Related work
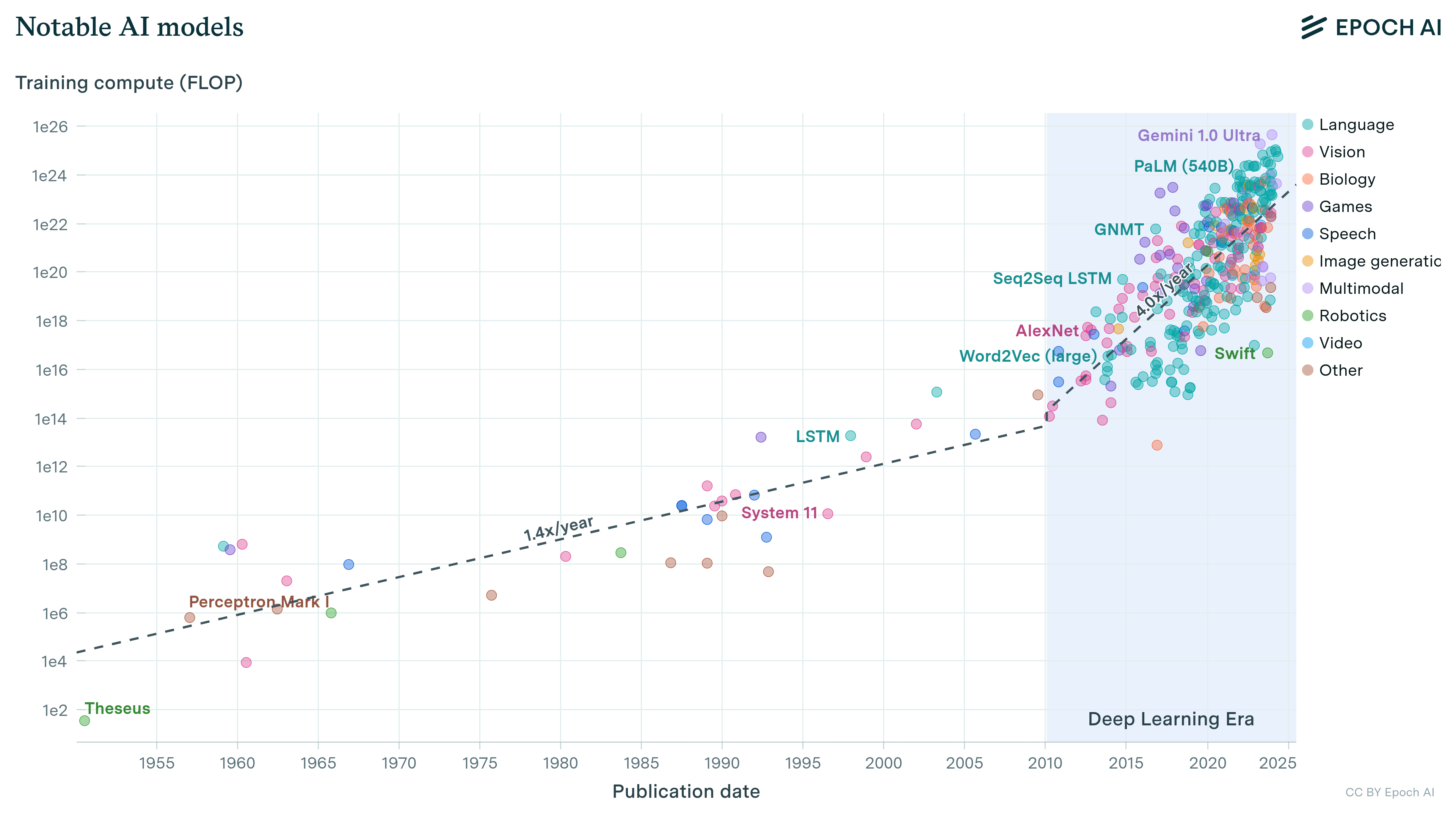
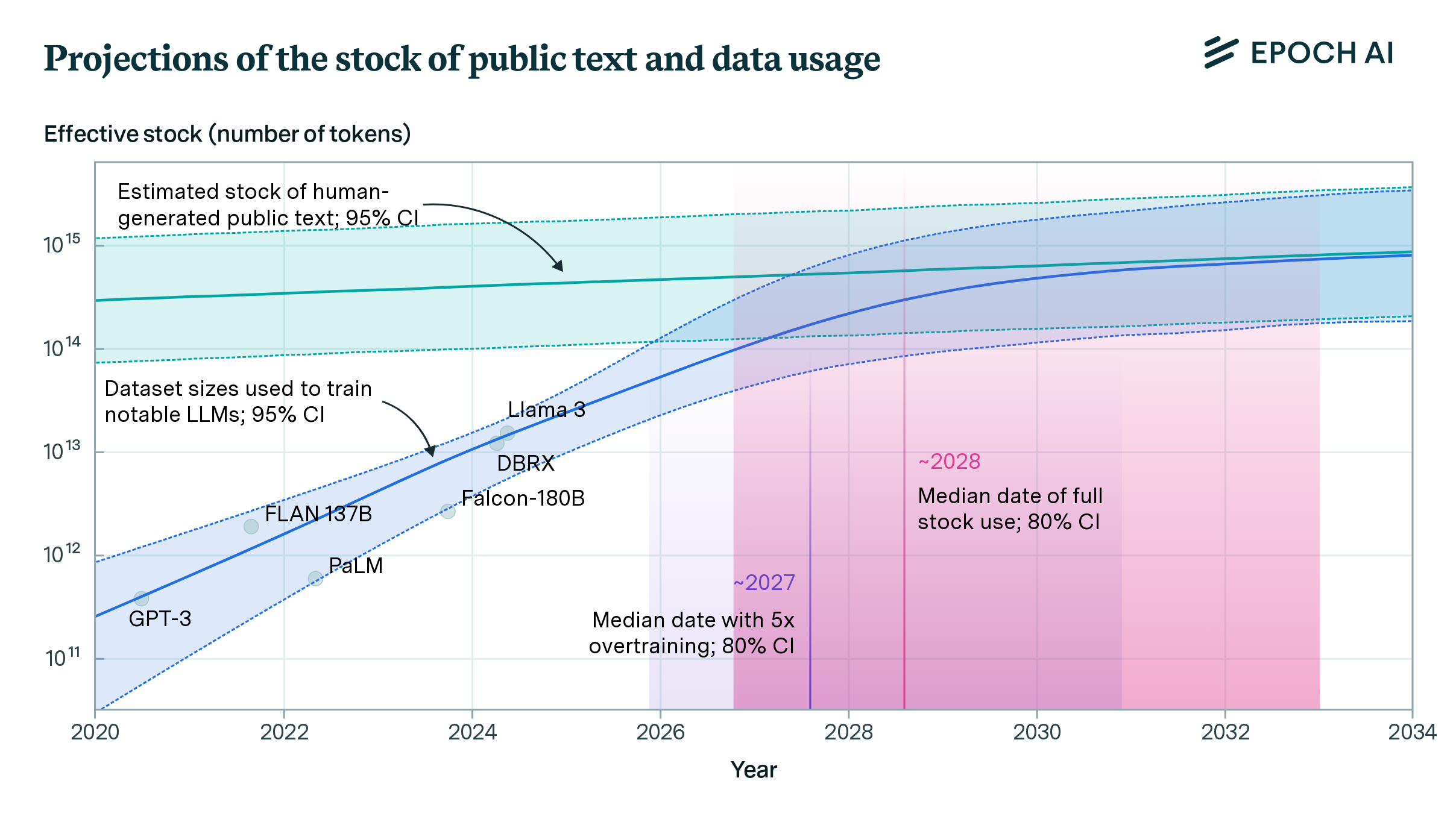
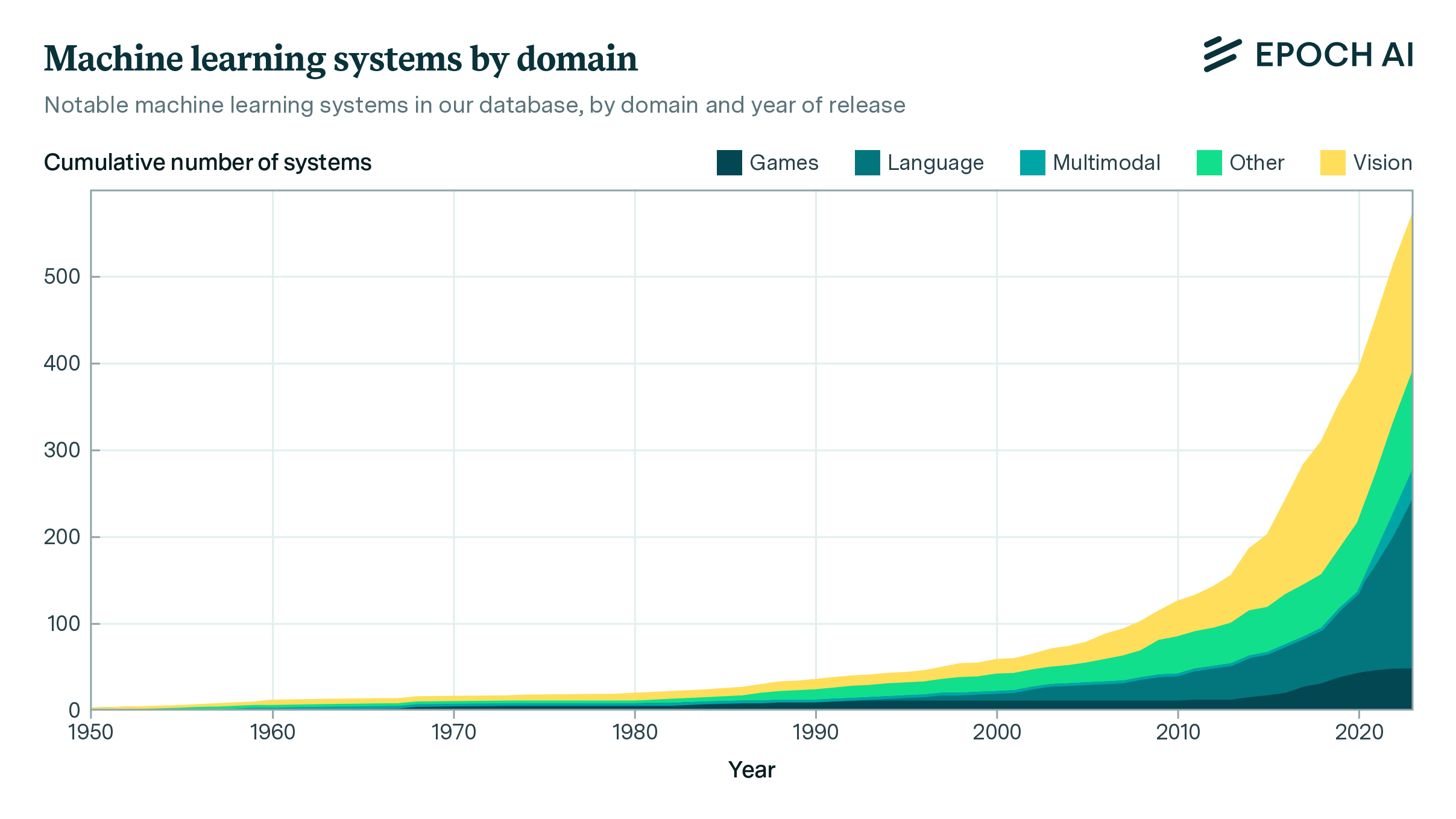
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.
Models in this dataset have been collected from various sources, including literature reviews, Papers With Code, historical accounts, highly-cited publications, proceedings of top conferences, and suggestions from individuals. The list of models is non-exhaustive, but aims to cover most models that were state-of-the-art when released, have over 1000 citations, one million monthly active users, or an equivalent level of historical significance. Additional information about our approach to measuring parameter counts, dataset size, and training compute can be found in the accompanying documentation.
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
A notable model meets any of the following criteria: (i) state-of-the-art improvement on a recognized benchmark; (ii) highly cited (over 1000 citations); (iii) historical relevance; (iv) significant use.
The dataset was originally created for the report “Compute Trends Across Three Eras of Machine Learning” and has continually grown and expanded since then.
We flag models as notable if they advanced the state of the art, achieved many citations in an academic publication, had over a million monthly users, were highly significant historically, or were developed at a cost of over one million dollars. You can learn more about these notability criteria by reading our AI Models Documentation.
Frontier models are models that were in the top 10 by training compute at the time of their release, a threshold that grows over time as larger models are developed.
Large-scale models are models that were trained with over 10^23 FLOP of compute, which is a static threshold that is used in some AI regulatory frameworks.
The explorer only shows models where we have estimates to visualize, e.g. for training compute, parameter count, or dataset size. While we do our best to collect as much information as possible about the models in our databases, this process is limited by the amount of publicly available information from companies, labs, researchers, and other organizations. Further details about coverage can be found in the Records section of the documentation.
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license. Complete citations can be found here.
Where possible, we collect details such as training compute directly from publications. Otherwise, we estimate details from information such as model architecture and training data, or training hardware and duration. The documentation describes these approaches further. Per-entry notes on the estimation process can be found within the database.
Records are labeled based on the uncertainty of their training compute, parameter count, and dataset size. “Confident” records are accurate within a factor of 3x, “Likely” records within a factor of 10x, and “Speculative” records within a factor of 30x, larger or smaller. Further details are available in the documentation. If you spot a mistake, please report it to data@epoch.ai.
Models with the “Speculative” confidence level are indicated with a small question mark icon on the graph, to alert users not to treat this data as very precise. In some cases, numbers may be based on partial information about training hardware, reported benchmark scores, or leaked sources. In other cases, developers provide information that is consistent with a wide range of values, such as “months” of training time, or “trillions” of data points.
The dataset is kept up-to-date by monitoring a variety of sources, including academic publications, press releases, and online news. An automated search process identifies newly released models each week using the Google Search API, and this is supplemented by models identified manually by Epoch staff.
The field of machine learning is highly active with frequent new releases, so there will inevitably be some models that have not yet been added. Generally, major models should be added within two weeks of their release, and others are added periodically during literature reviews. If you notice a missing model, you can notify us at data@epoch.ai.
Download the data in CSV format.
Explore the data using our interactive tools.
View the data directly in a table format.
Feedback and questions can be directed to the data group at data@epoch.ai.
Have a question? Noticed something wrong? Let us know.
Our public database, the largest of its kind, tracks over 3500 machine learning models from 1950 to today. Explore data and graphs showing the trajectory of AI.