
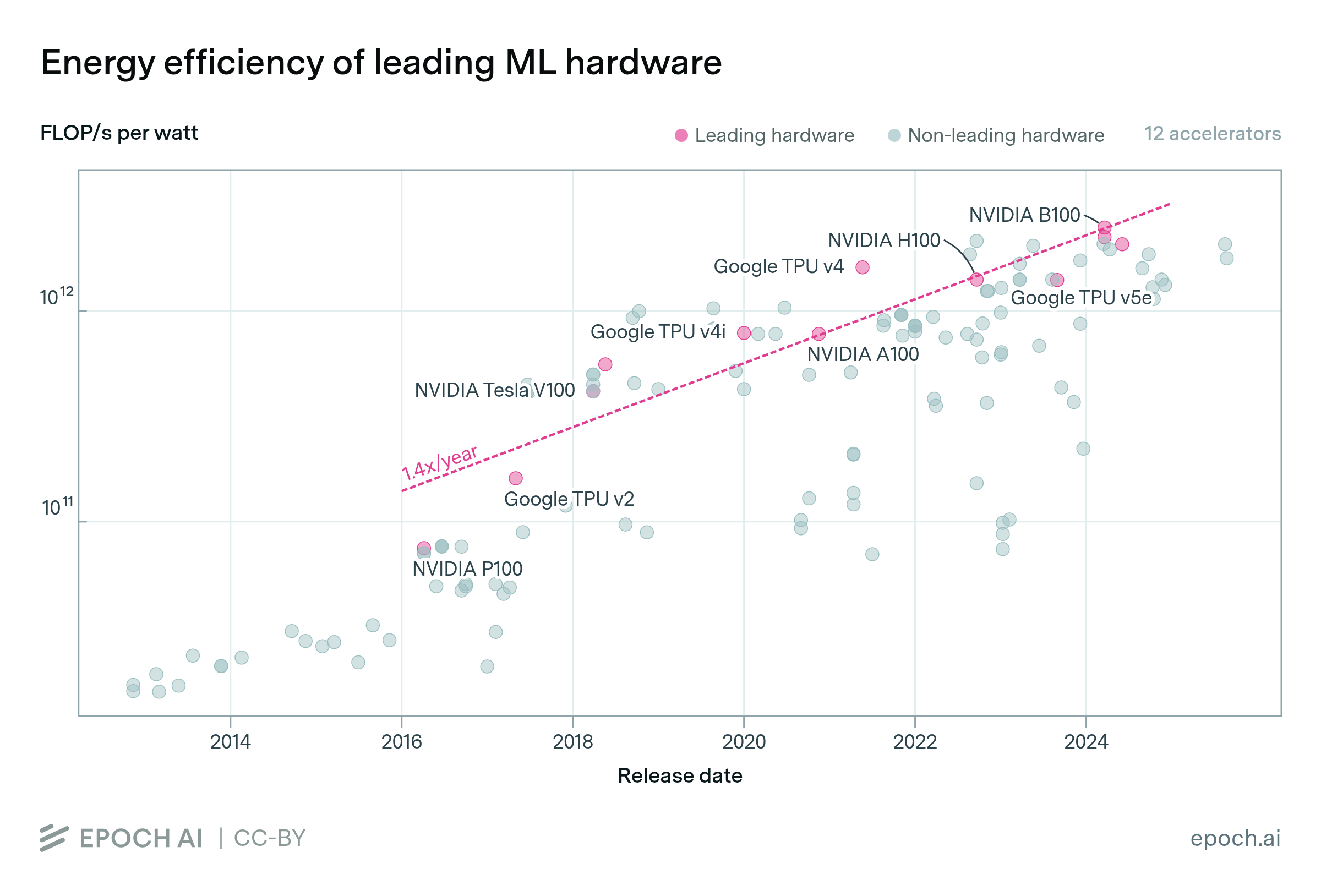
Historically, the energy efficiency of leading GPUs and TPUs has doubled every 2 years. In tensor-FP16 format, the most efficient accelerators are Meta’s MTIA, at up to 2.1 x 1012 FLOP/s per watt, and the NVIDIA H100, at up to 1.4 x 1012 FLOP/s per watt. The upcoming Blackwell series of processors may be even more efficient, depending on their power consumption.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Explore this data

Key data on over 170 AI accelerators, such as graphics processing units (GPUs) and tensor processing units (TPUs).