How Far Behind Are Open Models?
We compare open and closed AI models, and study how openness has evolved. The best open model today is on par with closed models in performance and training compute, but with a lag of about one year.
Published
Resources
Introduction
Openness has long been a norm in AI research, fostering collaboration in the field. However, rapid advances in AI have sparked concerns about the potential consequences of releasing the most capable models. In addition, businesses that sell access to models like ChatGPT have a commercial incentive to keep models private.
Industry AI labs have responded to these developments in various ways. Some models remain unreleased, such as Google DeepMind’s Chinchilla model. Alternatively, models like GPT-4o have structured access, controlling how users can interact with the model. Other models have their weights available to download with restrictions on the terms of use, such as Meta’s Llama models.
Publishing models, code, and datasets enables innovation and external scrutiny, but is irrevocable and risks misuse if a model’s safeguards are bypassed.1,2 There is an ongoing debate about whether this trade-off is acceptable, or avoidable. Supporters of open source AI have argued that openness benefits society, as well as the model developer, through innovations and tools developed by the open source community. It has even been argued that more closed AI developers are already being outcompeted by the open source community, making it futile to remain closed. The AI chatbot market is indeed competitive: ChatGPT (which uses closed models) has approximately 350 million monthly users, while Meta’s AI assistant (which uses open models) has nearly 500 million.
To inform this discussion, we provide the most comprehensive evidence to date for comparing the capabilities of open and closed AI models over time. We systematically collected data on the accessibility of model weights and training code for hundreds of notable AI models published since 2018. This data is now included in our Notable AI Models database.
For the purpose of this report, “open” AI models are defined as those with downloadable model weights (including those with restrictive licenses), while “closed” AI models are either unreleased or can only be queried in an API or hosted service. We use this classification to compare the benchmark performance and training compute of open and closed AI models over time, measuring how far open models lag behind. We also measure the rate of open weights among notable AI models, allowing us to quantify openness across time.3
Summary of findings
In terms of benchmark performance, the best open large language models (LLMs) have lagged the best closed LLMs by 5 to 22 months. Meta’s Llama 3.1 405B is the most recent open model to close the gap across multiple benchmarks. The results are similar when we exclude Meta’s Llama models.
To get further evidence about the lag between open and closed models, we look at training compute. Compute serves as a proxy for capabilities, which is more general and reliably measured than any one benchmark. In terms of training compute, the largest open models have lagged behind the largest closed models by about 15 months. The release of Llama 3.1 405B relative to GPT-4 is consistent with this lag, at 16 months. At the same time, Llama 3.1 405B has closed the gap in training compute, because we have yet to see a closed model much larger in scale than GPT-4.
It is unclear whether open LLMs use training compute more or less efficiently than closed LLMs. Open LLMs tend to use less training compute after they reach similar benchmark performance to closed LLMs. However, newer models tend to be more efficient in general, and we lack data on newer closed models that might be equally efficient. Training data contamination and “cramming for the leaderboard” may also contribute to higher scores.
Based on the trend in Meta’s open Llama models, we expect the lag between the best open and closed models to shorten next year. On historical trends alone, the evidence for how the lag will change is mixed. However, Meta aims for Llama 4 to be “the most advanced [model] in the industry next year”, using nearly 10x more compute than Llama 3. If Llama 4 reaches this scale and is an open model, the lag will likely shorten next year. Whether the gap will shrink or widen afterwards depends on whether open models remain a viable business strategy for leading developers like Meta.
Our overall finding is that in recent years, once-frontier AI capabilities are reached by open models with a lag of about one year.4 Having open models close to the frontier will boost research on AI capabilities and safety, and enable beneficial applications. However, open models are easier to modify and spread without oversight from the original developers. Highly capable open models could therefore allow harms that are otherwise avoided when using closed models. The lag of open models provides a window to assess these potential harms before the open models are released.
What is an “open” AI model?
Openness in AI is multi-faceted. For this work, we collected data on whether AI models are accessible in terms of model weights, training code, and training datasets.
The weights of a trained model are arguably the most important artifact of AI development. Modern AI models usually contain billions or trillions of parameters, which are numerical values that are adjusted throughout training. Some developers make the parameter values, or “weights”, of a trained model “open”. This means that they are available for download, and anyone with access to these weights can run the model themselves if they also have the necessary computing power.
For most of this report, we will use “open model” as shorthand for open-weight models, if not otherwise specified, whether or not the model’s code or data is open. This simplifies our analyses, and much of the relevant public discussion on “open” models has focused on model weights.
However, the openness of training code (the code that sets up and executes a training run) and training data are also significant. If someone wants to precisely reproduce a model by doing their own training run, they need access to the training code (or enough details about the training run to recreate it), and the original (or sufficiently similar) training data.5 Training code also contains insights that can potentially enable better models to be created. We discuss trends in the openness of training code and data further in Appendix G and Appendix H.
Open-weight AI models are often called “open source”, and there is some controversy over the definition of open source AI, and whether open weights are sufficient. The term “open source” originates from open-source software with publicly available source code that can be viewed, edited and freely redistributed (among other criteria). Model weights, which are a long list of numbers, do not provide transparency into how the model works the way source code does for software, and one cannot easily modify a model by editing its weights by hand. On the other hand, open-weight models can be fine-tuned (i.e. trained further to improve performance, often for a specific domain) even without access to the original code or data, so it is still practical for third parties to modify the model to suit their own needs.6
The Open Source Initiative recently released a definition of open source AI, requiring that a model’s weights and source code for training and inference be openly released, and that training data is described in sufficient detail to be reproducible. To sidestep the debate over whether weights alone make a model “open source”, we generally call models with downloadable weights, but not necessarily open code or data, “open-weight” or simply “open.”
Degrees of accessibility
There is an underlying spectrum of accessibility in whether a model has “open” or “closed” weights (or code or data). Models with downloadable weights typically come with a license. These licenses can be highly permissive, or they may restrict certain uses (such as harmful behavior or using model outputs to train other models), or entirely prohibit commercial use of the model.7 Meanwhile, “closed” models can be completely unreleased, or available via a product or an API.8 Accordingly, in our data, we break down model accessibility into six different categories, drawing on previous work. We use a similar set of categories for training code and dataset accessibility, also distinguishing by license permissiveness.
For a full breakdown of our accessibility framework across model weights, training code, and datasets, see Appendix A.
Benchmark performance
The primary aim of this work is to measure the gap in capabilities between open and closed AI models. Benchmarks are the most straightforward way to understand this, because they measure the capabilities of models directly in various domains. Benchmark performance also helps measure improvements in algorithmic efficiency. Here, we examine the performance of open and closed large language models (LLMs) on key benchmarks testing knowledge, reasoning, and mathematics. We took steps to select reliable benchmarks and filter out potentially overfitted models—see Appendix D for details.
Open models have lagged on benchmarks by 5 to 22 months
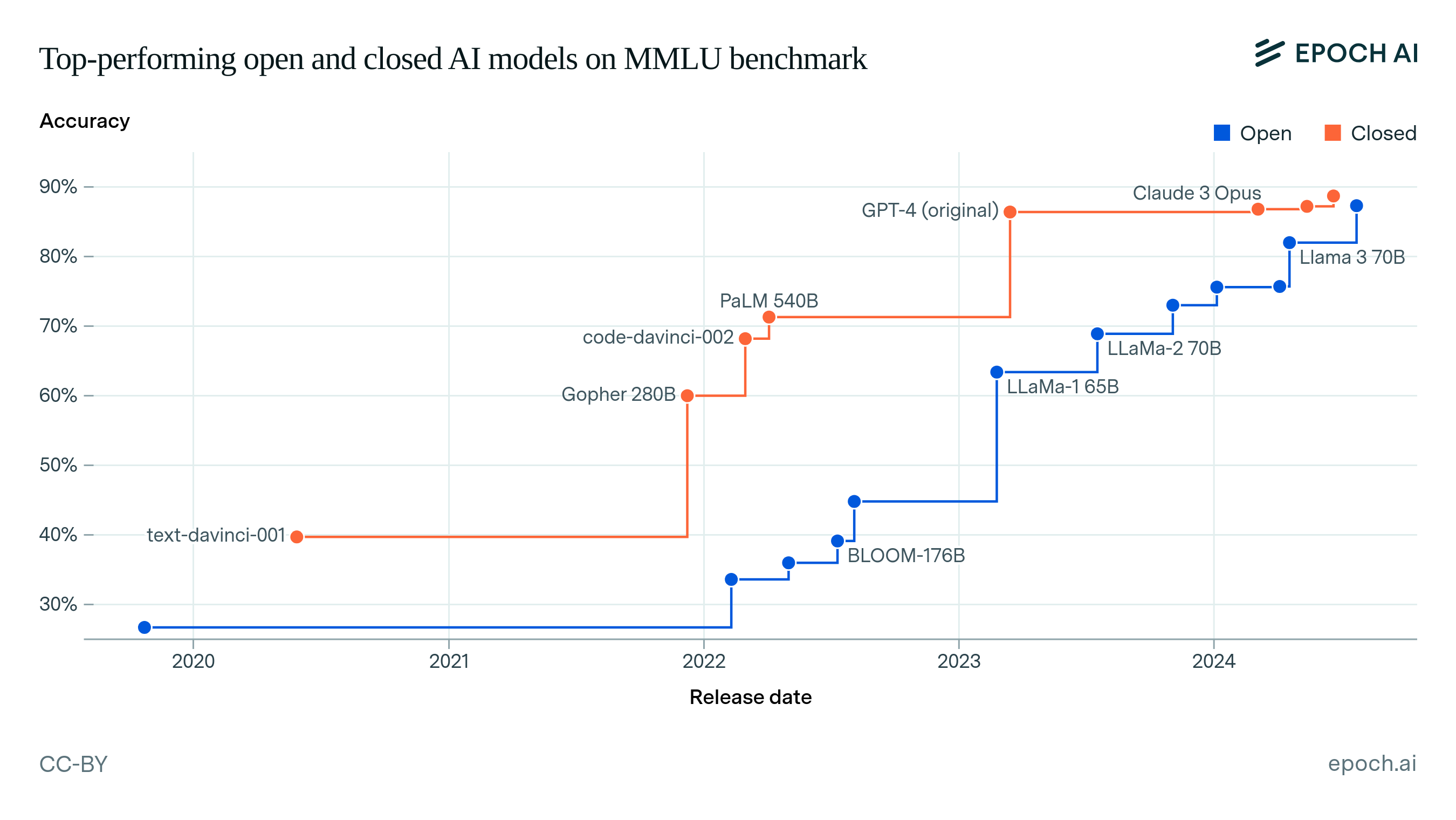
First, we compare the top-performing open and closed models on key language benchmarks over time. To measure the lag between open and closed models, we find the state-of-the-art (SOTA) closed model over time, and then find how long it took the first open model to match or exceed that closed model’s accuracy.9 Figure 1 shows the top-performing models over time on the selected benchmarks, interactively showing the lags between open and closed models.
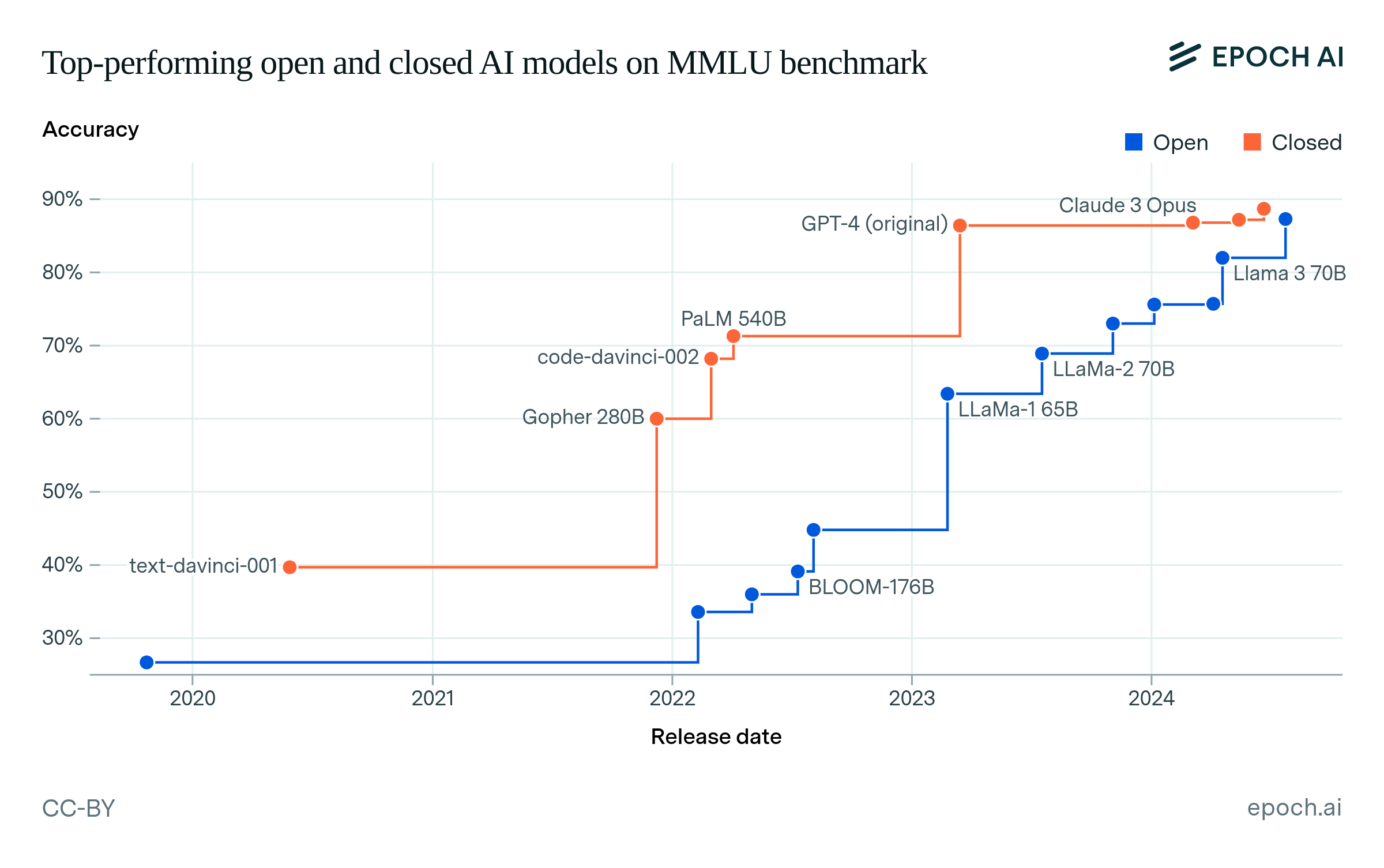
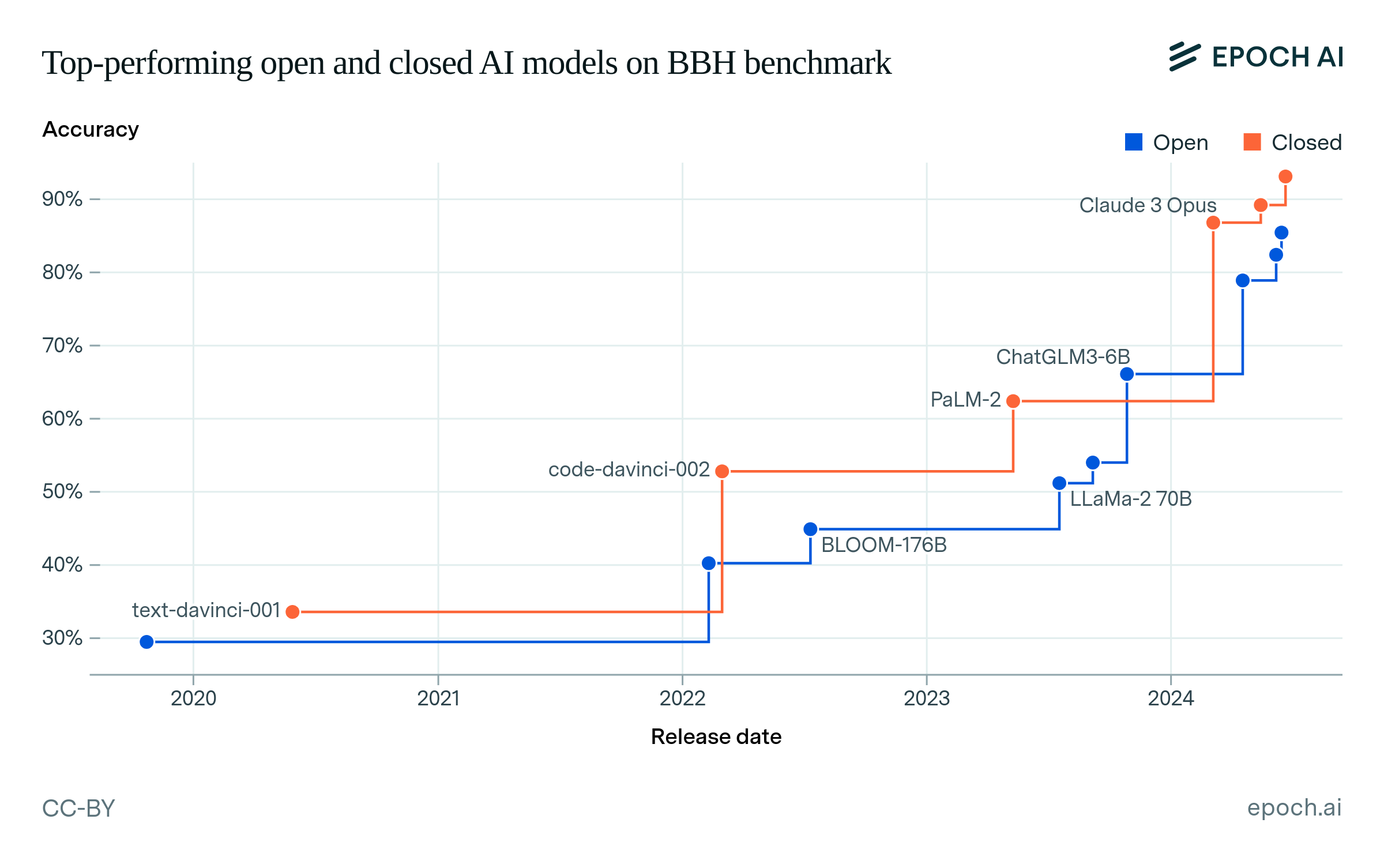
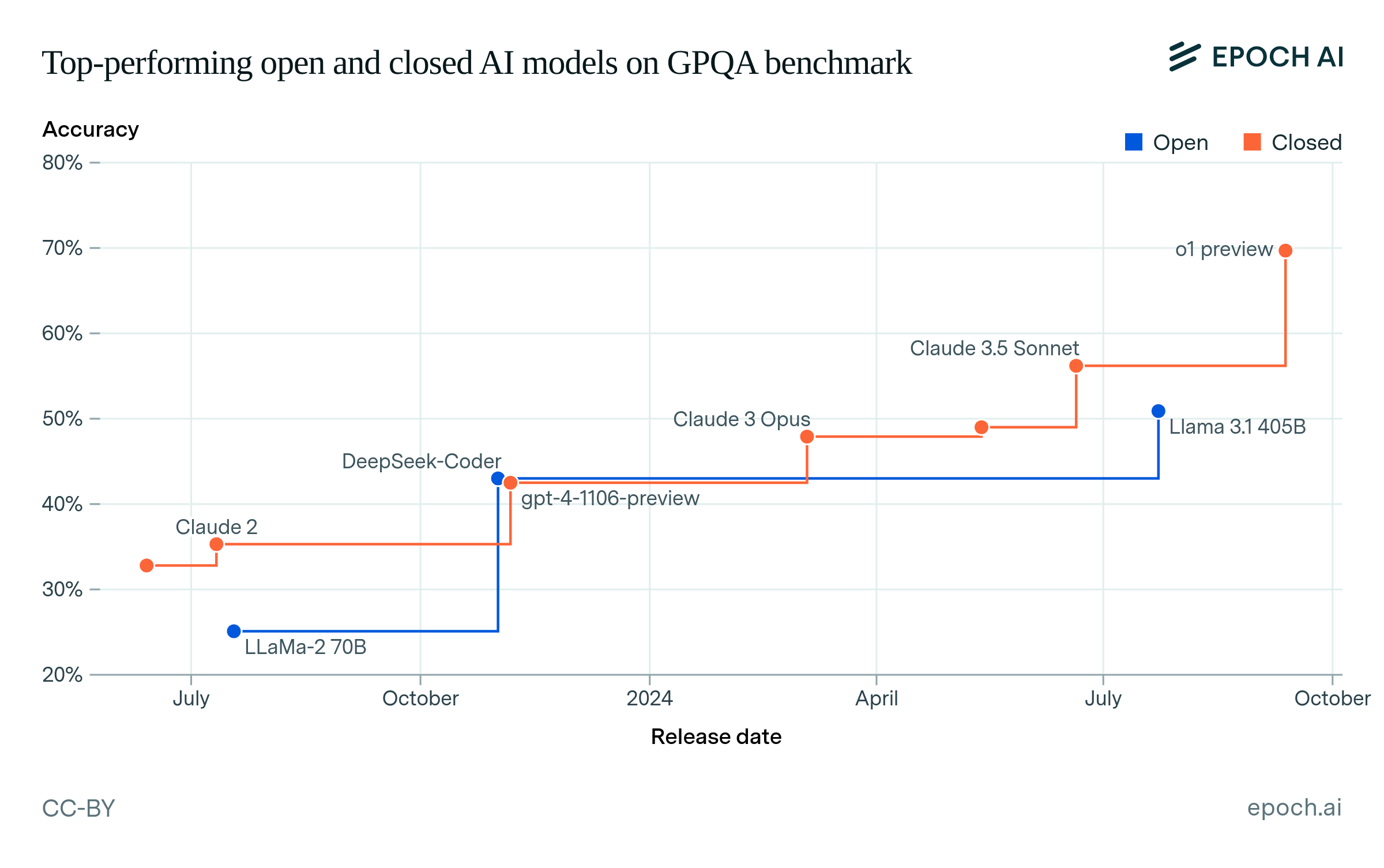
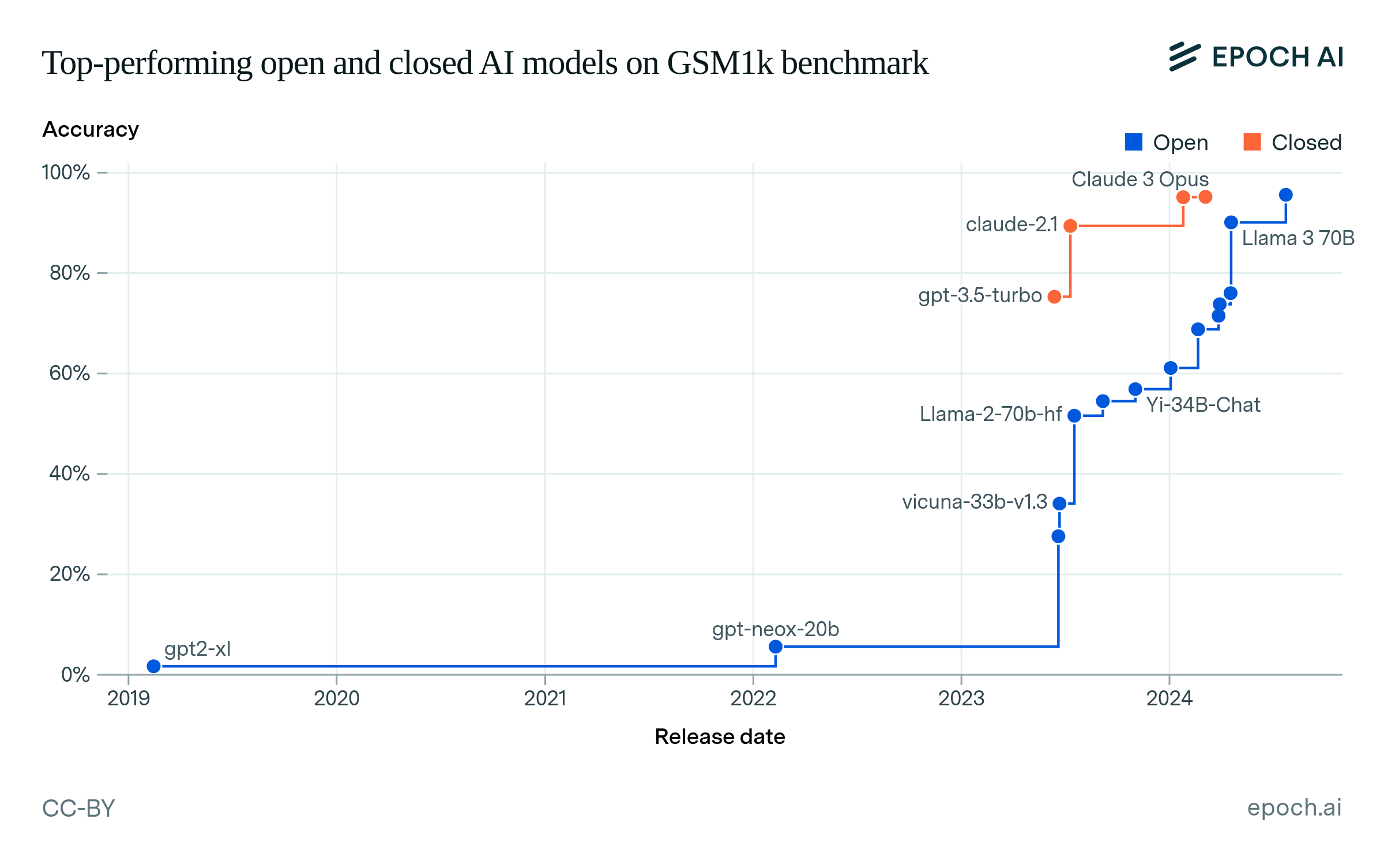
Figure 1: Top-performing open and closed models on benchmarks over time. The lag between an open and a closed model is shown by hovering over a data point.
Figure 2 summarizes the lags that we find across the four benchmarks, showing that open models have generally lagged behind closed models.10 The largest lag was 25 months on MMLU, between the release of GPT-3 (text-davinci-001) and BLOOM-176B. The smallest lag was 5 months between Claude 3 Opus and Llama 3.1 405B, on GPQA. We summarize these results using the 90% confidence interval (CI) over all 13 lag values, which is 5 to 22 months.11
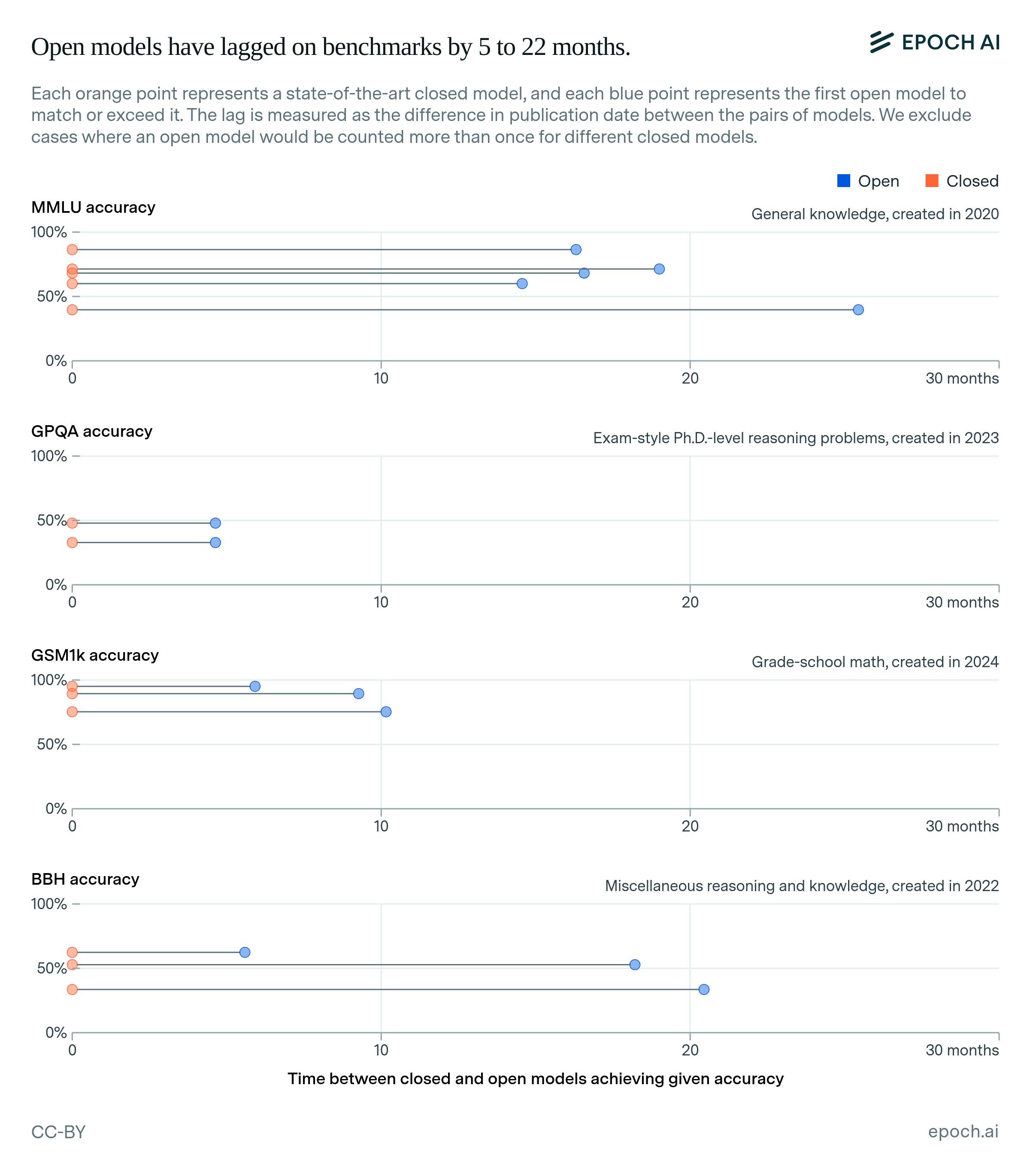
Figure 2: The lag of open models on key language benchmarks.
Closed models are leading not only in accuracy-based benchmarks, but also user preference rankings. In leaderboards based on human preferences between models, such as LMSys Chatbot Arena and SEAL Coding, closed models such as OpenAI’s o1 and Google DeepMind’s Gemini 1.5 Pro outrank open models such as Llama 3.1 405B and DeepSeek V2.5.12
Newer, open LLMs use less compute to match older, closed LLMs
We have just seen that closed models are ahead of open models in absolute performance. However, training compute efficiency is another important metric: how much performance does one get for the compute spent on training? By comparing the performance of models at different levels of training compute, we can find possible differences in efficiency between open and closed models.
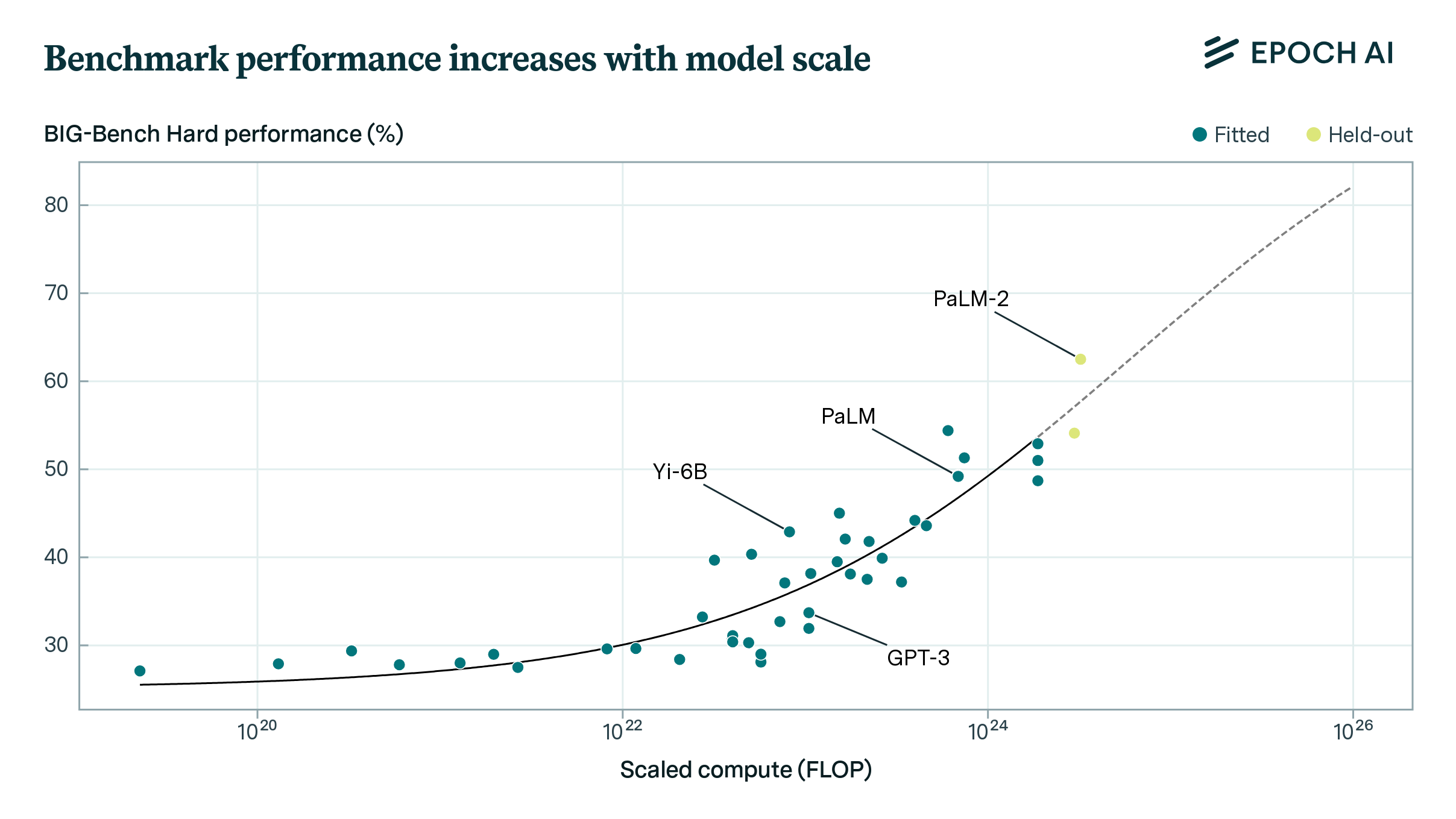
When we look at the performance-compute relationship on MMLU in Figure 3, we find that several open models have achieved similar MMLU scores to closed models, while using significantly less training compute.13 For example, DeepSeek V2 (open) achieves similar performance to PaLM 2 (closed), with about 7x less training compute. Google DeepMind’s Gemma 2 9B (open), which is distilled from a larger model, makes a similar gain on PaLM 540B (closed).
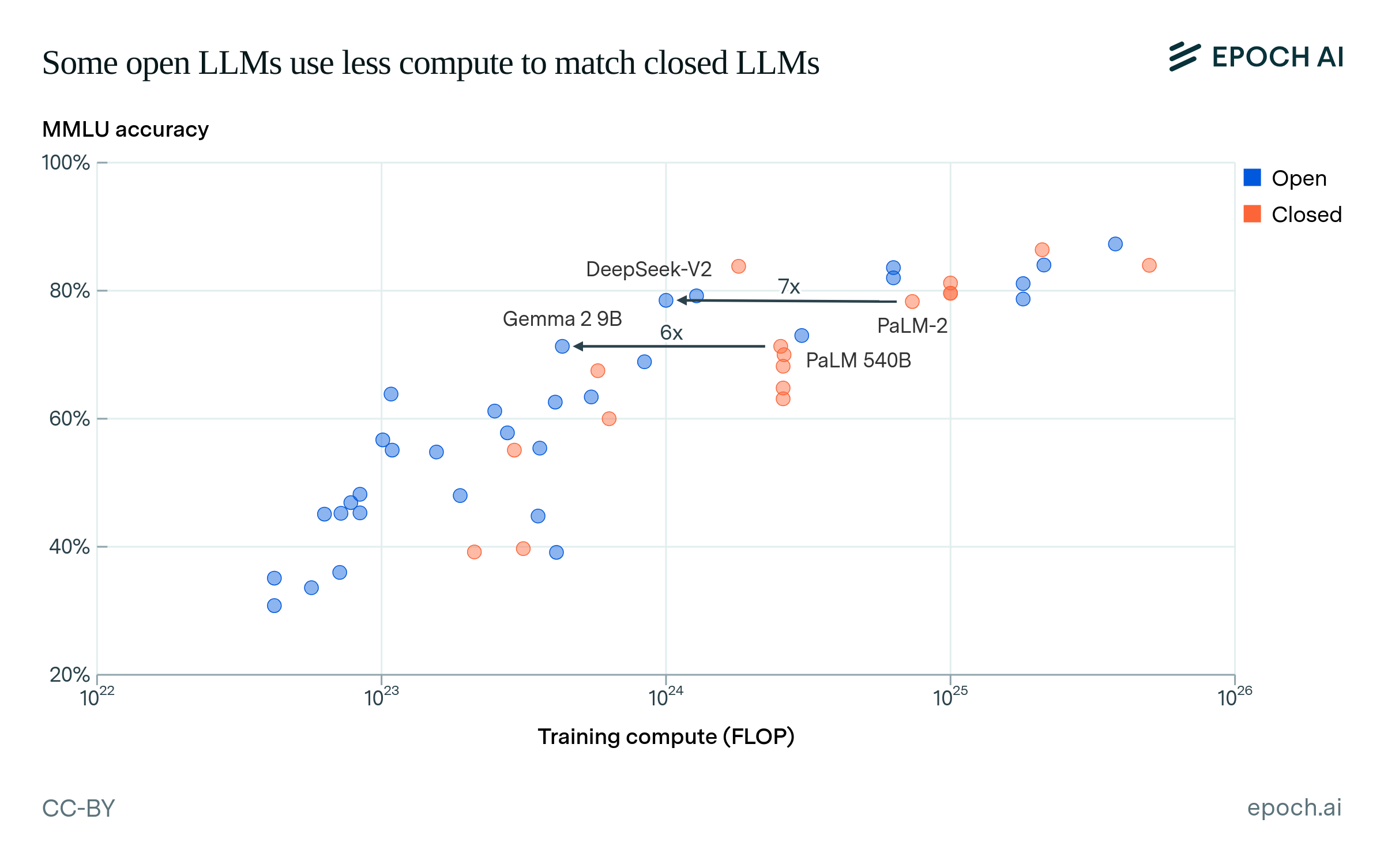
Figure 3: MMLU accuracy vs. training compute (log-scale) for various models. Models are color-coded by the accessibility of their weights. Newer open models like DeepSeek V2 and Gemma 2 9B tend to use less compute to achieve similar performance to older closed models like PaLM 540B and PaLM 2.
However, the variations in performance are explained just as well by a later publication date as by open weights. A regression on compute and publication date fits the data comparably well to a regression on compute and whether or not the model is open or closed.14 We also lack technical details on some newer closed models such as GPT-4o mini—which features efficiency as a selling point—so it is uncertain where those closed models lie on the training compute axis.
Of course, better algorithms are the underlying driver of performance at lower levels of compute, rather than publication date. However, some of the improvements we see on the above benchmarks may not generalize. For instance, some models are likely to be “cramming for the leaderboard” more than others: using knowledge about evaluation tasks in pre-training, without directly contaminating the data. A recent paper finds evidence that many new models have been trained in this fashion, more so than older models.15 The reported evaluation results may suffer from outright contamination as well, despite best intentions. Finally, even when an algorithm robustly improves capabilities using less compute, it’s not clear that this implies better performance at new frontiers of compute. This is an important topic for future research.
Training compute
In the previous section, we looked at the training compute efficiency of open and closed models. We can also view training compute itself as a metric to compare these models. As a key resource for AI development, training compute has been a fairly good predictor of capabilities. Compute is also easier to measure and less gameable than benchmarks. For these reasons, we use training compute to complement our analysis of benchmark performance. This has its own limitations. Some of our training compute estimates are speculative, and training compute may not predict capabilities as well in the future, due to inference scaling or a possible breakdown in scaling laws.
To focus on the most capable open and closed models, we select models that are near the frontier of training compute within each category. To do this, we filter to the models that had the largest training compute at the time of release, referred to as “top 1” models.16 Unlike the benchmark results, we measure the lag between two trend lines instead of between individual AI models. This is because our training compute data has a larger sample size and a more regular trend than the benchmark data.
The scaling of open models lags by about 15 months
Based on the trends in training compute shown in Figure 4, the largest open models currently lag the largest closed models by around 15 months. This estimate has a 90% confidence interval (CI) of 6 to 22 months. This CI overlaps with the CI of lags on benchmark performance, which is 5 to 22 months.
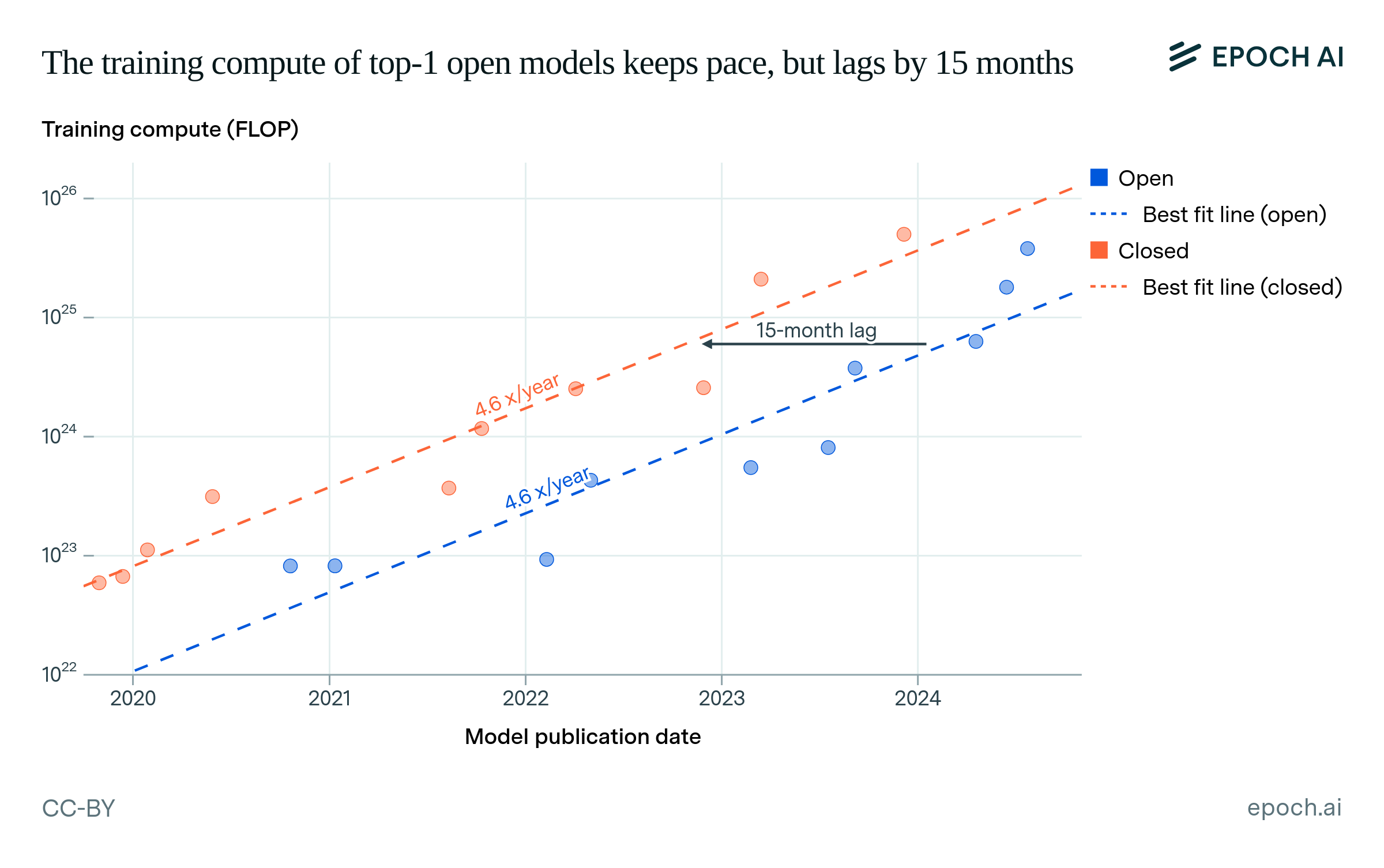
Figure 4: Trends in training compute over time for top-1 open models and top-1 closed models. “Top-1” means the model had the highest training compute within its category, at the time of its release. The “lag” shown is the time that the open models trend took to reach the same compute as the closed models trend, as of July 2024.
We find that the estimated lag in training compute is fairly robust to how we filter the data.17 Our estimate is also consistent with how much longer it took for open models to reach GPT-4 scale. Meta’s Llama 3.1 405B was likely the first open model to exceed the training compute of the original GPT-4 model, 16 months after GPT-4 was released.18,19 In addition, we have not seen a closed model much larger in scale than GPT-4. This means that while the lag in time between open and closed models has been significant, the gap in compute is minimal today. The similar growth rates of 4.6x/year suggest that this lag in training compute has been fairly stable for the past five years.
Will open AI models catch up or fall further behind?
By studying trends in benchmark performance and training compute, we have found that the best open models lag behind closed models across every metric. The amount of lag varies, but centers around one year.20 A crucial question is how this lag will change in the future. If the lag grows, then open models will probably become much less important for understanding and governing frontier AI. Conversely, a shrinking lag would soon put the best open models at the frontier. Here, we take another look at the trends to inform this question.
First, the lag of open models on the GPQA benchmark is about five months, shorter than the 16- to 25-month lag on MMLU (see Figure 2). GPQA was released three years after MMLU. The lag on MMLU, GSM1k and BBH is also shorter at higher levels of accuracy, which were achieved more recently. This weakly suggests that the lag of open models has shortened in the past year.
In terms of training compute, the top-1 open models have scaled at a similar pace to the top-1 closed models, at 4.6x/year for the past five years. This suggests that the lag of open models will remain stable rather than shorten. However, if we look at a broader set of models—the top-10—open models have scaled at 3.6x/year, slower than closed models at 5.0x/year (see Figure 5).21 This suggests a growing lag for this broader set of open models. About 45% of these open models are not affiliated with Google, OpenAI, Anthropic, or Meta, compared to 32% of the top-10 closed models.
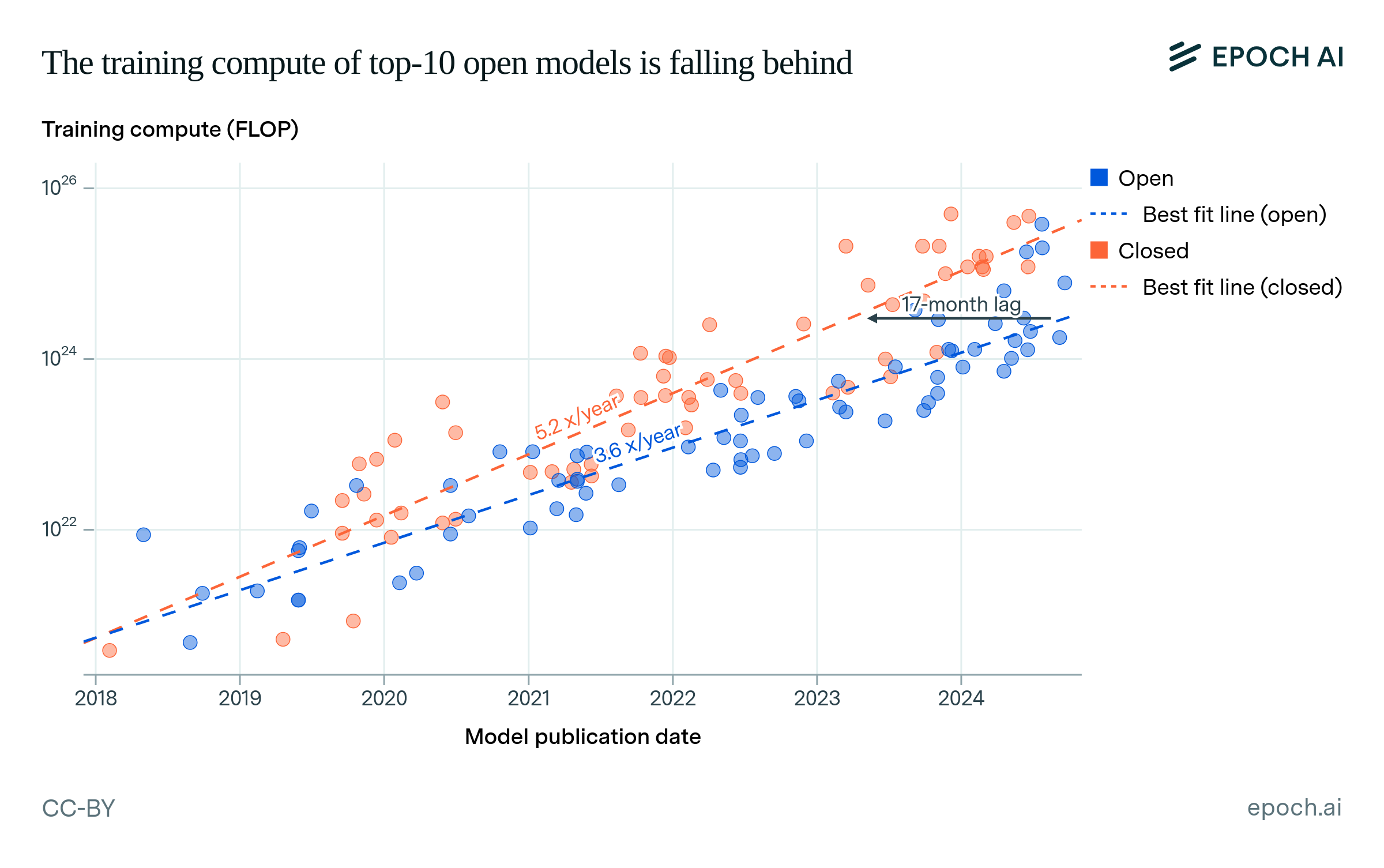
Figure 5: Trends in training compute over time for top-10 open and closed models. The “lag” shown is the time that the open models trend took to reach the same compute as the closed models trend, as of July 2024. Compared to top-1 models in Figure 4, this shows how the broader AI ecosystem is trending. The open models have scaled significantly slower than the closed models.
So far, this paints an unclear picture of where open models are headed. Another source of evidence is predictive power: testing how well the fitted trends predict held-out data. If we fit a single growth rate parameter to both open and closed AI models, we find that this improves the predictions of recent training compute values (see Appendix G). This is evidence for a stable lag so far, which could extend into the future.
Meta’s support of open-weight AI strengthens the case that open models will keep pace, or even catch up. Meta has released more open models than any other organization, and is near the frontier of AI after releasing Llama 3.1 405B. They have announced plans for Llama 4 to use “almost 10x more” compute than Llama 3 next year (very likely meaning 10x more compute than the 405B model). Supposing that Llama 4 has open weights and is released in July 2025,22,23 Llama 4 would be exactly on-trend for closed models, eliminating the lag in training compute. This would be consistent with the historical trend in Llama models (see Figure 6). In reality, the lag will also be affected by new closed models, but this is evidence for a shorter lag next year.
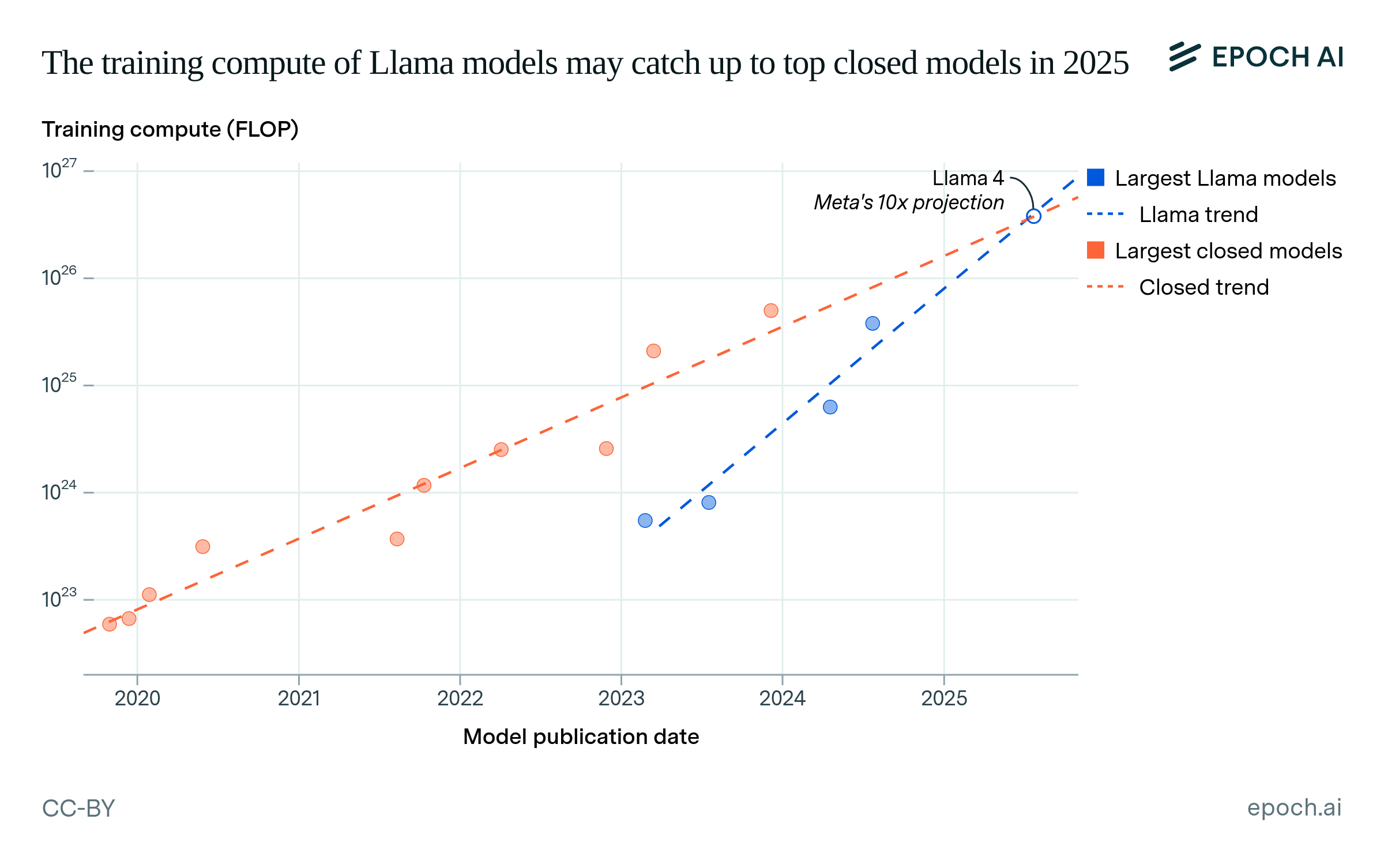
Figure 6: The trend in training compute for top-1 closed models, compared to the trend in the top Llama models. For illustration, we also show a hypothetical where Llama 4 is released with open weights in July 2025, and uses 10x more compute than Llama 3.1 405B (based on a statement by Meta’s CEO, Mark Zuckerberg).
Weighing up this evidence, the lag between the best open and closed models is likely to be shorter in one year’s time, but this may depend on Meta’s decisions. Meanwhile, we expect smaller open model developers will fall further behind the frontier of training compute.
In the long term, the economic value of open frontier models is a key uncertainty. This ultimately depends on whether it is more profitable for AI developers to directly sell access to their models, or to benefit from their models’ synergy with other lines of business.24 If open frontier models add enough benefit to the developer through shared innovations and user adoption, that could justify the R&D costs. However, this is a high bar if training costs grow to billions of dollars and beyond.25 Meanwhile, private innovations by closed model developers could increase their advantage over open model developers, letting them pull further ahead.26
Most notable AI models released between 2019 to 2023 were open
Here, we move beyond comparing the scaling and performance of open and closed frontier models, and analyze trends in the overall openness of models in the AI field. We also examine how release strategies have evolved in more detail, beyond simply classifying models as “open” or “closed”, using the accessibility framework we previously discussed.
Figure 7 shows the model accessibility split among notable models in our data, grouped by release year starting in 2018.27,28 From 2019 to 2023, a majority of these models were open, reaching as high as 66% of models released in 2023.29 This has not held in 2024 so far, but it is likely that notable open models are underrepresented in our current 2024 data.30 Cumulatively, open models make up 20% of notable models released as of 2018, and around 50% of notable models released as of today.
The prevalence of open models in recent years may be surprising, given that closed models have made up the vast majority of models near the frontier of compute.31 In addition, some major labs have moved away from openness over time, with OpenAI being a notable example. OpenAI’s GPT-2 in 2019 had open weights and code, but only after a several-month delay which OpenAI used to study whether GPT-2 could be misused in harmful ways. From GPT-3 onwards, OpenAI has not released the weights, training code, or data for their flagship language models.
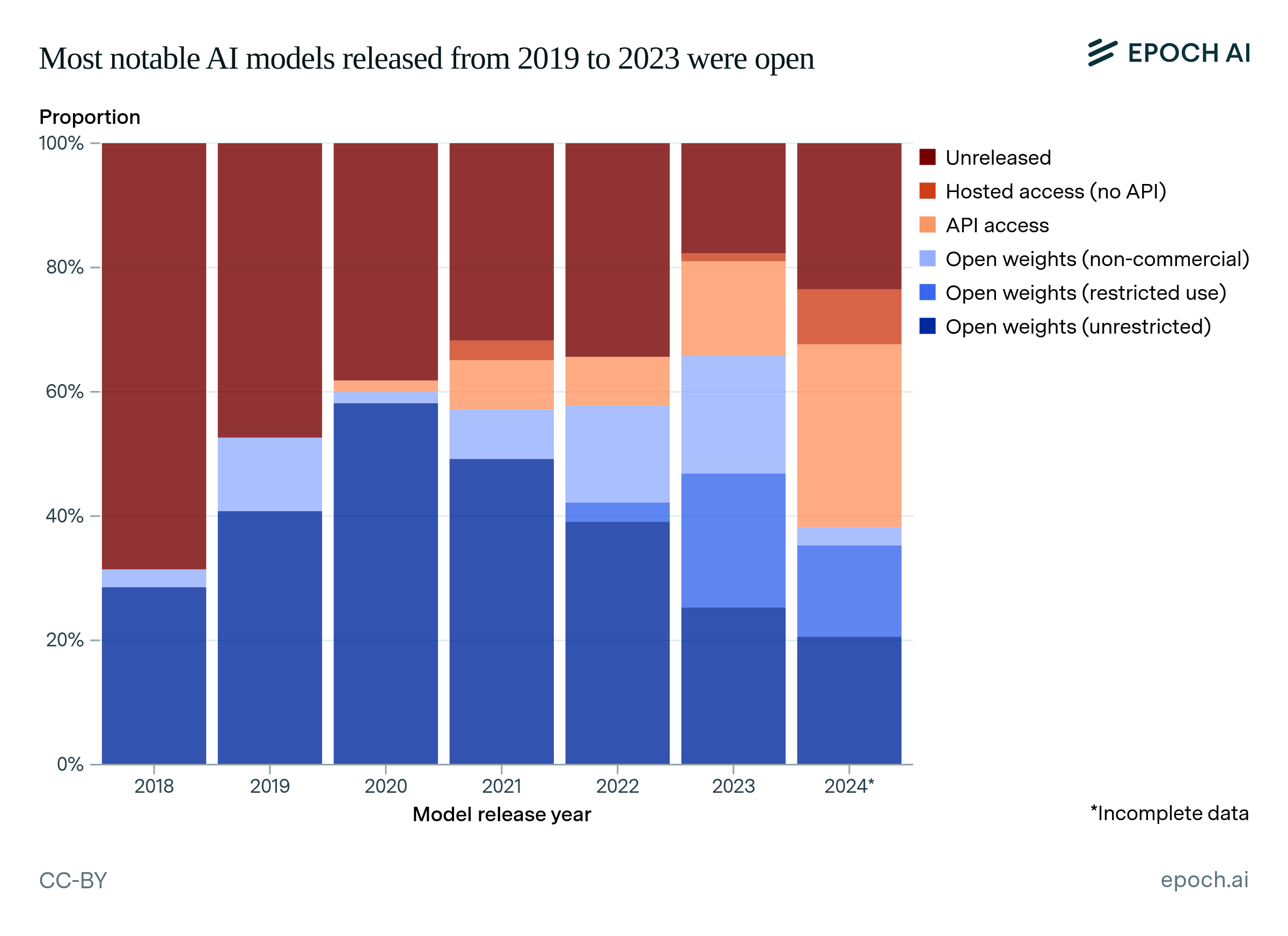
Figure 7: The proportion of notable AI models released in each accessibility category, by year. The blue portions are open-weight and the red portions are closed-weight, while the different shades represent more granular accessibility categories.
One explanation for the prevalence of notable open models is that the overall number of open models has grown greatly. The model hosting platform HuggingFace, founded in 2016, currently hosts over 1 million open models.32 This reflects the fact that the open model ecosystem has flourished in recent years, and it also means that most published models in general are open, making it more likely that a relatively high proportion of notable models according to our criteria are open.
Another contributor to the number of open models is that open weights have become more common among academic projects. For example, of the notable models that were published in 2018 and were developed or co-developed by academic organizations, only around 20% had open weights. However, in 2022 and 2023 over 80% of these models were open. This may be due to an influential push for openness even as AI has become more commercialized: for instance, a 2018 article in Science claimed that AI faced a reproducibility crisis.
When breaking model accessibility down into more granular categories, we see a growing middle ground in between completely unreleased models and open models with the most permissive licenses. Among open models, there has been a large shift towards more restrictive licenses for model weights. In 2018, only 2% of notable models were open-weight models with either a non-commercial or restricted use license. In 2023, this share reached 40%. This may reflect the growth in commercial open-weight models, which sometimes have license restrictions that limit the benefits to competitors.33 At the same time, a larger share of closed models have become accessible through products or APIs, without releasing weights, which also reflects the growing commercialization of AI. Overall, the proportion of notable models that are accessible to some degree (i.e. are not unreleased) has grown substantially.
In Appendix G we examine training code access, finding that it is correlated with model access, but did not rise as sharply after 2018.
Related work
Recently, several frameworks have been developed to understand and track openness in AI. Some of these frameworks consider openness as a spectrum along multiple dimensions, such as model weights, code, and data. Each of these dimensions can have multiple components, e.g. “code” can include both pre-training code and inference code. The most similar framework to ours is relatively simple, classifying six release strategies from “fully closed” to “fully open”, and examines these strategies over time. Such a framework makes it tractable to label hundreds of AI models, which allows us to reliably measure trends.
A related topic of research is the proliferation of AI capabilities and its impact. Previous work on this topic includes case studies of the release strategies of models like GPT-2 and GPT-3, and the attempted replication of these models by less-resourced actors. In particular, the latter study found that it took 23 months before GPT-3 was replicated (roughly speaking) with an open model, i.e. Meta’s OPT-175B.34 The 2022 State of AI report found that it took 15 months for open variants of DALL-E to be released, and 35 months for AlphaFold, though the open variants don’t necessarily reach similar performance.35 Other research presents perspectives on the benefits and risks of open foundation models, assesses their marginal risk, or presents alternative ways to achieve open-source objectives while reducing risk.
Our work bridges a gap between these two research areas of openness and diffusion in AI. We classify the accessibility of hundreds of AI models—many more than previous works that classify openness. Furthermore, we advance the understanding of AI diffusion by measuring the lag between open and closed models, and measuring rates of accessibility over time.
Discussion
Our findings have several implications for the future of AI development and policy. While open models have lagged behind closed models by around one year, the best open models are close to the frontier today. If this situation persists, it would enable freer access to models with the most advanced capabilities. Organizations outside of the largest AI developers would be able to fine-tune and deploy custom versions of near-frontier models to suit their own needs. This could boost innovation, AI safety research, and beneficial applications of AI. However, it could also make the potentially harmful capabilities of advanced AI more accessible.
The lag between open and closed models provides a window for policymakers and AI labs to assess frontier capabilities before they become available in open models. Our analysis points to a lag of about one year, though the range of our estimates is 5 to 22 months. The lag has not clearly increased or decreased in the past five years. However, we expect the best open model next year (possibly Llama 4) to be even closer to the frontier than the best open models today. A lag of less than one year is short by the typical standards of legislation, which highlights the need to proactively assess capabilities at the frontier.
Several parts of this work motivate further research. Firstly, our analysis of benchmarks did not separate the effect of algorithmic or data innovations from other factors, like targeted training procedures or data contamination. An ablation study would help separate these factors. Secondly, analyzing the economics of open vs. closed AI models would help predict future release strategies. One aspect of this is the user adoption of models. For example, if closed models are favored by users, the open-model strategy may decline. Thirdly, analyzing the effect of potential regulations on the open AI ecosystem would help inform AI policy. For example, since open models can be modified and distributed without oversight, developers of an open model may find it harder to comply with regulation that holds them liable for the model’s harms.
Release strategies in AI continue to evolve and spark debate. This work contributes valuable insights to inform these discussions. We have clarified the current gaps between open and closed AI models, finding that the best open models have lagged behind the best closed models by around one year. This lag is relatively short and is likely to get shorter next year, partly due to Meta’s release decisions. These insights can help policymakers and AI developers plan for the real possibility of open models at the frontier of training compute and capabilities.
We thank Markus Anderljung, Tamay Besiroglu, Stella Biderman, Ben Bucknall, Jean-Stanislas Denain, Alexander Erben, Ege Erdil, Kyle Miller, Elizabeth Seger, Jaime Sevilla, and Caleb Withers.
Appendix
A. Classification of accessibility
A.1. Model accessibility
Table A1 lists the definitions of the model accessibility categories used in our database of AI models. Some of these categories are not mutually exclusive; e.g. a model can be both downloadable and available in API or a product, so we classify models according to the order of the table, which is ranked from most permissive to least. That is, when reading the table from top to bottom, the first category that applies to the model is selected.
A.2. Training code accessibility
Training code accessibility denotes how the code used to train an AI model can be accessed and used by the public. We label a model’s training code “Open source”, “Open (restricted use)”, or “Open (non-commercial)” if the training code is downloadable by the public, i.e. “open”. “Open source” meets the standard definition of open-source code, while the other two categories are similar to their counterparts in the model accessibility field (see Appendix A.1). If there is no publicly available code, or the released code does not train the model from scratch, then the label is “Unreleased”, i.e. “closed”. If the code is not in the exact configuration for training the model, and it is not clear how to replicate that using the documentation, then the label is also “Unreleased”.
A.3. Dataset accessibility
We classify dataset accessibility independently of AI models. AI models can be trained using multiple datasets, each of which have different accessibility. We label each dataset using similar categories to the training code accessibility field, but here “Unreleased” simply means the dataset has not been released.
B. Scope of the data
We comprehensively labeled models from the Notable AI Models database from the beginning of 2018 onwards. We did not systematically collect accessibility data for models published before 2018, so our data before then is sparse. While the choice of 2018 is somewhat arbitrary, it shortly follows the introduction of the Transformer model architecture in mid-2017, which was crucial to the rise of large language models that began with GPT-1 and BERT in 2018. We cut off models published after September 30, 2024.
When analyzing training compute and benchmark performance, we exclude models which are derived from another, already-published model through knowledge distillation, additional fine-tuning, or reinforcement learning. An example is Vicuna-13B, trained by fine-tuning LLaMA-1 13B. In the case of training compute, this avoids effectively double-counting the compute of pretrained models. In the case of benchmarks, excluding these models simplifies the analysis and allows fairer comparisons between models, as fine-tuning can have large effects on benchmark performance using relatively little additional compute.
Although we filter out models that are fine-tuned separately from the original model, several of the models that we do include (both open and closed), such as Llama 3.1 405B, have already undergone fine-tuning before release. This is a reasonable trade-off, since these models often mark important milestones, and often use relatively broad fine-tuning data (rather than training for one benchmark).
When analyzing rates of openness, we are interested in all of the individual decisions to release model weights, code and datasets. So in contrast to the compute and benchmark analysis, we include all notable models in the analysis of openness.
C. Compute regression analysis
C.1. Regression model selection
We applied a bootstrapped log-linear regression to the training compute of AI models over time. The model shown in Figure 4 uses a separate slope and intercept for open and closed models. We also tested alternative model specifications, where the slopes and/or intercept parameters are shared between open and closed models.
As listed in Table A2, the BIC and cross-validation MSE of the same-slope model are approximately 19 and 0.11 respectively, similar to the different-slope model at 22 and 0.12. The same-slope model gives a similar lag of 16 months (90% CI: 12 to 20), compared to 15 months for the different-slope model (90% CI: 6 to 22). These fits are both better than using a single exponential (i.e. same slope and intercept). We also tested kinked exponential models, which account for possible changes in growth rate. However, these models were a worse fit than the simple exponential models.
C.2. Difference in growth for open and closed models
An important question in this work is whether open models will catch up to closed models in the future, or fall further behind. One source of evidence about this is the historical growth of compute for open vs. closed models. If one category of models is growing significantly faster, that suggests the two groups will either converge or diverge.
We therefore test for a significant difference between slopes in the training compute regression for open and closed models. For top-1 models, we find that the slopes are not significantly different based on a t-test (p=0.90). However, other sets of models have a different trajectory. The slope of open models is slightly slower for e.g. top-10 models since 2018 (p<0.01), top-10 models since 2021 (p=0.04), and top-3 models (p=0.02). In all three cases, the bootstrapped distributions of the slopes also have less than 5% overlap. While top-1 models are the odd one out for having similar slopes, we believe the top-1 models to be of greatest interest, so we use that for our main result.
D. Selecting and vetting model evaluations
We took several steps to select reliable benchmarks and filter models from our analysis that showed concrete evidence of overfitting.
We include MMLU and BBH, which test knowledge and reasoning respectively, because they have historically been among the most commonly evaluated benchmarks, providing ample data to work with. However, these benchmarks have evidence of being contaminated in commonly-used training datasets (at least with very similar data, if not verbatim).36 To avoid anchoring to potentially unreliable results, we supplement our analysis with more reliable (but less data-rich) benchmarks: GSM1k (grade-school level math questions) and GPQA (PhD-level science questions).
We include GSM1k because it is a new, private version of a previous benchmark, GSM8k, that has many evaluations already reported. The SEAL Math leaderboard lists GSM1k results, in addition to the results in the original paper. If a model was evaluated on SEAL Math, then we use that result, whether or not the model was evaluated in the original paper. Some models perform much better in the SEAL Math evaluation because their “chattiness” is not penalized. Excluding the SEAL Math evaluations results would exclude the 9-month and 6-month lag in the GSM1k results, leaving only the 10-month lag.
For benchmarks other than GSM1k, we exclude models that did substantially worse on GSM1k relative to GSM8k, such as Mixtral 8x22B. We consider a model overfitting on GSM8k to be weak evidence that the model also overfits on other benchmarks.
As a further check, we compare the performance of GPQA to MMLU. GPQA was released in November 2023, while MMLU was released September 2020. This means that models are currently less likely to be contaminated or optimized for GPQA compared to MMLU. Though this is only weak evidence of overfitting on MMLU, out of caution we exclude models whose relative performance was better on MMLU than GPQA. The additional models we exclude are Yi-34B, gpt-4-0613, gpt-4-0125-preview, Reka Core, and Qwen-2 72B. The results for benchmark lags are unaffected by the model exclusions, however. When analyzing GPQA results, we still include gpt-4-0613 because it was released before the GPQA benchmark.
For MMLU and BBH performance, we use results reported in the literature. We aim to be consistent about these results using few-shot prompting and no chain-of-thought, but for some models this is unclear or unavailable. For GPQA, we use our own evaluations with chain-of-thought, zero-shot prompting on the Diamond set. For models that have multiple versions, such as GPT-4, we separate the known versions of the model. Each model version is included in our analysis if it was at the frontier for that benchmark.
E. Benchmark performance vs. training compute
E.1. Model selection
The results of different regression models on MMLU and BBH performance are listed in Table A3 and Table A4, respectively. These results show how fitting to model publication date is comparable to (or better than) fitting to the open/closed category of the models.
Figure A1 shows the MMLU model fits for “compute” and “compute, date” that are listed in Table A3.
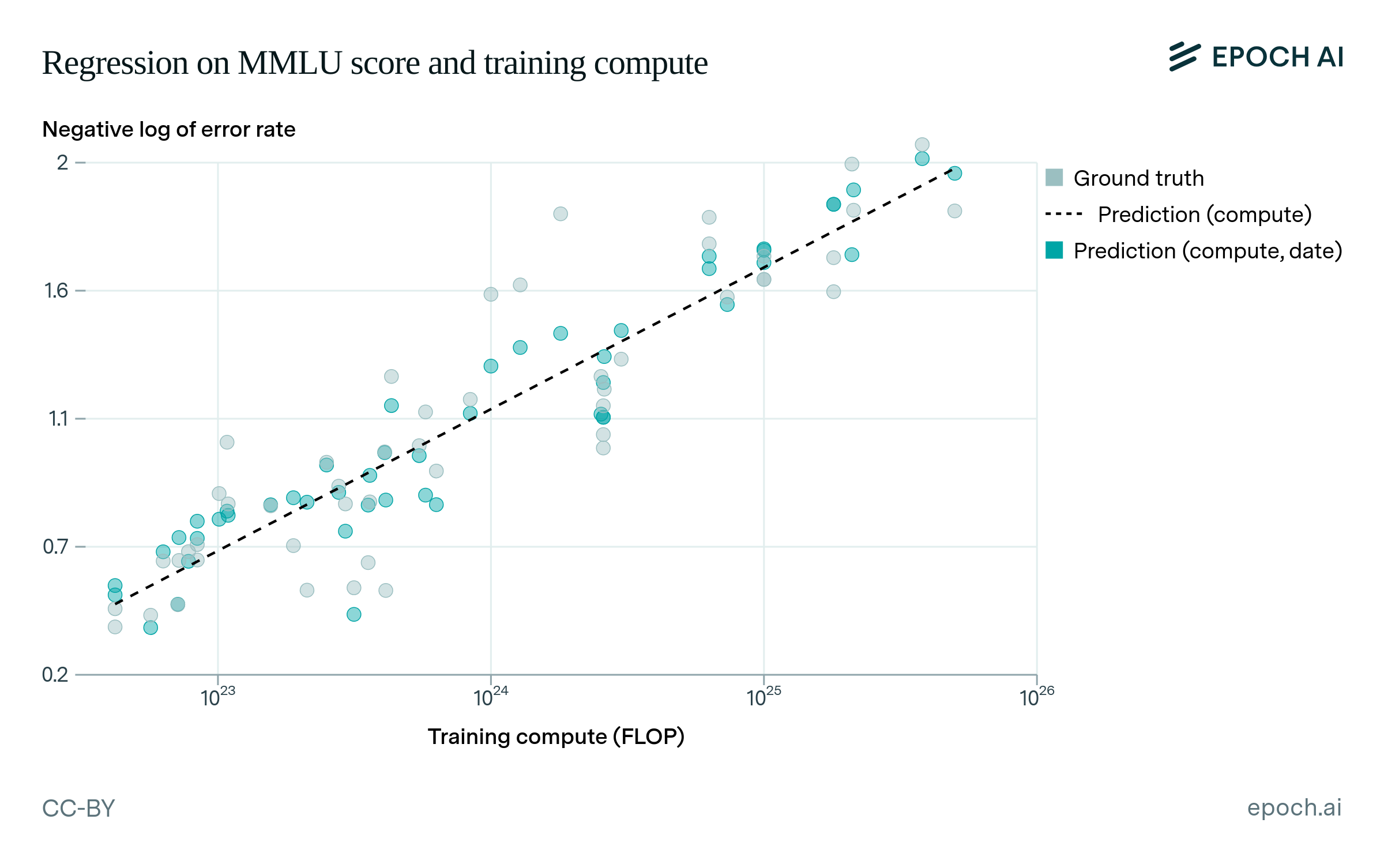
Figure A1: Predictions of MMLU performance (measured as the negative logarithm of the error rate). Regressing on compute and publication date explains more variance than regressing on compute alone, as shown by smaller residuals. The BIC is also lower, suggesting this is supported by the data.
E.2. Benchmark performance vs. training compute for all benchmarks
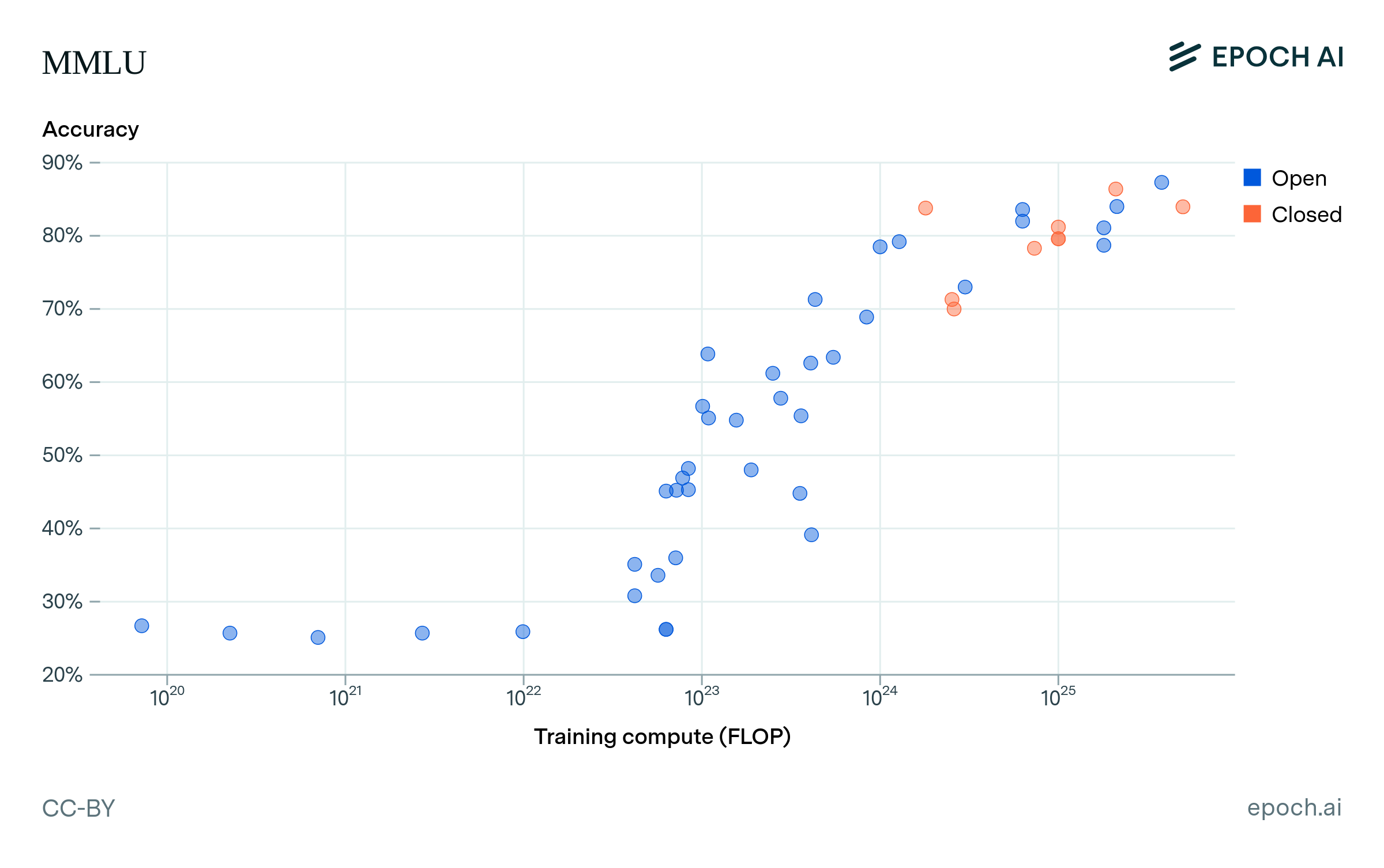
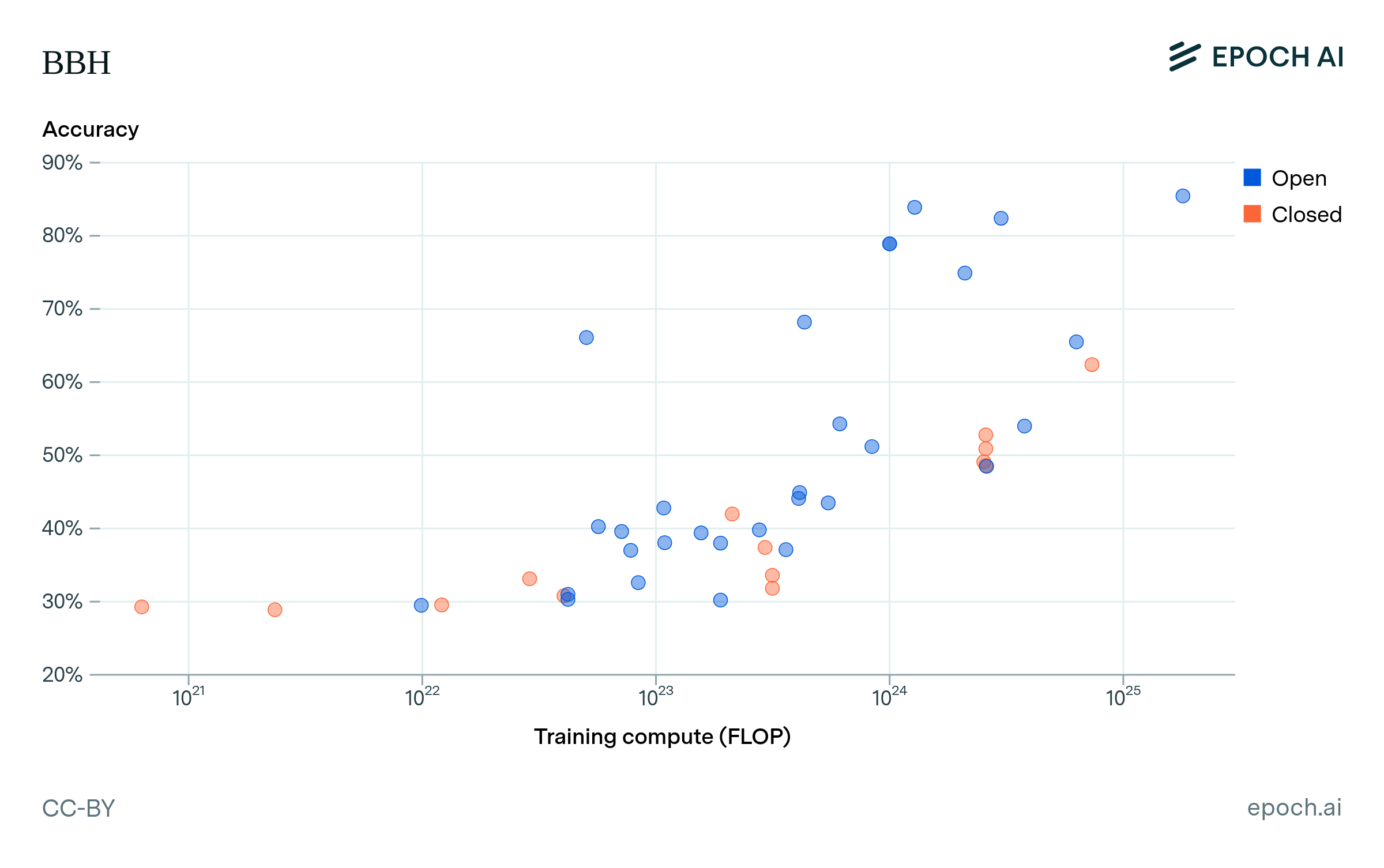
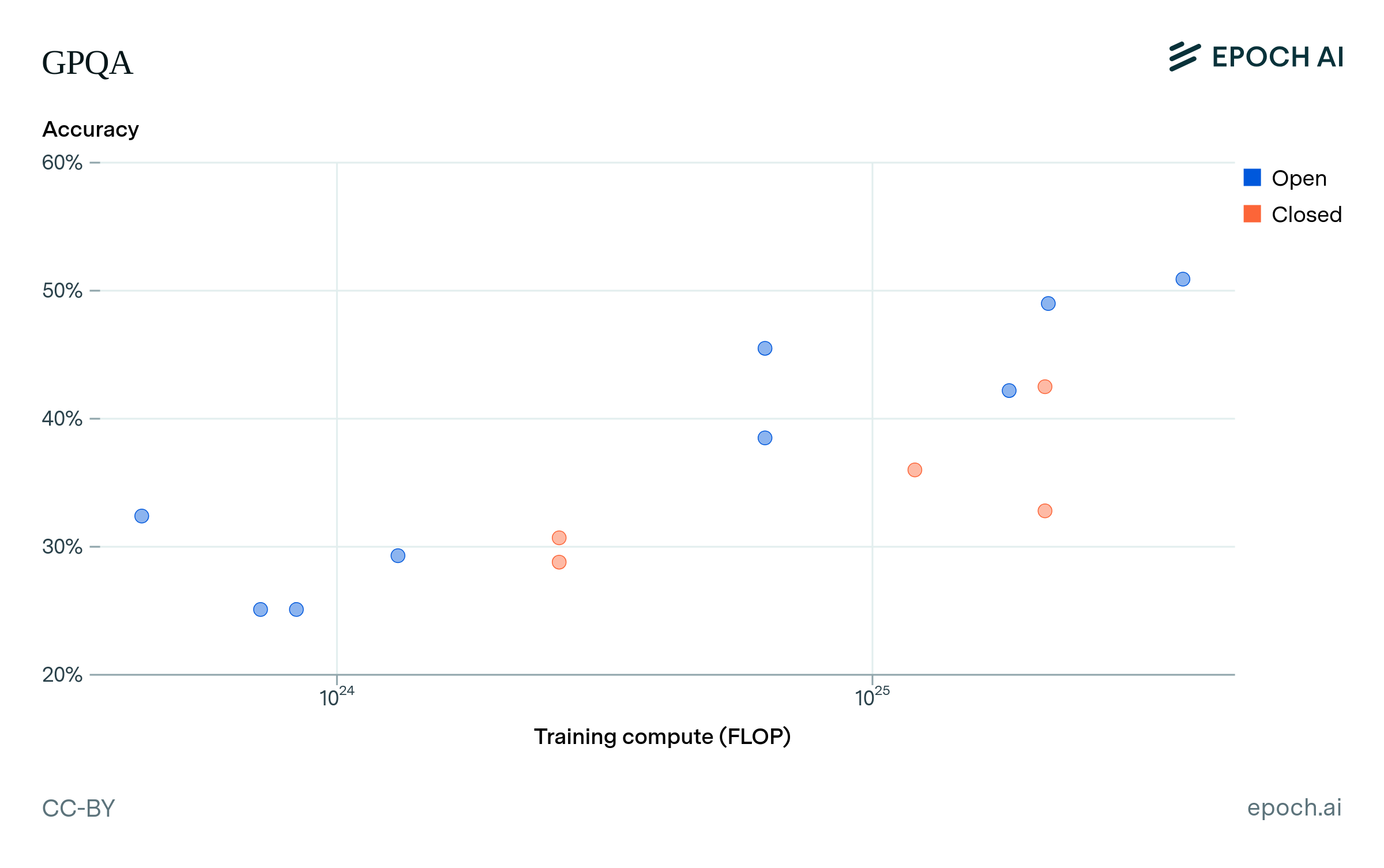
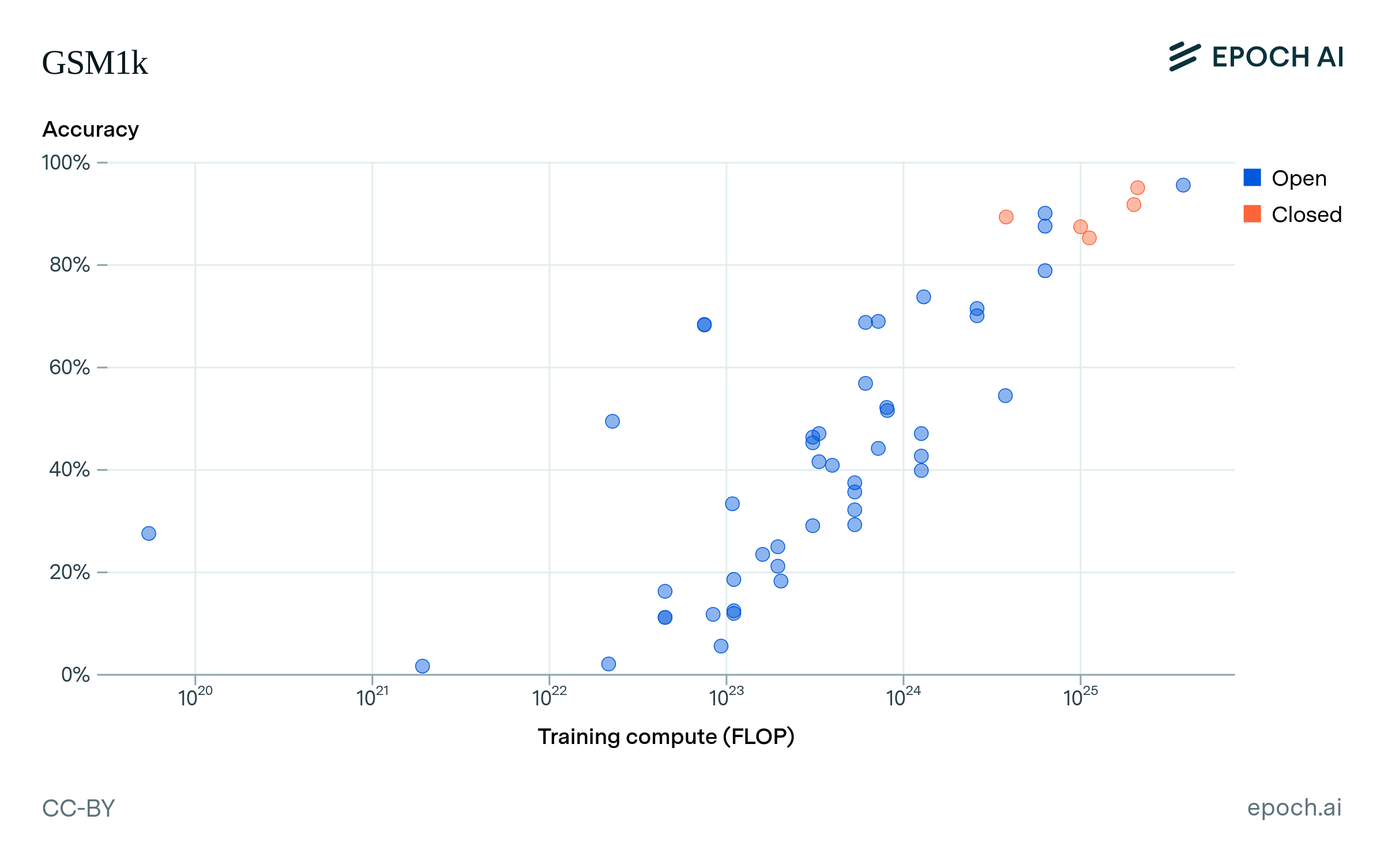
Figure A2: Performance on MMLU, GPQA, the GSM1k, and BBH, for open and closed models at different compute scales. Note that some of the highest-performing closed models are missing, because there is not enough information to estimate their compute.
F. Backtesting regression models
We backtest our training compute regression model to assess its predictive power. Figure A3 shows an example of a backtest, where the training set is before January 1, 2023 and the test set is afterward. This example uses the “same-slope” regression model, which finds the single best slope parameter for both open models and closed models (but with different y-intercepts). For each backtest, we calculate the root mean squared error of the predictions on the test set. We repeat this evaluation using the publication date of each AI model as a train-test split date, starting from halfway through our data up to the most recent model.
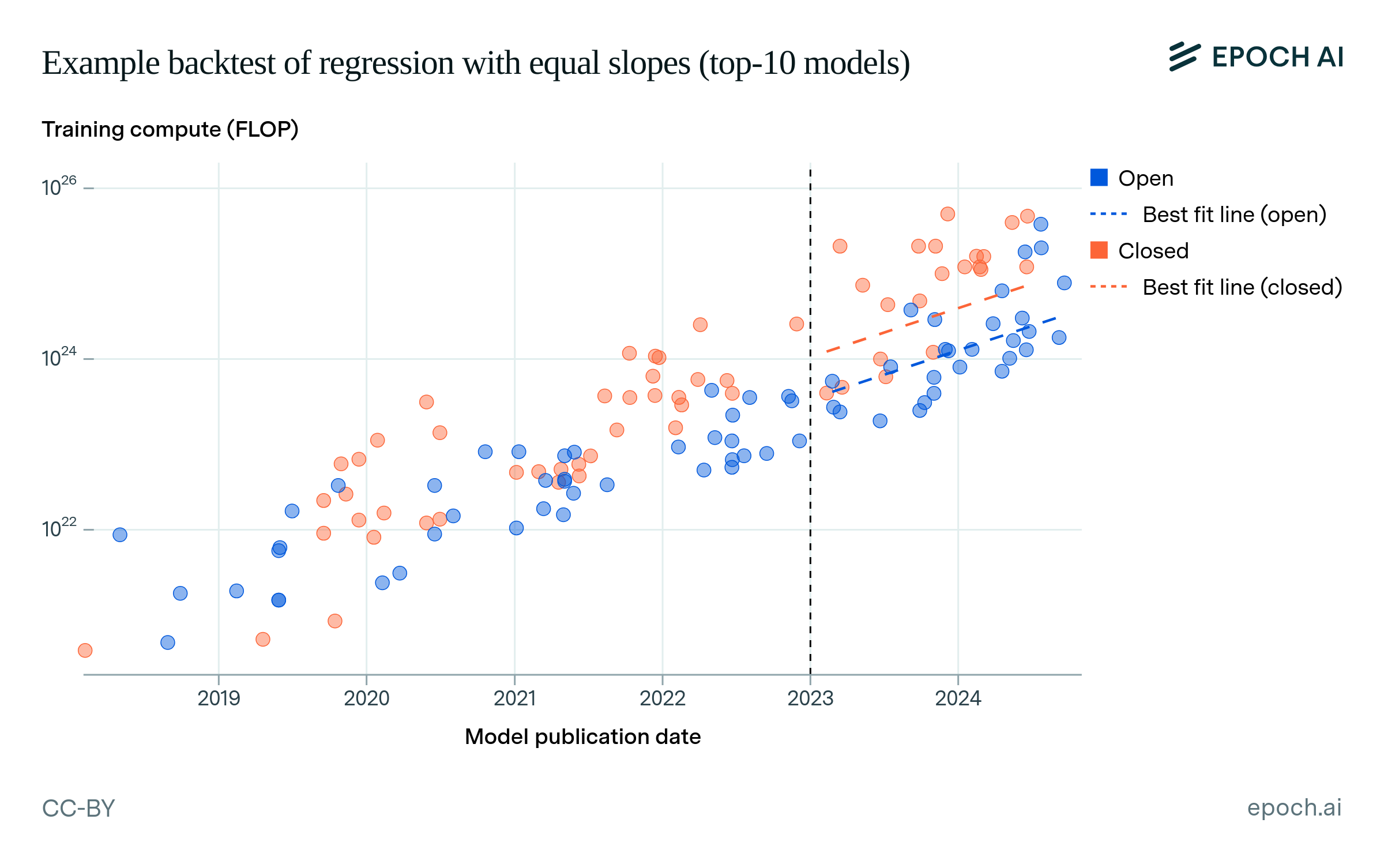
Figure A3: Example of a backtest where the train-test split date is 1 January 2023, and the regression model fixes the slope for open models and closed models to be equal.
Figure A4 shows the resulting test RMSE values for each train-test split date. For most split dates (April 2022 to December 2023), the same-slope regression model has similar test error to the default, “different-slope” model. After December 2023, the error increases for both models, peaking at the publication date of Llama 3.1 405B. This matches the intuition that some 2024 models like Llama 3.1 405B are off-trend, and therefore harder to predict. However, the equal-slopes model has slightly lower error than the different-slopes model in this period, meaning it is a better predictor of this change.
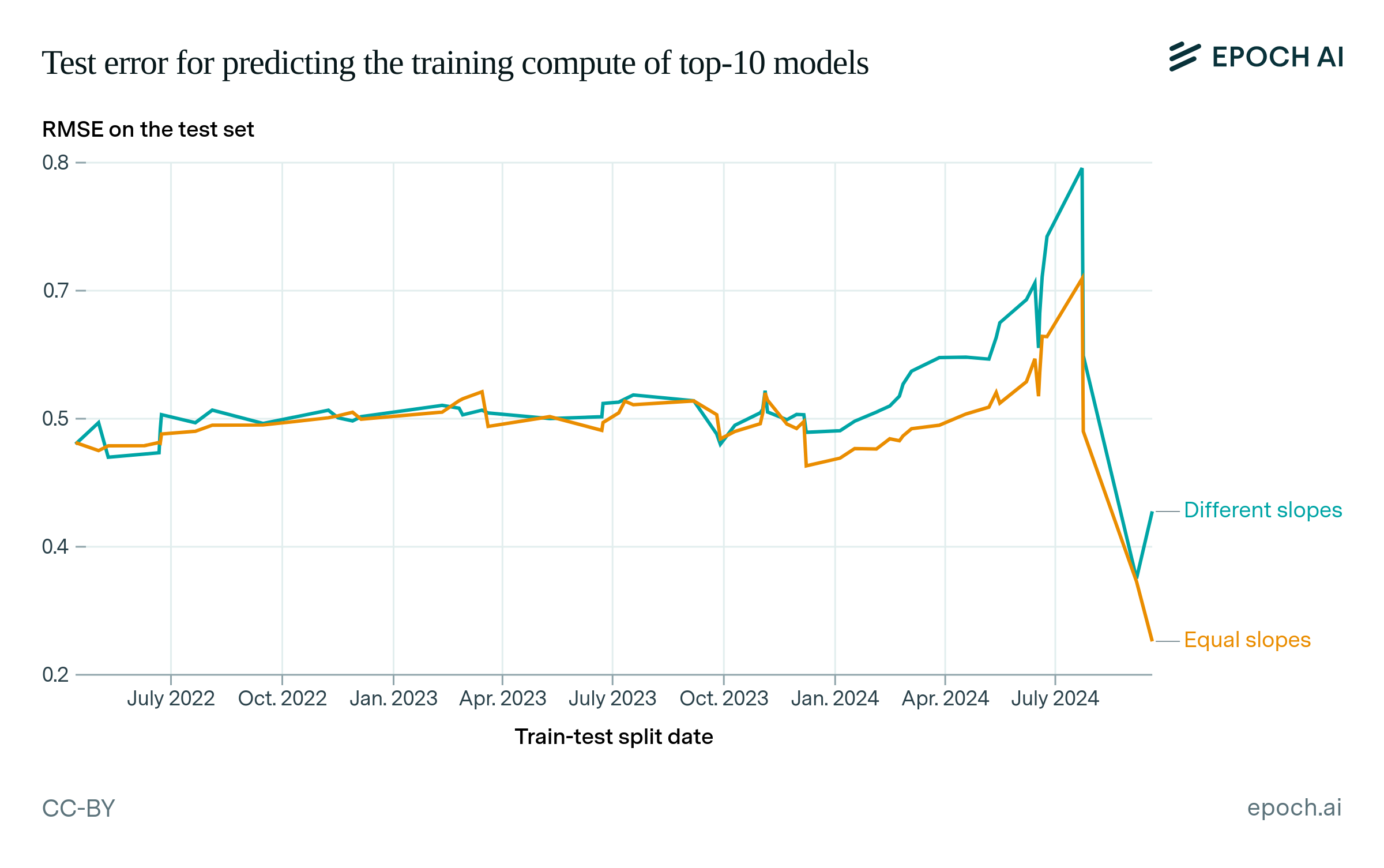
Figure A4: Root mean squared error (RMSE) of each regression model on the test set, for different train-test split dates. The “same-slope” model finds the single best slope parameter for both open and closed models (but with separate y-intercept parameters). The “different-slope” model is the default model, which finds the best-fitting slope and intercept for each category. The error is in units of log10(FLOP)—for example, 0.5 corresponds to a relative error of approximately 3x in FLOP.
G. Model access is correlated with training code access
Among notable models, open weights and open training code are fairly correlated, as shown in Figure A5. Most closed-weight models have closed training code, while most open-weight models have open training code. This also applies in the other direction—most closed-code models also have closed weights, and most open-code models have open weights. Overall, 67% of models have either open weights and open code, or closed weights and closed code.
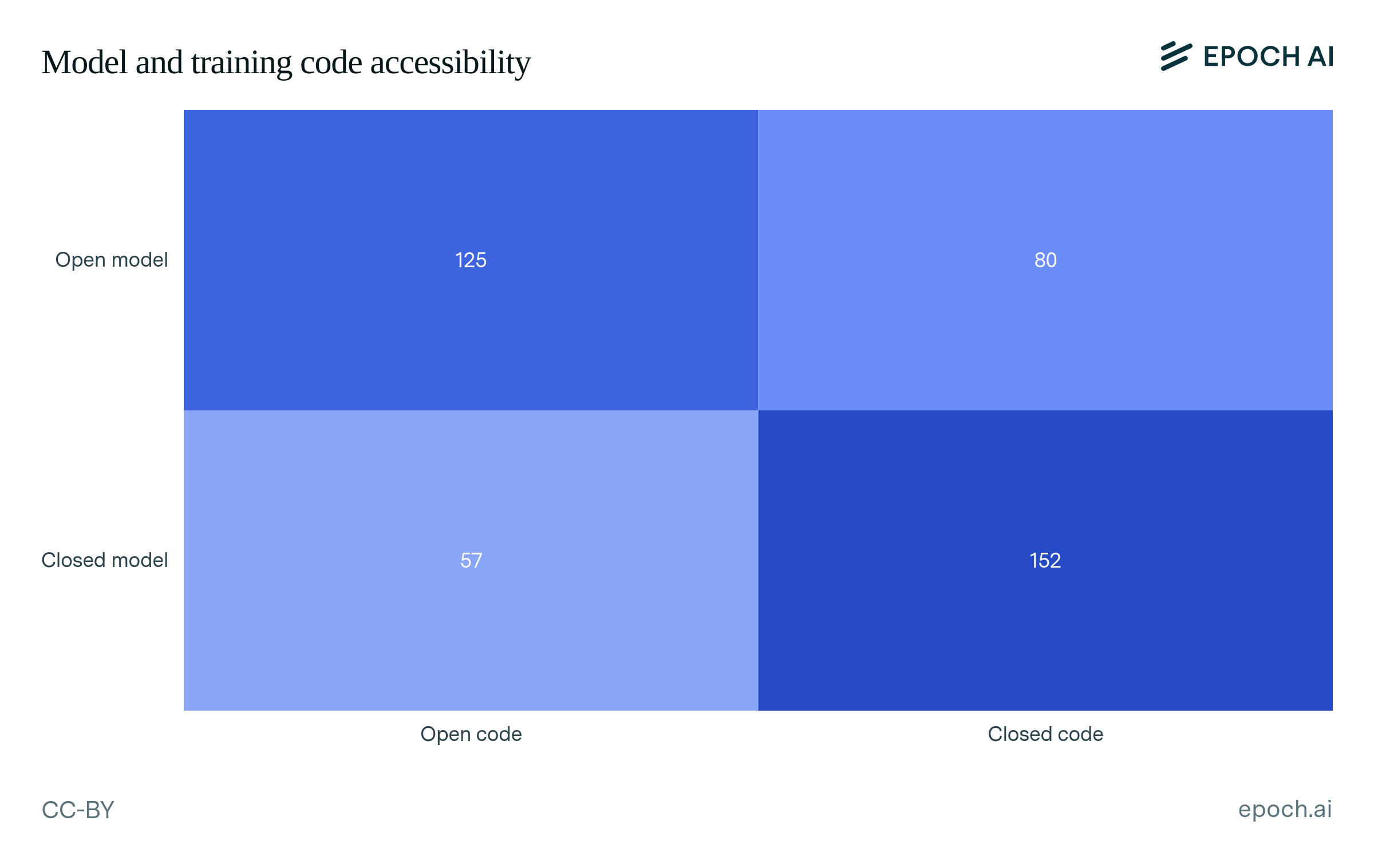
Figure A5: Number of AI models that use different combinations of model and training code accessibility
Figure A6 shows what proportion of notable models in our dataset have open/closed weights and open/closed training code, across the four possible combinations, by the year in which they were released.
Among open-weight models, closed training code has become more common over time. Intuitively, this is consistent with the rise of commercial open-weight models, and our data suggests that commercial developers are indeed contributing to this trend.37 Developers may choose to release model weights but keep their training methods proprietary, so that they can learn from other developers’ innovations in post-training techniques, while retaining their own techniques for training base models.38 Meanwhile, a non-commercial actor that simply wishes to share research has more straightforward reasons to release both training code and weights.
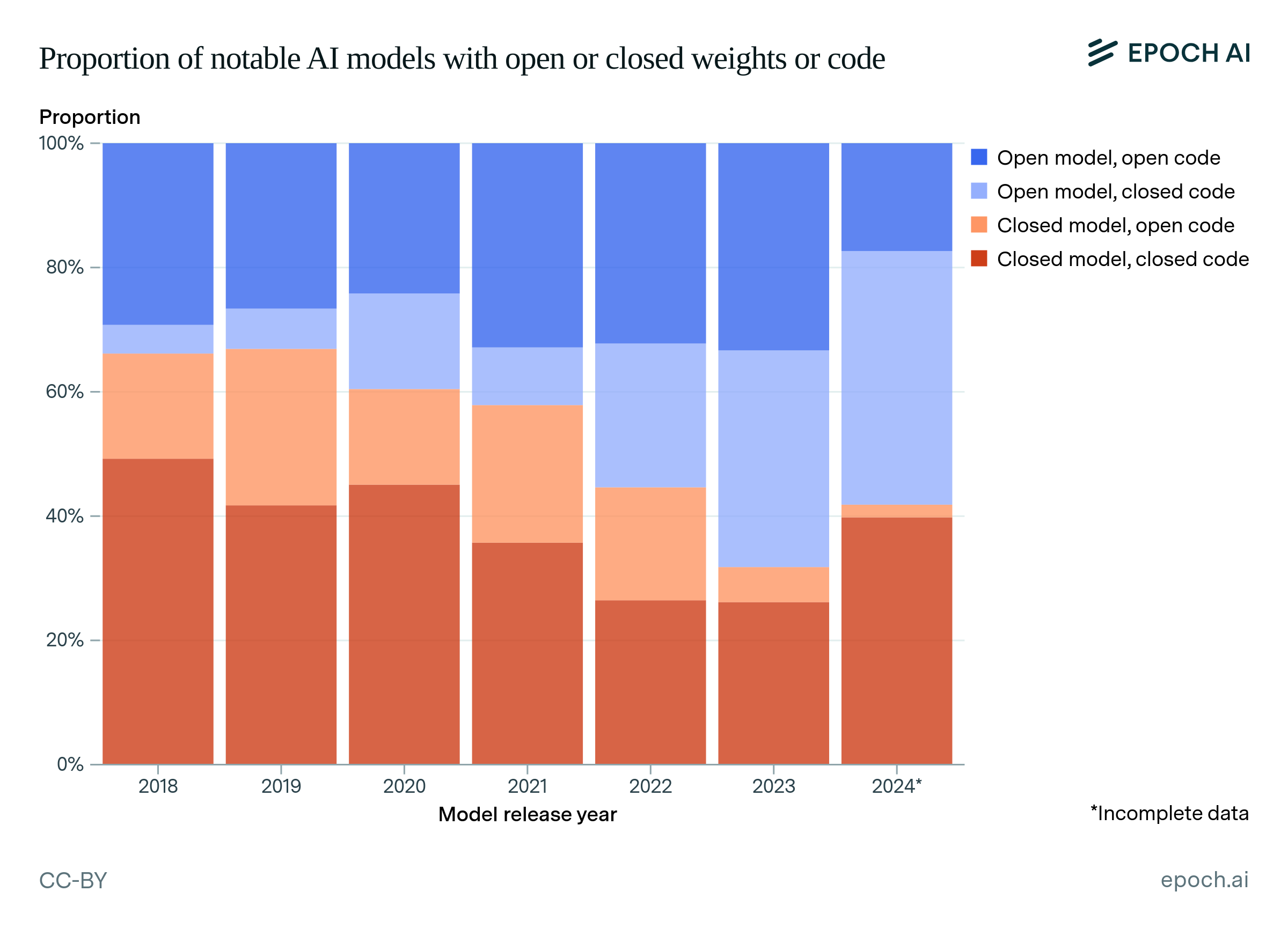
Figure A6: The proportion of notable models that have different combinations of model and training code accessibility.
Another noticeable trend is that open code was quite common in the past. In 2018 and 2019, open code was actually more common than open weights. However, the proportion of models with open code but closed weights has been shrinking, perhaps because sharing weights was previously less important for research projects when the compute cost of training was lower.
H. Fully open training data is rare among recent leading LLMs
Although we created a framework for classifying dataset accessibility, we have not yet collected comprehensive data on dataset accessibility for ML models. It is relatively difficult to gather this information because models can be trained on a large number of different datasets, which may be a mix of open and closed. Closed datasets are often difficult to identify because they are proprietary, and therefore may go unmentioned in technical reports.
While we don’t have systematic information on data accessibility to analyze trends, it is still clearly true that most recent leading LLMs (even those with open weights) were primarily or entirely trained on datasets that have not been openly released. This includes recent frontier models from OpenAI, Anthropic, and Google DeepMind, and major open-weight models such as the Llama 3 family, the Gemma family, Nemotron-4, and Mistral Large 2.
LLaMA 1 is a clear example of a language model with fully open training data, but it is almost two years old. Falcon 180B comes close to having open data; it was trained on the RefinedWeb dataset, which has a detailed paper explaining how the dataset was constructed, and an openly-released 600 billion token extract. However, the full RefinedWeb dataset, which is five trillion tokens, is not publicly available.
Note that much of the data contained within proprietary text datasets is publicly available in a sense. NVIDIA’s Nemotron-4 paper notes39 that large language models are frequently trained on public web data from sources such as CommonCrawl, which anyone can access.40 However, this raw web data is then processed to remove duplicates and to filter for quality before it is used for training,41 and the processed datasets are often kept private.42
Notes
-
If models can be downloaded, they may be distributed even after the publication is revoked. Additionally, open model developers cannot cut off access to specific users, as OpenAI has done in some cases. ↩
-
“Model safeguards” means training intended to prevent a model from producing harmful outputs. These can be removed by fine-tuning the model further, and if a model’s weights are downloadable, the model can be fine-tuned by anyone. ↩
-
Details on the scope of the data we collected and analyzed in this report are in Appendix B. ↩
-
We arrive at this figure through a weighted estimate from the historical trends: half weight to the training compute lag, and the remaining weight to the benchmark lags. The result is 14 months. The possibility of Llama 4 leads us to expect a slightly shorter lag than this, but still close to one year. ↩
-
Liesenfeld and Dingemanse (2024) argue for the importance of open training code and data in greater detail. ↩
-
It is also possible for model developers (e.g. OpenAI) to give third parties the ability to create a custom fine-tune of models without releasing model weights. But with an open model, the third party has a greater choice in fine-tuning techniques and does not have to share private data with the developer. ↩
-
It is unclear how consistently these licenses can be enforced, given that models can be downloaded and deployed offline. Violating licenses could be viewed as a meaningful legal risk by larger and more cautious actors but this may not be universally true. As one example, ByteDance has reportedly been violating OpenAI’s terms of service by using OpenAI models (which are proprietary models, and are easier to restrict than an open model) to train ByteDance’s own models. ↩
-
These distinctions are quite important, since some of the most widely-used models in the world, such as the models powering OpenAI’s ChatGPT, have closed weights but are available via APIs or applications. This structured access enables wide usage, but retains the ability to pull the model from deployment or block users. ↩
-
In principle this lag can be negative, meaning the open model was first. To account for noise in evaluations, we allowed the open model’s error rate on the benchmark to be up to 2% higher than the closed model, in relative terms. For example, 49% accuracy (i.e. 51% error rate) counts as “matching” 50% accuracy. Without this tolerance, BLOOM 176B is not counted as matching GPT-3 (text-davinci-001), and the 95th percentile of the lag on benchmarks is 23 months instead of 22 months. ↩
-
For GSM1k, we lack a result for the original GPT-4 from March 2023. It is plausible that this would perform similarly to the later gpt4-0125-preview model. If that were true, we’d measure a single lag of 16 months instead of three lags of 10, 9 and 6 months. This would increase the mean lag over all benchmarks from 13 months to 15 months, but wouldn’t change the 90% CI. ↩
-
We checked the sensitivity of this result to Meta’s “Llama” model series. Meta is arguably the leading open model developer and has published many of these models. Llama 3.1 405B is the most training-compute intensive open model to date—if this is excluded, the 95th percentile lag increases to 23 months. If all Llama models are excluded, the 95th percentile lag increases to 24 months. The lower bound is unchanged at 5 months. ↩
-
To give a sense of the gap, on SEAL Coding the highest-ranked closed model, o1-mini, has a win rate of about 76% on the highest-ranked open model, Mistral Large 2. Rankings are current as of October 6, 2024. The scores are not stable over time, so they cannot be used to estimate the lag between models. ↩
-
See Appendix E.2 for the performance vs. training compute plot for all four selected benchmarks. ↩
-
Quality of fit is measured by the Bayesian Information Criterion (BIC), and the mean-squared error of 10-fold cross-validation. See Appendix E.1 for detailed results. We find qualitatively similar results on BBH. The other two benchmarks, GPQA and GSM1k, lack sufficient data to draw conclusions. ↩
-
The authors only evaluated open models, and models were split before and after November 2023. ↩
-
This process can select low-compute models initially, since there are no previous models to compare to. So to avoid fitting an artificially steep trend in compute, we kickstarted the top-1 open and closed models with the overall top-1 models as of 2018-01-01. The estimated lag between open and closed models today is not drastically different without this kickstarting (18 months; 90% CI: 9 to 24 months). ↩
-
For example, filtering to top-10 models instead of top-1 (17 months), or starting the top-10 models from 2021 instead of 2018 (16 months). ↩
-
NVIDIA’s Nemotron-4 roughly tied GPT-4 in compute 15 months after GPT-4’s release. ↩
-
As with our benchmarks analysis, because Meta is a major open model developer, we reran our analysis to test how sensitive the trend is to Meta’s Llama models. Excluding just Llama 3.1 405B increased the lag in compute trendlines to 18 months, while excluding all Llama models decreased the lag slightly to 14 months. ↩
-
We arrive at this figure through a weighted average of the historical trends: half weight to the training compute lag of 15 months, and the remaining weight to the benchmark lags ranging from 5 to 22 months. The weighted mean is 14 months. ↩
-
The difference in growth rates is significant, with the bootstrapped 90% CI in the growth rate being 4.3x to 5.9x/year for closed models, and 3.2 to 4.1x for open models. ↩
-
On the same earnings call that mentioned Llama 4, Meta’s CFO mentioned “open sourcing subsequent generations of Llama”. However, each generation of Llama models has had multiple sizes, so this statement is consistent with keeping the most capable version of Llama 4 closed. Elsewhere, Meta’s CEO Mark Zuckerberg indicated that he hasn’t committed to making every future model open. ↩
-
This is 12 months after the release of the largest Llama 3 model, but Llama 4 may be released sooner, given that Llama 2 was released 5 months after Llama 1, and the first version of Llama 3 was released 9 months after Llama 2. ↩
-
Meta is pursuing open models in order to foster an innovative Llama ecosystem, so it can use Llama to improve its other products. NVIDIA may also continue releasing large open models in order to strengthen the overall AI industry, which would lead to more GPU sales. ↩
-
As a point of reference, the Linux kernel—one of the largest open-source software projects—would cost on the order of $1 billion to re-develop as of 2010. That cost is likely to be much larger now, as the codebase has expanded. ↩
-
Another reason that open models may decline is concern about foreign powers using open models to their advantage. For example, it was recently reported that Chinese researchers used one of Meta’s Llama models for military applications. ↩
-
We did not systematically collect accessibility data for models published before 2018, so our data before then is sparse. This choice of year was somewhat arbitrary, but 2018 is shortly before the rise of large language models like BERT and GPT-1. ↩
-
See our notable AI model database for full data and documentation, including how we define notability. While models that are near the frontier in training compute or capabilities are very likely to be present in our database, we have not cataloged every model that meets our notability criteria. ↩
-
For context, around 60% of the open notable models in our data are language models, or multimodal models with language abilities. ↩
-
We conducted an extensive search of large-scale and other notable AI models (both open and closed) in early 2024, which we believe results in a representative dataset for notable models published before that date. Since then, we prioritized adding leading AI models, which, as we have shown, tend to be closed. For that reason, open models are likely underrepresented in the current 2024 data. ↩
-
Closed models are 68% of the overall top-10 models and 100% of the overall top-1 models since 2018. ↩
-
Most of these seem to be very minor projects: when we scraped HuggingFace’s data earlier this year, we found that less than 2% of models had been downloaded more than 100 times. ↩
-
For example, Meta’s Llama 2 license prohibited using Llama 2 outputs to train other AI models. This restriction was lifted for Llama 3.1. ↩
-
The first GPT-3-level model we identified was BLOOM-176B, released two months after OPT-175B. The only source we found on the MMLU performance of OPT-175B implied an overall score of 29%. This is unexpectedly low, since the smaller OPT-66B model scored 36% in a separate evaluation. The former result did not seem as reliable, so we discarded it. ↩
-
The most recent State of AI report noted that AlphaFold3 was quickly followed by HelixFold3 with open-source code (about 3 months later), but again without fully comparable performance. The report also noted that Llama 3 closed the gap between open and closed models. ↩
-
See Rethinking Benchmark and Contamination for Language Models with Rephrased Samples and p.34 of the Llama 3.1 paper ↩
-
Specifically, among open-weight, closed-code models, 86% were developed or co-developed by industry organizations, and only 43% were developed or co-developed by academia. Meanwhile, among open-weight, open-code models, 77% were developed by industry and 54% by academia. ↩
-
For example, Mistral releases the weights for most of their models, but generally does not publish training code and discloses almost no information about training data. Google’s Gemma 2 model weights were also published without code. ↩
-
“As a consequence, a major focus of language modeling training efforts has shifted to collecting high-quality multi-trillion token datasets from public sources such as Common Crawl.” ↩
-
This means that anyone can download this data, though that doesn’t necessarily imply they have the legal right to use all of that data to train AI models. ↩
-
From the Nemotron-4 paper: “In constructing the pre-training corpus, we remove any possible duplicates via document-level exact and near-deduplication (Jennings et al., 2023). We additionally applied document-level quality filtering across our corpus using a language-model based filtering approach similar to (Wenzek et al., 2019) in addition to a series of heuristic filters as described in (Rae et al., 2022) and (Raffel et al., 2020)” ↩
-
It’s unclear how superior these private training datasets are compared to open datasets. In general, careful curation of training data can substantially improve training efficiency: in one experiment, FineWeb-Edu, an open dataset released in 2024, led to much better results than a GPT-3 training run from 2020. ↩
About the authors




Related work