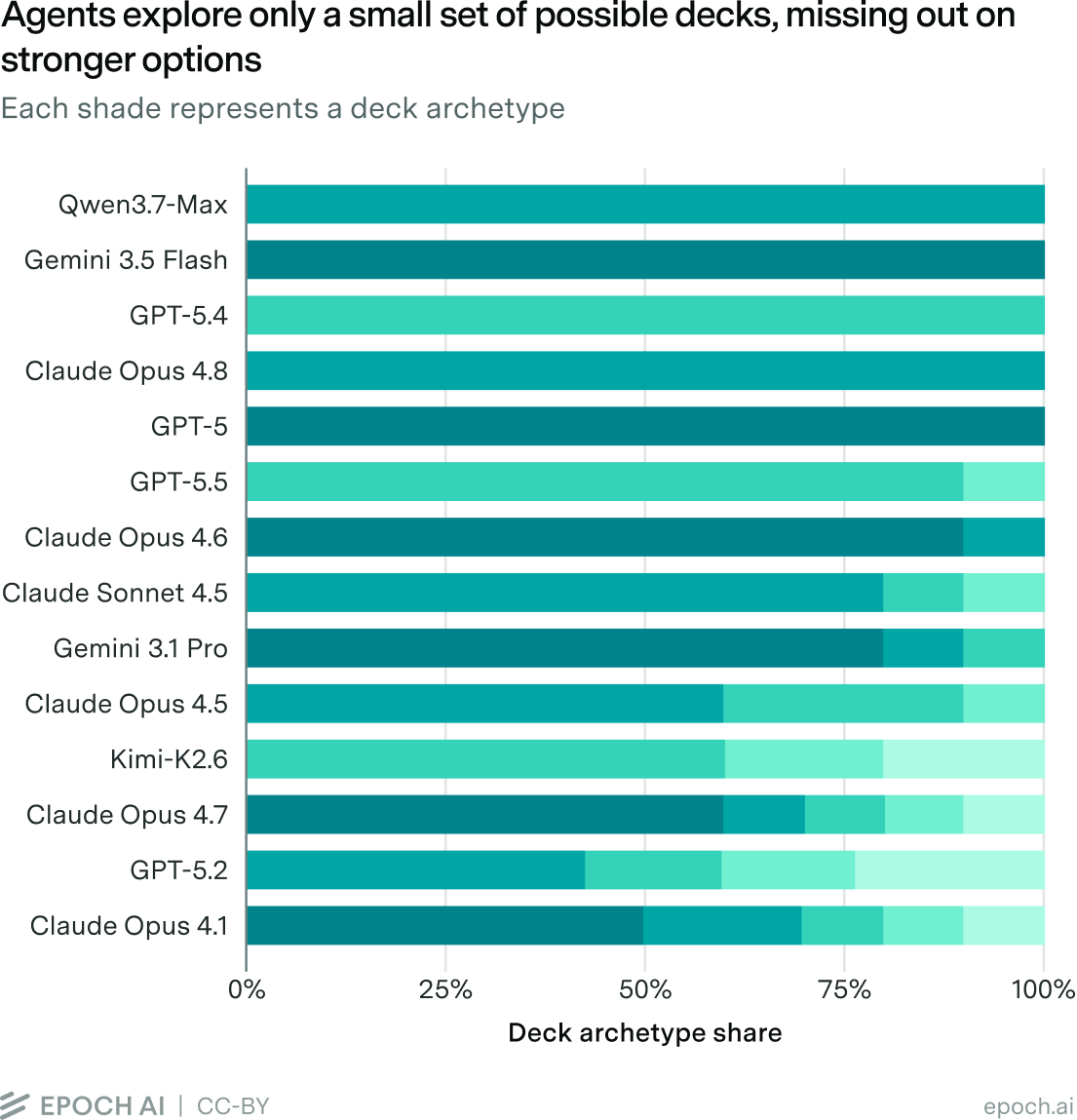
Agents underexplore strategic options
Before a playthrough begins, players build a 24-card deck. A deck’s power level can vary drastically. The maximum score achievable by the strongest deck might be twice that of the weakest deck. A player’s starting deck choices for each playthrough are therefore the highest-stakes decisions they will make in that playthrough. An intelligent player, with 80% of their allotted runs reserved for learning, would thoroughly explore a variety of decks. AI systems, however, engage in comparatively little exploration.
Coarsely measuring deck types, we can consider the four “background”, four “specialty”, and two “role” cards that players choose from, giving 32 deck archetypes. Of course, decks also differ in more complex ways. But, even in this limited example, agents drastically underexplore the deck variety available, and there is no clear trend showing that more recent models explore more diverse deck archetypes.7
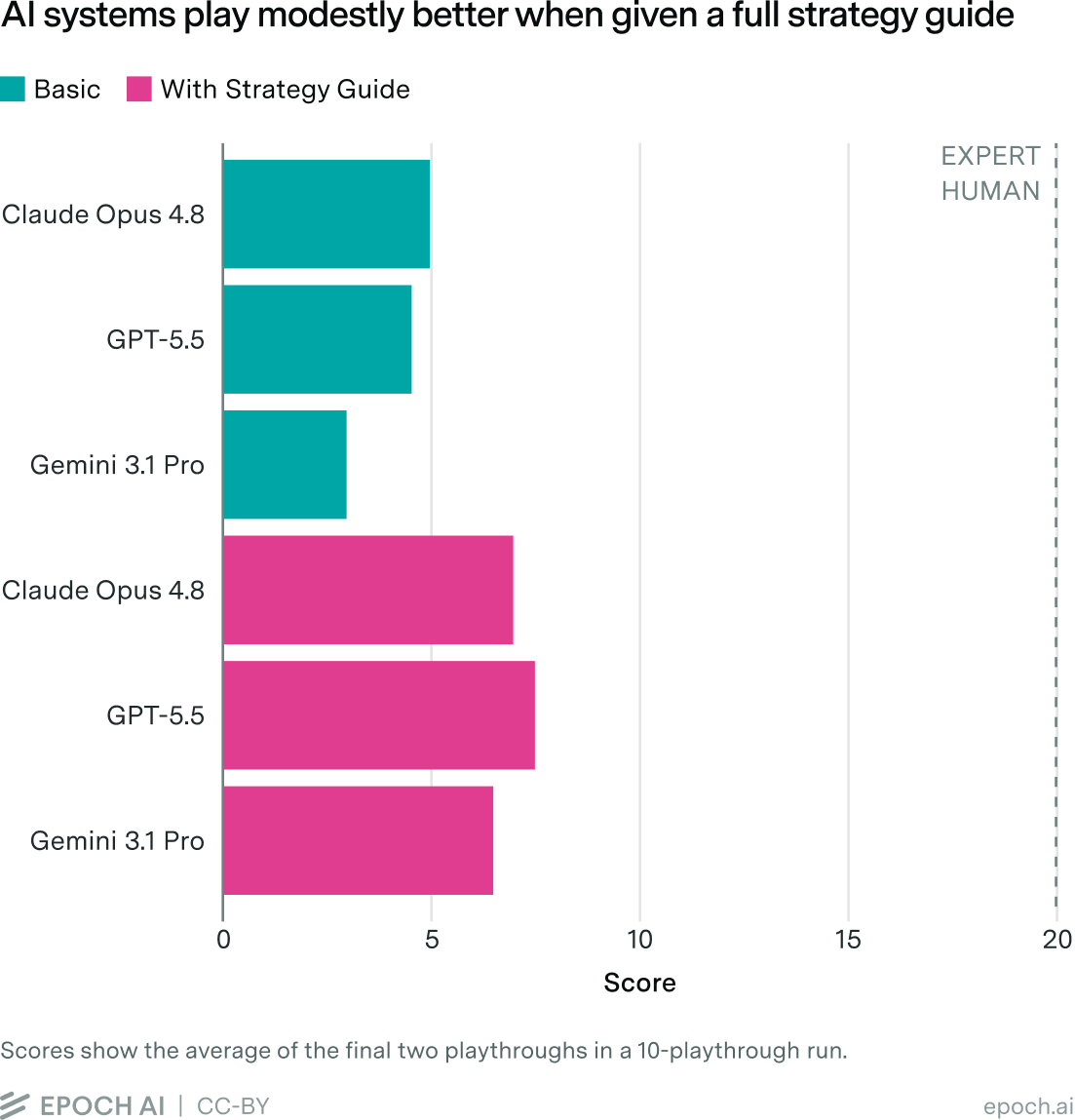
Agents struggle even when given an explicit strategy guide
In our basic setup, agents must take their own notes and learn their own lessons. Since they seem to struggle at this, what if we try to do this work for them? In our “max elicitation” setting, we give them detailed information about the game, including all the tactical and strategic advice that one experienced player could think of. Comparing this setting to the ten-playthrough “basic” setup, we see modest improvement. Namely, they achieve between 2 and 3.5 additional objectives (out of 21), depending on the model. But, considering that this approach essentially hands models the answer key, we consider the effect to be modest.
We’re curious to see how these abilities evolve. Will the impact of note-taking remain limited, indefinitely? Will agents simultaneously improve at taking notes and using those notes to improve their play? Or will there be a period in which agents can improve their play with externally supplied notes but can’t generate those notes themselves?
Elicitation gaps may remain
As with any negative claim about AI capabilities, there may be some fairly straightforward way to elicit stronger AI performance that we just didn’t find. In the future, we can try various levers, including:
- More tools, like code execution or web access
- Different scaffolds, like Claude Code or Codex instead of the simple ReAct harness we used
- Multi-agent setups
- Providing expert human playthrough transcripts to learn from
We conducted several ad hoc experiments that enabled code execution and also used Claude Code and Codex, and these didn’t show any significant performance improvements. Still, more experimentation seems warranted.
Out-of-distribution generalization remains limited—for now
Leading AI systems are not very good at this obscure, complex board game, even when allowed to play many times in a row. This is a useful data point to assimilate into a broad understanding of AI capabilities.
For one, it suggests that inference compute scaling doesn’t overcome every capability deficiency. The returns to repeated play for an out-of-distribution game appear minimal. Even when there is a concrete metric — like the number of objectives completed in EBR — it seems that AI systems cannot always optimize their way toward it.
It has also become harder to understand the boundaries of training distributions as AI companies put billions of dollars’ worth of data into them. But since it seems plausible that focused training could improve performance on EBR and similar games, it’s likely that AI companies simply haven’t prioritized doing so. Thus, we interpret our findings as evidence that AI systems remain fairly limited by their training distributions.
We will continue to evaluate new models on EBR-bench to see if this situation changes.
Epoch has used Earthborne Rangers content solely for the purposes of research and commentary. This work is conducted independently of Earthborne Games. Epoch does not distribute or sell access to the underlying copyrighted material from the game.
-
The game plays out over a number of “days”. It starts with a five-day introductory segment, with full games spanning 20–25 days. At present, we are only evaluating models on the initial five-day segment (i.e., AI agents play that segment repeatedly).

-
Our present understanding of human baselines is from the retrospective reflections of a single experienced human player who achieved a near-perfect score (95% of objectives achieved, where objectives consist of a mix of missions completed, rewards unlocked, and nontrivial “notable events” recorded) on a recent playthrough. We have more rigorous baselining studies underway.
-
For models that struggle with vision, we also provide a text-based pathfinding tool that helps agents plot out routes between target locations.
-
Our rough guess is that new players would score between 0 and 8 objectives out of 21 on their first playthrough, skewed toward the lower end. The game has a lot of rules and it takes a couple hours of effortful play for a human to internalize them properly.
-
Our estimates are noisy, but it’s not clear that more recent models have improved much. For instance, GPT-5.2 is plausibly about as good as GPT-5.5. We hope to do more statistically robust runs in the near future.
-
Gemini 3.1 Pro shows very low fatigue in runs where it decided to move on to the final 20% of scored runs. To do this, from runs 21 to 24, it ended playthrough as quickly as possible, triggering day-ending mechanisms that did not involve incurring fatigue.
-
If anything, more recent models are much worse on the deck diversity front, with the most diverse deck exploration coming from GPT-5.2 and Opus 4.1 trying four to five times as many decks as Opus 4.8.
About the authors

