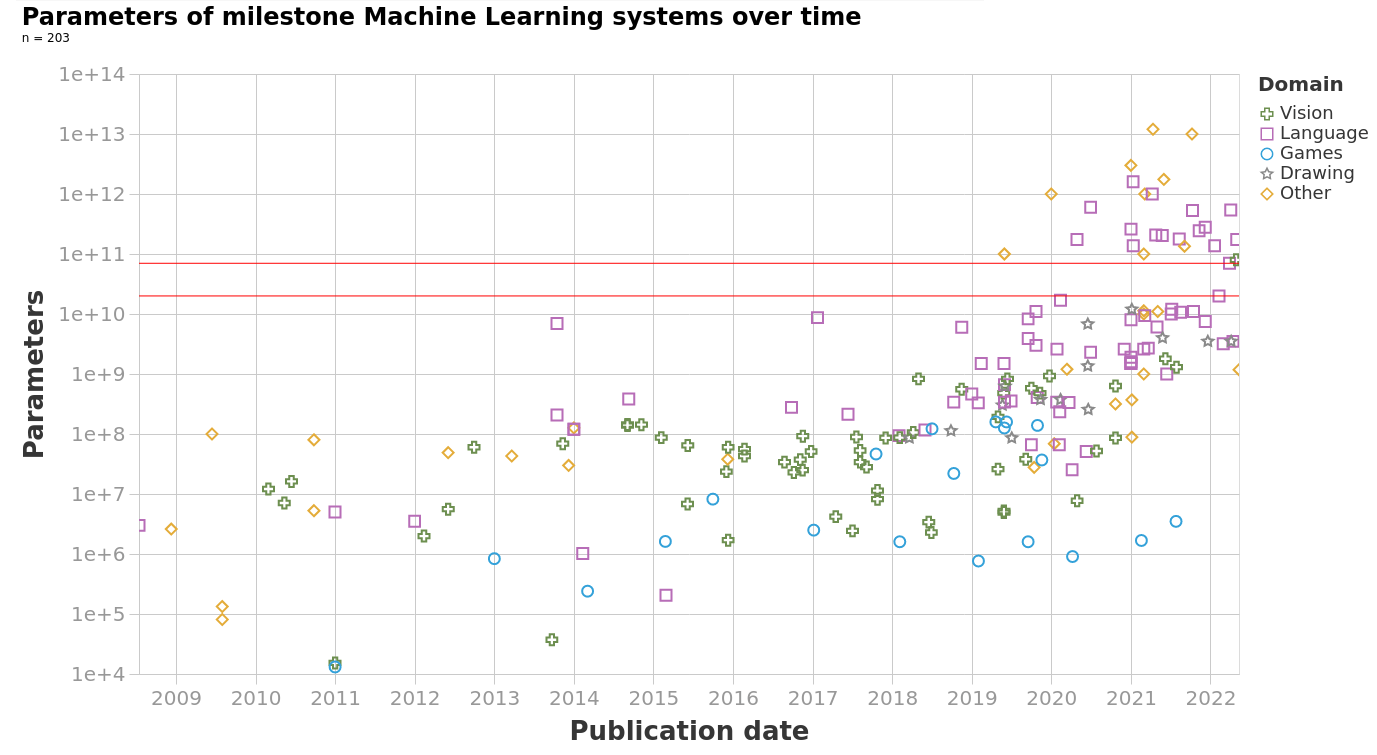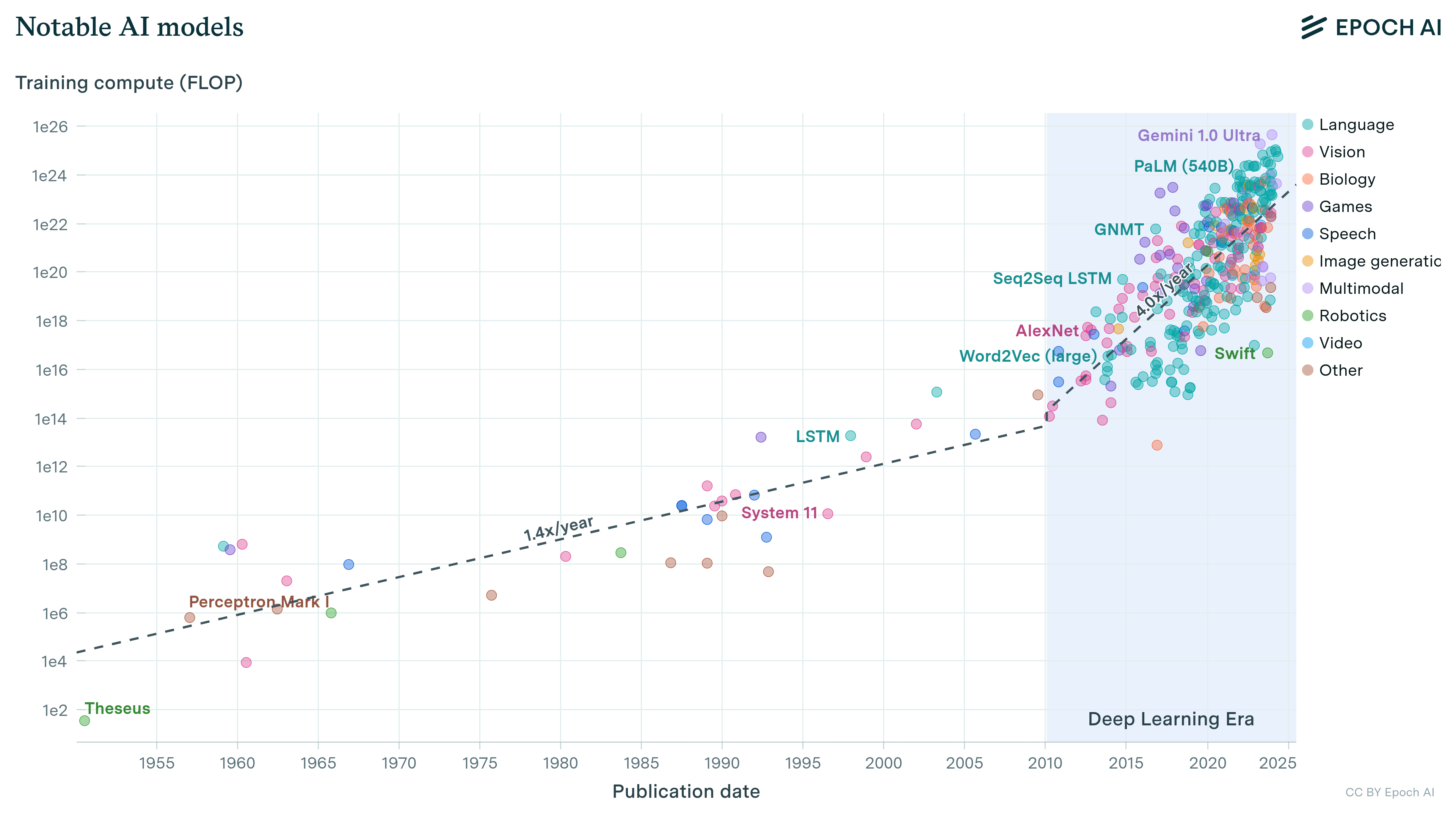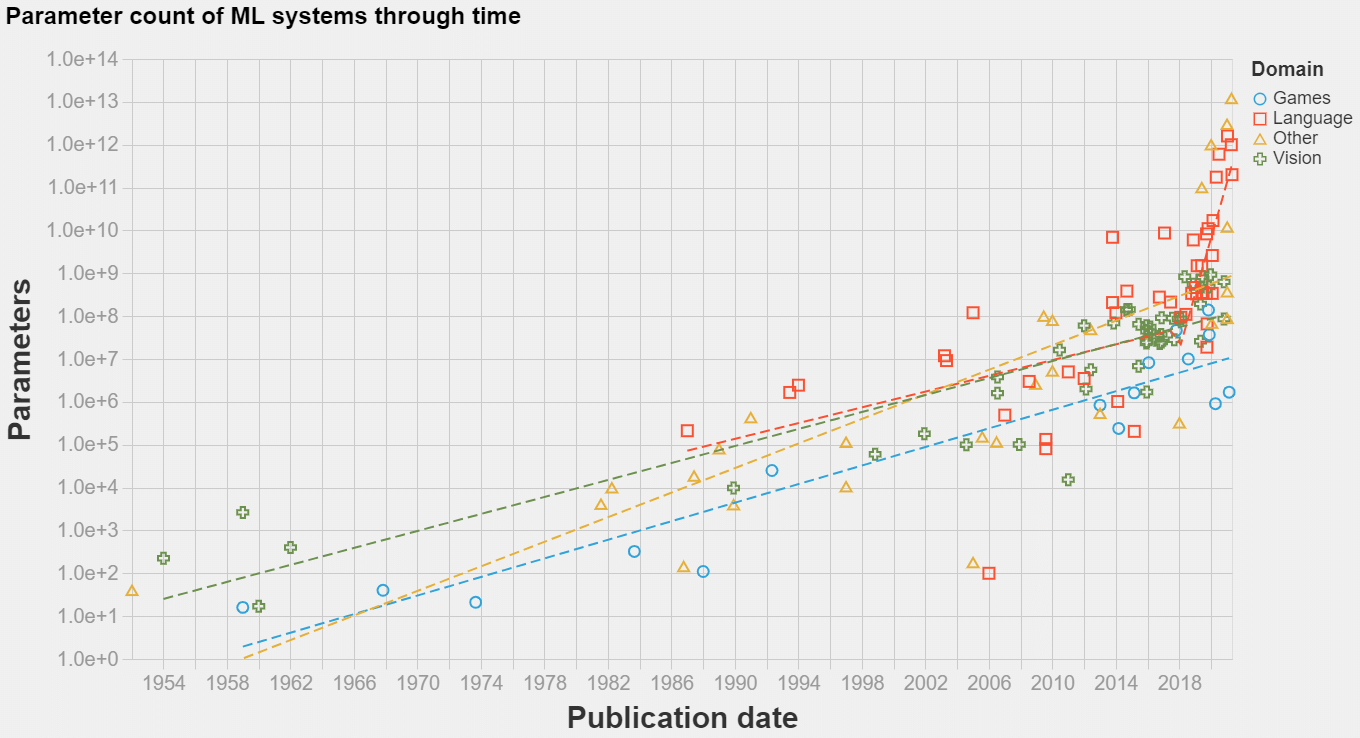
In short: we have compiled information about the date of development and trainable parameter counts of n=139 machine learning systems between 1952 and 2021. This is, as far as we know, the biggest public dataset of its kind. You can access our dataset here, and the code to produce an interactive visualization is available here.
We chose to focus on parameter count because previous work indicates that it is an important variable for model performance [1], because it helps as a proxy of model complexity and because it is information usually readily available or easily estimable from descriptions of model architecture.
We hope our work will help AI researchers and forecasters understand one way in which models have become more complex over time, and ground their predictions of how the field will progress in the future. In particular, we hope this will help us tease apart how much of the progress in machine learning has been due to algorithmic improvements versus increases in model complexity.
It is hard to draw firm conclusions from our biased and noisy dataset. Nevertheless, our work seems to give weak support to two hypotheses:
- There was no discontinuity in any domain in the trend of model size growth in 2011-2012. This suggests that the Deep Learning revolution was not due to an algorithmic improvement, but rather the point where the trend of improvement of machine learning methods caught up to the performance of other methods.
- In contrast, it seems there has been a discontinuity in model complexity for language models somewhere between 2016-2018. Returns to scale must have increased, and shifted the trajectory of growth from a doubling time of ~1.5 years to a doubling time of between 4 to 8 months.
The structure of this article is as follows. We first describe our dataset. We point out some weaknesses of our dataset. We expand on these and other insights. We raise some open questions. We finally discuss some next steps and invite collaboration.

Model size of popular new machine learning systems between 1954 and 2021. Includes n=139 datapoints. See expanded and interactive version of this graph here.
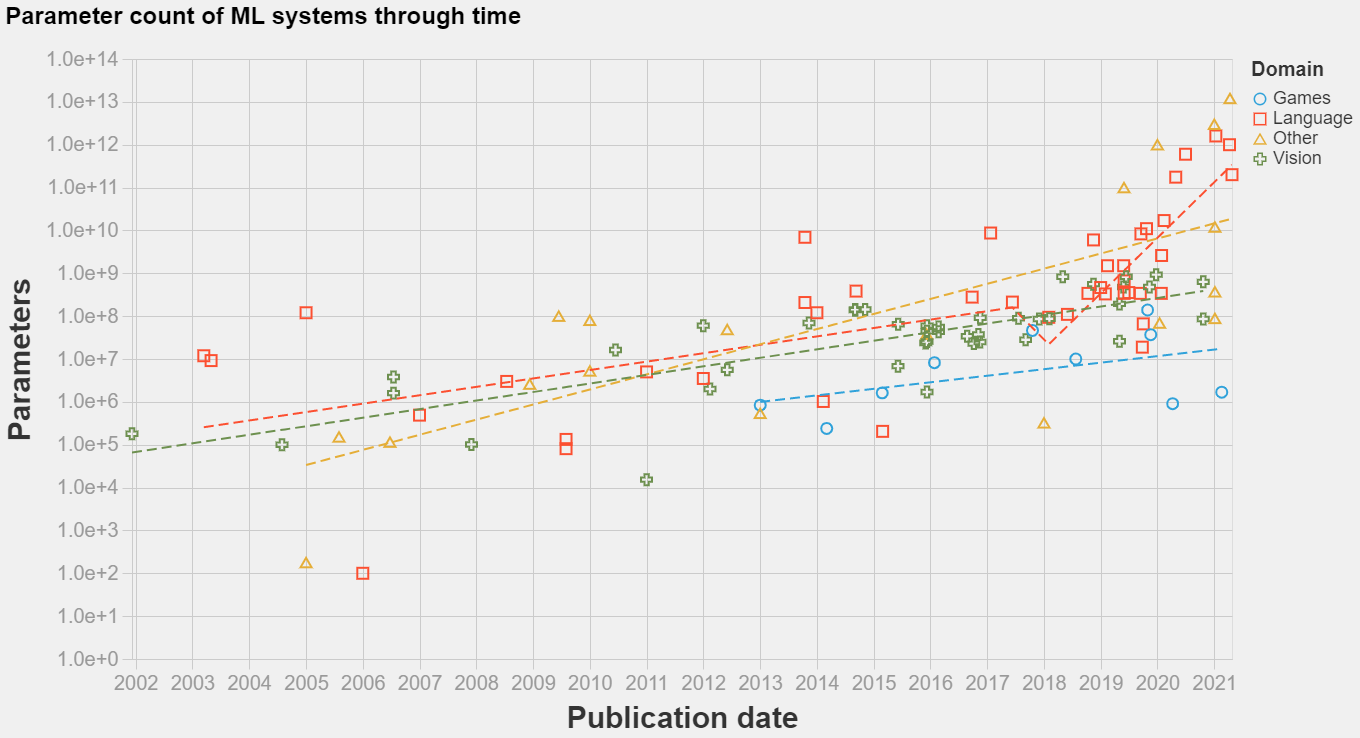
Model size of popular new machine learning systems between 2000 and 2021. Includes n=114 datapoints. See expanded and interactive version of this graph here.
Features of the dataset
- The dataset spans systems from 1952 to 2020, though we included far more information about recent systems (from 2010 onwards).
- The systems we include encompass many types, including neural networks, statistical models, support vector machines, bayesian networks and other more exotic architectures. However we mostly included systems of the neural network kind.
- The systems are from many domains and were trained to solve many tasks. However we mostly focused on systems trained to solve vision, language and gaming tasks.
- We relied on a subjective criteria of notability to decide which systems to include. Our decisions were informed by citation counts (papers with more than 1000 citations), external validation (papers that received some kind of paper of the year award or similar) and historical importance (papers that were cited by other work as seminal). The references to this post include some overviews we used as a starting point to curate our dataset [2-26].
- Several models have versions at multiple scales. Whenever we encountered this in their original publication, we recorded whichever was presented in the paper as the main one, or the largest presented version. Sometimes we recorded multiple versions when we felt it was warranted, e.g. when multiple different versions were trained to solve different tasks.
Caveats
- It is important to take into account that model size is hardly the most important parameter to understand the progress of ML systems. Other arguably more important indicators of non-algorithmic progress in ML systems include training compute and training dataset size [1].
- Model size as a metric of model complexity is hardly comparable across domains or even architectures. For example, a mixture-of-expert model can achieve higher parameter counts but invest far less compute into training each parameter.
- Our selection of systems is biased in many important ways. We are biased towards academic publications (since information on commercial systems is harder to come by). We include more information about recent systems. We tended to include information about papers where the parameter counts were readily available, in particular larger models that were developed to test the limits of how large a model can be. We are biased towards papers published in English. We mostly focused on systems on vision, language and gaming tasks, while we have comparatively fewer papers on e.g. speech recognition, recommender systems or self driving. Lastly, we are biased towards systems we personally found interesting or impressive.
- Recollecting the information was a time consuming exercise that required us to read through hundreds of technical papers to gather the parameter counts. It is quite likely we have made some mistakes.
Insights
- Unsurprisingly, there is an upward trend in model size. The trend seems exponential, and seems to have picked up its pace recently for language models. An eyeball estimate of the slope of progress suggests that the doubling rate was between 18 and 24 months from 2000 to 2016-2018 in all domains, and between 3 and 5 months from 2016-2018 onward in the language domain.
- The biggest models in terms of trainable parameters can be found in the language and recommender system domains. The biggest model we found was the 12 trillion parameter Deep Learning Recommender System from Facebook. We don’t have enough data on recommender systems to ascertain whether recommender systems have been historically large in terms of trainable parameters.
- Language models have been historically bigger than in other domains. This was because of statistical models whose parameterization scales with vocabulary size (e.g. as in the Hiero Machine Translation System from 2005) and word embeddings that also scale with vocabulary size (e.g. as in Word2Vec from 2013).
- Arguably Deep Learning started to proliferate in computer vision before it reached language processing (both circa 2011-2013), however the parameter counts of the second far surpass those of the first today. In particular, somewhere between 2016-2018 the trend of growth in language model size apparently greatly accelerated its pace, to a doubling time of between 4 and 8 months.
- Architectures on the game domain are small in terms of trainable parameters, below vision architectures while apparently growing at a similar rhythm. Naively we expected otherwise, since playing games seems more complicated. However, in hindsight, what determines model size is what are the returns to scale; in more complex domains we should expect lower effective model sizes, as the models are more constrained in other ways.
- The trend of growth in model size has been relatively stable through the transition into the deep learning era in 2011-2012 in all domains we studied (though it is hard to say with certainty given the amount of data). This suggests that the deep learning revolution was less of a paradigm change and more of a natural continuation of existing tendencies, which finally surpassed other non-machine learning methods.
Open questions
- Why is there a discrepancy in the trainable parameters magnitude and trend of growth in e.g. vision systems versus e.g. language systems? Some hypotheses are that language architectures scale better with size, that vision models are more bottlenecked on training data, that vision models require more compute per parameter or that the language processing ML community is ahead in experiment with large scale models (e.g. because they have access to more compute and resources).
- What caused the explosive growth in the size of language models from 2018 onwards? Was it a purely social phenomena as people realized the advantages of larger models, was it enabled by the discovery of architectures that scaled better with size, compute and data (e.g. transformers?) or was it caused by something else entirely?
- Do the scaling laws of machine learning for pre-and-post-deep-learning actually differ significatively? So far model size seems to suggest otherwise, what about other metrics?
- How can we more accurately estimate the rates of growth for each domain and period? For how long will current rates of growth be sustained?
Next steps
- We are interested in collaborating with other researchers to grow this dataset to be more representative and correcting any mistakes. As an incentive, we will pay $5 per mistake found or system addition (up to $600 total among all submissions; please contact us if you want to contribute with a donation to increase the payment cap). You can send your submissions to jaimesevillamolina at gmail dot com, preferably in spreadsheet format.
- We are interested in including other information about the systems, most notably compute and training dataset size.
- We want to include more information on other domains, specially on recommender systems.
- We want to look harder for systematic reviews and other already curated datasets of AI systems.
Acknowledgements
This article was written by Jaime Sevilla, Pablo Villalobos and Juan Felipe Cerón. Jaime’s work is supported by a Marie Curie grant of the NL4XAI Horizon 2020 program.
We thank Girish Sastry for advising us on the beginning of the project, the Spanish Effective Altruism community for creating a space to incubate projects such as this one, and Haydn Belfield, Pablo Moreno and Ehud Reiter for discussion and system submissions.
Bibliography
- Kaplan et al., “Scaling Laws for Neural Language Models,” 08361.
- 1.6 History of Reinforcement Learning. (n.d.). Retrieved June 19, 2021, from http://incompleteideas.net/book/first/ebook/node12.html
- AI and Compute. (n.d.). Retrieved June 19, 2021, from https://openai.com/blog/ai-and-compute/
- AI and Efficiency. (2020, May 5). OpenAI. https://openai.com/blog/ai-and-efficiency/
- AI Progress Measurement. (2017, June 12). Electronic Frontier Foundation. https://www.eff.org/ai/metrics
- Announcement of the 2020 ACL Test-of-Time Awards (ToT) | ACL Member Portal. (n.d.). Retrieved June 19, 2021, from https://www.aclweb.org/portal/content/announcement-2020-acl-test-time-awards-tot#:~:text=Each%20year%2C%20the%20ACL%20Test,papers%20from%2010%20years%20earlier.&text=The%20winners%20were%20announced%20at%20ACL%202020.
- Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623. https://doi.org/10.1145/3442188.3445922
- Best paper awards—ACL Wiki. (n.d.). Retrieved June 19, 2021, from https://aclweb.org/aclwiki/Best_paper_awards
- bnlearn—Bayesian Network Repository. (n.d.). Retrieved June 19, 2021, from https://www.bnlearn.com/bnrepository/
- Brian Christian on the alignment problem. (n.d.). 80,000 Hours. Retrieved June 19, 2021, from https://80000hours.org/podcast/episodes/brian-christian-the-alignment-problem/
- Computer Vision Awards – The Computer Vision Foundation. (n.d.). Retrieved June 19, 2021, from https://www.thecvf.com/?page_id=413
- DARPA Grand Challenge. (2021). In Wikipedia. https://en.wikipedia.org/w/index.php?title=DARPA_Grand_Challenge&oldid=1021627196
- Karim, R. (2020, November 28). Illustrated: 10 CNN Architectures. Medium. https://towardsdatascience.com/illustrated-10-cnn-architectures-95d78ace614d
- Mohammad, S. M. (2020). Examining Citations of Natural Language Processing Literature. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 5199–5209. https://doi.org/10.18653/v1/2020.acl-main.464
- Mudigere, D., Hao, Y., Huang, J., Tulloch, A., Sridharan, S., Liu, X., Ozdal, M., Nie, J., Park, J., Luo, L., Yang, J. A., Gao, L., Ivchenko, D., Basant, A., Hu, Y., Yang, J., Ardestani, E. K., Wang, X., Komuravelli, R., … Rao, V. (2021). High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models. ArXiv:2104.05158 [Cs]. http://arxiv.org/abs/2104.05158
- Nilsson, N. (1974). Artificial Intelligence. IFIP Congress. https://doi.org/10.7551/mitpress/11723.003.0006
- Posey, L. (2020, April 28). History of AI Research. Medium. https://web.archive.org/web/20191219113724/https://towardsdatascience.com/history-of-ai-research-90a6cc8adc9c?gi=2c235e3cb5bc
- Raschka, S. (2019). A Brief Summary of the History of Neural Networks and Deep Learning. Deep Learning, 29.
- Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2020). DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. ArXiv:1910.01108 [Cs]. http://arxiv.org/abs/1910.01108
- Thompson, N. C., Greenewald, K., Lee, K., & Manso, G. F. (2020). The Computational Limits of Deep Learning. ArXiv:2007.05558 [Cs, Stat]. http://arxiv.org/abs/2007.05558
- Vidal, R. (n.d.). Computer Vision: History, the Rise of Deep Networks, and Future Vistas. 60.
- Wang, B. (2021). Kingoflolz/mesh-transformer-jax [Jupyter Notebook]. https://github.com/kingoflolz/mesh-transformer-jax (Original work published 2021)
- Who Invented Backpropagation? (n.d.). Retrieved June 19, 2021, from https://people.idsia.ch//~juergen/who-invented-backpropagation.html
- Xie, Q., Luong, M.-T., Hovy, E., & Le, Q. V. (2020). Self-training with Noisy Student improves ImageNet classification. ArXiv:1911.04252 [Cs, Stat]. http://arxiv.org/abs/1911.04252
- Young, T., Hazarika, D., Poria, S., & Cambria, E. (2018). Recent Trends in Deep Learning Based Natural Language Processing. ArXiv:1708.02709 [Cs]. http://arxiv.org/abs/1708.02709
- Zhang, B., Xiong, D., Su, J., Lin, Q., & Zhang, H. (2018). Simplifying Neural Machine Translation with Addition-Subtraction Twin-Gated Recurrent Networks. ArXiv:1810.12546 [Cs]. http://arxiv.org/abs/1810.12546
- Zoph, B., & Le, Q. V. (2016). Neural Architecture Search with Reinforcement Learning. https://arxiv.org/abs/1611.01578v2
About the authors


Related work