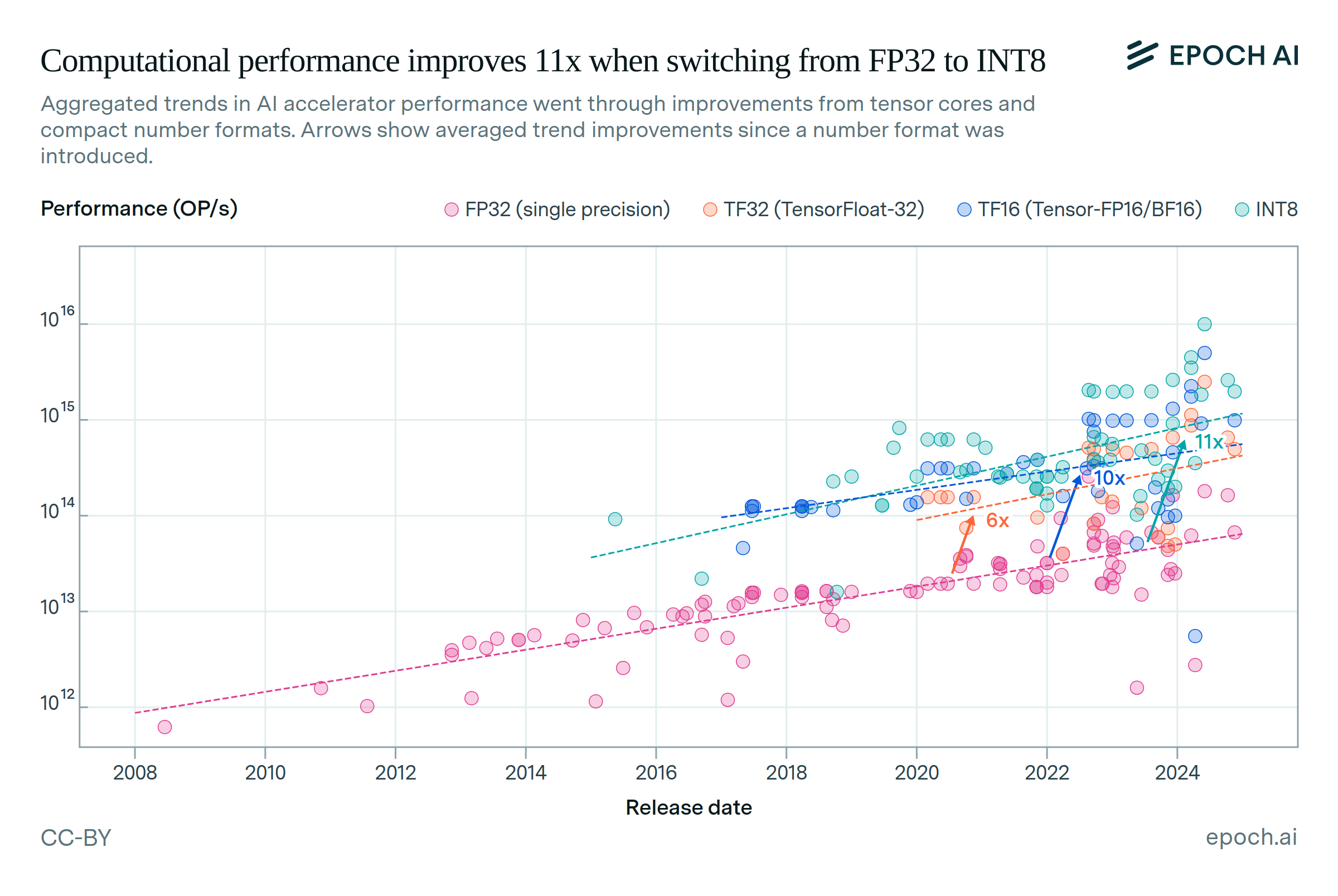
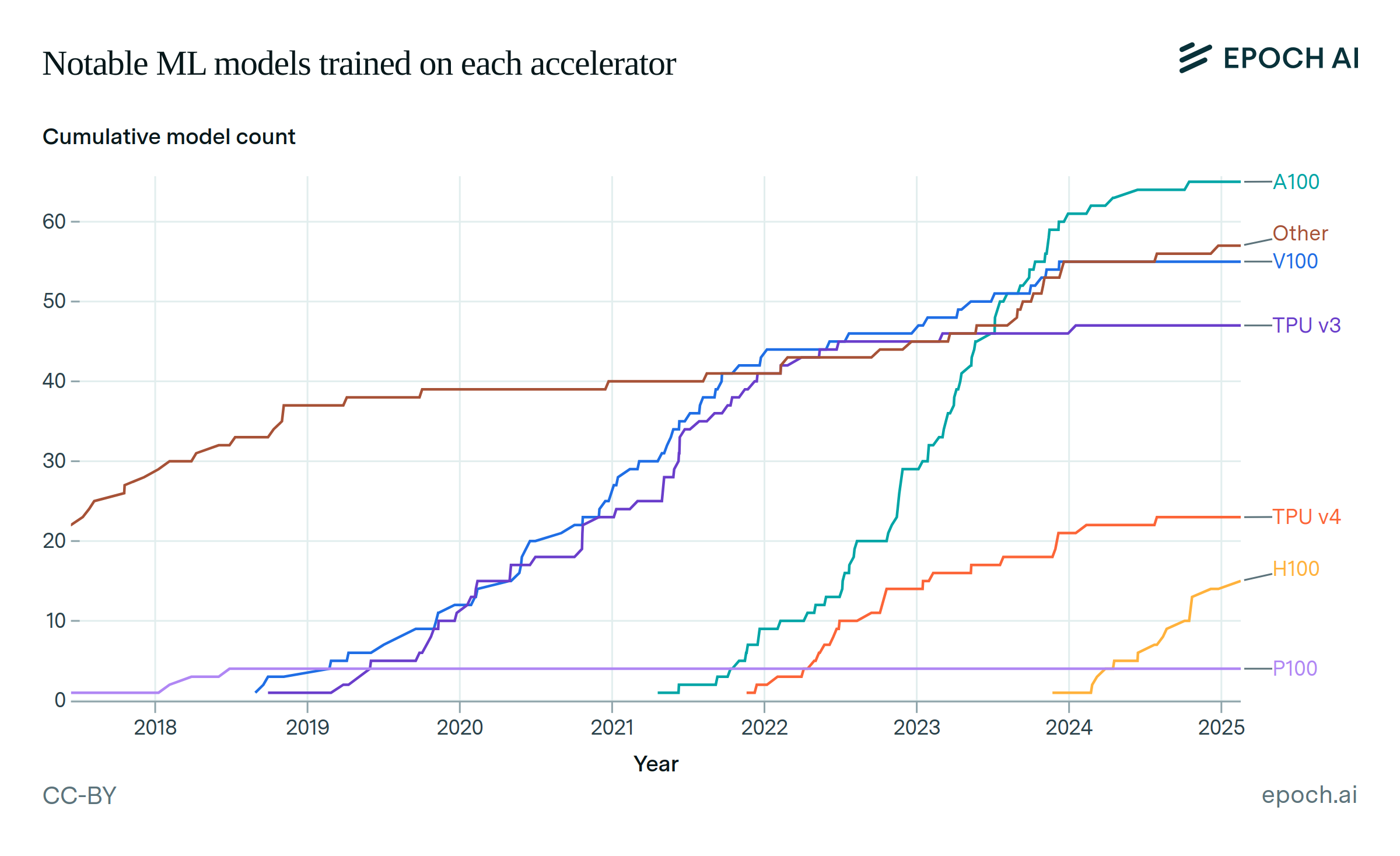
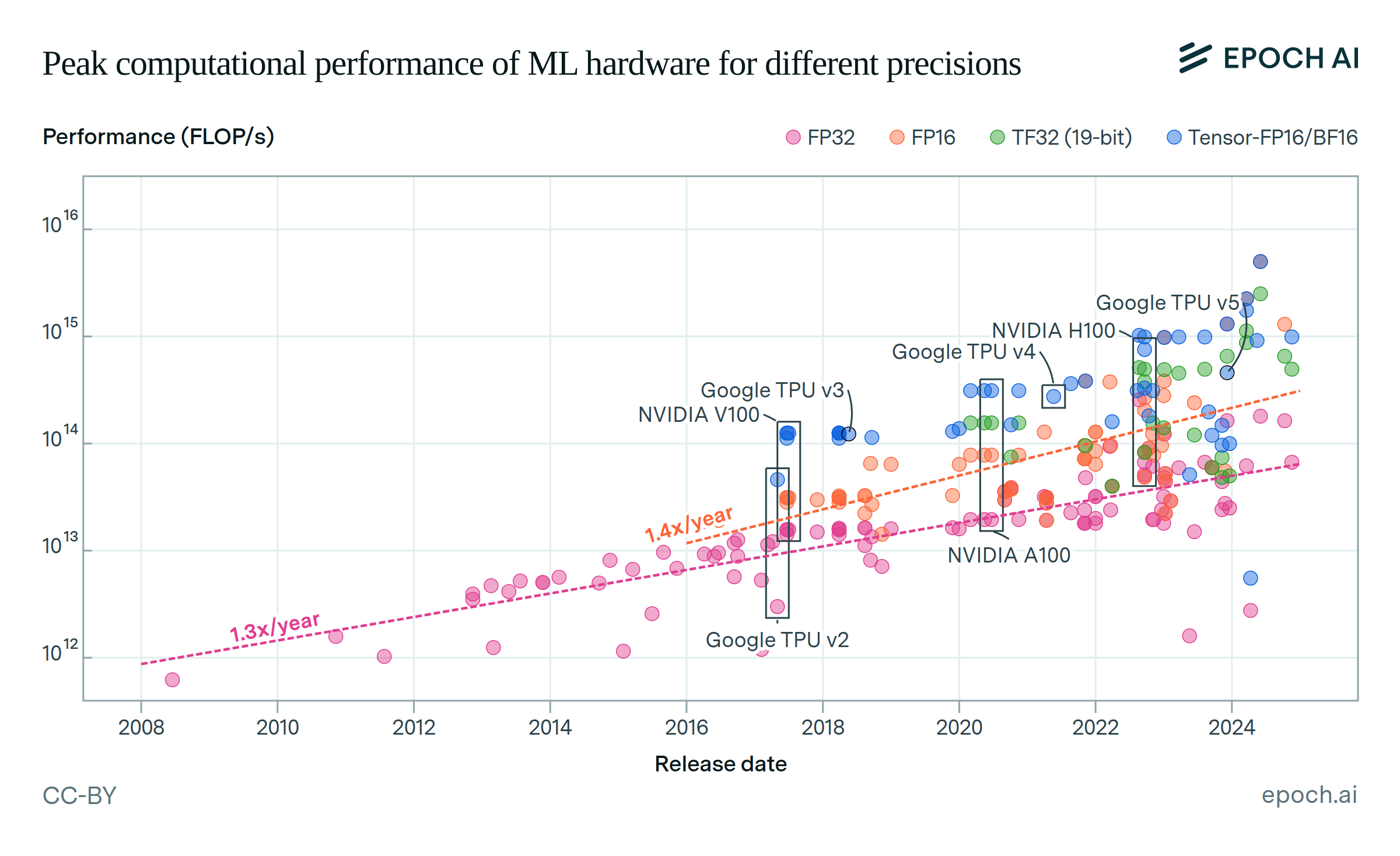
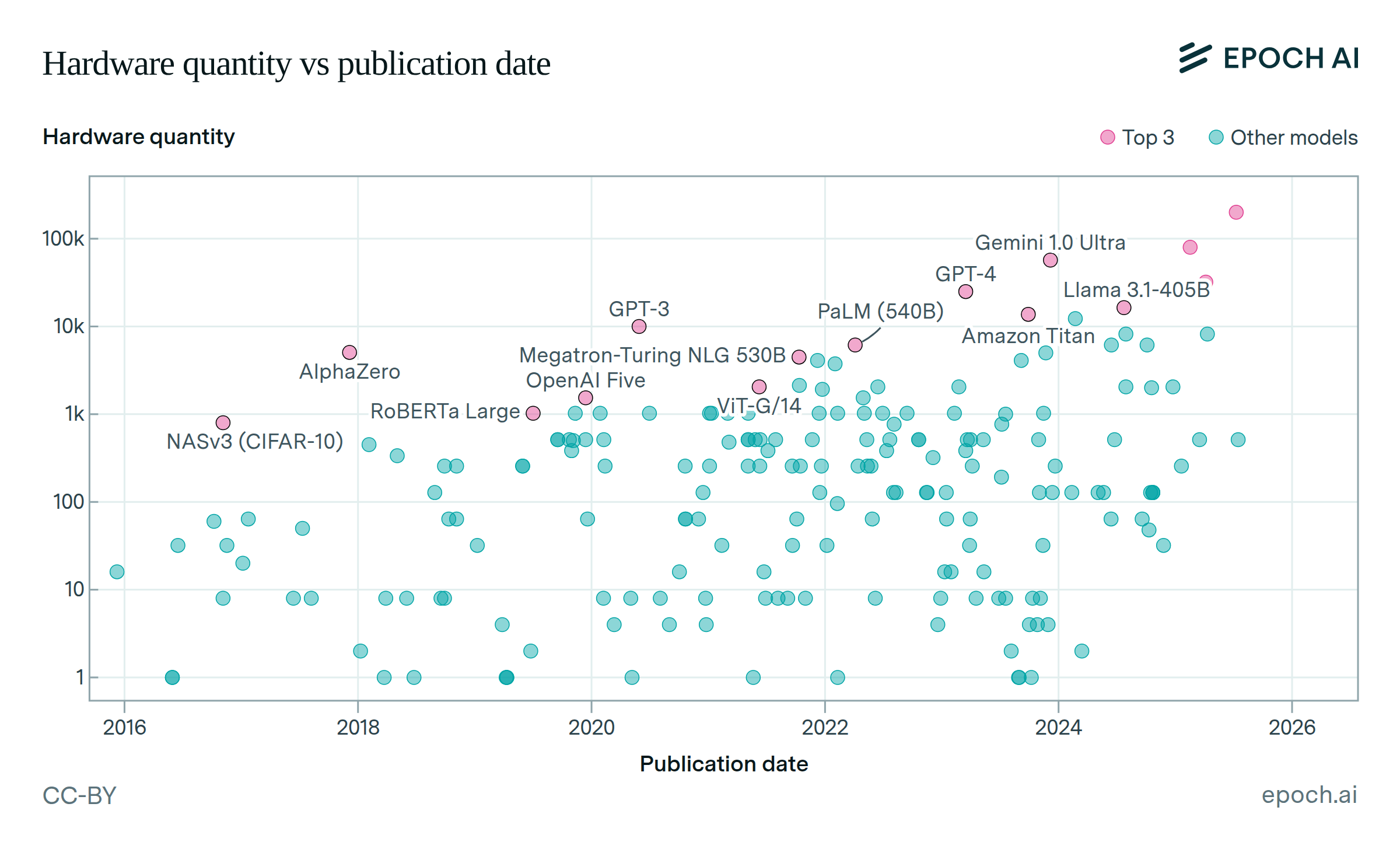
AI training cluster sizes increased by more than 20x since 2016
From Google’s NASv3 RL network, trained on 800 GPUs in 2016, to Meta’s Llama 3.1 405B, using 16,384 H100 GPUs in 2024, the number of processors used increased by a factor of over 20. Gemini Ultra was trained with an even larger number of TPUs, but precise details were not reported.

Authors
Published
October 23, 2024