Introduction
In 2025, we ramped up our public communication to keep pace with rapid developments in AI.
Our Data Insights offer short, visual, self-contained investigations of key trends and metrics in AI.
Gradient Updates is our outlet for leading-edge commentary by specific authors (also offered as a newsletter on Substack), without necessarily representing the views of Epoch AI as a whole.
Over the year, we published 36 Data Insights and 37 Gradient Updates.
Here, we bring you our top 10 most popular Data Insights and Gradient Updates in 2025.1
Most popular Data Insights
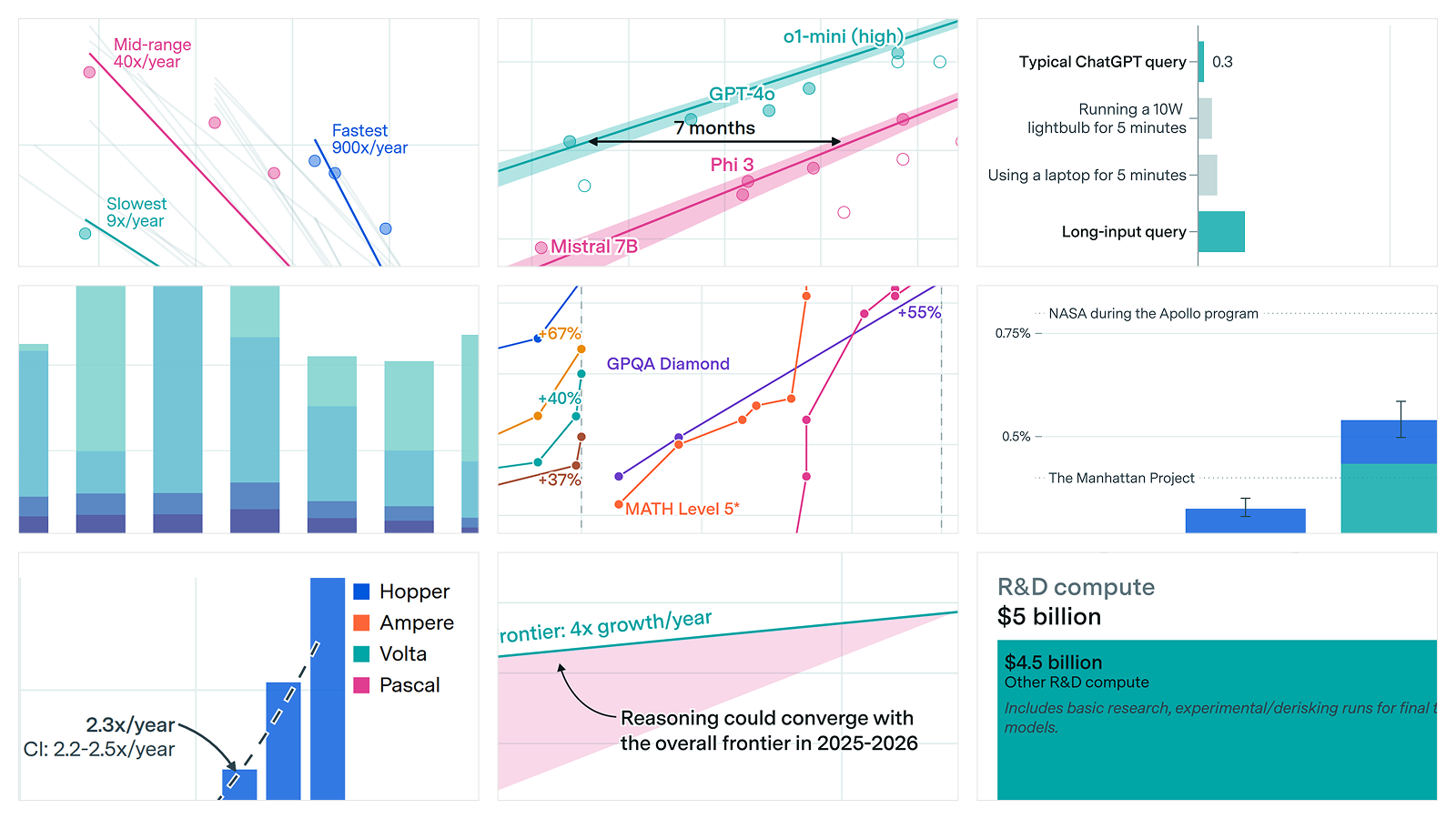
LLM inference prices have fallen rapidly but unequally across tasks
🠊 In short: Between April 2023 and March 2025, we saw a >10x and larger drop in the price per token at an equivalent performance level.
🠊 Why this matters: API cost reductions indicate a more competitive market and large gains in efficiency, making AI more affordable to customers. If these trends hold up, any AI capability that exists today will soon be available for very cheap!
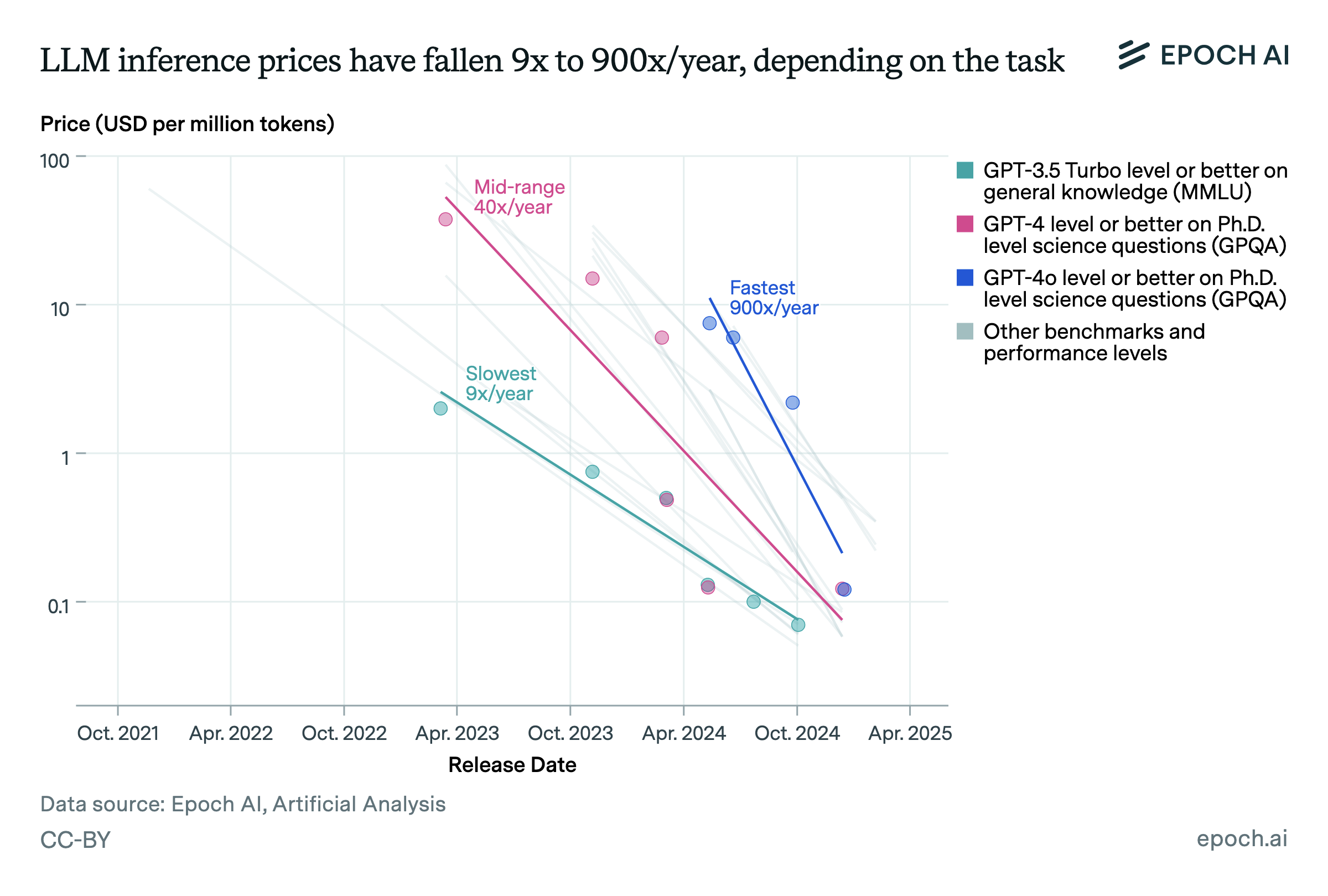
Frontier AI performance becomes accessible on consumer hardware within a year
🠊 In short: The best open models that can run on a consumer GPU lag the frontier of AI by only a year or less, as measured by several metrics of performance including GPQA, MMLU, AA Intelligence, and LMArena.
🠊 Why this matters: Open models that can run on a personal computer are accessible for billions of people. The relatively small lead held by frontier models suggests it would be hard to maintain a market advantage with a fixed level of model capabilities. Instead, companies face pressure to continue developing better models or excel at other services such as better integrations. This trend has direct implications for AI policy. Any capabilities appearing at the frontier are likely to be widely available and unrestricted in less than a year, complicating regulatory options.
Most of OpenAI’s 2024 compute went to experiments
🠊 In short: Media reporting indicates that most of OpenAI’s compute fleet in 2024 wasn’t used for inference or training runs, but rather to run experiments that enable further development.
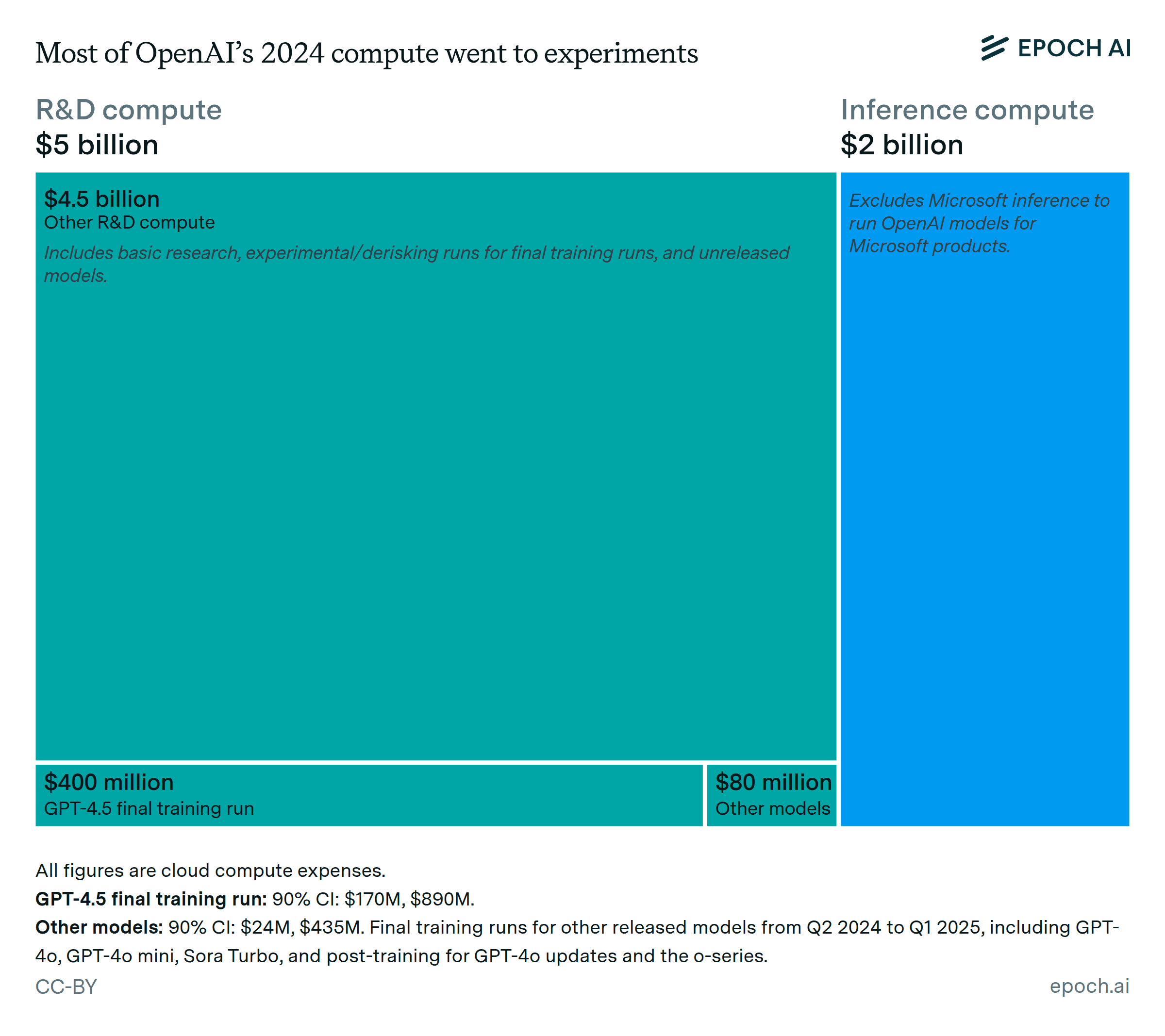
🠊 Why this matters: AI development is capital-intensive. So we should expect leaders in the field to have access to large amounts of compute that they use for experiments. This finding also suggests that most of the costs associated with AI currently are associated with experiments, rather than their direct training and deployment.
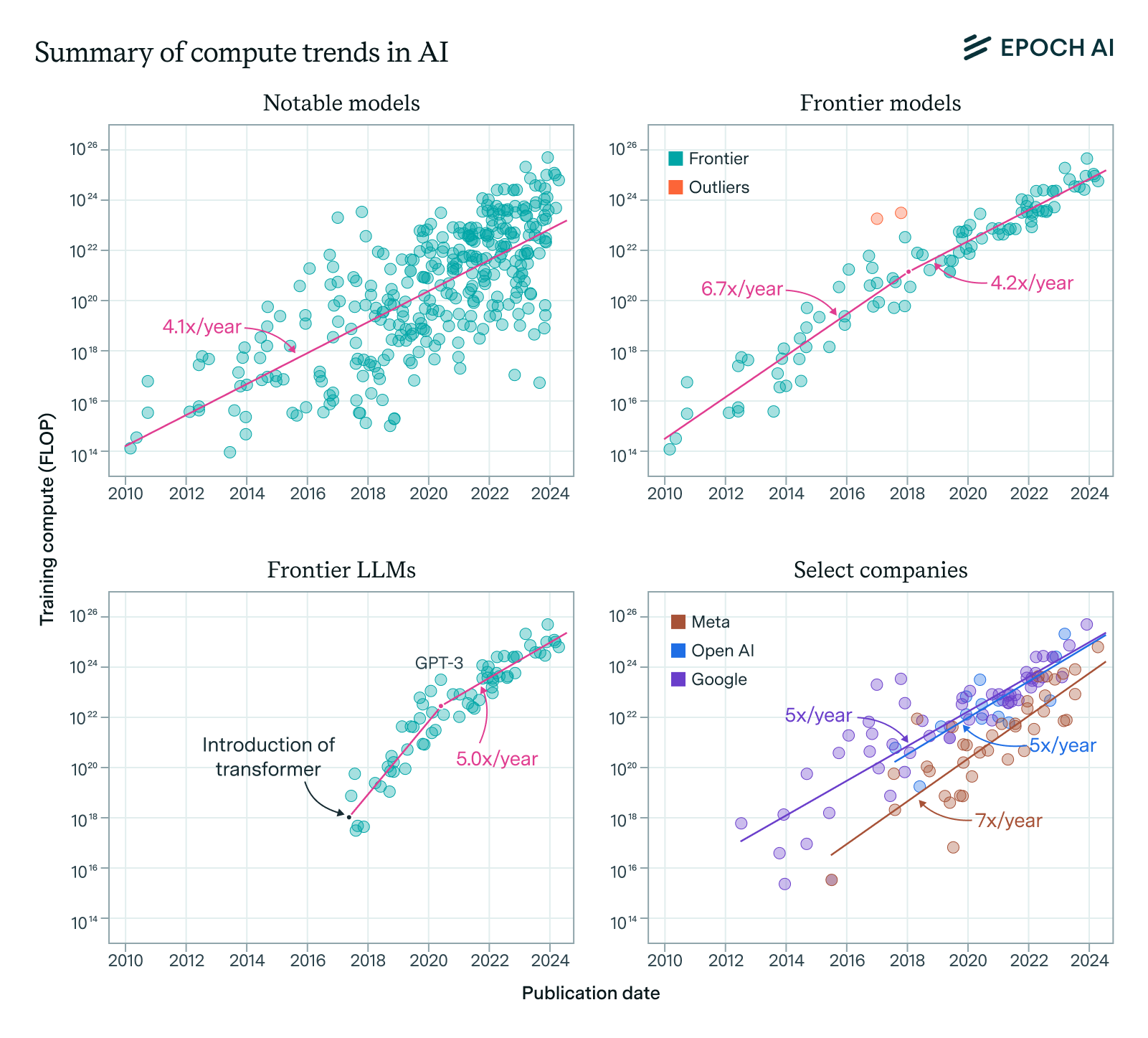
The stock of computing power from NVIDIA chips is doubling every 10 months
🠊 In short: The amount of installed AI compute from NVIDIA chips has more than doubled annually since 2020. New flagship chips account for most of the existing compute within three years of their release.

🠊 Why this matters: Compute is a fundamental input for AI development and deployment. Exponentially more computational resources are needed to maintain the current pace of AI development, which has driven sustained demand for chips from NVIDIA and other manufacturers.
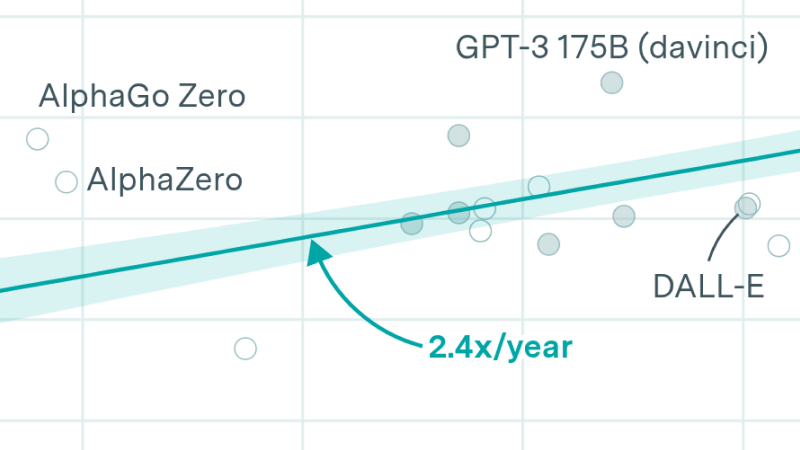
GPT-5 and GPT-4 were both major leaps in benchmarks from the previous generation
🠊 In short: Both GPT-4 and GPT-5 greatly exceeded the performance of their direct predecessors.
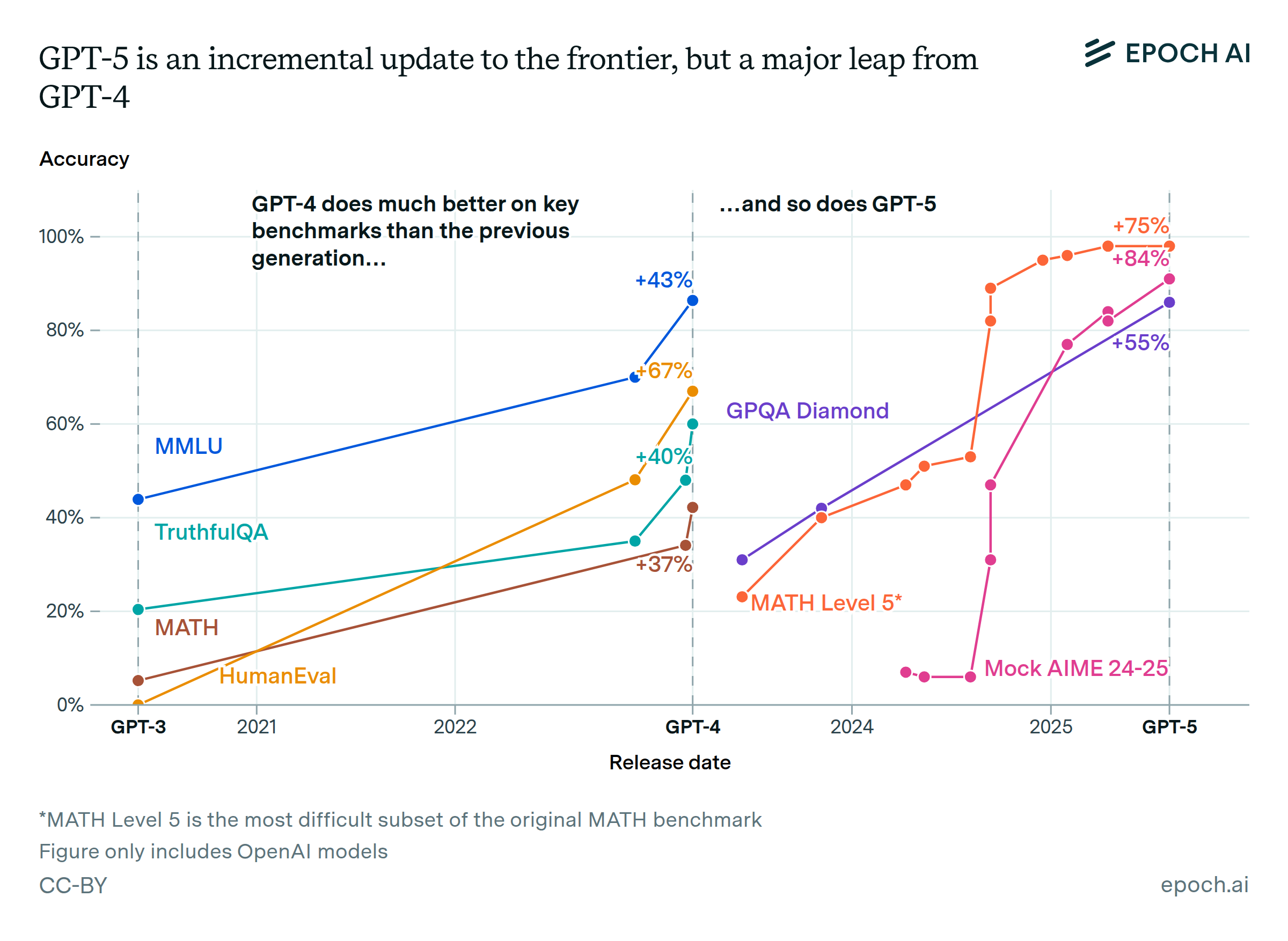
🠊 Why this matters: When GPT-5 released, some were disappointed that the performance improvements were only marginal compared to existing models. But this is better explained by a more frequent cadence of releases in the last two years, rather than a slowdown in capabilities.
Most popular Gradient Updates
How much energy does ChatGPT use?
🠊 In short: Josh estimated the average energy cost of a GPT-4o query, finding it was less than running a lightbulb for five minutes. His estimate was later corroborated by Sam Altman, and it is also similar to the energy cost per prompt for Gemini reported by Google.
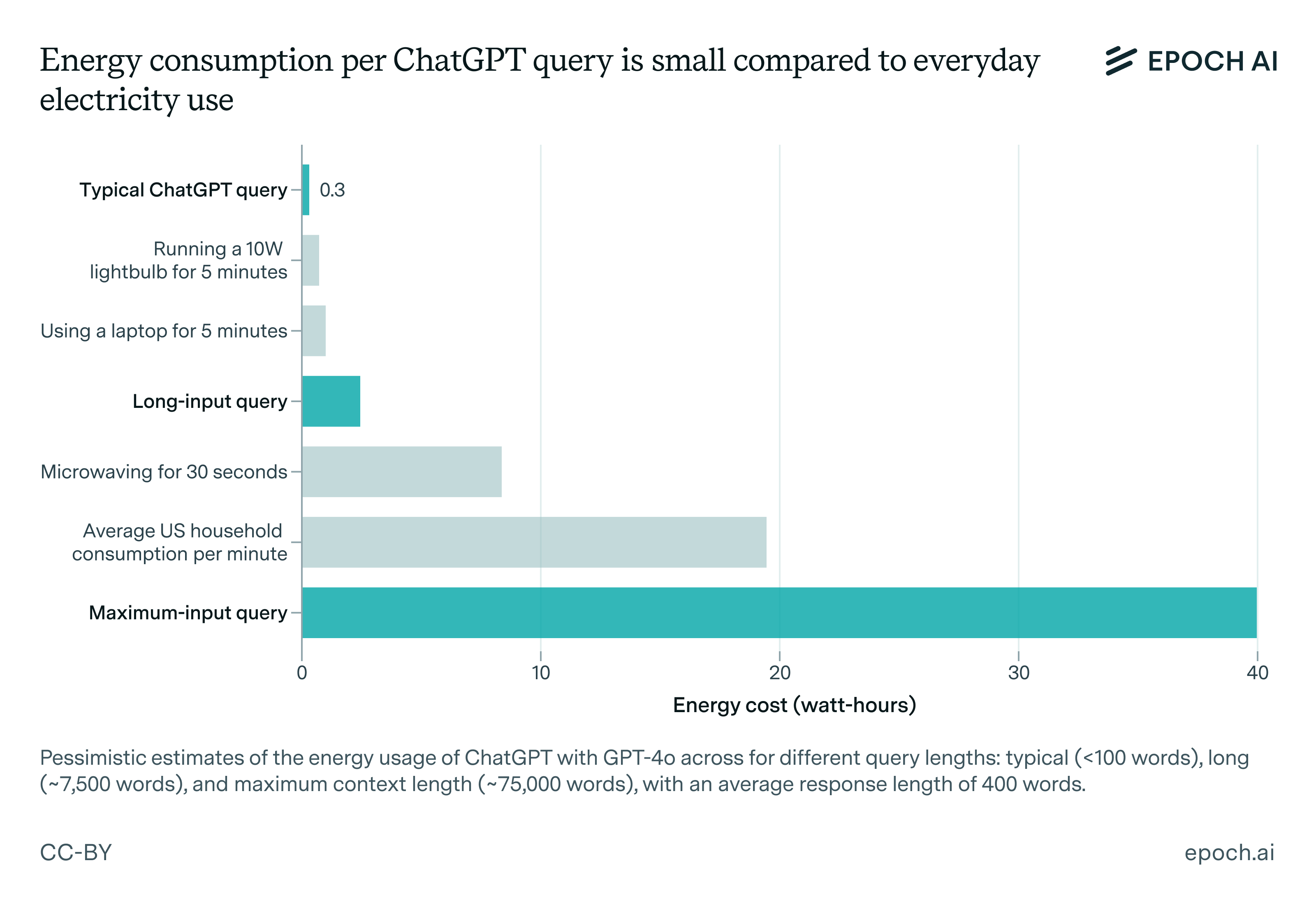
🠊 Why this matters: Many are concerned about AI’s energy use. This piece helped quantify the costs and put these concerns in context, showing that AI energy use at the time was not very significant compared to other household activities. AI energy use has continued to grow exponentially since then, though, and it might become a larger issue in the future.
How has DeepSeek improved the Transformer architecture?
🠊 In short: This post covered three techniques introduced by the team behind theDeepSeek v3 paper that allowed them to release the best open-source pretrained model at the time, while using 10× less compute than the next best open model Llama 3. The techniques are multi-head latent attention (MLA), innovations on the mixture-of-experts (MoE) architecture, and multi-token prediction.
![]()
🠊 Why this matters: Three days after we published this post, DeepSeek attracted far wider attention by releasing a reasoning model, R1. This model matched the performance of OpenAI’s o1 while using what we presume is a fraction of the development cost. The innovations they introduced illustrate the patterns of training compute efficiency, whereby year-to-year models become 3× cheaper to develop because of new training techniques and data improvements.
How far can reasoning models scale?
🠊 In short: Josh discussed the growth in compute for RL reasoning training. Labs like OpenAI and Anthropic claimed in early 2025 that their rate of RL scaling couldn’t be sustained for more than 1-2 years, since it would quickly run into the limits of their compute infrastructure.
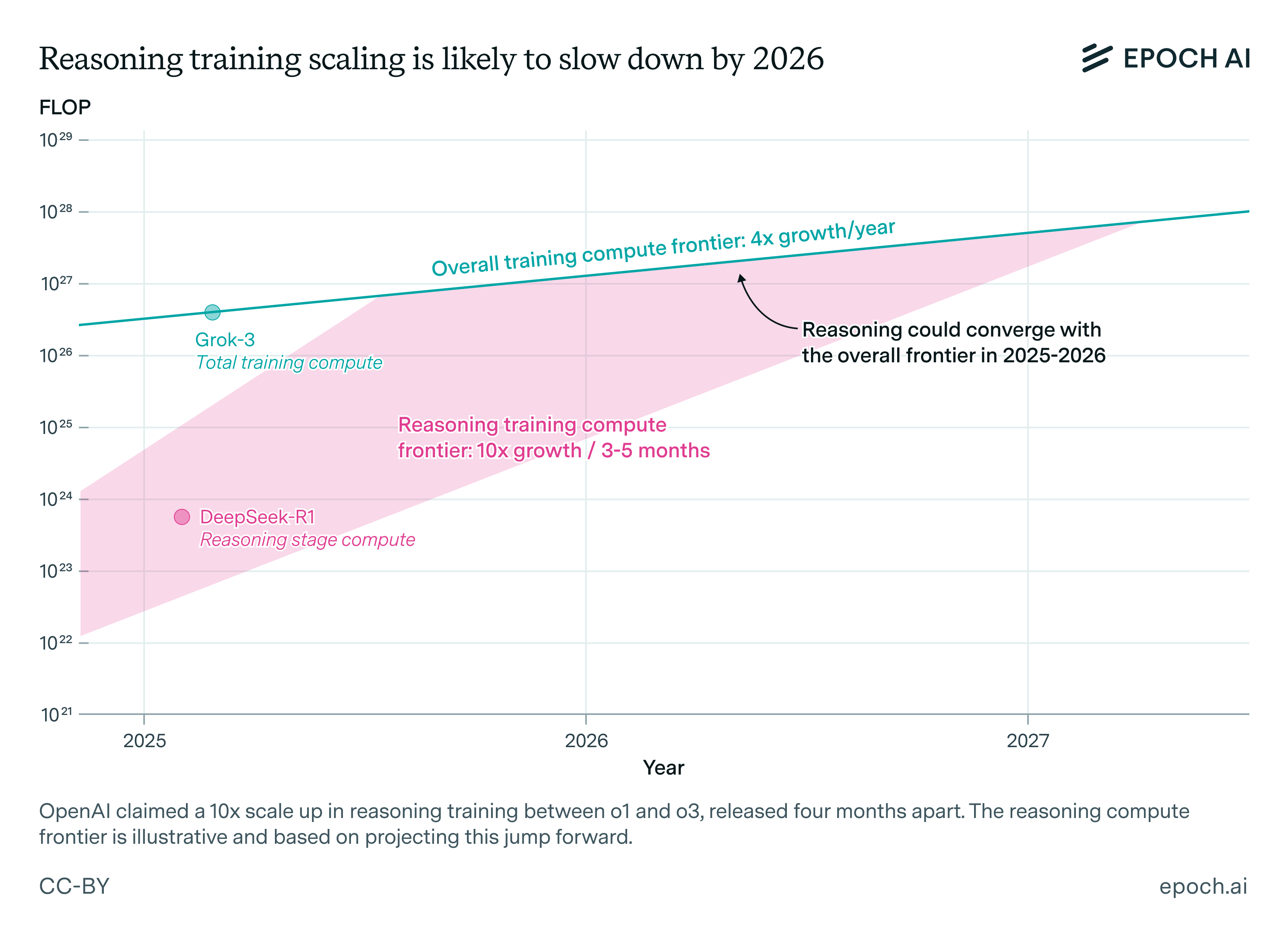
🠊 Why this matters: Reasoning has become a highly important axis for scaling model training, leading to excellent results in math, software engineering, and elsewhere. The limits to its growth suggest that the exceptional growth in capabilities during 2024 and 2025 could soon slow down.
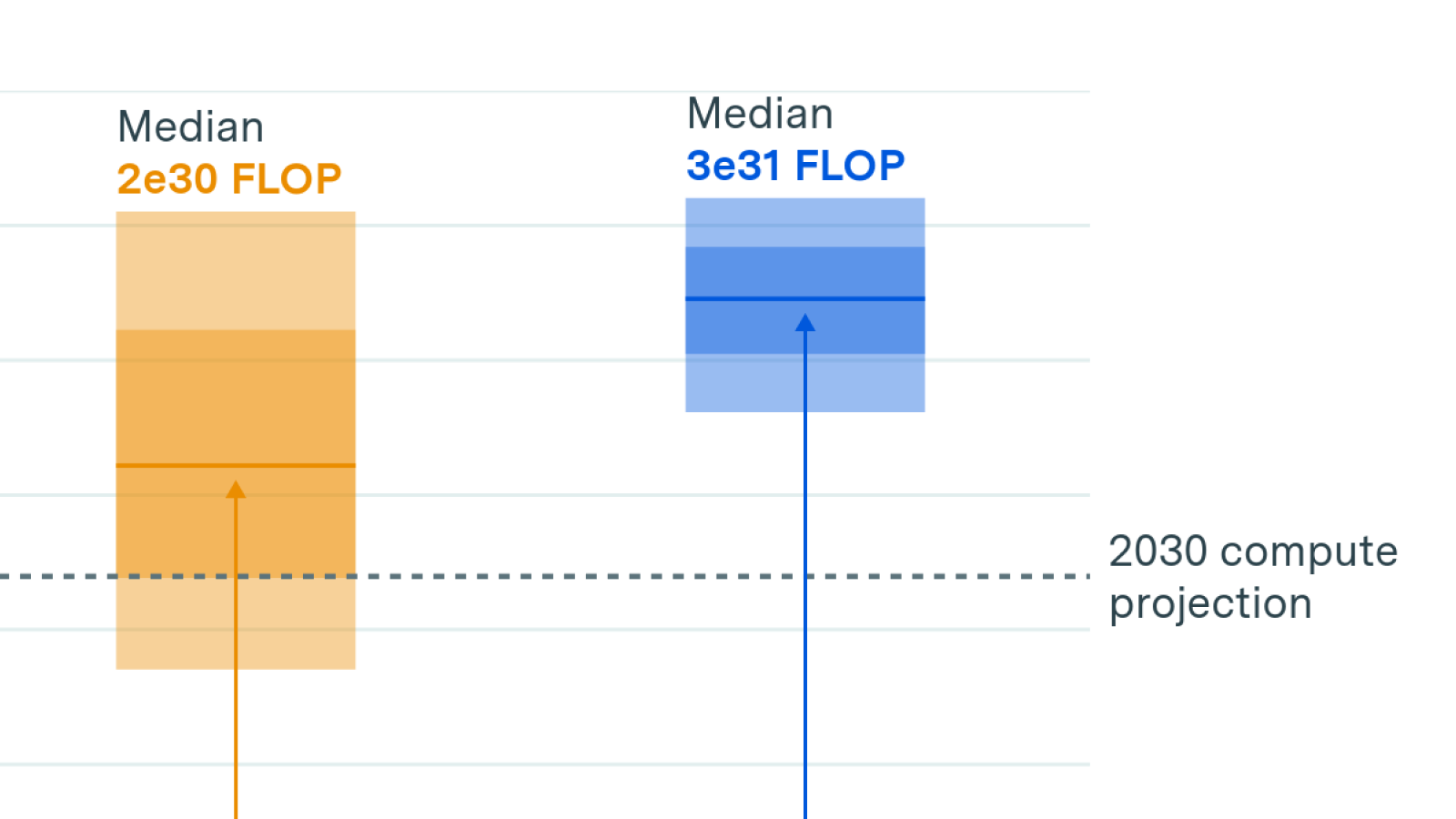
How big could an “AI Manhattan Project” get?
🠊 In short: Arden and Anson estimated how large a national US AI project could get, comparing it to the relative spending during the Manhattan Project and the Apollo program. They conclude it could result in a training run 10,000x larger than GPT-4.
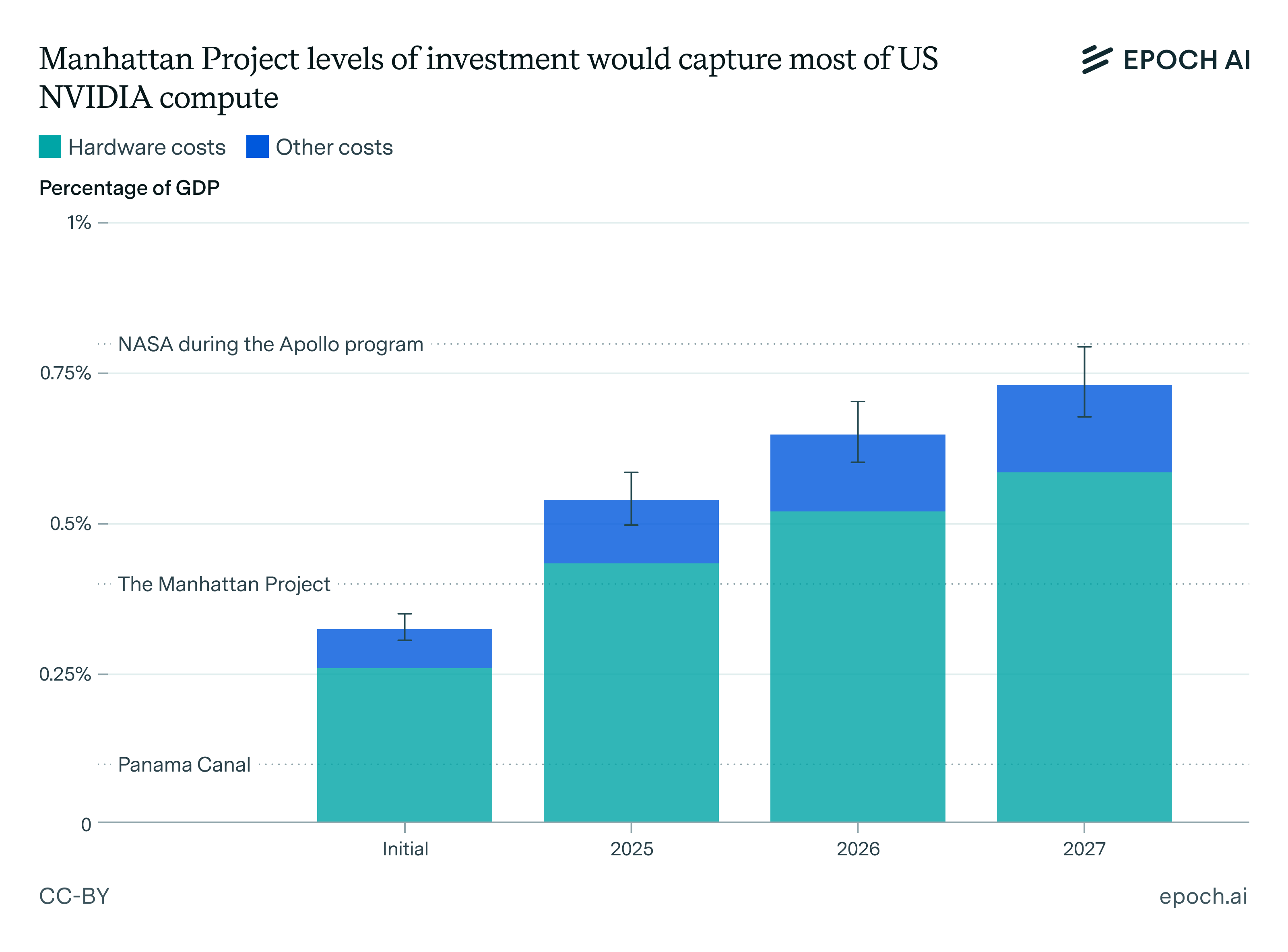
🠊 Why this matters: In November 2024, the US-China Economic and Security Review Commission’s top recommendation to Congress was to “establish and fund a Manhattan Project-like program dedicated to racing to and acquiring an Artificial General Intelligence capability.” This exercise puts into context the potential size of such a national project.
Most AI value will come from broad automation, not from R&D
🠊 In short: Ege and Matthew argued that most of the value AI will create will be mediated by its ability to automate many tasks across the economy, not its ability to speed up R&D. Relatedly, R&D activities have arguably contributed only a modest amount to productivity growth in the 1988-2020 period.
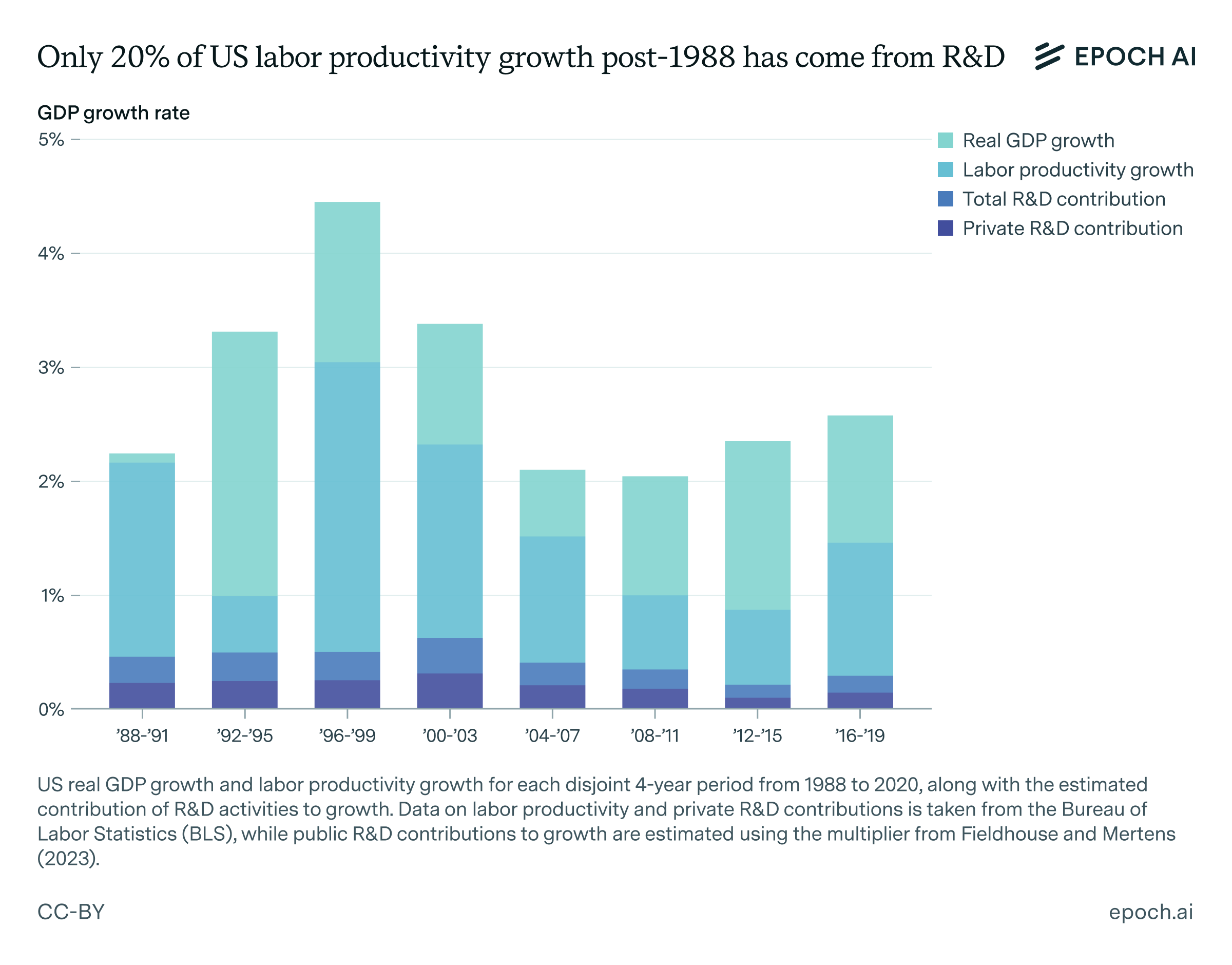
🠊 Why this matters: Many stories about explosive growth from AI, such as those posed by Sam Altman, Denis Hassabis and Dario Amodei, posit automation of R&D as a key lever of growth. This suggests that the impact of AI might be rapid, salient and localized.AI might suddenly automate the last hurdles to R&D automation and quickly make great advances within AI companies. But AI might instead primarily affect society through a diffuse and gradual process that lasts several years or decades as different orgs adopt AI to improve efficiency.
We started our Data Insights and Gradient Updates programs so we could offer timely input related to ongoing developments.
The rapid uptake has been gratifying. On our website alone, these new formats amassed nearly half a million views and a total engagement time of nearly 5,000 hours while related posts on Twitter had over 6 million impressions with over a quarter million engagements. They have been used widely to inform the discourse on AI.
If you found any of our outputs helpful this past year, please take our 2025 Epoch AI Impact Survey! Next year we will bring the same passion to improving how we pursue our mission of informing the world about AI trends.
Happy holidays!
-
We went by website page views to determine the ranking. Arguably, social media impressions would have been a better metric, since we see more engagement via these channels. We chose to go for website views for convenience and as a proxy for settled value and discoverability.

Related work