80% of US adults who report using Claude in the previous week live in households earning $100,000 or more a year, compared to 37% of Meta AI users. Nationally, about 50% of US adults fall in this income bracket. Among Meta AI users, 32% live in households earning less than $50,000, compared to 7% of Claude users and 24% of US adults. Other major providers cluster in a relatively narrow band, with 56–64% of users in $100,000+ households and 15–22% under $50,000.
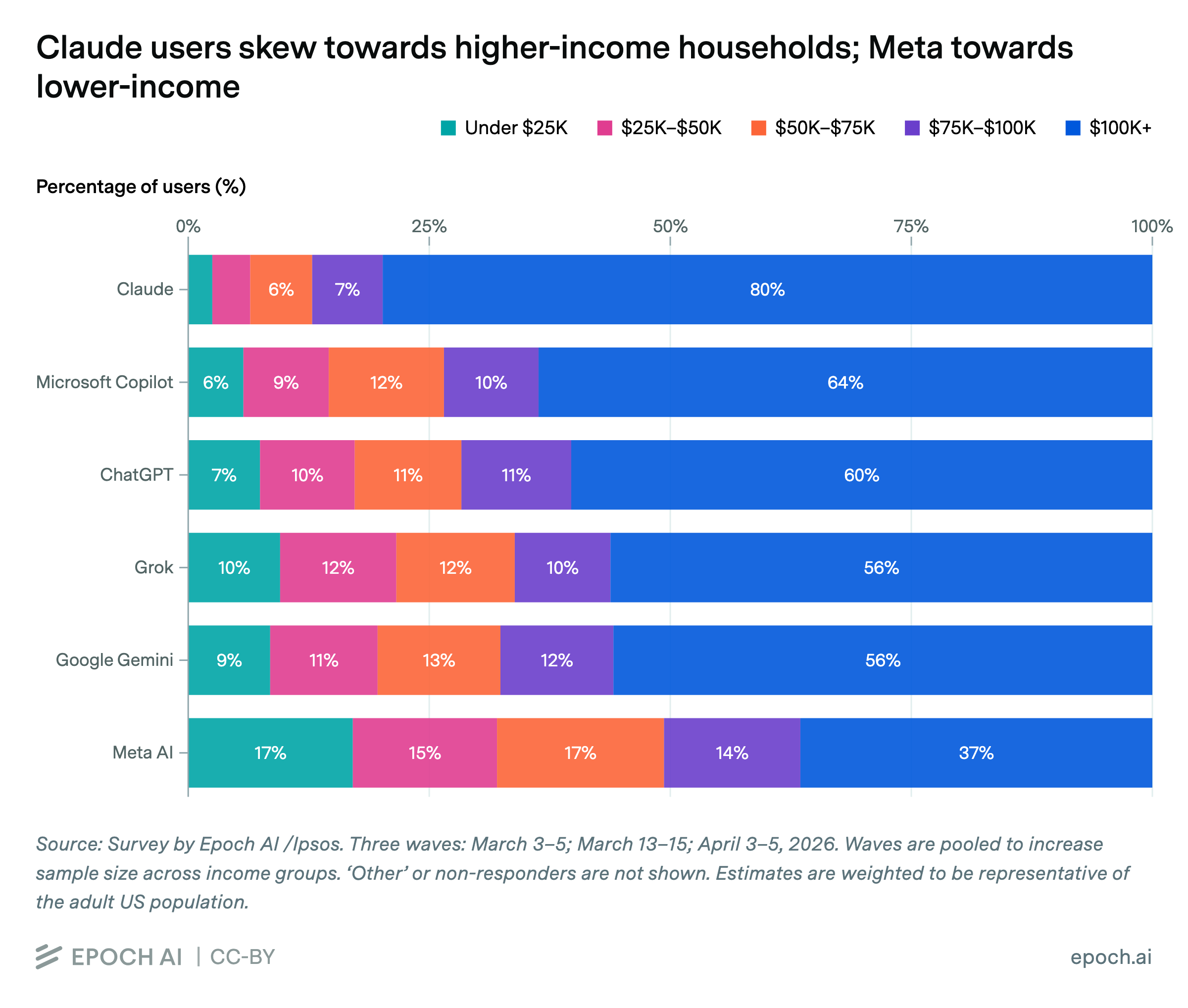
Results are based on three pooled waves of the Epoch AI/Ipsos survey (~2,000 respondents in each of waves 1–2, ~1,000 in wave 3). Participants reported which AI services (if any) they used in the past week. Respondents were recruited at random. Estimates are weighted to better reflect underrepresented groups, like those from lower socioeconomic backgrounds. Users may report using more than one AI service, so groups are not mutually exclusive.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
This analysis examines how household income is distributed among weekly users of six AI services measured in an Epoch AI/Ipsos survey: ChatGPT, Claude, Google Gemini, Grok, Meta AI, and Microsoft Copilot.
For each service, we compute the share of its weekly users who fall into five income brackets: under $25,000; $25,000–$50,000; $50,000–$75,000; $75,000–$100,000; and $100,000 or more and display these as stacked 100% bar charts sorted by the share of $100,000+ earners (descending).
Data
Analysis
Assumptions and limitations
Download this data
Explore this data

Tracking adoption and usage patterns, across demographics.
Related insights